






























































































Ad
More Related Content
Similar to Git mercurial - Git basics , features and commands (20)
More from DivyanshGupta922023 (19)

















Ad
Recently uploaded (20)




















Ad
Git mercurial - Git basics , features and commands
- 1. Beyond code: Versioning data with Git and Mercurial Stephanie Collett and Martin Haye California Digital Library, University of California
- 6. Agenda • Background • Case Study #1: eScholarship Backup • Case Study #2: Zephir Metadata • Summary
- 15. Why distributed?
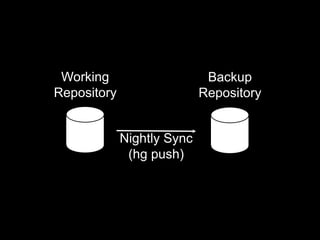
- 17. Case #1 eScholarship Data/Metadata Backup
- 18. eScholarship
- 21. XML Metadata 10 files per work }
- 29. 30-60 minutes for the batch job
- 31. Case #2 Zephir Metadata Management System
- 34. Zephir
- 40. Individually
- 41. Versioning + Audit Trail + Diffing + Debugging
- 42. Collectively
- 43. record/ marc.xml
- 44. 1 file, ~4k
- 46. 4 file, ~36k
- 48. record/ + record/.git 43 files, ~132k
- 49. record/ + record/.git ~132k x 10 million
- 50. record/ + record/.git 43 files x 10 million
- 53. Grit Gem (Git) vs. Rugged Gem (Libgit2)
- 54. Grit Gem (Git)
- 60. Grit vs. Rugged • add files • commit • add files • determine changes • determine parent • commit • replace HEAD
- 62. Summary
- 64. vs.
- 67. texty data, small files 100-10,000 files per repository
- 68. If it looks like code, even if it's data, it will probably work
Editor's Notes
- #4: Not tutorial
- #5: http://www.flickr.com/photos/maisonbisson/201844037/ Not an explanation on how Mercurial and Git work under the hood
- #6: Not an epic fight to determine whose better, Git or Mercurial
- #10: http://www.flickr.com/photos/apenguincalledelvis/4262022435/
- #11: http://www.flickr.com/photos/aiwells/4672742619/ versioning, author, annotate, compare, manage (we just scrape the surface)
- #17: lightweight, file-based, compressed, reliable, ubiquitous
- #26: http://www.flickr.com/photos/bycp/5033418814/
- #28: 30-60 minutes
- #30: http://www.flickr.com/photos/ckaiserca/434018871/in/photostream/
- #33: The mission of HathiTrust is to contribute to the common good by collecting, organizing, preserving, communicating, and sharing the record of human knowledge.
- #34: http://www.flickr.com/photos/zenobia_joy/5393914694/
- #35: http://www.flickr.com/photos/ppl_ri_images/4019188259/
- #41: versioning worked great, debugging fantastic, audit trail, see what files changed, and what changed in the files.
- #48: 38 files
- #50: 33 times the space needed
- #56: Not tutorial
- #57: http://www.flickr.com/photos/12495774@N02/2405297371/ committing in grit: ~.2, committing in rugged ~.004
- #59: http://www.flickr.com/photos/kingway-school/5876407905/in/photostream/
- #60: http://www.flickr.com/photos/maisonbisson/201844037/
- #62: http://www.flickr.com/photos/boris/2345300428/sizes/z/in/photostream/ 50x faster (.2, .004)
- #65: Some implementations easy, others hard. Depends on complexity and API support.
- #66: Certain uses are going to be very slow. Lots of files, binary files, or command line use.
- #67: Real differences between the implementation, API support in languages
- #68: http://www.flickr.com/photos/pewari/3609957389/