Generative Artificial Intelligence and Large Language Model

Natural Language Processing (NLP) is a discipline dedicated to enabling computers to comprehend and generate human language. Word embedding is a technique in NLP that converts words into dense numerical vectors, capturing their semantic meanings and contextual relationships. Analyzing sequential data often requires techniques such as time series analysis and sequence modeling, using machine learning models like Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs). Encoder-Decoder architecture is an RNN framework designed for sequence-to-sequence tasks. Beam Search is a search algorithm used in sequence-to-sequence models, particularly in natural language processing tasks. BLEU is a popular evaluation metric for assessing the quality of text generated by machine translation systems. Attention mechanism allows models to selectively focus on the most relevant information within large datasets, thereby enhancing efficiency and accuracy in data processing.

























































More Related Content
Similar to Generative Artificial Intelligence and Large Language Model (20)
More from Shiwani Gupta (20)

















Recently uploaded (20)




















Generative Artificial Intelligence and Large Language Model
- 1. Generative AI and LLM Dr. Shiwani Gupta Associate Professor, HoD AI&ML TCET, Mumbai
- 2. NLP Natural Language Processing (NLP) is a discipline dedicated to enabling computers to comprehend and generate human language. It encompasses tasks such as language translation, sentiment analysis, and text summarization. By employing algorithms and models to process and analyze text, NLP allows computers to derive meaning and execute language-based functions. This technology has a wide range of applications across different industries, significantly enhancing communication and information retrieval. Unstructured (Text) data in form of email, blog, news… Social Media platforms: twitter, FB, Quora Sentiments (product, app, movie, service) Social media platforms and chatbot applications to reach out to customers
- 3. Difficult to learn Right as ‘ryt’, How are you as ‘hru’ NLP really a hard problem to solve
- 4. NLP Applications • From customer service chatbots to language translation apps • healthcare, finance, and education • By allowing machines to extract meaning, analyze sentiments, and summarize text, NLP has revolutionized communication, making it an essential technology in our increasingly interconnected world. Opinion, feeling, emotions Feedback, Comment, rating, like Amazon, Flipkart Product/Service Intent Analysis Digital medium over IVR or customer call center Complaint, opinion, comment, statement, feedback, query, suggestion Automated ticketing system Extract info from resume, financial attributes, events from news for trading
- 5. NLP Applications Automated Text generation Q&A system Text to speech and vice versa Topic Modeling Word to word to sentences Employee engagement Obtain transactional info From bounded Qs to responses to free text in multiple languages Auto response Difficult to get prev context Incorrect sentence leads to negative publicity or legal complications News Extract important Rewrite whole article capturing context
- 6. Tokenization • Tokenization in NLP involves breaking text into smaller units, such as words or characters, for analysis. • It serves as the foundation for tasks like part-of-speech tagging and sentiment analysis. • This process entails removing punctuation, splitting words, and addressing special cases to create tokens. • Preprocessing: STOP WORD REMOVAL, STEMMING, LEMMATIZATION • NLTK, Spacy packages Preposition, joining word, conjunction Inflectional form to base form
- 7. Numericalization • Numericalization in NLP involves transforming text data into numerical formats that machine learning algorithms can interpret and process. This conversion enables NLP models to handle and analyze text through mathematical operations. Bag of word Model – One Hot Encoding Weight is 1 irrespective of freq of word
- 8. Word Embedding Word embedding is a technique in NLP that converts words into dense numerical vectors, capturing their semantic meanings and contextual relationships. Unlike traditional methods that use sparse representations, word embeddings provide a more compact and informative representation of words. This approach enables NLP models to understand and interpret language more effectively, as it incorporates nuances of word meanings and their usage in different contexts. By leveraging word embeddings, models can perform complex tasks such as measuring word similarity, identifying relationships between words, and enhancing context-aware operations, leading to improved language understanding and application.
- 9. Learning word embeddings involves using algorithms like Word2Vec and GloVe to train models that generate dense vector representations of words, capturing their semantic and contextual relationships. These embeddings are created by analyzing large corpora of text data, which allows the model to understand word meanings and their usage in various contexts. The resulting embeddings offer a rich, nuanced representation of words, significantly improving performance on diverse NLP tasks such as word similarity, context understanding, and language generation. By leveraging these embeddings, NLP models can achieve more accurate and meaningful interpretations of language.
- 10. Word2Vec and Negative Sampling Word2Vec is an NLP algorithm that learns word embeddings by training a neural network on extensive text datasets. It employs either the skip-gram or Continuous Bag of Words (CBOW) methods to predict words based on their surrounding context. Through this process, Word2Vec generates dense vector representations of words that encapsulate their semantic relationships and contextual meanings. These embeddings are typically represented in just a few dozen dimensions, enabling efficient and effective handling of language tasks such as measuring word similarity and performing various language processing applications. This compact representation facilitates improved language understanding and application.
- 11. • In the figure we see that the word embeddings are represented by the weights connecting between the hidden and output layer. • If we have 500 neurons in the hidden layer and 1000 neurons that is if the vocabulary is 1000 in the output layer we have to learn around 0.5 million weights, which might not be too huge but generally in any practical scenario we deal with bigger vocabularies. • If we even consider 10000 words in our vocabulary, then we have to learn a whopping 5 million weights. • Besides that we know that for embeddings to capture several context we would need a pretty huge corpus. • So, training these many weights for a huge corpus and applying softmax on 10000 weights is computationally very expensive and sometimes infeasible. • This issue could be addressed using negative sampling technique.
- 12. Properties and Visualization of Word Embeddings Word embeddings in NLP exhibit several important properties: capturing semantic relationships, enabling compositionality, managing subword information, maintaining compactness, and adapting to context. These properties allow embeddings to effectively represent word meanings, construct phrase and sentence representations, handle out-of-vocabulary words, and reduce dimensionality. By incorporating these aspects, word embeddings enhance various language processing tasks, leading to improved understanding and performance in NLP applications. Word embeddings can be visualized in a reduced-dimensional space to provide insights into word relationships. This technique enables the observation of clusters of semantically similar words and the exploration of their connections in a visually interpretable format. By projecting high-dimensional embeddings into a lower-dimensional space, patterns and relationships between words become more apparent, facilitating a clearer understanding of their semantic similarities and differences. Such visualizations help in analyzing and interpreting complex word associations and the overall structure of the word embeddings.
- 13. Word Embedding GloVe – Global Vectors for word representation The model is trained on multiple data sets including Wikipedia, Twitter and Common Crawl on billions of tokens and the embeddings are represented in different dimension size ranging from 50 to 300. “glove.6B.zip” file available in the following website and just consider the 50-dimension representation use the dimension reduction technique like t-SNE that is, t-Distributed Stochastic Neighbor embedding to reduce the dimensions to 2 and plot around 500 words on those 2-dimensions
- 14. Embedding Matrix In NLP, the embedding matrix is a crucial component that maps words to their respective vector representations. This matrix enables models to access and leverage the learned word embeddings during both training and inference phases. The size of the embedding matrix is determined by two factors: the vocabulary size, which represents the number of unique words, and the dimensionality of the embeddings, which indicates the number of features in each vector. By organizing word vectors in this matrix, models can efficiently use these embeddings to perform various language processing tasks and improve their overall performance. Keras layer as the first layer for NLP related applications: Text classification (sentiment analysis), Machine translation, NER, Text summarization. It maps indices to vectors. # of rows equal to the vocabulary size and the number of columns equal to the dimension of the embeddings we define
- 15. Sequential/Temporal/Series Data: RNN & LSTM Sequential data consists of information organized in a specific order, where the sequence is meaningful. This type of data includes time series, text, audio, DNA, and music. Analyzing sequential data often requires techniques such as time series analysis and sequence modeling, using machine learning models like Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs). Unstructured Sequential: speech, text, videos, music, etc…sequence of symbol, image, notes, letters, words, etc. Eg. daily average temperature of a city, monthly revenue of a company Internet of Things kind of environment, where we would have univariate and multivariate time series data for multiple entities like sensors
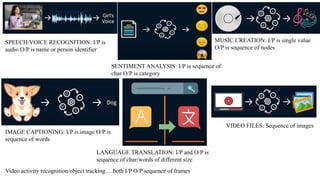
- 16. SPEECH/VOICE RECOGNITION: I/P is audio O/P is name or person identifier SENTIMENT ANALYSIS: I/P is sequence of char O/P is category MUSIC CREATION: I/P is single value O/P is sequence of nodes IMAGE CAPTIONING: I/P is image O/P is sequence of words LANGUAGE TRANSLATION: I/P and O/P is sequence of char/words of different size VIDEO FILES: Sequence of images Video activity recognition/object tracking….both I/P O/P sequence of frames
- 17. RNN and its variants (LSTM, GRU, Bi-RNN, S-RNN) • Multilayer Perceptrons (MLPs) are designed to process fixed-size inputs, treating each input as an independent data point without considering any sequential or time-based relationships. Due to this limitation, MLPs cannot capture patterns that depend on the order of the data, making them unsuitable for time series analysis. In contrast, Recurrent Neural Networks (RNNs) are specifically designed to handle sequential information through their recurrent connections, making them a more suitable choice for tasks involving time series data. I/P data is indep of each other but there is a time relationship In MLP I/P and O/P size is fixed A Recurrent Neural Network (RNN) is a type of neural network designed for processing sequential data. It features loops that allow information to be retained across time steps, making it effective at capturing temporal patterns. This capability makes RNNs particularly useful for applications such as time series forecasting, speech recognition, and natural language processing. More advanced variants, like Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) networks, have been developed to overcome the limitations of traditional RNNs, such as difficulty in learning long-term dependencies.
- 19. Types of RNN Based on Cardinality 1.One-to-One (1:1): This is a standard feedforward neural network used for non-sequential data. 2.Many-to-One (N:1): This type processes multiple inputs to produce a single output, such as in sentiment analysis. 3.One-to-Many (1-N): This setup uses a single input to generate multiple outputs, such as in image captioning. 4.Many-to-Many (N-N): This configuration handles multiple inputs and produces multiple outputs, which is common in machine translation. 5.Many-to-Many (N-M): This flexible structure allows for varying sequence lengths in both inputs and outputs, useful in applications like video analysis. One to one Character/word prediction Sales forecasting Many to one Sentiment Analysis Predict M/C failure One to Many Music generation Image Captioning Seq to Vector to seq N/W Many to Many cardinality Language Translation Variable I/O seq
- 20. To train an RNN using Backpropagation Through Time (BPTT): 1.Unroll the RNN: Treat each time step as a separate layer. 2.Forward Pass: Generate predictions. 3.Calculate Loss: Compare predictions with actual values. 4.Backpropagate Error: Propagate the error through time. 5.Update Parameters: Adjust using an optimization algorithm. 6.Repeat: Continue for multiple epochs. To prevent vanishing gradients in long sequences, use techniques like gradient clipping or advanced RNN variants like LSTM and GRU. Training RNNs: BPTT
- 21. Truncated Back propagation Through Time (Truncated BPTT) is a modified version of the standard BPTT algorithm for training RNNs with long sequences. It involves limiting the number of time steps over which error gradients are back propagated, instead of propagating them through the entire sequence. Running per parameter update on BPTT is computationally expensive, running for multiple epochs not feasible Break seq to sub seq, computationally feasible but temporal dependency reduced to sub seq level Training RNNs: BPTT
- 22. Here’s a brief overview of different types of Recurrent Neural Networks (RNNs): 1.Long Short-Term Memory (LSTM): LSTMs are a type of RNN designed to remember information for long periods. They use special units called memory cells that can maintain information in memory for long durations. LSTMs are effective for tasks like time series prediction and natural language processing. 2.Gated Recurrent Unit (GRU): GRUs are similar to LSTMs but with a simpler structure. They use gating mechanisms to control the flow of information, making them faster to train and sometimes more efficient for certain tasks. GRUs are often used in similar applications as LSTMs, such as speech recognition and machine translation. 3.Character Prediction: This refers to RNNs used for predicting the next character in a sequence. These models are trained on text data and can generate text one character at a time, making them useful for tasks like text generation and autocompletion. 4.Stacked RNNs: Stacked RNNs consist of multiple layers of RNNs stacked on top of each other. This architecture allows the model to learn more complex patterns by capturing different levels of abstraction. They are commonly used in tasks that require deep understanding, such as language modeling and sequence-to-sequence tasks. 5.Bidirectional RNNs: These RNNs process sequences in both forward and backward directions. By having access to both past and future contexts, bidirectional RNNs can better understand the entire sequence. They are particularly useful in tasks like speech recognition and text classification, where context is important. These various types of RNNs can be combined or adapted for specific use cases, depending on the requirements of the task at hand. Types of RNN
- 23. LSTM • Sepp H and Jurgen S (1997): solve complex probs with long time dependency and ran faster and efficiently • To address memory issue: Long term state (c), short term state (h) • Forgets not so imp old memories • Updates/refreshes old memories, forms new imp ones Each GATE has a NN Main NN produces O/P based on I/P and prev state of cell and updates long term memory Forget GATE determines how much of the long term memory needs to be forgotten or retained Input GATE figures out important part of I/P and concatenates that to long term state Output GATE decides how much of updated long term memory should be considered as part of O/P of cell
- 25. 2014 NN-3 1 state 1 NN to ctrl I/P and Forget GATE
- 26. Stacked and Bi directional RNN Time series forecasting Language modeling Named entity recognition Machine Translation
- 27. Encoder Decoder Seq to Seq Model • The Encoder-Decoder architecture is an RNN framework designed for sequence-to- sequence tasks. In this setup, the Encoder processes an input sequence and produces a context vector, which encapsulates the information from the input. The Decoder then uses this context vector to generate an output sequence. This architecture is commonly applied in areas such as machine translation, text summarization, and speech recognition. Teacher Forcing: correct word acts as a teacher and forces the model to correct immediately when prediction is wrong
- 28. Beam Search and Bleu Evaluation Matrices Beam Search: Beam Search is a search algorithm used in sequence-to-sequence models, particularly in natural language processing tasks. Unlike the greedy search that selects the best option at each step, Beam Search keeps track of multiple hypotheses (beams) at each step, expanding the top N sequences with the highest probabilities. This method balances between searching broadly and efficiently, aiming to find the most likely sequence of tokens. It is widely used in tasks like machine translation and speech recognition to improve the quality of generated sequences. BLEU (Bilingual Evaluation Understudy): BLEU is a popular evaluation metric for assessing the quality of text generated by machine translation systems. It compares the overlap of n-grams (contiguous sequences of words) in the machine-generated text with one or more reference translations. The score ranges from 0 to 1, with higher scores indicating closer matches to the reference translations. BLEU emphasizes precision by measuring how many words in the generated output match the reference, considering factors like brevity and the presence of multiple references. It is widely used due to its simplicity and effectiveness in evaluating machine translation quality. Numerical translation closeness metric Corpus of good quality human reference translations Modified n-gram Precision BLEU score uses av. log with uniform weights, like geom mean of modified n-gram precision Doesn ot consider: Semantic Sentence structure morphology
- 29. Attention Mechanism • allowing models to selectively focus on the most relevant information within large datasets, thereby enhancing efficiency and accuracy in data processing.