Glibc malloc internal
Download as PPT, PDF179 likes65,891 views

glibc mallocの解説 Video: https://youtu.be/0-vWT-t0UHg









































![small bin 16 24 32 40 504 ・・・ size index 2 63 3 4 5 chunks これで小さいサイズの malloc が /* 8 の倍数に切り上げ */ size = request2size(req); if( size <= 512 ) { bin_index = size/8; chunk = bins[bin_index].bk; unlink(chunk); /* remove freelist */ return chunk + sizeof(size_t)*2; } このぐらい簡単に終わる 構造体とかはたいてい、このぐらいのサイズにおさまるよね? best fit どころか、 just fit アロケータですよ。と 8 8 8 8 8 bin width free list head の配列](https://image.slidesharecdn.com/glibcmalloc-110710054847-phpapp01/85/Glibc-malloc-internal-43-320.jpg)













![バッファの遅延合体 その2 gligc malloc では最低確保サイズが 32 なので bins[0] と bins[1] は使ってない bins[1] をこの遅延されてる block をつなげるリストのリストヘッドとして特別な意味で用いる ソースコード上は unsorted_chunk と呼ばれているが、ソートしない=時系列順である。 リストをたぐって、要求サイズと一致するものを検索 要求サイズと一致しないものは、この時点で、隣と併合して実際の free 処理](https://image.slidesharecdn.com/glibcmalloc-110710054847-phpapp01/85/Glibc-malloc-internal-57-320.jpg)



























































Ad
More Related Content
What's hot (20)
Viewers also liked (16)
![SECCON 2016 Online CTF [Memory Analysis] Write-Up (ver.korean)](https://cdn.slidesharecdn.com/ss_thumbnails/seccon2016onlinectfmemoryanalysiswrite-upver-161217144042-thumbnail.jpg?width=560&fit=bounds)













Ad
Similar to Glibc malloc internal (20)




















Ad
Glibc malloc internal
- 1. malloc の旅( glibc 編) kosaki @ぬまづ
- 2. 今日は何の話? libc でもっとも良く使われる関数、 malloc と free の実装の解説 もっと一般的に言うと、プロセスのアドレス空間のうち、 heap 領域とよばれる、場所を操作する関数の説明 解説というと聞こえはいいが、そんな大層なものじゃない
- 3. Linux での process address space model kernel stack text mmap data bss heap 矢印はデータ量の増加と ともに、伸びる方向 使用中 使用中 使用中 今日は、ここ、 heap と呼ばれる領域のお話 low high free free free
- 4. 古典的 malloc プログラミング言語 C (いわゆる K&R) で紹介された初期の Unix の malloc 実装 使用中 使用中 使用中 free listの head 使用中 ・ free list を使って空きメモリを管理 ・プロセス全体でただ1つの Heap を使う ・ malloc するときに管理領域分だけ多く allocate して先頭に管理領域を付加 ( どこかに管理領域がないと free するときに開放 size がわからない ) ・割り付け strategy は first fit. union header{ struct{ union header* ptr; unsigned size; }s; long alignment; };
- 5. malloc のアルゴリズム 使用中 使用中 使用中 free listの head 使用中 このぐらい 欲しい X 足りない 1.まず、 list head から先頭ポインタを get 2.空き領域が十分か調べる ・・・・小さすぎた
- 6. malloc のアルゴリズム 使用中 使用中 使用中 free listの head 使用中 X また足りない X このぐらい 欲しい 1.まず、 list head から先頭ポインタを get 2.空き領域が十分か調べる 3.ポインタを list の次の要素に進める 4.また空き領域が十分か調べる うむむ。。また小さい
- 7. malloc のアルゴリズム 使用中 使用中 使用中 free listの head 使用中 1.まず、 list head から先頭ポインタを get 2.空き領域が十分か調べる 3.ポインタを list の次の要素に進める 4.また空き領域が十分か調べる 5.また、ポインタを次の要素に進める 6.またまた、空き領域を調べる 今度はあった!! X OK X このぐらい 欲しい
- 8. malloc のアルゴリズム 使用中 使用中 使用中 free listの head 使用中 1.まず、 list head から先頭ポインタを get 2.空き領域が十分か調べる 3.ポインタを list の次の要素に進める 4.また空き領域が十分か調べる 5.また、ポインタを次の要素に進める 6.またまた、空き領域を調べる 7.空き領域を2つに分けて、 free list をつなぎなおす 8. list head を更新 今確保した 領域 最後に探索が失敗した場所 (アロケートされたメモリの 1つ前 の要素) を指すように変更
- 9. 実は・・・ 使用中 使用中 使用中 free listの head 使用中 実はもう1つ先を探すと、もっといい場所が あったのに・・・ X X このぐらい 欲しい 今確保した 領域
- 10. free のアルゴリズム 使用中 使用中 使用中 free listの head 使用中 free したい 領域 1. free list head から最初のポインタをゲット 2.最初の要素の、さらに次のポインタもゲット (next = p->s.ptr) 3. p < bp < next が成立しないので次へ bp p next
- 11. free のアルゴリズム 使用中 使用中 使用中 free listの head 使用中 free したい 領域 bp p next 1. free list head から最初のポインタをゲット 2.最初の要素の、さらに次のポインタもゲット (next = p->s.ptr) 3. p < bp < next が成立しないので次へ 4. p を次の要素に進める 5 .次のポインタをゲット 6 . p < bp < next が成立した
- 12. free のアルゴリズム 使用中 使用中 使用中 free listの head 使用中 bp p 7 . p と bp は隣接していない (p + p->s.size != bp) ので併合しない next 1. free list head から最初のポインタをゲット 2.最初の要素の、さらに次のポインタもゲット (next = p->s.ptr) 3. p < bp < next が成立しないので次へ 4. p を次の要素に進める 5 .次のポインタをゲット 6 . p < bp < next が成立した 8. bp と p->s.ptr は隣接しているので (bp + bp->s.size == next) 併合 free したい 領域
- 13. free のアルゴリズム 使用中 使用中 使用中 free listの head 使用中 bp p 7 . p と bp は隣接していない (p + p->s.size != bp) ので併合しない next 1. free list head から最初のポインタをゲット 2.最初の要素の、さらに次のポインタもゲット (next = p->s.ptr) 3. p < bp < next が成立しないので次へ 4. p を次の要素に進める 5 .次のポインタをゲット 6 . p < bp < next が成立した 8. bp と p->s.ptr は隣接しているので (bp + bp->s.size == next) 併合 9. free list head を今開放した要素を 指すよう動かす
- 14. 次に malloc の特殊なケース heap にまったく空きがなくて heap 自体を拡張するケースを 説明します
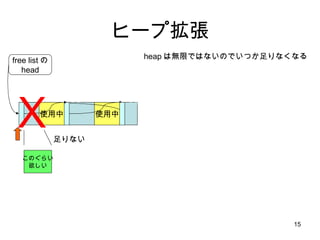
- 15. ヒープ拡張 使用中 free listの head 使用中 このぐらい 欲しい heap は無限ではないのでいつか足りなくなる X 足りない
- 16. ヒープ拡張 使用中 free listの head 使用中 このぐらい 欲しい heap は無限ではないのでいつか足りなくなる X 足りない X
- 17. ヒープ拡張 使用中 free listの head 使用中 このぐらい 欲しい heap は無限ではないのでいつか足りなくなる X 足りない X X
- 18. ヒープ拡張 使用中 free listの head 使用中 このぐらい 欲しい heap は無限ではないのでいつか足りなくなる X X X ptr と free list の head が再び一致 (一周してしまった)
- 19. ヒープ拡張 使用中 free listの head 使用中 このぐらい 欲しい heap は無限ではないのでいつか足りなくなる ここで brk システムコールで heap 領域を一気に 伸ばす brk は heap 最後尾アドレスを変更するAPI heap 最後尾 heap 最後尾
- 20. ヒープ拡張 使用中 使用中 heap は無限ではないのでいつか足りなくなる heap 最後尾 今確保した 領域 増えた領域を 2 つにわけ、先頭をユーザに返却。 残りを free list につなぐ free listの head
- 21. やや脱線
- 22. 素朴な brk の実装 0. データセグメントには静的データとスタック が入っている 1. 現在値+増加分で (kernel 内で ) malloc 2. 新しいメモリにメモリコピー 3. 古いデータを mfree 4 スタックを末尾にメモリコピー 5. スタックと静的データの間をゼロクリア new memory data data stack stack 出典: Lions ’ Commentary on UNIX 増加分 data stack data stack data stack data stack data stack
- 23. つまり カーネル brk がくそ遅い あんまり brk 呼ばなくてもいいように、ユーザー空間で「なるべく brk しない。するときはガバッと一気に取る」方針でいく とかいう価値観で実装されておりまする
- 24. さて 実は brk も、イマドキの Linux では大幅に高速になっているのだが、それは今回は考えない事にする 今はbrkが遅いって前提で malloc の高速化を考えていくぜい 脱線終わり
- 25. K&R malloc のいいところ 単純 コードサイズが小さい。 (組み込みとかも malloc はいまだにこんな形しとるよ) フラグメンテーションが進まない限り malloc は O(1) プログラム全体で数十回しか malloc しないような小規模プログラムではとてもうまく動く
- 26. K&R malloc のダメなところ 小さい malloc が多発すると フラグメンテーションがすぐ進む free が O(n) brk が呼ばれる状況では一回 freelist を一周する必要がある (リストが数万個もあれば、なにそのキャッシュ・フラッシング・コード状態) フラグメンテーションが進むとメモリ効率も急激に悪化
- 27. 時代は変わった・・・ イマドキなプログラミング GUI スクリプト言語や Java C++ プログラミング 等々 は、まさに小さい malloc が連発される
- 28. 最大の問題はなんだろう? ここは、とりあえずフラグメンテーションが最大の問題だと仮定しよう フラグメンテーションさえ解決すれば メモリ使用効率 UP! 使用メモリ量が減れば、それだけキャッシュに載る確率 UP! なんか カコ ( ・∀・ ) イイ !
- 29. とゆーわけで、時代は best fit アロケータなのである
- 30. で、 Just Idea に従って 実装してみる
- 31. アドレス順をやめて、 サイズ順にソートしてみる 使用中 使用中 使用中 free listの head 使用中 free の時に、隣接要素と併合することが不可能に・・・・ よけいフラグメンテーションが進みました 本末転倒
- 32. やっぱり malloc header に メンバを増やすしかない struct malloc_chunk { INTERNAL_SIZE_T prev_size; INTERNAL_SIZE_T size; struct malloc_chunk* fd; struct malloc_chunk* bk; }; 使用中 使用中 使用中 free listの head 使用中 変数名を glibc にあわせたので、だいぶ雰囲気が 変わったけど気にしない address space の prev, next はポインタで 持たずサイズで保持している。
- 33. 何が変わったのか 良くなったところ free が typical で O(n) から O(1) へ フラグメンテーションによる空間の無駄が減る 悪くなったところ malloc が typical で O(1) から O(n) へ ヘッダサイズが増えて空間効率ダウン
- 35. ヘッダのダイエットが必要です まず、 free list のポインタ、 bk, fd は割り付け済みブロックには必要ない これは単純に削ればいい アクセス方法には注意 prev_size size fd bk malloc_chunk 構造体にキャストして アクセスするので一見、 fd, bk メンバが あるように見えるが、実はそこは ユーザアプリに使われてしまっているので アクセスするとメモリ破壊 ソースコードからは読み取りにくい・・
- 36. ダイエットはつづくよ・・・ よーく考えると prev_size メンバは free 時の合併処理のみに必要 とゆーことは、 prev が free 状態のときのみ必要 prev_size は prev が free の時のみ記録したい ちょっとまって どうやって、 prev が free 状態か調べればいいんだっけ? (卵と鶏問題)
- 37. 下位 2bit は絶対0になるよね glibc malloc は実際には内部で 8 の倍数に切り上げるから、下位3 bit は 0 size メンバは2つのポインタの差を記録しているのだから、当然、同じく下位 3bit が0 32bit なシステムのポインタって・・ 0 31 1 2 ポインタ 0 0
- 38. というわけで prev_size size fd bk size fd bk use free free prev_size size use size 1 0 size メンバの再下位 bit を prev が USE 状態かを 記録するビットとして使う (図中の が最下位ビットを示している) 再下位が0なら prev_size メンバがある。 1 1 free() 関数で chunk_p = (malloc_chunk*)(((char*)ptr) - sizeof(size_t)*2); なんてやってるけど、 size メンバ以外はあるかどうか 分からない 構造体の型とメモリ上のデータ構造がまるで 一致していない香ばしい構造 -> 読みにくさの主原因 ブロック1 ブロック2 ブロック3 ブロック4
- 39. 時系列で見ると prev_size size fd bk use free free prev_size size fd bk 0 1 1 prev_size size fd bk use free free prev_size size fd bk 0 1 prev_size size fd bk malloc 1 1 prev_size size fd bk prev_size size fd bk 余分に確保するメモリは 4バイトのみ。 request2size() が req + sizeof( malloc_chunk) ではなく req + sizeof(size_t) なのは ここに原因があった!! malloc 編 malloc ヘッダ malloc ボディ(使用中) malloc ボディ( free ) 当然だけど、 malloc ヘッダから 突き抜けている malloc_chunk メンバはアクセスしたらエライ事になります fd,bk メンバはユーザに使われて しまうので壊される
- 40. 時系列で見ると use free 1 1 1 1 prev_size size fd bk prev_size size fd bk use prev_size size fd bk prev_size size fd bk free free 1 1 0 1 prev_size size fd bk prev_size size fd bk use prev_size size fd bk prev_size size fd bk free の時に初めて fd, bk, prev_size メンバが 書き込まれる size メンバ以外は、 malloc 時には確保してなかったのだが どうせ free じゃーん。 あいてるじゃーん。 という訳で勝手に使ってる。 ソース上はとってもメモリ破壊ちっく free free 編 ここで prev_in_use フラグが1に
- 41. ダイエットは出来たので ある意味、本日の code reading の最難関部分は突破 (^-^; (他の部分は、ちゃんと C 言語ちっくな C のソースコード (?) なので) 次は最大の課題。 malloc() が typical で O(n) じゃーん。問題を片付ける
- 42. ここでアイデア 別に free list で、1つのリストに全部つながなくてもいいよね? サイズは絶対8の倍数なんだから、サイズ16用のリスト、サイズ24用のリスト・・・・ ってやったら best fist かつ O(1) じゃね?
- 43. small bin 16 24 32 40 504 ・・・ size index 2 63 3 4 5 chunks これで小さいサイズの malloc が /* 8 の倍数に切り上げ */ size = request2size(req); if( size <= 512 ) { bin_index = size/8; chunk = bins[bin_index].bk; unlink(chunk); /* remove freelist */ return chunk + sizeof(size_t)*2; } このぐらい簡単に終わる 構造体とかはたいてい、このぐらいのサイズにおさまるよね? best fit どころか、 just fit アロケータですよ。と 8 8 8 8 8 bin width free list head の配列
- 44. さらに改良 512byte over の部分が手付かず でも、大きいサイズにも 8byte おきに bin を用意するのは現実的じゃない でもリストを複数もつ。 というアイデアは悪くない
- 45. large bin 588 652 716 780 ・・・ size index 65 123 66 67 68 64 64 64 64 32K bin width 124 32K 125 250K 126 250k 127 ∞ グラフにするとこんなカンジ bin width bin index bin index が大きくなるにつれ、あつかう block size の幅が指数的に大きくなるように調整 小さいサイズのほうが数が多いので、リストにつながる数を平均化するための施策 大きなサイズ用の リストヘッドも 64 個つくる ・・・ 512 4k ・・・ 750k more
- 46. でも どう頑張っても、一番ラストの bin は一杯つながってしまうんだよね 画像とか扱うと平気で数十 M とか malloc するし・・・・ あーあ、 Heap をもう1つ用意できたら でかいメモリを完全に分離できるのに・・
- 47. その為の mmap です
- 48. anonymous mmap とは? mmap は、本来ファイルをメモリにマップするシステムコール でも fd 引数に “ /dev/zero” を渡すことにより、メモリ確保 API として使用可能 この API を使って、 Huge Block( デフォルトで 128K byte 以上 ) は heap からではなく、 mmap で直接 kernel から取得する
- 49. またしても size メンバの下位 bit を 0 31 1 2 size 0 0 0 IS_MMAPED PREV_IN_USE 下から2 bit 目を mmap から取得したよーん。 という意味で使うことにする。 この bit が ON なら free list からではなく MMAP で取得 しているので、 free 時に freelist につながずに、 いきなり munmap() する
- 50. データ構造図解 使用中 使用中 使用中 使用中 使用中 (huge) 使用中 (huge) bins ※ 1 見やすくするために、リストをつなぐ線の種類を少しずつ変えてある ※ 2 Huge かつ free 状態はありえない。開放と同時に OS に返却するから
- 51. この方法の利点 Huge Block も malloc, free ともに O(1) フラグメンテーション、むっさ起きにくい (リスト管理してないんだから当たり前) メモリの無駄が少ない (でっかいメモリは同じサイズで再度 malloc される確率は低いので、すぐさま OS に返却するのは賢い戦略)
- 52. ここまでの結果 良くなったところ malloc が typical で O(1) free が typical で O(1) フラグメンテーションがすごく起きにくく ヘッダサイズは実質4バイト brk が発生するときに、 K&R malloc では freelist を一周する必要があったのが、要求サイズより大きい bin を検索するだけでよくなった。 平均で探索コスト 1/2 悪くなったところ なんかあったっけ?
- 53. でも! それでも! しばしば、 K&R malloc に 負けるんです。これが 実は large size block の malloc – free –malloc – free と 繰り返す割り当てが遅い
- 54. K&R free を振り返ってみる 使用中 使用中 使用中 free listの head 使用中 bp p next 9. free list head を今開放した要素を 指すよう動かす 今開放した 要素 ここがポイント
- 55. キャッシュと局所参照性 heap メモリーに一番アクセスする確率が高いのは malloc 直後と free 直前である free されたばかりのメモリはキャッシュに載ってる確率が高い そこから優先してメモリ確保することは malloc 直後のアクセスでキャッシュミスしなくなるということ キャッシュのヒット率重要
- 56. バッファの遅延合体 free が呼ばれたときに、すぐに隣と併合& free list につなぐ処理をやめる 最初にこのアイデアを実装したのは SVR4 らしい ( 最前線 UNIX のカーネル より ) malloc – free – malloc – free という非常によくあるアクセスパターンでメモリブロックの分離・併合・分離・併合という無駄な処理が避けられる。 かつ、 free された順に時系列にリストにつながっているので、リスト先頭の block をアプリに返せばキャッシュヒット率向上
- 57. バッファの遅延合体 その2 gligc malloc では最低確保サイズが 32 なので bins[0] と bins[1] は使ってない bins[1] をこの遅延されてる block をつなげるリストのリストヘッドとして特別な意味で用いる ソースコード上は unsorted_chunk と呼ばれているが、ソートしない=時系列順である。 リストをたぐって、要求サイズと一致するものを検索 要求サイズと一致しないものは、この時点で、隣と併合して実際の free 処理
- 58. マクロな視点で話をすると malloc の呼び出しパターンはたいてい以下のような経過をへる アプリ起動時はやたら malloc が呼ばれる。 free はほとんど呼ばれない その後、 malloc と free がほぼ交互に呼ばれる定常状態に入る GUI の画面遷移のような、なんからの契機で、 free がひたすら呼ばれ、次に malloc がひたすら呼ばれるデータ構造の大転換がおこる そしてまた定常状態に・・・・
- 59. malloc の 定常状態とバースト状態 バースト状態 バースト状態 このとき、遅延併合が 裏目に出る。 遅延併合リストに要素が 一杯たまるから メモリ使用量 定常状態 遅延併合は裏目にでることもあるが、いちばんありがちな、 定常状態で高速化されるのでモトがとれる
- 60. まだもうちょっとだけ 続くんじゃ
- 62. 素朴な lock malloc(size_t sz){ lock(); ptr = internal_malloc(sz); unlock(); return ptr; } ご冗談でしょう。ファインマンさん たんじゅんに、関数全体を mutex で保護してみた
- 63. 本当はこうしたい 使用中 使用中 使用中 使用中 使用中 使用中 使用中 使用中 bins 使用中 使用中 使用中 使用中 bins bins スレッド1 スレッド2 スレッド3 スレッド1専用 heap スレッド 2 専用 heap スレッド 3 専用 heap ロックのいらない素敵な世界
- 64. それは流石に無理 アプリがいくつスレッドをつくるか事前に知る方法はない 1つのスレッドが最大どのくらいのメモリを使うのか事前に知る方法はない ITRON だと両方ともコンパイル時に決まるのに・・
- 66. Arena 生成 使用中 使用中 使用中 使用中 bins スレッド1 main_arena main_arena == 今まで説明してきた heap アクセス ロック arena 構造体
- 67. 使用中 使用中 使用中 使用中 スレッド1 main_arena アクセス ロック アクセス、しかし、ロックとれず bins arena 構造体 スレッド 2 別のスレッドが malloc を同時に呼ぶと、 ロック取得 (mutex_trylock) に失敗 Arena 生成 スレッド2
- 68. Arena 生成 スレッド2 使用中 使用中 使用中 使用中 スレッド1 main_arena アクセス ロック スレッド 2 新しい自分専用 heap を mmap で作成 この altanative heap の仕組みを arena と呼んでいる。 TLS(thread local strage) に自分用 arena を覚えておくので スレッドが増えるか 1M 使い切るかしない限り二度とバッティングしない bins arena 構造体 とってきたメモリの先頭を arena 構造体 ( bin 配列などが入っている構造体)として使う 1M free mmap arena 同士は list でつなげる
- 69. Arena 生成 スレッド3 使用中 使用中 使用中 使用中 スレッド1 main_arena スレッド 2 bins arena 構造体 free アクセス スレッド 3 アクセス 次のスレッドも、ロック競合が起きるまでは main_arena を 使い続ける
- 70. Arena 生成 スレッド3 使用中 使用中 使用中 使用中 スレッド1 main_arena アクセス ロック スレッド 2 bins arena 構造体 free アクセス スレッド 3 アクセス ロックがぶつかったら・・・・
- 71. Arena 生成 スレッド3 使用中 使用中 使用中 使用中 スレッド1 main_arena アクセス ロック スレッド 2 bins arena 構造体 free アクセス スレッド 3 アクセス arena list を、たぐって次々とロック取得をチャレンジ すべて失敗したら、また新しい自分専用 arena を作る。
- 72. Arena 生成 スレッド3 使用中 使用中 使用中 使用中 スレッド1 main_arena アクセス ロック スレッド 2 bins arena 構造体 free アクセス スレッド 3 mmap いきなり arena 生成をしないのはスレッド2が すでに終了していたときに、その専用 arena が無駄になるのを防ぐため これにより、スレッド生成直後は色々な arena でロック競合するが そのうちに、 1 スレッド・ 1 アリーナに収束する free
- 73. 1スレッド:1 Arena の隠れた利点 SMP マシンでは、別の CPU からアクセスしたメモリは自分 CPU のキャッシュには乗らないのでラストアクセスを単純に管理してはうまくいかない しかし、ユーザ空間から自分がどの CPU で動いているのか明に意識するのは無理 (いつのまにか勝手に変わるし) そこでカーネルがもつスレッドの CPU affinity スケジューリングに着目して、自分スレッドがアクセスしたデータは自分 CPU でアクセスした確率が高いと考える スレッド専用メモリ=キャッシュヒット率がものすごく Up!
- 74. ところで free するときに、自分の所属する arena ってどうやって見つけるんだっけ?
- 75. だめアイデア1 TLS から arena を取得 -> 自分専用 arena を作る前に 何回か main_arena から取得 している分がある。 それは、 main_arena に戻さないと。
- 76. だめアイデア2 それぞれの malloc header に arena へのポインタを追加する -> なんのために死ぬ思いでヘッダを 4バイトまで削ったと思ってるんです?
- 77. だめアイデア3 main_arena (唯一のグローバル変数)から arena のリストをたどって・・・ -> O(n) の検索はダメだっつってんだろ!
- 78. 結局どうしたか? arena を絶対 1M align されるようにメモリを確保する。 すると、 ptr & ~0xFFFFF するだけで arena へのポインタが得られるようにする
- 79. 課題 1 main_arena はグローバル変数なんだけど・・・ 0 31 1 2 size 0 0 0 IS_MMAPED PREV_IN_USE -> 毎度おなじみ size メンバハックのお時間でございま~す♪ IS_NON_MAINARENA
- 80. 課題 2 Linux に 1M align を保障するメモリ確保システムコールってないんだけど -> 以下のちょっとトリッキーな方法で可能 (次ページ参照)
- 81. Arena で 1M にそろえる方法 図解 0x100000 0x200000 こういうメモリ確保がしたい しかし mmap では出来ない。 low high use free free 1 M アライン
- 82. Arena で 1M にそろえる方法 図解 0x100000 0x200000 2 倍のサイズで mmap ただし PROT_NONE 0x100000 0x200000 余分な場所を munmap READ も WRITE も EXEC も不可なメモリ確保というのは メモリを確保しないが、アドレススペースは確保するというのと同義 1M アラインされた場所から size 1M で PROT_READ | PROT_WRITE | PROT_EXEC で remap. 0x100000 0x200000
- 83. まとめ 小さい malloc は回数がすごくたくさん呼ばれるので、 O(n) ではダメ フラグメンテーションを防ぐには Huge Block は Heap を分けるのが効果的 キャッシュヒット率を上げるには、参照局所性 超 重要 per Thread なデータ構造は per CPU なデータ構造のよい近似値
- 84. glibc malloc のダメなところ Huge Block が絶対 page align されてしまうので、キャッシュが競合しやすい ( HPC 分野ではこの機能は OFF にするのが一般的) もう一工夫すれば、 Arena へのロック自体なくせる(これが問題になるような heavy allocation アプリは自前 heap 管理をしてるので効果は見えにくいかも) 最新の dlmalloc は large-bin の管理がリストからバイナリツリーに変更されて高速化が図られている(でも使用率がいまいち低いので効果は微妙か?)
- 85. 終わりに変えて glibc malloc は、今日のスライド 90 枚にわたる色々なアイデアが int_malloc() という1つの関数にごった煮で詰め込んであるので、すごく読みにくい おまいら、ソースコードのコメントにうそを書くなと小一時間・・ おまいら、関数分割ぐらいしろと小二時間・・・ おまいら、構造体の型とメモリ上のデータ構造は合わせておけと小三時間・・・ これを見ると Linux kernel ってなんて読みやすいのかと・・・・
- 86. ご清聴ありがとうございました! つかれた~ (≧ω≦) ゞ