Generating super resolution images using transformers

The document summarizes a research paper on using transformers for the task of natural language processing. Some key points: - Transformers use attention mechanisms to draw global dependencies between input and output without regard to sequence length, addressing limitations of RNNs and CNNs for NLP tasks. - The proposed transformer architecture contains self-attention layers in the encoder and decoder, as well as an attention mechanism between the encoder and decoder. - The transformer uses scaled dot-product attention and multi-head attention. Self-attention allows relating different positions of a single sequence to compute representations. - Other components include feedforward layers and positional encoding to inject information about the relative or absolute positions of the tokens in the sequence










![DESCRIPTION OF EXISTING METHODS
Method 1: TTSR
lrsr
refsr
ref
Learnable Texture Extractor (LTE)
Normalize Input range:[-1,1], Output range:[0,1], f(x)=(x+1)/2
Equalize Data by fixing mean&std (MeanShift)
(Lv3,Lv2,Lv1)=VGG19 (2,7,12 layer output)
Embedding-Create Patches
UnFold (kernel(3,3),padding(1))
Lv3
Lv3
Lv3, Lv2, Lv1,
UnFold(k(3,3),p(1),s(1))
UnFold(k(6,6),p(2),s(2))
UnFold(k(12,12),p(4),s(4))
Transpose
Normalize patches
Matrix Multiplication (t.bmm)
Q
K
V
Attention weight
Max
MaxArg
h
s
S (soft attention map)
Value map
H (hard attention maps)
Fold values map
TIV3
TIV2
TIV1
Lr
F Conv+Relu+Res-block+Conv
Backbone DNN
Fout=F+Conv(F,TIVi)*S](https://image.slidesharecdn.com/generatingsuper-resolutionimagesusingtransformers-210930110353/85/Generating-super-resolution-images-using-transformers-12-320.jpg?cb=1684058196)




























































More Related Content
Similar to Generating super resolution images using transformers (20)
More from NEERAJ BAGHEL (16)














Recently uploaded (20)




















Generating super resolution images using transformers
- 1. GENERATING SUPER-RESOLUTION IMAGES USING TRANSFORMERS NEERAJ BAGHEL (RSI2021003) 19 Sept 2021 at IIIT-Allahabad
- 4. INTRODUCTION Image super-resolution Original low-resolution images Cropped and Zoom
- 5. INTRODUCTION Image super-resolution Cropped and Zoom Reconstructed high-resolution image Original low-resolution images
- 6. INTRODUCTION Image super-resolution Cropped and Zoom Reconstructed high-resolution image Original low-resolution images low-resolution high-resolution Applications: Medical Imaging. Satellite Imaging. Digital zoom in Camera. Image enhancement technology for digital televisions
- 7. MOTIVATION & OBJECTIVE Motivation: low resolution images.
- 8. MOTIVATION & OBJECTIVE Motivation: low resolution images.
- 9. MOTIVATION & OBJECTIVE Motivation: low resolution images. Objective: Super-Resolution Transformer
- 10. DESCRIPTION OF EXISTING METHODS 1)Deep Learning methods like conditional GANs can be used to for this problems. Method where, end to end mapping function between LR and HR images. 2)Method like image aligning or patch matching functions can be used to treat this problem. Aligning b/w LR and Ref. image. Optical flow,
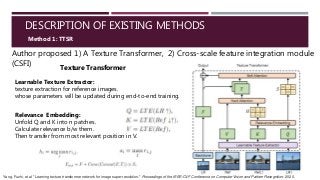
- 11. DESCRIPTION OF EXISTING METHODS Author proposed 1) A Texture Transformer, 2) Cross-scale feature integration module (CSFI) Method 1: TTSR Texture Transformer Learnable Texture Extractor: texture extraction for reference images. whose parameters will be updated during end-to-end training. Relevance Embedding: Unfold Q and K into n patches. Calculate relevance b/w them. Then transfer from most relevant position in V. Yang, Fuzhi, et al. "Learning texture transformer network for image super-resolution." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
- 12. DESCRIPTION OF EXISTING METHODS Method 1: TTSR lrsr refsr ref Learnable Texture Extractor (LTE) Normalize Input range:[-1,1], Output range:[0,1], f(x)=(x+1)/2 Equalize Data by fixing mean&std (MeanShift) (Lv3,Lv2,Lv1)=VGG19 (2,7,12 layer output) Embedding-Create Patches UnFold (kernel(3,3),padding(1)) Lv3 Lv3 Lv3, Lv2, Lv1, UnFold(k(3,3),p(1),s(1)) UnFold(k(6,6),p(2),s(2)) UnFold(k(12,12),p(4),s(4)) Transpose Normalize patches Matrix Multiplication (t.bmm) Q K V Attention weight Max MaxArg h s S (soft attention map) Value map H (hard attention maps) Fold values map TIV3 TIV2 TIV1 Lr F Conv+Relu+Res-block+Conv Backbone DNN Fout=F+Conv(F,TIVi)*S
- 13. DESCRIPTION OF EXISTING METHODS 2) Cross-scale feature integration module (CSFI) Method 1: TTSR Cross-Scale Feature Integration Module 3) Loss Function 1) Reconstruction loss: Utilize L1 loss and L2 loss 2) Adversarial loss: effective in generating clear and visually favorable images 3) Perceptual loss: enhance the similarity in feature space Yang, Fuzhi, et al. "Learning texture transformer network for image super-resolution." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
- 14. SUMMARY OF THE PROPOSED PLAN Transformer for computer vision problems. There are various techniques available that are efficient for lower scale values (✕ 2, ✕ 3 ) but as we go for higher scales like the efficiency gets reduced. Transformer commonly need heavy GPU memory cost. Assume case where no reference image is available for test data.
- 15. SUMMARY OF THE PROPOSED PLAN We can use Different deep feature space as for texture extractor. Based on pre- trained model Other than vgg19. give direct image as input Upgrading LR ↑ using self-attention in LR↑ to create LR ↑+ images: which has more information then LR↑. Apply discriminator transformer. After that for more enhanced resolution. Assume case where no reference image is available for test data. LR ↑+ Discriminator HR Ground Truth
- 16. DESCRIPTION OF DATASETS CUFED Dataset: 11,871 pair images CUFED5 Dataset: 126 testing images with 5 reference set DIV2K Dataset : 800 RGB training images and 100 validation images, Rich textures (2K resolution) Set5, Set14: Evaluation dataset for Super Resolution (5,14 images) (buildings, animal,etc.) B100, Urban100: Comparison for 4 scale factor (100 images)
- 17. EVOLUTION TECHNIQUE Peak signal-to-noise ratio (PSNR) Structure similarity index (SSIM) are used to evaluate the performance of the reconstructed SR images.
- 18. DESCRIPTION OF CODE AVAILABILITY SwinIR: Image Restoration Using Swin Transformer https://github.com/JingyunLiang/SwinIR Light Field Image Super-Resolution with Transformers https://github.com/ZhengyuLiang24/LFT Learning Texture Transformer Network for Image Super-Resolution https://github.com/researchmm/TTSR
- 19. EXPERIMENTAL SETUP Python Pytorch using JuyperLab IDE Created virtual environment as transformer
- 20. PRESENTER CONTRIBUTION Learning Transformer basic concepts. Available state of ART Technique on super resolution. Implementation of previous state of art technique. Downloaded dataset and check it for state of art technique. Proposed plan for future work.
- 21. QUESTIONS
- 22. THANK YOU
- 23. ATTENTION IS ALL YOU NEED CONFERENCE ON NEURAL INFORMATION PROCESSING SYSTEMS (NIPS 2017) 4 DEC 2017 – 9 DEC 2017 AT CALIFORNIA, UNITED STATES NEERAJ BAGHEL (RESEARCH SCHOLAR) IIITA, INDIA Ashish Vaswani (Google Brain) Noam Shazeer (Google Brain) Niki Parmar (Google Research) Jakob Uszkoreit (Google Research) Llion Jones (Google Research) Aidan N. Gomez (University of Toronto) Łukasz Kaiser (Google Brain) Illia Polosukhin (Google Research)
- 24. OUTLINE • NATURAL LANGUAGE PROCESSING • ATTENTION • PROPOSED TRANSFORMER ARCHITECTURE • SCALED DOT-PRODUCT ATTENTION • MULTI-HEAD ATTENTION • SELF-ATTENTION • FEED FORWARD LAYER • POSITIONAL ENCODING • BEAM-SEARCH • EXPERIMENT
- 25. DOMAIN: NATURAL LANGUAGE PROCESSING (APPLICATION OF ML) PROBLEMS THAT CAN BE SOLVED BY NLP :SENTENCE CLASSIFICATION :SENTENCE TO SENTENCE :LANGUAGE CONVERSION Methods :RNN, :LSTM, :GRN e H start H0 e H1 e H2 Word vector X1 X2 X3 d H3 Y1 d H4 Y2 Problems in Rnn This sequential nature. reduce the connectivity of hidden states to original inputs. Not effective when sequence length is long. Prevents parallelization within training samples Require Attention Mechanism for remembering the focused area Problems in CNN :DON’T ALLOW THE TIME SERIES CONTEXT TO FLOW. :CAN PERFORM ONE TO ONE OUTPUT Methods :RNN, :LSTM, :GRN Summary: Need attention mechanisms allow us to draw global dependencies between input and output by a constant number of operations The cat eats DIE KATZ
- 26. ATTENTION: The cat eats e H start H0 e H1 e H2 Word vector X1 X2 X3 d H3 Y1 d H4 Y2 DIE KATZ d Y2 K1 K2 . . . kn Searching key Search keys which are similar to a query, and return the corresponding values.
- 27. Proposed Transformer Architecture Input: Sequence of symbol representations (x1, x2,…, xn ) Output: Sequence of symbol representations (y1, y2,…, yn )
- 28. Attention! All you need Self Attention in Encoder Encoder decoder Attention Self Attention in Decoder
- 34. 2. FEED FORWARD LAYER
- 37. USING BEAM-SEARCH IN SELECTING MODEL PREDICTION When selecting model output, we can take the word with the highest probability and throw away the rest word candidates. : greedy decoding Another way to select model output is beam-search. beam-search Instead of only predicting the token with the best score, we keep track of k hypotheses (for example k=4, we refer to k as the beam size).
- 39. Result
- 42. THANKS YOU
Editor's Notes
- #2: Good evening, neeraj baghel, enrollment no, my project topic is
- #4: Image super-resolution aims at recovering a high-resolution image from its low-resolution counterpart. In this example we can see there is low resolution image from an cctv camera. And the Objective is to read the registration no from its number plate.
- #5: So we have find the reason of interest. Cropped , zoomed , numberplate
- #6: Then we have reconstructed the high resolution image, where we can clearly see the registration no.
- #7: So, it is a task to generate the high resolution Image It is an still active area for offering the promise of overcoming resolution limitations in many applications, such as ……... The image super-resolution task has witnessed great strides with the development of deep learning.
- #8: Motivation: Identifying the person in a low resolution image. To achieve low storage memory in mobiles and transferring low resolution images. Ob: We want to propose a novel Super-Resolution Transformer for fast and accurate image super-resolution with comparatively less computational cost and memory storage. Recent years, Transformer has made great progress in computer vision task as its strong self attention mechanism. In SISR, similar image blocks within the image can be used as reference images to each other, so that the texture details of the current image block can be restored with reference to other image blocks, which is proper to use Transformer.
- #9: Motivation: Identifying the person in a low resolution image. To achieve low storage memory in mobiles and transferring low resolution images. Ob: We want to propose a novel Super-Resolution Transformer for fast and accurate image super-resolution with comparatively less computational cost and memory storage. Recent years, Transformer has made great progress in computer vision task as its strong self attention mechanism. In this similar image blocks can be used as reference images, so that the texture details of the current image block can be restored with reference to other image blocks, which is proper to use Transformer.
- #10: Motivation: Identifying the person in a low resolution image. To achieve low storage memory in mobiles and transferring low resolution images. Ob: We want to propose a novel Super-Resolution Transformer for fast and accurate image super-resolution with comparatively less computational cost and memory storage. Recent years, Transformer has made great progress in computer vision task as its strong self attention mechanism. In SISR, similar image blocks within the image can be used as reference images to each other, so that the texture details of the current image block can be restored with reference to other image blocks, which is proper to use Transformer.
- #12: In this, On top of the texture transformer, author propose a cross-scale feature integration module (CSFI) to further enhance model performances. The proposed texture transformer. Q, K and V are the texture features extracted from an up-sampled LR image, a sequentially down/up-sampled Ref image, and an original Ref image, respectively. H and S indicate the hard/soft attention map, calculated from relevance embedding. F is the LR features extracted from a DNN backbone, and is further fused with the transferred texture features T for generating the SR output.
- #14: absolute differences between the true value and the predicted value. L1 Loss (Least Absolute Deviations) L2 Loss (Least Square Errors)
- #15: It present the overall architecture of the proposed model “Efficient SR Transformer” (ESRT). In this author present the LCB (lightweight CNN backbone) with novel high preserving block (HPB) and high-frequency filtering module (HFM). Next, author present the LTB (lightweight Transformer backbone) with an efficient Transformer (ET). Finally, it present the difference between our ESRT and other SR methods
- #16: Lightweight CNN Backbone (LCB) is built like other SR models, which served as the front part of ESRT. The function of LCB is to extract the latent SR features in advance so that the model has the initial ability of super-resolution. HPB first isolates the high-frequency information with the help of HFM. In HPB, an adaptive residual feature block (ARFB) is also introduced as the basic feature extraction unit. Firstly, an ARFB is adopted to extract the input features Fn 1 for HFM. HFM then calculates the high-frequency information (marked as Phigh) of the features. In this paper, we propose a lightweight Transformer backbone (LTB), which is composed of efficient Transformer (ET), to capture the long-term dependence of similar local regions in the image at a low computational cost.
- #18: However, previous variants of vision Transformer commonly need heavy GPU memory cost, which hinders the development of Transformer in the vision area. Extensive benchmark and real-world datasets demonstrate that our ESRT achieves the best trade-off between model performance and computation cost.
- #20: Our model is trained with the DIV2K [13] dataset, which is widely used in SISR task. DIV2K contains 800 RGB training images and 100 validation images with rich textures (2K resolution). Common evaluation dataset f for Super Resolution of images. contains various images of buildings to animal faces. The Set14 dataset is a dataset consisting of 14 images commonly used for testing performance of Image Super-Resolution models. Visual comparison for 4 scale factor on urban100 dataset and B100 dataset. For evaluation, we use five benchmark datasets to validate the effectiveness of our method, including Set5 [38], Set14 [39], B100 [40], Urban100 [41], and Manga109 [42]. Meanwhile, Peak signal-to-noise ratio (PSNR) and structure similarity index (SSIM) are used to evaluate the performance of the reconstructed SR images.
- #21: are used to evaluate the performance of the reconstructed SR images. PSNR: ratio between the maximum possible power of a signal and the power of corrupting noise