Gluent Extending Enterprise Applications with Hadoop
Download as PPTX, PDF3 likes868 views

This presentation shows how to transparently extend enterprise applications with the power of modern data platforms such as Hadoop. Application re-writing is not needed and there is no downtime when virtualizing data with Gluent.

































































Ad
More Related Content
What's hot (20)
Similar to Gluent Extending Enterprise Applications with Hadoop (20)


















Ad
Recently uploaded (20)




















Ad
Gluent Extending Enterprise Applications with Hadoop
- 1. 1 we liberate enterprise data
- 2. 2 Extending Enterprise Applications with the Full Power of Hadoop Tanel Poder gluent.com
- 3. 3 Gluent - who we are Tanel also co-authored the Expert Oracle Exadata book. Speaker: Tanel Poder A long time computer performance geek. Co-founder & CEO of Gluent. Long term Oracle Database & Data Warehousing guys – focused on performance & scale. Alumni 2009-2016
- 4. 4 • Super-scalable • Processing pushed close to data • Software-defined (open source) • Commodity hardware • No SAN storage bottlenecks • Open data formats • One data, many engines Why Hadoop? Scalable & affordable-at-scale • Yahoo: multiple 4000+ node Hadoop clusters • Facebook: 30 PB Hadoop cluster (in year 2011!) 2017: Enterprise-ready • Hadoop is secure … • … has management tools … • … and evolving fast
- 5. 5 One Data, Many Engines! • Decoupling storage from compute + open data formats = flexible future-proof data platforms! HDFS Parquet ORC XML Avro Amazon S3 Parquet WebLog Kudu Column-store Impala SQLHive SQL Xyz… Solr / Search SparkMR Kudu API libparquet
- 6. 6 BUT No complex transactions No transactional “PL/SQL” No very complex queries
- 7. 7 Is Hadoop only for ”Big Data”?
- 8. 8
- 9. 9 Hadoop for traditional enterprise apps? New “Big Data” applications Traditional enterprise applications
- 10. 10 How to connect all this data with enterprise applications? New data SaaS IoT Big Data Modern data platformsCore enterprise apps Running on relational DBs ? ?
- 11. 11 Hybrid World!
- 12. 1212 Gluent Oracle Postgres SQL Teradata IoT & Big Data MSSQL App X App Y App Z Hadoop/RDBMS connectivity layer Open data formats!
- 13. 13 • Gluent Data Platform (of course :-) • No-ETL Data Sync (Data Offload to Hadoop) • Smart Connector (Transparent Data Query from Hadoop) • ETL & replication products • Informatica, Talend, Pentaho, etc etc… • Oracle GoldenGate, Attunity, DBVisit, etc… • RDBMS->Hadoop Query products • Teradata QueryGrid • Microsoft SQL Server Polybase • Oracle Big Data SQL • IBM Big SQL • Native RDBMS database links & linked servers over ODBC etc… Hybrid World-related Vendors & Tools
- 14. 14 • 2-minute demo! • More technical details at: • https://vimeo.com/196497024 Gluent Demo
- 15. 15 Hybrid World Case Studies
- 16. 16 Case Study 1 – IoT data within existing RDBMS app
- 17. 17 Securus: Satellite Tracking of People (STOP) VeriTracks Application http://www.stopllc.com/ Challenge - how to: • Scale business? • Offer additional services? • Add additional data sources? • Embed predictive & advanced analytics, machine learning? • Cut cost at the same time?! • 150 TB dataset • Geospatial data • Kept in Oracle DB • Growing fast • Google Maps API • Near-realtime reaction • Long-term analytics
- 18. 18 Securus: Satellite Tracking of People (STOP) VeriTracks Application
- 19. 19 1. New analytics in existing apps immediately possible 2. Reduced cost 3. Move fast with low risk – don’t rewrite entire apps • The customer didn’t change a single line of code! Securus STOP: Summary
- 21. 21 Typical Application Story: Monolithic Data Model A complex business application running on a RDBMS Years of application development & improvement Upstream & downstream dependencies Terabytes of historical data (usually years of history) Big queries run for too long or never complete (or never tried) Does not scale with modern demand Way too expensive Application rewrite very costly & risky or virtually impossible Customers Products Preferences Promotions Prices RDBMS + SAN SALES
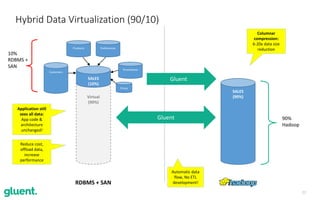
- 22. 22 Hybrid Data Virtualization (90/10) Virtual (90%) SALES (10%) Customers Products Preferences Promotions Prices RDBMS + SAN 10% RDBMS + SAN SALES (90%) 90% Hadoop Gluent Reduce cost, offload data, increase performance Application still sees all data: App code & architecture unchanged! Gluent Columnar compression: 6-20x data size reduction Automatic data flow, No ETL development!
- 23. 23 Hybrid Data Virtualization (100/10) Virtual (90%) SALES (10%) Customers Products Preferences Promotions Prices RDBMS + SAN SALES (100%) 10% RDBMS + SAN 100% Hadoop Gluent Customers Products Preferences Promotions Prices Gluent Gluent New Analytics & Apps Reduce cost and enable new analytics on Hadoop
- 24. 24 Hybrid Data Virtualization (Big Data/IoT) Customers Products Preferences Promotions Prices RDBMS + SAN WEB_VISITS (Hadoop only) SALES WEB_VISITS (Virtual) Gluent Data & compute virtualization: Users query tables in databases, actual data & processing in Hadoop
- 25. 25 • Call Detail Records • Only 90 days of history • Offloaded 89 days Case Study 2 – Large Telecom
- 26. 26 Case Study 2 – Large Telecom - Results
- 27. 27 • Query Elapsed Times Avg 36X Faster in Hybrid Mode • Average Oracle CPU Reduction 87% in Hybrid Mode • Storage cost reduction ~100X • HDFS storage ~10x cheaper than SAN • 11x compression due to columnar format (ORC) • 30 days < 2 minutes • 90 days ~3 minutes • Enabled Completely New Capabilities • Application Owner Wanted to Query 1 Year Case Study 2 – Large Telecom - Results
- 28. 28 Case Study 3 – Multi-Year Reports
- 29. 29 • Many different (generated) queries running for a few seconds each • We executed 5,500 APPX queries from AWR history using our tools • 50% reduction of CPU Case Study 4 – Thousands of ”Short” Queries 7731 3846 0 1000 2000 3000 4000 5000 6000 7000 8000 9000 Before After Total CPU… Schema CPU Seconds DATAMART 7731 DATAMART_H 3846 50% CPU saving with hybrid query Average CPU 1.4 sec/exec before 0.7 sec with hybrid query
- 30. 30 Hybrid Case Study 5 – EDW Offload EDW DB (Oracle) EDW Apps EDW Apps Hadoop Transparent access No ETL data sync EDW DB (Oracle) EDW Apps EDW Apps Shrink legacy cost footprint, increase performance without re-writing apps
- 31. 31 Hybrid Case Study 6 – Access IoT Data in Enterprise Apps EDW DB (Oracle) EDW Apps EDW Apps Hadoop Smart Meter Data Call Recordings Transparent access Transparent access Hybrid Queries over all enterprise data No need to rewrite existing apps
- 32. 32 Hybrid Case Study 7 – data sharing platform (24 DBs) App 23 App 24 Hadoop App 1 App 2 Oracle DB Oracle DB … Oracle DB CDR data Oracle DB CDR data
- 33. 33 Summary
- 34. 34 • The Hybrid World is not “all-or-nothing” • Get the best of both worlds (RDBMS+Hadoop) • No data migration downtime & cutover needed • No need to re-write your apps to take advantage of modern data platforms • No need write ETL jobs to sync your data to Hadoop & Cloud Summary we liberate enterprise data
- 35. 35 Advisor Do you want to assess potential savings & opportunities with Gluent? https://gluent.com/products/gluent-advisor/
- 36. 36 http://gluent.com @gluent Thanks! + Q&A we liberate enterprise data