GCPUG meetup 201610 - Dataflow Introduction
8 likes1,302 views

This document provides information about Simon Su and Sunny Hu, who will be presenting on Google's BigData solution. It includes their contact information and backgrounds. Simon's areas of focus include Node.js and blogging. Sunny's skills include project management, system analysis, and Java. The document also advertises a Facebook and Google+ group for the Google Cloud Platform User Group Taiwan, where people can share experiences using GCP. It poses trivia questions about Google's infrastructure and provides timelines of Google's BigData innovations.


![Sunny Hu
var sunny = {};
sunny.aboutme = 'https://plus.google.com/u/0/+sunnyHU/posts';
sunny.email = sunnyhu@linkernetworks.com.’;
sunny.language =[‘Java’,’.NET’,’NodeJS’,’SQL’ ]
sunny.skill = [ ‘Project management’,
’System Analysis’,
’System design’,
’Car ho lan’ ]
sunny.say(‘寫code太苦悶,心情要sunny');
GCP Qualified Developer](https://image.slidesharecdn.com/gcpugmeetup201610-dataflowintroduction-161006164421/85/GCPUG-meetup-201610-Dataflow-Introduction-3-320.jpg)

































GCPUG meetup 201610 - Dataflow Introduction
- 1. Google BigData solution Su plus Hu @ GCPUG.TW
- 2. Simon Su var simon = {}; simon.aboutme = 'http://about.me/peihsinsu'; simon.nodejs = ‘http://opennodes.arecord.us'; simon.googleshare = 'http://gappsnews.blogspot.tw' simon.nodejsblog = ‘http://nodejs-in-example.blogspot.tw'; simon.blog = ‘http://peihsinsu.blogspot.com'; simon.slideshare = ‘http://slideshare.net/peihsinsu/'; simon.email = ‘[email protected]’; simon.say(‘Good luck to everybody!');
- 3. Sunny Hu var sunny = {}; sunny.aboutme = 'https://plus.google.com/u/0/+sunnyHU/posts'; sunny.email = [email protected].’; sunny.language =[‘Java’,’.NET’,’NodeJS’,’SQL’ ] sunny.skill = [ ‘Project management’, ’System Analysis’, ’System design’, ’Car ho lan’ ] sunny.say(‘寫code太苦悶,心情要sunny'); GCP Qualified Developer
- 4. ● We are “舒” “服” 二人組 ... ● This is Su Hu style ...
- 5. https://www.facebook.com/groups/GCPUG.TW/ https://plus.google.com/u/0/communities/116100913832589966421 Google Cloud Platform User Group Taiwan 我們是Google Cloud Platform Taiwan User Group。在Google雲端服務在台灣地區展 露頭角之後,有許多新的服務、新的知識、新的創意,歡迎大家一起分享,一起了解 Google雲端服務... GCPUG透過網際網路串聯喜好Google Cloud的使用者,分享與交流使用GCP的點滴 鑑驗。如果您是Google Cloud Platform的初學者,您應該來聽聽前輩們的使用經驗;如 果您是Google Cloud Platform的Expert,您應該來分享一下寶貴的經驗,並與更多高 手互相交流;如果您還沒開始用Google Cloud Platform,那麼您應該馬上來聽聽我們 是怎麼使用Google Cloud的!
- 6. Linker Want You... ● Data scientist ● Data engineer ● Frontend engineer
- 7. 每分鐘上傳到YouTube的影片長度? Google search 的 index 有多大? Google有多少有效的使用者? 72 hours 425M+ 100PB+ (over 100,000 TBs) 0.25 seconds Google 需要平均回應客戶搜索關鍵字的時間?
- 9. SpannerDremelMapReduce Big Table Colossus 2012 20132002 2004 2006 2008 2010 GFS MillWheel Flume Google innovation
- 10. Provided as a managed services ... SpannerDremelMapReduce Big Table Colossus 2012 20132002 2004 2006 2008 2010 GFS MillWheel Flume
- 11. Google Changed the Big Data Market Google MapReduce Google Bigtable Google Borg Google Borg Google Dremel
- 12. StoreCapture Analyze BigQuery Larger Hadoop Ecosystem Hadoop Spark (on GCE) Pub/Sub BigQuery streaming Process Dataflow (stream & batch) Cloud Storage (objects) BigQuery Storage (structured) Hadoop Spark (on GCE) Big Data on Google Cloud Platform
- 14. Cloud Pub/Sub Publisher A Publisher B Publisher C Message 1 Topic A Topic B Topic C Subscription XA Subscription XB Subscription YC Subscription ZC Cloud Pub/Sub Subscriber X Subscriber Y Message 2 Message 3 Subscriber Z Message 1 Message 2 Message 3 Message 3 ● Globally redundant ● Low latency (sub sec.) ● N to N coupling ● Batched read/write ● Push & Pull ● Guaranteed Delivery ● Auto expiration
- 15. Cloud Dataflow = Managed Flume + MillWheel on GCE
- 16. Dataflow use case • Movement • Filtering • Enrichment • Shaping • Reduction • Batch computation • Continuous computation • Composition • External orchestration • Simulation OrchestrationAnalysisETL
- 17. <- Aggregations, Filters, Joins, ... <- Completeness Pipeline{ Who => Inputs What => Transforms Where => Windows When => Watermarks + Triggers To => Outputs } Transform Output Input Cloud Dataflow SDK - Logic model
- 18. Life of Pipeline GCP Managed Service User Code & SDK Work Manager Deploy & Schedule Monitoring UI Job Manager Progress & Logs
- 19. Cloud Dataflow SDK ❯ Unified programming model for both batch & stream processing ● Independent from the execution back-end aka “runner” ❯ Google driven & open sourced ● Java 7 or 8 @ github.com/GoogleCloudPlatform/DataflowJavaSDK ● Python ❯ Community sourced ● Scala @ github.com/darkjh/scalaflow ● Scala @ github.com/jhlch/scala-dataflow-dsl
- 20. Pipeline ● A Direct Acyclic Graph of data processing transformations ● Can be submitted to the Dataflow Service for optimization and execution or executed on an alternate runner e.g. Spark ● May include multiple inputs and multiple outputs ● May encompass many logical MapReduce operations ● PCollections flow through the pipeline
- 21. Your Source/Sink Here ❯ Read from standard Google Cloud Platform data sources • GCS, Pub/Sub, BigQuery, Datastore ❯ Write your own custom source by teaching Dataflow how to read it in parallel • Currently for bounded sources only ❯ Write to GCS, BigQuery, Pub/Sub • More coming… ❯ Can use a combination of text, JSON, XML, Avro formatted data Inputs & Outputs
- 22. PCollection ❯ A collection of data of type T in a pipeline - PCollection<K,V> ❯ Maybe be either bounded or unbounded in size ❯ Created by using a PTransform to: • Build from a java.util.Collection • Read from a backing data store • Transform an existing PCollection ❯ Often contain the key-value pairs using KV {Seahawks, NFC, Champions, Seattle, ...} {..., “NFC Champions #GreenBay”, “Green Bay #superbowl!”, ... “#GoHawks”, ...}
- 23. ● A step, or a processing operation that transforms data ○ convert format , group , filter data ● Type of Transforms ○ ParDo ○ GroupByKey ○ Combine ○ Flatten ■ Multiple PCollection objects that contain the same data type, you can merge them into a single logical PCollection using the Flatten transform Transforms
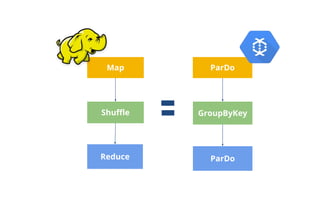
- 24. ❯ Processes each element of a PCollection independently using a user-provided DoFn ❯ Corresponds to both the Map and Reduce phases in Hadoop i.e. ParDo->GBK->ParDo ❯ Useful for ○ Filtering a data set. ○ Formatting or converting the type of each element in a data set. ○ Extracting parts of each element in a data set. ○ Performing computations on each element in a data set. Pardo (Parallel do) {Seahawks, NFC, Champions, Seattle, ...} { KV<S, Seahawks>, KV<C,Champions>, <KV<S, Seattle>, KV<N, NFC>, … } KeyBySessionId
- 26. Wait a minute… How do you do a GroupByKey on an unbounded PCollection? {KV<S, Seahawks>, KV<C,Champions>, <KV<S, Seattle>, KV<N, NFC>, ...} {KV<S, Seahawks>, KV<C,Champions>, <KV<S, Seattle>, KV<N, NFC>, ...} GroupByKey • Takes a PCollection of key-value pairs and gathers up all values with the same key • Corresponds to the shuffle phase in Hadoop {KV<S, {Seahawks, Seattle, …}, KV<N, {NFC, …} KV<C, {Champion, …}} Group by key
- 29. Windowing
- 30. ● Triggers control when results are emitted. ● Triggers are often relative to the watermark Trigger http://cdn.oreillystatic.com/en/assets/1/event/155/Watermarks_%20Time%20and%20progress%20in %20streaming%20dataflow%20and%20beyond%20Presentation.pdf
- 32. Composite Transform ● Code reuse ● Better monitoring experience
- 33. Benifits of Cloud Dataflow ● Functional (transform based) programming model ● Unified programming model for batch & stream processing ● Reduced operational cost of “cluster” management ● Decreased job clock time via platform innovation ● Open source ecosystem of SDKs, extensions, runners, etc.
- 34. Optimizing Your Time Programming Resource provisioning Performance tuning Monitoring Reliability Deployment & configuration Handling growing scale Utilization improvements Typical Data Processing More time to dig into your data Programming Data Processing with Cloud Dataflow
- 35. Run the same code in multiple modes using different runners ❯ Direct Runner • For local, in-memory execution. • Great for developing and unit tests ❯ Cloud Dataflow Service Runner • Runs on the fully-manage Dataflow Service • Your code runs distributed across GCE instances ❯ Community sourced • Spark runner @ github.com/cloudera/spark-dataflow • Flink runner from dataArtisans Cloud DataFlow Runners
- 36. Build a mobile gaming analytics platform
- 37. Q&A