Generative Adversarial Networks : Basic architecture and variants
2 likes1,831 views
In this presentation we review the fundamentals behind GANs and look at different variants. We quickly review the theory such as the cost functions, training procedure, challenges and go on to look at variants such as CycleGAN, SAGAN etc.
1 of 20
Downloaded 71 times



















Ad
Recommended
Introduction to Generative Adversarial Networks (GANs)
Introduction to Generative Adversarial Networks (GANs)Appsilon Data Science Introduction to Generative Adversarial Networks (GANs) by Michał Maj
Full story: https://appsilon.com/satellite-imagery-generation-with-gans/
Generative adversarial networks
Generative adversarial networks남주 김 Generative Adversarial Networks (GANs) are a class of machine learning frameworks where two neural networks contest with each other in a game. A generator network generates new data instances, while a discriminator network evaluates them for authenticity, classifying them as real or generated. This adversarial process allows the generator to improve over time and generate highly realistic samples that can pass for real data. The document provides an overview of GANs and their variants, including DCGAN, InfoGAN, EBGAN, and ACGAN models. It also discusses techniques for training more stable GANs and escaping issues like mode collapse.
[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=560&fit=bounds)
[PR12] You Only Look Once (YOLO): Unified Real-Time Object DetectionTaegyun Jeon The document summarizes the You Only Look Once (YOLO) object detection method. YOLO frames object detection as a single regression problem to directly predict bounding boxes and class probabilities from full images in one pass. This allows for extremely fast detection speeds of 45 frames per second. YOLO uses a feedforward convolutional neural network to apply a single neural network to the full image. This allows it to leverage contextual information and makes predictions about bounding boxes and class probabilities for all classes with one network.
Autoencoders in Deep Learning
Autoencoders in Deep Learningmilad abbasi 1. Autoencoders are unsupervised neural networks that are useful for dimensionality reduction and clustering. They compress the input into a latent-space representation then reconstruct the output from this representation.
2. Deep autoencoders stack multiple autoencoder layers to learn hierarchical representations of the data. Each layer is trained sequentially.
3. Variational autoencoders use probabilistic encoders and decoders to learn a Gaussian latent space. They can generate new samples from the learned data distribution.
Cnn
CnnNirthika Rajendran Convolutional neural networks (CNNs) learn multi-level features and perform classification jointly and better than traditional approaches for image classification and segmentation problems. CNNs have four main components: convolution, nonlinearity, pooling, and fully connected layers. Convolution extracts features from the input image using filters. Nonlinearity introduces nonlinearity. Pooling reduces dimensionality while retaining important information. The fully connected layer uses high-level features for classification. CNNs are trained end-to-end using backpropagation to minimize output errors by updating weights.
Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs)Amol Patil Introduction to GANs
Generator & Discriminator Networks
GAN Schema / GAN Lab
Generative Models
Face Generation - Vanilla GAN, DCGAN, CoGAN, ProGAN, StyleGAN, BigGAN
Style Transfer - CGAN, pix2pix
Image to Image Translation (CycleGAN)
Video Synthesis (vid2vid, Everybody Dance Now)
Doodle to Realistic Landscape (SPADE, GauGAN)
Image Super Resolution (ISR - ESRGAN)
Colorize/Restore Images (Deoldify - NoGAN)
Generative adversarial networks
Generative adversarial networksYunjey Choi Generative Adversarial Networks (GANs) are a type of deep learning model used for unsupervised machine learning tasks like image generation. GANs work by having two neural networks, a generator and discriminator, compete against each other. The generator creates synthetic images and the discriminator tries to distinguish real images from fake ones. This allows the generator to improve over time at creating more realistic images that can fool the discriminator. The document discusses the intuition behind GANs, provides a PyTorch implementation example, and describes variants like DCGAN, LSGAN, and semi-supervised GANs.
GAN - Theory and Applications
GAN - Theory and ApplicationsEmanuele Ghelfi GANs are the new hottest topic in the ML arena; however, they present a challenge for the researchers and the engineers alike. Their design, and most importantly, the code implementation has been causing headaches to the ML practitioners, especially when moving to production.
Starting from the very basic of what a GAN is, passing trough Tensorflow implementation, using the most cutting-edge APIs available in the framework, and finally, production-ready serving at scale using Google Cloud ML Engine.
Slides for the talk: https://www.pycon.it/conference/talks/deep-diving-into-gans-form-theory-to-production
Github repo: https://github.com/zurutech/gans-from-theory-to-production
Convolutional Neural Network and Its Applications
Convolutional Neural Network and Its ApplicationsKasun Chinthaka Piyarathna In machine learning, a convolutional neural network is a class of deep, feed-forward artificial neural networks that have successfully been applied fpr analyzing visual imagery.
Generative Adversarial Networks (GAN)
Generative Adversarial Networks (GAN)Manohar Mukku This document provides an overview of generative adversarial networks (GANs). It explains that GANs were introduced in 2014 and involve two neural networks, a generator and discriminator, that compete against each other. The generator produces synthetic data to fool the discriminator, while the discriminator learns to distinguish real from synthetic data. As they train, the generator improves at producing more realistic outputs that match the real data distribution. Examples of GAN applications discussed include image generation, text-to-image synthesis, and face aging.
Convolution Neural Network (CNN)
Convolution Neural Network (CNN)Suraj Aavula The presentation is made on CNN's which is explained using the image classification problem, the presentation was prepared in perspective of understanding computer vision and its applications. I tried to explain the CNN in the most simple way possible as for my understanding. This presentation helps the beginners of CNN to have a brief idea about the architecture and different layers in the architecture of CNN with the example. Please do refer the references in the last slide for a better idea on working of CNN. In this presentation, I have also discussed the different types of CNN(not all) and the applications of Computer Vision.
Transfer Learning and Fine Tuning for Cross Domain Image Classification with ...
Transfer Learning and Fine Tuning for Cross Domain Image Classification with ...Sujit Pal Supporting code for my talk at Demystifying Deep Learning and AI event on November 19-20 2016 at Oakland CA.
Introduction to CNN
Introduction to CNNShuai Zhang The document discusses convolutional neural networks (CNNs). It begins with an introduction and overview of CNN components like convolution, ReLU, and pooling layers. Convolution layers apply filters to input images to extract features, ReLU introduces non-linearity, and pooling layers reduce dimensionality. CNNs are well-suited for image data since they can incorporate spatial relationships. The document provides an example of building a CNN using TensorFlow to classify handwritten digits from the MNIST dataset.
Deep neural networks
Deep neural networksSi Haem Deep learning and neural networks are inspired by biological neurons. Artificial neural networks (ANN) can have multiple layers and learn through backpropagation. Deep neural networks with multiple hidden layers did not work well until recent developments in unsupervised pre-training of layers. Experiments on MNIST digit recognition and NORB object recognition datasets showed deep belief networks and deep Boltzmann machines outperform other models. Deep learning is now widely used for applications like computer vision, natural language processing, and information retrieval.
Generative Adversarial Networks
Generative Adversarial NetworksMark Chang Tutorial on Generative Adversarial Networks
youtube: https://www.youtube.com/playlist?list=PLeeHDpwX2Kj5Ugx6c9EfDLDojuQxnmxmU
Loss Functions for Deep Learning - Javier Ruiz Hidalgo - UPC Barcelona 2018
Loss Functions for Deep Learning - Javier Ruiz Hidalgo - UPC Barcelona 2018Universitat Politècnica de Catalunya https://telecombcn-dl.github.io/2018-dlai/
Deep learning technologies are at the core of the current revolution in artificial intelligence for multimedia data analysis. The convergence of large-scale annotated datasets and affordable GPU hardware has allowed the training of neural networks for data analysis tasks which were previously addressed with hand-crafted features. Architectures such as convolutional neural networks, recurrent neural networks or Q-nets for reinforcement learning have shaped a brand new scenario in signal processing. This course will cover the basic principles of deep learning from both an algorithmic and computational perspectives.
Introduction to Diffusion Models
Introduction to Diffusion ModelsSangwoo Mo The document provides an introduction to diffusion models. It discusses that diffusion models have achieved state-of-the-art performance in image generation, density estimation, and image editing. Specifically, it covers the Denoising Diffusion Probabilistic Model (DDPM) which reparametrizes the reverse distributions of diffusion models to be more efficient. It also discusses the Denoising Diffusion Implicit Model (DDIM) which generates rough sketches of images and then refines them, significantly reducing the number of sampling steps needed compared to DDPM. In summary, diffusion models have emerged as a highly effective approach for generative modeling tasks.
Introduction to Autoencoders
Introduction to AutoencodersYan Xu The document provides an introduction and overview of auto-encoders, including their architecture, learning and inference processes, and applications. It discusses how auto-encoders can learn hierarchical representations of data in an unsupervised manner by compressing the input into a code and then reconstructing the output from that code. Sparse auto-encoders and stacking multiple auto-encoders are also covered. The document uses handwritten digit recognition as an example application to illustrate these concepts.
Support Vector Machines ( SVM ) 
Support Vector Machines ( SVM ) Mohammad Junaid Khan Welcome to the Supervised Machine Learning and Data Sciences.
Algorithms for building models. Support Vector Machines.
Classification algorithm explanation and code in Python ( SVM ) .
Deep Convolutional GANs - meaning of latent space
Deep Convolutional GANs - meaning of latent spaceHansol Kang DCGAN은 GAN에 단순히 conv net을 적용했을 뿐만 아니라, latent space에서도 의미를 찾음.
DCGAN 논문 리뷰 및 PyTorch 기반의 구현.
VAE 세미나 이슈 사항에 대한 리뷰.
my github : https://github.com/messy-snail/GAN_PyTorch
[참고]
https://github.com/znxlwm/pytorch-MNIST-CelebA-GAN-DCGAN
https://github.com/taeoh-kim/Pytorch_DCGAN
Radford, Alec, Luke Metz, and Soumith Chintala. "Unsupervised representation learning with deep convolutional generative adversarial networks." arXiv preprint arXiv:1511.06434 (2015).
Training Neural Networks
Training Neural NetworksDatabricks Part 2 of the Deep Learning Fundamentals Series, this session discusses Tuning Training (including hyperparameters, overfitting/underfitting), Training Algorithms (including different learning rates, backpropagation), Optimization (including stochastic gradient descent, momentum, Nesterov Accelerated Gradient, RMSprop, Adaptive algorithms - Adam, Adadelta, etc.), and a primer on Convolutional Neural Networks. The demos included in these slides are running on Keras with TensorFlow backend on Databricks.
Autoencoder
AutoencoderMehrnaz Faraz 1. Autoencoders are unsupervised neural networks that are useful for dimensionality reduction and clustering. They learn an efficient coding of the input in an unsupervised manner.
2. Deep autoencoders, also known as stacked autoencoders, are autoencoders with multiple hidden layers that can learn hierarchical representations of the data. They are trained layer-by-layer to learn increasingly higher level features.
3. Variational autoencoders are a type of autoencoder that are probabilistic models, with the encoder output being the parameters of an assumed distribution such as Gaussian. They can generate new samples from the learned distribution.
cnn ppt.pptx
cnn ppt.pptxrohithprabhas1 Convolutional neural networks (CNNs) are a type of deep neural network commonly used for analyzing visual imagery. CNNs use various techniques like convolution, ReLU activation, and pooling to extract features from images and reduce dimensionality while retaining important information. CNNs are trained end-to-end using backpropagation to update filter weights and minimize output error. Overall CNN architecture involves an input layer, multiple convolutional and pooling layers to extract features, fully connected layers to classify features, and an output layer. CNNs can be implemented using sequential models in Keras by adding layers, compiling with an optimizer and loss function, fitting on training data over epochs with validation monitoring, and evaluating performance on test data.
Deep Learning in Computer Vision
Deep Learning in Computer VisionSungjoon Choi Deep Learning in Computer Vision Applications
1. Basics on Convolutional Neural Network
2. Otimization Methods (Momentum, AdaGrad, RMSProp, Adam, etc)
3. Semantic Segmentation
4. Class Activation Map
5. Object Detection
6. Recurrent Neural Network
7. Visual Question and Answering
8. Word2Vec (Word embedding)
9. Image Captioning
Feedforward neural network
Feedforward neural networkSopheaktra YONG This slide is prepared for the lectures-in-turn challenge within the study group of social informatics, kyoto university.
Resnet
Resnetashwinjoseph95 Residual neural networks (ResNets) solve the vanishing gradient problem through shortcut connections that allow gradients to flow directly through the network. The ResNet architecture consists of repeating blocks with convolutional layers and shortcut connections. These connections perform identity mappings and add the outputs of the convolutional layers to the shortcut connection. This helps networks converge earlier and increases accuracy. Variants include basic blocks with two convolutional layers and bottleneck blocks with three layers. Parameters like number of layers affect ResNet performance, with deeper networks showing improved accuracy. YOLO is a variant that replaces the softmax layer with a 1x1 convolutional layer and logistic function for multi-label classification.
Multilayer perceptron
Multilayer perceptronomaraldabash In this study was to understand the first thing about machine learning and the multilayer perceptron.
Generative adversarial networks
Generative adversarial networksDing Li Generative Adversarial Networks (GANs) use two neural networks, a generator and discriminator, that compete against each other. The generator learns to generate fake images that look real, while the discriminator learns to tell real images apart from fakes. This document discusses various GAN architectures and applications, including conditional GANs, image-to-image translation, style transfer, semantic image editing, and data augmentation using GAN-generated images. It also covers evaluation metrics for GANs and societal impacts such as bias and deepfakes.
Vladislav Kolbasin “Introduction to Generative Adversarial Networks (GANs)”
Vladislav Kolbasin “Introduction to Generative Adversarial Networks (GANs)”Lviv Startup Club This document provides an introduction to generative adversarial networks (GANs). It begins with an agenda that covers what GANs are, applications of GANs such as image generation and inpainting, pros and cons of GANs, how to train a GAN, and example applications including face generation and lesion segmentation. GANs use two neural networks, a generator and discriminator, that compete against each other in a game theoretic framework. The generator learns to generate realistic samples to fool the discriminator, while the discriminator learns to distinguish generated from real samples.
Jakub Langr (University of Oxford) - Overview of Generative Adversarial Netwo...
Jakub Langr (University of Oxford) - Overview of Generative Adversarial Netwo...Codiax This document provides an overview of Generative Adversarial Networks (GANs) in 3 sections. It begins by briefly discussing supervised and unsupervised machine learning. It then explains that GANs use two neural networks, a generator and discriminator, that compete against each other in a game theoretic setup. The generator learns to produce more realistic samples while the discriminator learns to better distinguish real and fake samples. Popular GAN architectures like CycleGAN and BigGAN are also summarized.
Ad
More Related Content
What's hot (20)
Convolutional Neural Network and Its Applications
Convolutional Neural Network and Its ApplicationsKasun Chinthaka Piyarathna In machine learning, a convolutional neural network is a class of deep, feed-forward artificial neural networks that have successfully been applied fpr analyzing visual imagery.
Generative Adversarial Networks (GAN)
Generative Adversarial Networks (GAN)Manohar Mukku This document provides an overview of generative adversarial networks (GANs). It explains that GANs were introduced in 2014 and involve two neural networks, a generator and discriminator, that compete against each other. The generator produces synthetic data to fool the discriminator, while the discriminator learns to distinguish real from synthetic data. As they train, the generator improves at producing more realistic outputs that match the real data distribution. Examples of GAN applications discussed include image generation, text-to-image synthesis, and face aging.
Convolution Neural Network (CNN)
Convolution Neural Network (CNN)Suraj Aavula The presentation is made on CNN's which is explained using the image classification problem, the presentation was prepared in perspective of understanding computer vision and its applications. I tried to explain the CNN in the most simple way possible as for my understanding. This presentation helps the beginners of CNN to have a brief idea about the architecture and different layers in the architecture of CNN with the example. Please do refer the references in the last slide for a better idea on working of CNN. In this presentation, I have also discussed the different types of CNN(not all) and the applications of Computer Vision.
Transfer Learning and Fine Tuning for Cross Domain Image Classification with ...
Transfer Learning and Fine Tuning for Cross Domain Image Classification with ...Sujit Pal Supporting code for my talk at Demystifying Deep Learning and AI event on November 19-20 2016 at Oakland CA.
Introduction to CNN
Introduction to CNNShuai Zhang The document discusses convolutional neural networks (CNNs). It begins with an introduction and overview of CNN components like convolution, ReLU, and pooling layers. Convolution layers apply filters to input images to extract features, ReLU introduces non-linearity, and pooling layers reduce dimensionality. CNNs are well-suited for image data since they can incorporate spatial relationships. The document provides an example of building a CNN using TensorFlow to classify handwritten digits from the MNIST dataset.
Deep neural networks
Deep neural networksSi Haem Deep learning and neural networks are inspired by biological neurons. Artificial neural networks (ANN) can have multiple layers and learn through backpropagation. Deep neural networks with multiple hidden layers did not work well until recent developments in unsupervised pre-training of layers. Experiments on MNIST digit recognition and NORB object recognition datasets showed deep belief networks and deep Boltzmann machines outperform other models. Deep learning is now widely used for applications like computer vision, natural language processing, and information retrieval.
Generative Adversarial Networks
Generative Adversarial NetworksMark Chang Tutorial on Generative Adversarial Networks
youtube: https://www.youtube.com/playlist?list=PLeeHDpwX2Kj5Ugx6c9EfDLDojuQxnmxmU
Loss Functions for Deep Learning - Javier Ruiz Hidalgo - UPC Barcelona 2018
Loss Functions for Deep Learning - Javier Ruiz Hidalgo - UPC Barcelona 2018Universitat Politècnica de Catalunya https://telecombcn-dl.github.io/2018-dlai/
Deep learning technologies are at the core of the current revolution in artificial intelligence for multimedia data analysis. The convergence of large-scale annotated datasets and affordable GPU hardware has allowed the training of neural networks for data analysis tasks which were previously addressed with hand-crafted features. Architectures such as convolutional neural networks, recurrent neural networks or Q-nets for reinforcement learning have shaped a brand new scenario in signal processing. This course will cover the basic principles of deep learning from both an algorithmic and computational perspectives.
Introduction to Diffusion Models
Introduction to Diffusion ModelsSangwoo Mo The document provides an introduction to diffusion models. It discusses that diffusion models have achieved state-of-the-art performance in image generation, density estimation, and image editing. Specifically, it covers the Denoising Diffusion Probabilistic Model (DDPM) which reparametrizes the reverse distributions of diffusion models to be more efficient. It also discusses the Denoising Diffusion Implicit Model (DDIM) which generates rough sketches of images and then refines them, significantly reducing the number of sampling steps needed compared to DDPM. In summary, diffusion models have emerged as a highly effective approach for generative modeling tasks.
Introduction to Autoencoders
Introduction to AutoencodersYan Xu The document provides an introduction and overview of auto-encoders, including their architecture, learning and inference processes, and applications. It discusses how auto-encoders can learn hierarchical representations of data in an unsupervised manner by compressing the input into a code and then reconstructing the output from that code. Sparse auto-encoders and stacking multiple auto-encoders are also covered. The document uses handwritten digit recognition as an example application to illustrate these concepts.
Support Vector Machines ( SVM )
Support Vector Machines ( SVM ) Mohammad Junaid Khan Welcome to the Supervised Machine Learning and Data Sciences.
Algorithms for building models. Support Vector Machines.
Classification algorithm explanation and code in Python ( SVM ) .
Deep Convolutional GANs - meaning of latent space
Deep Convolutional GANs - meaning of latent spaceHansol Kang DCGAN은 GAN에 단순히 conv net을 적용했을 뿐만 아니라, latent space에서도 의미를 찾음.
DCGAN 논문 리뷰 및 PyTorch 기반의 구현.
VAE 세미나 이슈 사항에 대한 리뷰.
my github : https://github.com/messy-snail/GAN_PyTorch
[참고]
https://github.com/znxlwm/pytorch-MNIST-CelebA-GAN-DCGAN
https://github.com/taeoh-kim/Pytorch_DCGAN
Radford, Alec, Luke Metz, and Soumith Chintala. "Unsupervised representation learning with deep convolutional generative adversarial networks." arXiv preprint arXiv:1511.06434 (2015).
Training Neural Networks
Training Neural NetworksDatabricks Part 2 of the Deep Learning Fundamentals Series, this session discusses Tuning Training (including hyperparameters, overfitting/underfitting), Training Algorithms (including different learning rates, backpropagation), Optimization (including stochastic gradient descent, momentum, Nesterov Accelerated Gradient, RMSprop, Adaptive algorithms - Adam, Adadelta, etc.), and a primer on Convolutional Neural Networks. The demos included in these slides are running on Keras with TensorFlow backend on Databricks.
Autoencoder
AutoencoderMehrnaz Faraz 1. Autoencoders are unsupervised neural networks that are useful for dimensionality reduction and clustering. They learn an efficient coding of the input in an unsupervised manner.
2. Deep autoencoders, also known as stacked autoencoders, are autoencoders with multiple hidden layers that can learn hierarchical representations of the data. They are trained layer-by-layer to learn increasingly higher level features.
3. Variational autoencoders are a type of autoencoder that are probabilistic models, with the encoder output being the parameters of an assumed distribution such as Gaussian. They can generate new samples from the learned distribution.
cnn ppt.pptx
cnn ppt.pptxrohithprabhas1 Convolutional neural networks (CNNs) are a type of deep neural network commonly used for analyzing visual imagery. CNNs use various techniques like convolution, ReLU activation, and pooling to extract features from images and reduce dimensionality while retaining important information. CNNs are trained end-to-end using backpropagation to update filter weights and minimize output error. Overall CNN architecture involves an input layer, multiple convolutional and pooling layers to extract features, fully connected layers to classify features, and an output layer. CNNs can be implemented using sequential models in Keras by adding layers, compiling with an optimizer and loss function, fitting on training data over epochs with validation monitoring, and evaluating performance on test data.
Deep Learning in Computer Vision
Deep Learning in Computer VisionSungjoon Choi Deep Learning in Computer Vision Applications
1. Basics on Convolutional Neural Network
2. Otimization Methods (Momentum, AdaGrad, RMSProp, Adam, etc)
3. Semantic Segmentation
4. Class Activation Map
5. Object Detection
6. Recurrent Neural Network
7. Visual Question and Answering
8. Word2Vec (Word embedding)
9. Image Captioning
Feedforward neural network
Feedforward neural networkSopheaktra YONG This slide is prepared for the lectures-in-turn challenge within the study group of social informatics, kyoto university.
Resnet
Resnetashwinjoseph95 Residual neural networks (ResNets) solve the vanishing gradient problem through shortcut connections that allow gradients to flow directly through the network. The ResNet architecture consists of repeating blocks with convolutional layers and shortcut connections. These connections perform identity mappings and add the outputs of the convolutional layers to the shortcut connection. This helps networks converge earlier and increases accuracy. Variants include basic blocks with two convolutional layers and bottleneck blocks with three layers. Parameters like number of layers affect ResNet performance, with deeper networks showing improved accuracy. YOLO is a variant that replaces the softmax layer with a 1x1 convolutional layer and logistic function for multi-label classification.
Multilayer perceptron
Multilayer perceptronomaraldabash In this study was to understand the first thing about machine learning and the multilayer perceptron.
Generative adversarial networks
Generative adversarial networksDing Li Generative Adversarial Networks (GANs) use two neural networks, a generator and discriminator, that compete against each other. The generator learns to generate fake images that look real, while the discriminator learns to tell real images apart from fakes. This document discusses various GAN architectures and applications, including conditional GANs, image-to-image translation, style transfer, semantic image editing, and data augmentation using GAN-generated images. It also covers evaluation metrics for GANs and societal impacts such as bias and deepfakes.
Loss Functions for Deep Learning - Javier Ruiz Hidalgo - UPC Barcelona 2018
Loss Functions for Deep Learning - Javier Ruiz Hidalgo - UPC Barcelona 2018Universitat Politècnica de Catalunya
Similar to Generative Adversarial Networks : Basic architecture and variants (20)
Vladislav Kolbasin “Introduction to Generative Adversarial Networks (GANs)”
Vladislav Kolbasin “Introduction to Generative Adversarial Networks (GANs)”Lviv Startup Club This document provides an introduction to generative adversarial networks (GANs). It begins with an agenda that covers what GANs are, applications of GANs such as image generation and inpainting, pros and cons of GANs, how to train a GAN, and example applications including face generation and lesion segmentation. GANs use two neural networks, a generator and discriminator, that compete against each other in a game theoretic framework. The generator learns to generate realistic samples to fool the discriminator, while the discriminator learns to distinguish generated from real samples.
Jakub Langr (University of Oxford) - Overview of Generative Adversarial Netwo...
Jakub Langr (University of Oxford) - Overview of Generative Adversarial Netwo...Codiax This document provides an overview of Generative Adversarial Networks (GANs) in 3 sections. It begins by briefly discussing supervised and unsupervised machine learning. It then explains that GANs use two neural networks, a generator and discriminator, that compete against each other in a game theoretic setup. The generator learns to produce more realistic samples while the discriminator learns to better distinguish real and fake samples. Popular GAN architectures like CycleGAN and BigGAN are also summarized.
DiscoGAN
DiscoGANIl Gu Yi This document summarizes the DiscoGAN model, which uses generative adversarial networks to discover relations between image domains without paired training examples. It introduces GANs and the DiscoGAN model, which uses two generators and discriminators with reconstruction and adversarial losses to learn bijective mappings between domains. Experiments show DiscoGAN can discover relations like azimuth angle between car images and translate attributes like gender between faces while maintaining other features. Code links for TensorFlow and PyTorch implementations are also provided.
Cahall Final Intern Presentation
Cahall Final Intern PresentationDaniel Cahall The document proposes improving object detection and recognition capabilities. It discusses challenges with current methods like different object sizes and color variations. The objectives are to build a module that can learn and detect objects without a sliding box or datastore. A high-level design approach is outlined using techniques like contouring, BING, sliding box, and feature selection methods. The design considers optimal feature selection, dimensionality reduction, and classification algorithms to function in real-time.
20200322 inpainting
20200322 inpaintingX 37 This document summarizes several image inpainting methods using GANs. It describes the task of image inpainting, common GAN architectures used for inpainting including conditional GANs, and several state-of-the-art models such as Partial Convolution, GLCIC, Contextual Attention, Gated Convolution, PEPSI, and PEPSI++. It also includes background information on techniques like dilated convolution, PatchGAN, cycleGAN, and WGAN used in image inpainting.
Volodymyr Lyubinets “Generative models for images”
Volodymyr Lyubinets “Generative models for images”Lviv Startup Club Generative models for images can generate new samples from a target distribution or with particular properties. Variational autoencoders use an encoder to compress inputs into a latent representation and a decoder to reconstruct the input from that representation. Generative adversarial networks use a generator and discriminator that compete, with the generator trying to generate realistic samples and the discriminator trying to distinguish real from generated samples. CycleGAN uses GANs with cycle consistency to translate between image domains without paired data. Recent research includes Fader Networks for attribute transfer and semi-parametric image synthesis that reuses patterns from training data to generate new images conditioned on a semantic layout.
Distributed deep learning
Distributed deep learningAlireza Shafaei The document discusses strategies for distributed deep learning including data and model parallelism as well as synchronous and asynchronous optimization. It outlines challenges such as communication overhead, long-tail latency, and programming barriers. It then summarizes several papers that improved the speed of training on ImageNet through techniques like larger batch sizes, model distillation, and gradient compression. The conclusion notes that while scaling has limitations due to infrastructure and optimization barriers, asynchronous methods and gradient compression can help address communication overhead.
Volodymyr Lyubinets: Аналіз супутникових зображень: визначаємо параметри буді...
Volodymyr Lyubinets: Аналіз супутникових зображень: визначаємо параметри буді...Lviv Startup Club Volodymyr Lyubinets: Аналіз супутникових зображень: визначаємо параметри будівель з моделями сегментації (UA)
AI & BigData Online Day 2025 Spring
Website – https://aiconf.com.ua
Youtube – https://www.youtube.com/startuplviv
FB – https://www.facebook.com/aiconf/
Unpaired Image Translations Using GANs: A Review
Unpaired Image Translations Using GANs: A ReviewIRJET Journal This document reviews recent research on unpaired image translation using Generative Adversarial Networks (GANs). It discusses CycleGAN, an approach for unpaired image-to-image translation using two GANs and cycle consistency. The document reviews several papers applying CycleGAN and related methods to tasks like horse to zebra translation, summer to winter, and medical imaging. It finds CycleGAN often succeeds at color and texture changes but struggles with geometric transformations. Improving complex translations, especially geometry, remains a challenge.
Reading group gan - 20170417
Reading group gan - 20170417Shuai Zhang Generative Adversarial Networks (GANs) are a type of generative model that uses two neural networks - a generator and discriminator - competing against each other. The generator takes noise as input and generates synthetic samples, while the discriminator evaluates samples as real or generated. They are trained together until the generator fools the discriminator. GANs can generate realistic images, do image-to-image translation, and have applications in reinforcement learning. However, training GANs is challenging due to issues like non-convergence and mode collapse.
Large-scale Recommendation Systems on Just a PC
Large-scale Recommendation Systems on Just a PCAapo Kyrölä Aapo Kyrölä presented on running large-scale recommender systems on a single PC using GraphChi, a framework for graph computation on disk. GraphChi uses parallel sliding windows to efficiently process graphs that do not fit in memory by only loading subsets of the graph into RAM at a time. Kyrölä demonstrated training recommender models like ALS matrix factorization and item-based collaborative filtering on large graphs like Twitter using GraphChi on a single laptop. He concluded that very large recommender algorithms can now be run on a single machine and that GraphChi and similar frameworks hide the low-level optimizations needed for efficient single machine graph computation.
brief Introduction to Different Kinds of GANs
brief Introduction to Different Kinds of GANsParham Zilouchian Generative adversarial networks (GANs) are introduced, including the basic GAN framework containing a generator and discriminator. Various types of GANs are then discussed, such as DCGANs, semi-supervised GANs, and character GANs. The document concludes with a summary of resources on GANs and applications such as image-to-image translation and conditional waveform synthesis.
gan.pdf
gan.pdfDr.rukmani Devi Generative Adversarial Networks (GANs) are a class of deep learning models that are trained using an adversarial process. GANs consist of two neural networks, a generator and a discriminator, that compete against each other. The generator tries to generate new samples from a latent space to fool the discriminator, while the discriminator tries to distinguish real samples from fake ones. GANs can learn complex high-dimensional distributions and have been applied to image generation, video generation, and other domains. However, training GANs is challenging due to issues like non-convergence and mode collapse. Recent work has explored techniques like minibatch discrimination, conditional GANs, and unrolled GANs to help address these training issues.
Deep Generative Models - Kevin McGuinness - UPC Barcelona 2018
Deep Generative Models - Kevin McGuinness - UPC Barcelona 2018Universitat Politècnica de Catalunya https://telecombcn-dl.github.io/2018-dlcv/
Deep learning technologies are at the core of the current revolution in artificial intelligence for multimedia data analysis. The convergence of large-scale annotated datasets and affordable GPU hardware has allowed the training of neural networks for data analysis tasks which were previously addressed with hand-crafted features. Architectures such as convolutional neural networks, recurrent neural networks and Q-nets for reinforcement learning have shaped a brand new scenario in signal processing. This course will cover the basic principles and applications of deep learning to computer vision problems, such as image classification, object detection or image captioning.
Generative Adversarial Network (GAN) for Image Synthesis
Generative Adversarial Network (GAN) for Image SynthesisRiwaz Mahat This is a short yet informative presentation on one of the most popular machine learning model Generative Adversarial Network (GAN).
ExplainingMLModels.pdf
ExplainingMLModels.pdfLHong526661 Integrated Gradients provides a method for attributing the predictions of machine learning models to features of the input. It works by calculating the gradient of the model output with respect to the input across all points along the linear path between a baseline input and the actual input. This path integral attribution method satisfies several desirable properties. Integrated Gradients can be used for applications like generating explanations, debugging models, and analyzing model robustness.
Weave-D - 2nd Progress Evaluation Presentation
Weave-D - 2nd Progress Evaluation Presentationlasinducharith Weave-D is a cognitive system that accumulates and fuses temporal, multi-modal data in an organized manner. It extracts features from images and text, learns incrementally using the IKASL algorithm, and generates links between data. The system aims to handle large amounts of information and prevent catastrophic interference during incremental learning. It will extract color, edge, and shape features from images and use text feature extraction techniques. Unsupervised learning algorithms like SOM, GSOM, and IKASL will be implemented and visualized.
Generative Adversarial Networks and Their Applications in Medical Imaging
Generative Adversarial Networks and Their Applications in Medical ImagingSanghoon Hong 의료 인공지능 교육 워크샵 (17.09.16) 발표자료
- Generative Adversarial Network에 대한 소개
- Medical imaging 분야에서의 연구 사례
- Our research
Deep Generative Modelling
Deep Generative ModellingPetko Nikolov This document provides an overview of deep generative models for images. It discusses generative adversarial networks (GANs) which define generative modeling as an adversarial game between a generator and discriminator. Conditional GANs can generate images from text or translate between image domains. Variational autoencoders (VAEs) learn latent representations of the data. Fully convolutional models use transposed convolutions in the decoder. CycleGAN can perform unpaired image-to-image translation using cycle consistency losses. Overall, generative models aim to understand data distributions in order to generate new, realistic samples.
Brief introduction on GAN
Brief introduction on GANDai-Hai Nguyen This document discusses generative adversarial networks (GANs) and their applications. It begins with an overview of generative models including variational autoencoders and GANs. GANs use two neural networks, a generator and discriminator, that compete against each other in a game theoretic framework. The generator learns to generate fake samples to fool the discriminator, while the discriminator learns to distinguish real and fake samples. Applications discussed include image-to-image translation using conditional GANs to map images from one domain to another, and text-to-image translation using GANs to generate images from text descriptions.
Ad
More from ananth (20)
Convolutional Neural Networks : Popular Architectures
Convolutional Neural Networks : Popular Architecturesananth In this presentation we look at some of the popular architectures, such as ResNet, that have been successfully used for a variety of applications. Starting from the AlexNet and VGG that showed that the deep learning architectures can deliver unprecedented accuracies for Image classification and localization tasks, we review other recent architectures such as ResNet, GoogleNet (Inception) and the more recent SENet that have won ImageNet competitions.
Foundations: Artificial Neural Networks
Foundations: Artificial Neural Networksananth Artificial Neural Networks have been very successfully used in several machine learning applications. They are often the building blocks when building deep learning systems. We discuss the hypothesis, training with backpropagation, update methods, regularization techniques.
Overview of Convolutional Neural Networks
Overview of Convolutional Neural Networksananth In this presentation we discuss the convolution operation, the architecture of a convolution neural network, different layers such as pooling etc. This presentation draws heavily from A Karpathy's Stanford Course CS 231n
Artificial Intelligence Course: Linear models 
Artificial Intelligence Course: Linear models ananth In this presentation we present the linear models: Regression and Classification. We illustrate with several examples. Concepts such as underfitting (Bias) and overfitting (Variance) are presented. Linear models can be used as stand alone classifiers for simple cases and they are essential building blocks as a part of larger deep learning networks
An Overview of Naïve Bayes Classifier 
An Overview of Naïve Bayes Classifier ananth Naive Bayes Classifier is a machine learning technique that is exceedingly useful to address several classification problems. It is often used as a baseline classifier to benchmark results. It is also used as a standalone classifier for tasks such as spam filtering where the naive assumption (conditional independence) made by the classifier seem reasonable. In this presentation we discuss the mathematical basis for the Naive Bayes and illustrate with examples
Mathematical Background for Artificial Intelligence
Mathematical Background for Artificial Intelligenceananth Mathematical background is essential for understanding and developing AI and Machine Learning applications. In this presentation we give a brief tutorial that encompasses basic probability theory, distributions, mixture models, anomaly detection, graphical representations such as Bayesian Networks, etc.
Search problems in Artificial Intelligence
Search problems in Artificial Intelligenceananth This presentation discusses the state space problem formulation and different search techniques to solve these. Techniques such as Breadth First, Depth First, Uniform Cost and A star algorithms are covered with examples. We also discuss where such techniques are useful and the limitations.
Introduction to Artificial Intelligence
Introduction to Artificial Intelligenceananth This is the first lecture of the AI course offered by me at PES University, Bangalore. In this presentation we discuss the different definitions of AI, the notion of Intelligent Agents, distinguish an AI program from a complex program such as those that solve complex calculus problems (see the integration example) and look at the role of Machine Learning and Deep Learning in the context of AI. We also go over the course scope and logistics.
Word representation: SVD, LSA, Word2Vec
Word representation: SVD, LSA, Word2Vecananth In this presentation we discuss several concepts that include Word Representation using SVD as well as neural networks based techniques. In addition we also cover core concepts such as cosine similarity, atomic and distributed representations.
Deep Learning For Speech Recognition
Deep Learning For Speech Recognitionananth Deep Learning techniques have enabled exciting novel applications. Recent advances hold lot of promise for speech based applications that include synthesis and recognition. This slideset is a brief overview that presents a few architectures that are the state of the art in contemporary speech research. These slides are brief because most concepts/details were covered using the blackboard in a classroom setting. These slides are meant to supplement the lecture.
Overview of TensorFlow For Natural Language Processing
Overview of TensorFlow For Natural Language Processingananth TensorFlow open sourced recently by Google is one of the key frameworks that support development of deep learning architectures. In this slideset, part 1, we get started with a few basic primitives of TensorFlow. We will also discuss when and when not to use TensorFlow.
Convolutional Neural Networks: Part 1
Convolutional Neural Networks: Part 1ananth Convolutional neural networks (CNNs) are better suited than traditional neural networks for processing image data due to properties of images. CNNs apply filters with local receptive fields and shared weights across the input, allowing them to detect features regardless of position. A CNN architecture consists of convolutional layers that apply filters, and pooling layers for downsampling. This reduces parameters and allows the network to learn representations of the input with minimal feature engineering.
Machine Learning Lecture 3 Decision Trees
Machine Learning Lecture 3 Decision Treesananth This presentation discusses decision trees as a machine learning technique. This introduces the problem with several examples: cricket player selection, medical C-Section diagnosis and Mobile Phone price predictor. It discusses the ID3 algorithm and discusses how the decision tree is induced. The definition and use of the concepts such as Entropy, Information Gain are discussed.
Machine Learning Lecture 2 Basics
Machine Learning Lecture 2 Basicsananth This presentation is a part of ML Course and this deals with some of the basic concepts such as different types of learning, definitions of classification and regression, decision surfaces etc. This slide set also outlines the Perceptron Learning algorithm as a starter to other complex models to follow in the rest of the course.
Introduction To Applied Machine Learning
Introduction To Applied Machine Learningananth This is the first lecture on Applied Machine Learning. The course focuses on the emerging and modern aspects of this subject such as Deep Learning, Recurrent and Recursive Neural Networks (RNN), Long Short Term Memory (LSTM), Convolution Neural Networks (CNN), Hidden Markov Models (HMM). It deals with several application areas such as Natural Language Processing, Image Understanding etc. This presentation provides the landscape.
Recurrent Neural Networks, LSTM and GRU
Recurrent Neural Networks, LSTM and GRUananth Recurrent Neural Networks have shown to be very powerful models as they can propagate context over several time steps. Due to this they can be applied effectively for addressing several problems in Natural Language Processing, such as Language Modelling, Tagging problems, Speech Recognition etc. In this presentation we introduce the basic RNN model and discuss the vanishing gradient problem. We describe LSTM (Long Short Term Memory) and Gated Recurrent Units (GRU). We also discuss Bidirectional RNN with an example. RNN architectures can be considered as deep learning systems where the number of time steps can be considered as the depth of the network. It is also possible to build the RNN with multiple hidden layers, each having recurrent connections from the previous time steps that represent the abstraction both in time and space.
MaxEnt (Loglinear) Models - Overview
MaxEnt (Loglinear) Models - Overviewananth In this presentation we discuss the hypothesis of MaxEnt models, describe the role of feature functions and their applications to Natural Language Processing (NLP). The training of the classifier is discussed in a later presentation.
An overview of Hidden Markov Models (HMM)
An overview of Hidden Markov Models (HMM)ananth In this presentation we describe the formulation of the HMM model as consisting of states that are hidden that generate the observables. We introduce the 3 basic problems: Finding the probability of a sequence of observation given the model, the decoding problem of finding the hidden states given the observations and the model and the training problem of determining the model parameters that generate the given observations. We discuss the Forward, Backward, Viterbi and Forward-Backward algorithms.
L06 stemmer and edit distance
L06 stemmer and edit distanceananth Discusses the edit distance concepts, applications and the algorithms to compute the minimum edit distance with an example.
L05 language model_part2
L05 language model_part2ananth Discusses the concept of Language Models in Natural Language Processing. The n-gram models, markov chains are discussed. Smoothing techniques such as add-1 smoothing, interpolation and discounting methods are addressed.
Ad
Recently uploaded (20)
Adobe Master Collection CC Crack Advance Version 2025
Adobe Master Collection CC Crack Advance Version 2025kashifyounis067 🌍📱👉COPY LINK & PASTE ON GOOGLE http://drfiles.net/ 👈🌍
Adobe Master Collection CC (Creative Cloud) is a comprehensive subscription-based package that bundles virtually all of Adobe's creative software applications. It provides access to a wide range of tools for graphic design, video editing, web development, photography, and more. Essentially, it's a one-stop-shop for creatives needing a broad set of professional tools.
Key Features and Benefits:
All-in-one access:
The Master Collection includes apps like Photoshop, Illustrator, InDesign, Premiere Pro, After Effects, Audition, and many others.
Subscription-based:
You pay a recurring fee for access to the latest versions of all the software, including new features and updates.
Comprehensive suite:
It offers tools for a wide variety of creative tasks, from photo editing and illustration to video editing and web development.
Cloud integration:
Creative Cloud provides cloud storage, asset sharing, and collaboration features.
Comparison to CS6:
While Adobe Creative Suite 6 (CS6) was a one-time purchase version of the software, Adobe Creative Cloud (CC) is a subscription service. CC offers access to the latest versions, regular updates, and cloud integration, while CS6 is no longer updated.
Examples of included software:
Adobe Photoshop: For image editing and manipulation.
Adobe Illustrator: For vector graphics and illustration.
Adobe InDesign: For page layout and desktop publishing.
Adobe Premiere Pro: For video editing and post-production.
Adobe After Effects: For visual effects and motion graphics.
Adobe Audition: For audio editing and mixing.
Societal challenges of AI: biases, multilinguism and sustainability
Societal challenges of AI: biases, multilinguism and sustainabilityJordi Cabot Towards a fairer, inclusive and sustainable AI that works for everybody.
Reviewing the state of the art on these challenges and what we're doing at LIST to test current LLMs and help you select the one that works best for you
Interactive odoo dashboards for sales, CRM , Inventory, Invoice, Purchase, Pr...
Interactive odoo dashboards for sales, CRM , Inventory, Invoice, Purchase, Pr...AxisTechnolabs Interactive Odoo Dashboard for various business needs can provide users with dynamic, visually appealing dashboards tailored to their specific requirements. such a module that could support multiple dashboards for different aspects of a business
✅Visit And Buy Now : https://bit.ly/3VojWza
✅This Interactive Odoo dashboard module allow user to create their own odoo interactive dashboards for various purpose.
App download now :
Odoo 18 : https://bit.ly/3VojWza
Odoo 17 : https://bit.ly/4h9Z47G
Odoo 16 : https://bit.ly/3FJTEA4
Odoo 15 : https://bit.ly/3W7tsEB
Odoo 14 : https://bit.ly/3BqZDHg
Odoo 13 : https://bit.ly/3uNMF2t
Try Our website appointment booking odoo app : https://bit.ly/3SvNvgU
👉Want a Demo ?📧 [email protected]
➡️Contact us for Odoo ERP Set up : 091066 49361
👉Explore more apps: https://bit.ly/3oFIOCF
👉Want to know more : 🌐 https://www.axistechnolabs.com/
#odoo #odoo18 #odoo17 #odoo16 #odoo15 #odooapps #dashboards #dashboardsoftware #odooerp #odooimplementation #odoodashboardapp #bestodoodashboard #dashboardapp #odoodashboard #dashboardmodule #interactivedashboard #bestdashboard #dashboard #odootag #odooservices #odoonewfeatures #newappfeatures #odoodashboardapp #dynamicdashboard #odooapp #odooappstore #TopOdooApps #odooapp #odooexperience #odoodevelopment #businessdashboard #allinonedashboard #odooproducts
The Significance of Hardware in Information Systems.pdf
The Significance of Hardware in Information Systems.pdfdrewplanas10 The Significance of Hardware in Information Systems: The Types Of Hardware and What They Do
FL Studio Producer Edition Crack 2025 Full Version
FL Studio Producer Edition Crack 2025 Full Versiontahirabibi60507 Copy & Past Link 👉👉
http://drfiles.net/
FL Studio is a Digital Audio Workstation (DAW) software used for music production. It's developed by the Belgian company Image-Line. FL Studio allows users to create and edit music using a graphical user interface with a pattern-based music sequencer.
Kubernetes_101_Zero_to_Platform_Engineer.pptx
Kubernetes_101_Zero_to_Platform_Engineer.pptxCloudScouts Presentacion de la primera sesion de Zero to Platform Engineer
Solidworks Crack 2025 latest new + license code
Solidworks Crack 2025 latest new + license codeaneelaramzan63 Copy & Paste On Google >>> https://dr-up-community.info/
The two main methods for installing standalone licenses of SOLIDWORKS are clean installation and parallel installation (the process is different ...
Disable your internet connection to prevent the software from performing online checks during installation
Automation Techniques in RPA - UiPath Certificate
Automation Techniques in RPA - UiPath CertificateVICTOR MAESTRE RAMIREZ Automation Techniques in RPA - UiPath Certificate
Who Watches the Watchmen (SciFiDevCon 2025)
Who Watches the Watchmen (SciFiDevCon 2025)Allon Mureinik Tests, especially unit tests, are the developers’ superheroes. They allow us to mess around with our code and keep us safe.
We often trust them with the safety of our codebase, but how do we know that we should? How do we know that this trust is well-deserved?
Enter mutation testing – by intentionally injecting harmful mutations into our code and seeing if they are caught by the tests, we can evaluate the quality of the safety net they provide. By watching the watchmen, we can make sure our tests really protect us, and we aren’t just green-washing our IDEs to a false sense of security.
Talk from SciFiDevCon 2025
https://www.scifidevcon.com/courses/2025-scifidevcon/contents/680efa43ae4f5
Not So Common Memory Leaks in Java Webinar
Not So Common Memory Leaks in Java WebinarTier1 app This SlideShare presentation is from our May webinar, “Not So Common Memory Leaks & How to Fix Them?”, where we explored lesser-known memory leak patterns in Java applications. Unlike typical leaks, subtle issues such as thread local misuse, inner class references, uncached collections, and misbehaving frameworks often go undetected and gradually degrade performance. This deck provides in-depth insights into identifying these hidden leaks using advanced heap analysis and profiling techniques, along with real-world case studies and practical solutions. Ideal for developers and performance engineers aiming to deepen their understanding of Java memory management and improve application stability.
How can one start with crypto wallet development.pptx
How can one start with crypto wallet development.pptxlaravinson24 This presentation is a beginner-friendly guide to developing a crypto wallet from scratch. It covers essential concepts such as wallet types, blockchain integration, key management, and security best practices. Ideal for developers and tech enthusiasts looking to enter the world of Web3 and decentralized finance.
How to Batch Export Lotus Notes NSF Emails to Outlook PST Easily?
How to Batch Export Lotus Notes NSF Emails to Outlook PST Easily?steaveroggers Migrating from Lotus Notes to Outlook can be a complex and time-consuming task, especially when dealing with large volumes of NSF emails. This presentation provides a complete guide on how to batch export Lotus Notes NSF emails to Outlook PST format quickly and securely. It highlights the challenges of manual methods, the benefits of using an automated tool, and introduces eSoftTools NSF to PST Converter Software — a reliable solution designed to handle bulk email migrations efficiently. Learn about the software’s key features, step-by-step export process, system requirements, and how it ensures 100% data accuracy and folder structure preservation during migration. Make your email transition smoother, safer, and faster with the right approach.
Read More:- https://www.esofttools.com/nsf-to-pst-converter.html
Meet the Agents: How AI Is Learning to Think, Plan, and Collaborate
Meet the Agents: How AI Is Learning to Think, Plan, and CollaborateMaxim Salnikov Imagine if apps could think, plan, and team up like humans. Welcome to the world of AI agents and agentic user interfaces (UI)! In this session, we'll explore how AI agents make decisions, collaborate with each other, and create more natural and powerful experiences for users.
Exploring Wayland: A Modern Display Server for the Future
Exploring Wayland: A Modern Display Server for the FutureICS Wayland is revolutionizing the way we interact with graphical interfaces, offering a modern alternative to the X Window System. In this webinar, we’ll delve into the architecture and benefits of Wayland, including its streamlined design, enhanced performance, and improved security features.
Why Orangescrum Is a Game Changer for Construction Companies in 2025
Why Orangescrum Is a Game Changer for Construction Companies in 2025Orangescrum Orangescrum revolutionizes construction project management in 2025 with real-time collaboration, resource planning, task tracking, and workflow automation, boosting efficiency, transparency, and on-time project delivery.
Avast Premium Security Crack FREE Latest Version 2025
Avast Premium Security Crack FREE Latest Version 2025mu394968 🌍📱👉COPY LINK & PASTE ON GOOGLE https://dr-kain-geera.info/👈🌍
Avast Premium Security is a paid subscription service that provides comprehensive online security and privacy protection for multiple devices. It includes features like antivirus, firewall, ransomware protection, and website scanning, all designed to safeguard against a wide range of online threats, according to Avast.
Key features of Avast Premium Security:
Antivirus: Protects against viruses, malware, and other malicious software, according to Avast.
Firewall: Controls network traffic and blocks unauthorized access to your devices, as noted by All About Cookies.
Ransomware protection: Helps prevent ransomware attacks, which can encrypt your files and hold them hostage.
Website scanning: Checks websites for malicious content before you visit them, according to Avast.
Email Guardian: Scans your emails for suspicious attachments and phishing attempts.
Multi-device protection: Covers up to 10 devices, including Windows, Mac, Android, and iOS, as stated by 2GO Software.
Privacy features: Helps protect your personal data and online privacy.
In essence, Avast Premium Security provides a robust suite of tools to keep your devices and online activity safe and secure, according to Avast.
Microsoft AI Nonprofit Use Cases and Live Demo_2025.04.30.pdf
Microsoft AI Nonprofit Use Cases and Live Demo_2025.04.30.pdfTechSoup In this webinar we will dive into the essentials of generative AI, address key AI concerns, and demonstrate how nonprofits can benefit from using Microsoft’s AI assistant, Copilot, to achieve their goals.
This event series to help nonprofits obtain Copilot skills is made possible by generous support from Microsoft.
What You’ll Learn in Part 2:
Explore real-world nonprofit use cases and success stories.
Participate in live demonstrations and a hands-on activity to see how you can use Microsoft 365 Copilot in your own work!
EASEUS Partition Master Crack + License Code
EASEUS Partition Master Crack + License Codeaneelaramzan63 Copy & Paste On Google >>> https://dr-up-community.info/
EASEUS Partition Master Final with Crack and Key Download If you are looking for a powerful and easy-to-use disk partitioning software,
Download YouTube By Click 2025 Free Full Activated
Download YouTube By Click 2025 Free Full Activatedsaniamalik72555 Copy & Past Link 👉👉
https://dr-up-community.info/
"YouTube by Click" likely refers to the ByClick Downloader software, a video downloading and conversion tool, specifically designed to download content from YouTube and other video platforms. It allows users to download YouTube videos for offline viewing and to convert them to different formats.
Adobe Illustrator Crack FREE Download 2025 Latest Version
Adobe Illustrator Crack FREE Download 2025 Latest Versionkashifyounis067 🌍📱👉COPY LINK & PASTE ON GOOGLE http://drfiles.net/ 👈🌍
Adobe Illustrator is a powerful, professional-grade vector graphics software used for creating a wide range of designs, including logos, icons, illustrations, and more. Unlike raster graphics (like photos), which are made of pixels, vector graphics in Illustrator are defined by mathematical equations, allowing them to be scaled up or down infinitely without losing quality.
Here's a more detailed explanation:
Key Features and Capabilities:
Vector-Based Design:
Illustrator's foundation is its use of vector graphics, meaning designs are created using paths, lines, shapes, and curves defined mathematically.
Scalability:
This vector-based approach allows for designs to be resized without any loss of resolution or quality, making it suitable for various print and digital applications.
Design Creation:
Illustrator is used for a wide variety of design purposes, including:
Logos and Brand Identity: Creating logos, icons, and other brand assets.
Illustrations: Designing detailed illustrations for books, magazines, web pages, and more.
Marketing Materials: Creating posters, flyers, banners, and other marketing visuals.
Web Design: Designing web graphics, including icons, buttons, and layouts.
Text Handling:
Illustrator offers sophisticated typography tools for manipulating and designing text within your graphics.
Brushes and Effects:
It provides a range of brushes and effects for adding artistic touches and visual styles to your designs.
Integration with Other Adobe Software:
Illustrator integrates seamlessly with other Adobe Creative Cloud apps like Photoshop, InDesign, and Dreamweaver, facilitating a smooth workflow.
Why Use Illustrator?
Professional-Grade Features:
Illustrator offers a comprehensive set of tools and features for professional design work.
Versatility:
It can be used for a wide range of design tasks and applications, making it a versatile tool for designers.
Industry Standard:
Illustrator is a widely used and recognized software in the graphic design industry.
Creative Freedom:
It empowers designers to create detailed, high-quality graphics with a high degree of control and precision.
Generative Adversarial Networks : Basic architecture and variants
- 1. Generative Adversarial Networks Palacode Narayana Iyer Anantharaman 29 Oct 2018
- 2. References • https://github.com/lukedeo/keras-acgan/blob/master/acgan-analysis.ipynb • https://github.com/keras-team/keras/blob/master/examples/mnist_acgan.py • https://skymind.ai/wiki/generative-adversarial-network-gan • https://junyanz.github.io/CycleGAN/ • Self Attention Generative Adversarial Networks: Zhang et al
- 3. Why GAN? • GANs can learn to mimic any distribution and generate data • The data may be images, speech or music • The outputs from GANs are found to be quite realistic and impressive • Thus, GANs have a number of applications: From being a feature in products like Photoshop to generating synthetic datasets for image augmentation
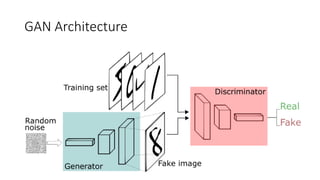
- 6. GAN Workflow
- 7. Generator • Generates synthetic images given the input noise z • G is differentiable • Typically a Gaussian distribution
- 8. Training • Train on 2 mini batches simultaneously • Training samples • Generated samples • Cost
- 10. Different Variants of GAN Ref: https://github.com/lukedeo/keras-acgan/blob/master/acgan-analysis.ipynb
- 11. Cycle GAN (2017) • Original Paper: “Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks”, Zhu et al
- 12. Image to Image Translation • Image to image translation is aimed at finding a mapping between an input image (X) and its corresponding output image (Y), where the pair X, Y are provided in the dataset • This assumes that we are provided with such a labelled dataset with pairings • CycleGAN attempts to find a mapping between images from source and target domains in the absence of paired examples Learn G: X → Y such that the distribution of images from G(X) is indistinguishable from the distribution Y using an adversarial loss. Couple this with an inverse mapping F: Y → X and enforce a cycle consistency loss to enforce F(G(X)) ≈ X
- 14. Cycle GAN: Objective Function • Two discriminators: Dx and Dy where Dx aims to distinguish between images {x} and translated images {F(y)}. In the same way Dy aims to discriminate between {y} and {G(x)} • The objective function has 2 parts representing the losses: • adversarial losses for matching the distribution of generated images to the data distribution in the target domain • Cycle consistency losses that prevent the learned mappings G and F from contradicting each other
- 15. Losses
- 16. Exercises • Go through the original paper and answer the following: • How is the model evaluated? What are the metrics? • What are the main applications discussed in the paper? • What are the limitations and future work?
- 17. SAGAN (2018) Zhang et al Abstract • GANs often use a CNN as a generator • CNNs capture short range dependencies very well (local receptive fields) but not effective to capture long distance correlations • Self Attention Generative Adversarial Networks (SAGAN) is aimed at generating images that take in to account both short and long distance dependencies in the source images
- 18. SAGAN