













![Recall: Warp Execution
15
32-thread warp executing ADD A[tid],B[tid] C[tid]
C[1]
C[2]
C[0]
A[3] B[3]
A[4] B[4]
A[5] B[5]
A[6] B[6]
Execution using
one pipelined
functional unit
C[4]
C[8]
C[0]
A[12] B[12]
A[16] B[16]
A[20] B[20]
A[24] B[24]
C[5]
C[9]
C[1]
A[13] B[13]
A[17] B[17]
A[21] B[21]
A[25] B[25]
C[6]
C[10]
C[2]
A[14] B[14]
A[18] B[18]
A[22] B[22]
A[26] B[26]
C[7]
C[11]
C[3]
A[15] B[15]
A[19] B[19]
A[23] B[23]
A[27] B[27]
Execution using
four pipelined
functional units
Slide credit: Krste Asanovic
Time
Space
Time](https://image.slidesharecdn.com/comparch-fall2019-lecture17-gpuprogramming-afterlecture-240426190002-c85c3769/85/gpuprogram_lecture-architecture_designsn-15-320.jpg)












![Indexing and Memory Access
Images are 2D data structures
height x width
Image[j][i], where 0 ≤ j < height, and 0 ≤ i < width
Image[0][1]
Image[1][2]
31
0 1 2 3 4 5 6 7
0
1
2
3
4
5
6
7](https://image.slidesharecdn.com/comparch-fall2019-lecture17-gpuprogramming-afterlecture-240426190002-c85c3769/85/gpuprogram_lecture-architecture_designsn-31-320.jpg)
![Image Layout in Memory
Row-major layout
Image[j][i] = Image[j x width + i]
Image[0][1] = Image[0 x 8 + 1]
Image[1][2] = Image[1 x 8 + 2]
32
Stride = width](https://image.slidesharecdn.com/comparch-fall2019-lecture17-gpuprogramming-afterlecture-240426190002-c85c3769/85/gpuprogram_lecture-architecture_designsn-32-320.jpg)

![Indexing and Memory Access: 2D Grid
2D blocks
gridDim.x, gridDim.y
Block (0, 0)
blockIdx.x = 2
blockIdx.y = 1
Row = blockIdx.y *
blockDim.y + threadIdx.y
Row = 1 * 2 + 1 = 3
threadIdx.x = 1
threadIdx.y = 0
Col = blockIdx.x *
blockDim.x + threadIdx.x
Col = 0 * 2 + 1 = 1
Image[3][1] = Image[3 * 8 + 1]
34](https://image.slidesharecdn.com/comparch-fall2019-lecture17-gpuprogramming-afterlecture-240426190002-c85c3769/85/gpuprogram_lecture-architecture_designsn-34-320.jpg)









![AoS vs. SoA
Array of Structures vs. Structure of Arrays
Tenemos 2 data layouts principales (AoS y SoA) y uno nuevo propuesto (A
ASTA permite transformar uno en otro más rápidamente y facilita hacerlo in-place
ahorrar memoria. En la siguiente figura se ven los tres:
Data Layout Alternatives
Array of
Structures
(AoS)
Array of
Structure of
Tiled Array
(ASTA)
struct foo{
float a;
float b;
float c;
int d;
} A[8];
struct foo{
float a[4];
float b[4];
float c[4];
int d[4];
} A[2];
Structure of
Arrays
(SoA)
struct foo{
float a[8];
float b[8];
float c[8];
int d[8];
} A;
Layout Conversion and Transposition 46](https://image.slidesharecdn.com/comparch-fall2019-lecture17-gpuprogramming-afterlecture-240426190002-c85c3769/85/gpuprogram_lecture-architecture_designsn-46-320.jpg)

![Data Reuse
Same memory locations accessed by neighboring threads
for (int i = 0; i < 3; i++){
for (int j = 0; j < 3; j++){
sum += gauss[i][j] * Image[(i+row-1)*width + (j+col-1)];
}
}
48](https://image.slidesharecdn.com/comparch-fall2019-lecture17-gpuprogramming-afterlecture-240426190002-c85c3769/85/gpuprogram_lecture-architecture_designsn-48-320.jpg)
![Data Reuse: Tiling
To take advantage of data reuse, we divide the input into tiles
that can be loaded into shared memory
__shared__ int l_data[(L_SIZE+2)*(L_SIZE+2)];
…
Load tile into shared memory
__syncthreads();
for (int i = 0; i < 3; i++){
for (int j = 0; j < 3; j++){
sum += gauss[i][j] * l_data[(i+l_row-1)*(L_SIZE+2)+j+l_col-1];
}
}
49](https://image.slidesharecdn.com/comparch-fall2019-lecture17-gpuprogramming-afterlecture-240426190002-c85c3769/85/gpuprogram_lecture-architecture_designsn-49-320.jpg)









![Vector Reduction: Naïve Mapping (II)
Program with low SIMD utilization
__shared__ float partialSum[]
unsigned int t = threadIdx.x;
for (int stride = 1; stride < blockDim.x; stride *= 2) {
__syncthreads();
if (t % (2*stride) == 0)
partialSum[t] += partialSum[t + stride];
}
59](https://image.slidesharecdn.com/comparch-fall2019-lecture17-gpuprogramming-afterlecture-240426190002-c85c3769/85/gpuprogram_lecture-architecture_designsn-59-320.jpg)

![Divergence-Free Mapping (II)
Program with high SIMD utilization
__shared__ float partialSum[]
unsigned int t = threadIdx.x;
for (int stride = blockDim.x; stride > 1; stride >> 1){
__syncthreads();
if (t < stride)
partialSum[t] += partialSum[t + stride];
}
61](https://image.slidesharecdn.com/comparch-fall2019-lecture17-gpuprogramming-afterlecture-240426190002-c85c3769/85/gpuprogram_lecture-architecture_designsn-61-320.jpg)

![ Atomic Operations are needed when threads might update the
same memory locations at the same time
CUDA: int atomicAdd(int*, int);
PTX: atom.shared.add.u32 %r25, [%rd14], %r24;
SASS:
/*00a0*/ LDSLK P0, R9, [R8];
/*00a8*/ @P0 IADD R10, R9, R7;
/*00b0*/ @P0 STSCUL P1, [R8], R10;
/*00b8*/ @!P1 BRA 0xa0;
/*01f8*/ ATOMS.ADD RZ, [R7], R11;
Native atomic operations for
32-bit integer, and 32-bit and
64-bit atomicCAS
Tesla, Fermi, Kepler Maxwell, Pascal, Volta
Shared Memory Atomic Operations
63](https://image.slidesharecdn.com/comparch-fall2019-lecture17-gpuprogramming-afterlecture-240426190002-c85c3769/85/gpuprogram_lecture-architecture_designsn-63-320.jpg)

![Histogram Calculation
Histograms count the number of data instances in disjoint
categories (bins)
for (each pixel i in image I){
Pixel = I[i] // Read pixel
Pixel’ = Computation(Pixel) // Optional computation
Histogram[Pixel’]++ // Vote in histogram bin
}
Atomic additions
65](https://image.slidesharecdn.com/comparch-fall2019-lecture17-gpuprogramming-afterlecture-240426190002-c85c3769/85/gpuprogram_lecture-architecture_designsn-65-320.jpg)












![ Fine-grain heterogeneity becomes possible with
Pascal/Volta architecture
Pascal/Volta Unified Memory
CPU-GPU memory coherence
System-wide atomic operations
// Allocate input
cudaMallocManaged(input, ...);
// Allocate output
cudaMallocManaged(output, ...);
// Launch GPU kernel
gpu_kernel<<<blocks, threads>>> (output, input, ...);
// CPU can do things here
output[x] = input[y];
output[x+1].fetch_add(1);
Fine-Grained Heterogeneity
78](https://image.slidesharecdn.com/comparch-fall2019-lecture17-gpuprogramming-afterlecture-240426190002-c85c3769/85/gpuprogram_lecture-architecture_designsn-78-320.jpg)
![Since CUDA 8.0
Unified memory
cudaMallocManaged(&h_in, in_size);
System-wide atomics
old = atomicAdd_system(&h_out[x], inc);
79](https://image.slidesharecdn.com/comparch-fall2019-lecture17-gpuprogramming-afterlecture-240426190002-c85c3769/85/gpuprogram_lecture-architecture_designsn-79-320.jpg)
![Since OpenCL 2.0
Shared virtual memory
XYZ * h_in = (XYZ *)clSVMAlloc(
ocl.clContext, CL_MEM_SVM_FINE_GRAIN_BUFFER, in_size, 0);
More flags:
CL_MEM_READ_WRITE
CL_MEM_SVM_ATOMICS
C++11 atomic operations
(memory_scope_all_svm_devices)
old = atomic_fetch_add(&h_out[x], inc);
80](https://image.slidesharecdn.com/comparch-fall2019-lecture17-gpuprogramming-afterlecture-240426190002-c85c3769/85/gpuprogram_lecture-architecture_designsn-80-320.jpg)
![C++AMP (HCC)
Unified memory space (HSA)
XYZ *h_in = (XYZ *)malloc(in_size);
C++11 atomic operations
(memory_scope_all_svm_devices)
Platform atomics (HSA)
old = atomic_fetch_add(&h_out[x], inc);
81](https://image.slidesharecdn.com/comparch-fall2019-lecture17-gpuprogramming-afterlecture-240426190002-c85c3769/85/gpuprogram_lecture-architecture_designsn-81-320.jpg)






![// Allocate control points
malloc(control_points, ...);
generate_cp(control_points);
cudaMalloc(d_control_points, ...);
cudaMemcpy(d_control_points, control_points, ..., HostToDevice); // Copy to device memory
// Allocate surface
malloc(surface, ...);
cudaMalloc(d_surface, ...);
// Launch CPU threads
std::thread main_thread (run_cpu_threads, control_points, surface, ...);
// Launch GPU kernel
gpu_kernel<<<blocks, threads>>> (d_surface, d_control_points, ...);
// Synchronize
main_thread.join();
cudaDeviceSynchronize();
// Copy gpu part of surface to host memory
cudaMemcpy(&surface[end_of_cpu_part], d_surface, ..., DeviceToHost);
Bézier Surfaces (IV)
Without Unified Memory
90](https://image.slidesharecdn.com/comparch-fall2019-lecture17-gpuprogramming-afterlecture-240426190002-c85c3769/85/gpuprogram_lecture-architecture_designsn-90-320.jpg)

































![Benefits of Collaboration on FPGA (III)
126
Sitao Huang, Li-Wen Chang, Izzat El Hajj, Simon Garcia De Gonzalo, Juan Gomez-Luna, Sai Rahul
Chalamalasetti, Mohamed El-Hadedy, Dejan Milojicic, Onur Mutlu, Deming Chen, and Wen-mei Hwu,
"Analysis and Modeling of Collaborative Execution Strategies for Heterogeneous CPU-
FPGA Architectures"
Proceedings of the 10th ACM/SPEC International Conference on Performance Engineering (ICPE),
Mumbai, India, April 2019.
[Slides (pptx) (pdf)]
[Chai CPU-FPGA Benchmark Suite]](https://image.slidesharecdn.com/comparch-fall2019-lecture17-gpuprogramming-afterlecture-240426190002-c85c3769/85/gpuprogram_lecture-architecture_designsn-126-320.jpg)
































Ad
More Related Content
Similar to gpuprogram_lecture,architecture_designsn (20)
Recently uploaded (20)


















Ad
gpuprogram_lecture,architecture_designsn
- 1. Computer Architecture Lecture 17: GPU Programming Dr. Juan Gómez Luna Prof. Onur Mutlu ETH Zürich Fall 2019 21 November 2019
- 2. Agenda for Today GPU as an accelerator Program structure Bulk synchronous programming model Memory hierarchy and memory management Performance considerations Memory access SIMD utilization Atomic operations Data transfers Collaborative computing 2
- 3. Recommended Readings CUDA Programming Guide https://docs.nvidia.com/cuda/cuda-c-programming- guide/index.html Hwu and Kirk, “Programming Massively Parallel Processors,” Third Edition, 2017 3
- 5. Recall: NVIDIA GeForce GTX 285 NVIDIA-speak: 240 stream processors “SIMT execution” Generic speak: 30 cores 8 SIMD functional units per core Slide credit: Kayvon Fatahalian 5
- 6. NVIDIA GeForce GTX 285 “core” … = instruction stream decode = SIMD functional unit, control shared across 8 units = execution context storage = multiply-add = multiply 64 KB of storage for thread contexts (registers) Slide credit: Kayvon Fatahalian 6
- 7. NVIDIA GeForce GTX 285 “core” … 64 KB of storage for thread contexts (registers) Groups of 32 threads share instruction stream (each group is a Warp) Up to 32 warps are simultaneously interleaved Up to 1024 thread contexts can be stored Slide credit: Kayvon Fatahalian 7
- 8. NVIDIA GeForce GTX 285 Tex Tex Tex Tex Tex Tex Tex Tex Tex Tex … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … 30 cores on the GTX 285: 30,720 threads Slide credit: Kayvon Fatahalian 8
- 9. 0 2000 4000 6000 8000 10000 12000 14000 16000 0 1000 2000 3000 4000 5000 6000 GTX285 (2009) GTX480 (2010) GTX780 (2013) GTX980 (2014) P100 (2016) V100 (2017) GFLOPS #Stream Processors Stream Processors GFLOPS Recall: Evolution of NVIDIA GPUs 9
- 10. Recall: NVIDIA V100 NVIDIA-speak: 5120 stream processors “SIMT execution” Generic speak: 80 cores 64 SIMD functional units per core Specialized Functional Units for Machine Learning (tensor ”cores” in NVIDIA-speak) 10
- 11. Recall: NVIDIA V100 Block Diagram 80 cores on the V100 https://devblogs.nvidia.com/inside-volta/ 11
- 12. Recall: NVIDIA V100 Core 15.7 TFLOPS Single Precision 7.8 TFLOPS Double Precision 125 TFLOPS for Deep Learning (Tensor ”cores”) 12 https://devblogs.nvidia.com/inside-volta/
- 13. Food for Thought What is the main bottleneck in GPU programs? “Tensor cores”: Can you think about other operations than matrix multiplication? What other applications could benefit from specialized cores? Compare and contrast GPUs vs other accelerators (e.g., systolic arrays) Which one is better for machine learning? Which one is better for image/vision processing? What types of parallelism each one exploits? What are the tradeoffs? 13
- 14. Recall: Latency Hiding via Warp-Level FGMT Warp: A set of threads that execute the same instruction (on different data elements) Fine-grained multithreading One instruction per thread in pipeline at a time (No interlocking) Interleave warp execution to hide latencies Register values of all threads stay in register file FGMT enables long latency tolerance Millions of pixels 14 Decode RF RF RF ALU ALU ALU D-Cache Thread Warp 6 Thread Warp 1 Thread Warp 2 Data All Hit? Miss? Warps accessing memory hierarchy Thread Warp 3 Thread Warp 8 Writeback Warps available for scheduling Thread Warp 7 I-Fetch SIMD Pipeline Slide credit: Tor Aamodt
- 15. Recall: Warp Execution 15 32-thread warp executing ADD A[tid],B[tid] C[tid] C[1] C[2] C[0] A[3] B[3] A[4] B[4] A[5] B[5] A[6] B[6] Execution using one pipelined functional unit C[4] C[8] C[0] A[12] B[12] A[16] B[16] A[20] B[20] A[24] B[24] C[5] C[9] C[1] A[13] B[13] A[17] B[17] A[21] B[21] A[25] B[25] C[6] C[10] C[2] A[14] B[14] A[18] B[18] A[22] B[22] A[26] B[26] C[7] C[11] C[3] A[15] B[15] A[19] B[19] A[23] B[23] A[27] B[27] Execution using four pipelined functional units Slide credit: Krste Asanovic Time Space Time
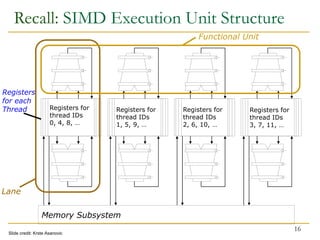
- 16. 16 Lane Functional Unit Registers for each Thread Memory Subsystem Registers for thread IDs 0, 4, 8, … Registers for thread IDs 1, 5, 9, … Registers for thread IDs 2, 6, 10, … Registers for thread IDs 3, 7, 11, … Slide credit: Krste Asanovic Recall: SIMD Execution Unit Structure
- 17. Recall: Warp Instruction Level Parallelism Can overlap execution of multiple instructions Example machine has 32 threads per warp and 8 lanes Completes 24 operations/cycle while issuing 1 warp/cycle 17 W3 W0 W1 W4 W2 W5 Load Unit Multiply Unit Add Unit time Warp issue Slide credit: Krste Asanovic
- 18. Clarification of some GPU Terms 18 Generic Term NVIDIA Term AMD Term Comments Vector length Warp size Wavefront size Number of threads that run in parallel (lock-step) on a SIMD functional unit Pipelined functional unit / Scalar pipeline Streaming processor / CUDA core - Functional unit that executes instructions for one GPU thread SIMD functional unit / SIMD pipeline Group of N streaming processors (e.g., N=8 in GTX 285, N=16 in Fermi) Vector ALU SIMD functional unit that executes instructions for an entire warp GPU core Streaming multiprocessor Compute unit It contains one or more warp schedulers and one or several SIMD pipelines
- 19. GPU Programming
- 20. Recall: Vector Processor Disadvantages -- Works (only) if parallelism is regular (data/SIMD parallelism) ++ Vector operations -- Very inefficient if parallelism is irregular -- How about searching for a key in a linked list? 20 Fisher, “Very Long Instruction Word architectures and the ELI-512,” ISCA 1983.
- 21. General Purpose Processing on GPU Easier programming of SIMD processors with SPMD GPUs have democratized High Performance Computing (HPC) Great FLOPS/$, massively parallel chip on a commodity PC Many workloads exhibit inherent parallelism Matrices Image processing Deep neural networks However, this is not for free New programming model Algorithms need to be re-implemented and rethought Still some bottlenecks CPU-GPU data transfers (PCIe, NVLINK) DRAM memory bandwidth (GDDR5, GDDR6, HBM2) Data layout 21
- 22. CPU vs. GPU Different design philosophies CPU: A few out-of-order cores GPU: Many in-order FGMT cores 22 Slide credit: Hwu & Kirk
- 23. GPU Computing Computation is offloaded to the GPU Three steps CPU-GPU data transfer (1) GPU kernel execution (2) GPU-CPU data transfer (3) CPU memory CPU cores Matrix GPU memory GPU cores Matrix 1 3 2 23
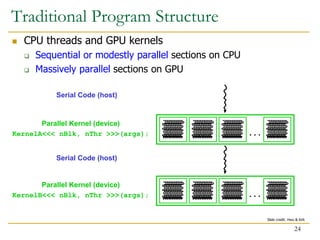
- 24. CPU threads and GPU kernels Sequential or modestly parallel sections on CPU Massively parallel sections on GPU Serial Code (host) . . . . . . Parallel Kernel (device) KernelA<<< nBlk, nThr >>>(args); Serial Code (host) Parallel Kernel (device) KernelB<<< nBlk, nThr >>>(args); Traditional Program Structure 24 Slide credit: Hwu & Kirk
- 25. Recall: SPMD Single procedure/program, multiple data This is a programming model rather than computer organization Each processing element executes the same procedure, except on different data elements Procedures can synchronize at certain points in program, e.g. barriers Essentially, multiple instruction streams execute the same program Each program/procedure 1) works on different data, 2) can execute a different control-flow path, at run-time Many scientific applications are programmed this way and run on MIMD hardware (multiprocessors) Modern GPUs programmed in a similar way on a SIMD hardware 25
- 26. CUDA/OpenCL Programming Model SIMT or SPMD Bulk synchronous programming Global (coarse-grain) synchronization between kernels The host (typically CPU) allocates memory, copies data, and launches kernels The device (typically GPU) executes kernels Grid (NDRange) Block (work-group) Within a block, shared memory, and synchronization Thread (work-item) 26
- 27. Transparent Scalability Hardware is free to schedule thread blocks Device Block 0 Block 1 Block 2 Block 3 Block 4 Block 5 Block 6 Block 7 Kernel grid Block 0 Block 1 Block 2 Block 3 Block 4 Block 5 Block 6 Block 7 Device Block 0 Block 1 Block 2 Block 3 Block 4 Block 5 Block 6 Block 7 Each block can execute in any order relative to other blocks. time 27 Slide credit: Hwu & Kirk time
- 29. Function prototypes float serialFunction(…); __global__ void kernel(…); main() 1) Allocate memory space on the device – cudaMalloc(&d_in, bytes); 2) Transfer data from host to device – cudaMemCpy(d_in, h_in, …); 3) Execution configuration setup: #blocks and #threads 4) Kernel call – kernel<<<execution configuration>>>(args…); 5) Transfer results from device to host – cudaMemCpy(h_out, d_out, …); Kernel – __global__ void kernel(type args,…) Automatic variables transparently assigned to registers Shared memory: __shared__ Intra-block synchronization: __syncthreads(); repeat as needed Traditional Program Structure in CUDA 29 Slide credit: Hwu & Kirk
- 30. CUDA Programming Language Memory allocation cudaMalloc((void**)&d_in, #bytes); Memory copy cudaMemcpy(d_in, h_in, #bytes, cudaMemcpyHostToDevice); Kernel launch kernel<<< #blocks, #threads >>>(args); Memory deallocation cudaFree(d_in); Explicit synchronization cudaDeviceSynchronize(); 30
- 31. Indexing and Memory Access Images are 2D data structures height x width Image[j][i], where 0 ≤ j < height, and 0 ≤ i < width Image[0][1] Image[1][2] 31 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
- 32. Image Layout in Memory Row-major layout Image[j][i] = Image[j x width + i] Image[0][1] = Image[0 x 8 + 1] Image[1][2] = Image[1 x 8 + 2] 32 Stride = width
- 33. Indexing and Memory Access: 1D Grid One GPU thread per pixel Grid of Blocks of Threads gridDim.x, blockDim.x blockIdx.x, threadIdx.x Block 0 Block 0 Thread 0 Thread 1 Thread 2 Thread 3 blockIdx.x threadIdx.x blockIdx.x * blockDim.x + threadIdx.x 6 * 4 + 1 = 25 33
- 34. Indexing and Memory Access: 2D Grid 2D blocks gridDim.x, gridDim.y Block (0, 0) blockIdx.x = 2 blockIdx.y = 1 Row = blockIdx.y * blockDim.y + threadIdx.y Row = 1 * 2 + 1 = 3 threadIdx.x = 1 threadIdx.y = 0 Col = blockIdx.x * blockDim.x + threadIdx.x Col = 0 * 2 + 1 = 1 Image[3][1] = Image[3 * 8 + 1] 34
- 35. Brief Review of GPU Architecture (I) Streaming Processor Array Tesla architecture (G80/GT200) 35
- 36. Brief Review of GPU Architecture (II) Streaming Multiprocessors (SM) Streaming Processors (SP) Blocks are divided into warps SIMD unit (32 threads) … t0 t1 t2 … t31 … … t0 t1 t2 … t31 … Block 0’s warps Block 1’s warps … t0 t1 t2 … t31 … Block 2’s warps 36 NVIDIA Fermi architecture
- 37. Brief Review of GPU Architecture (III) Streaming Multiprocessors (SM) or Compute Units (CU) SIMD pipelines Streaming Processors (SP) or CUDA ”cores” Vector lanes Number of SMs x SPs across generations Tesla (2007): 30 x 8 Fermi (2010): 16 x 32 Kepler (2012): 15 x 192 Maxwell (2014): 24 x 128 Pascal (2016): 56 x 64 Volta (2017): 80 x 64 37
- 39. Performance Considerations Main bottlenecks Global memory access CPU-GPU data transfers Memory access Latency hiding Occupancy Memory coalescing Data reuse Shared memory usage SIMD (Warp) Utilization: Divergence Atomic operations: Serialization Data transfers between CPU and GPU Overlap of communication and computation 39
- 40. Memory Access
- 41. Latency Hiding FGMT can hide long latency operations (e.g., memory accesses) Occupancy: ratio of active warps 4 active warps 2 active warps 41
- 42. Occupancy SM resources (typical values) Maximum number of warps per SM (64) Maximum number of blocks per SM (32) Register usage (256KB) Shared memory usage (64KB) Occupancy calculation Number of threads per block (defined by the programmer) Registers per thread (known at compile time) Shared memory per block (defined by the programmer) 42
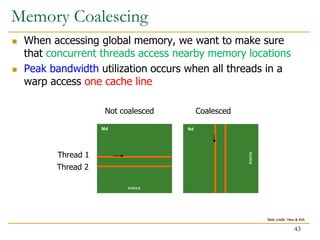
- 43. When accessing global memory, we want to make sure that concurrent threads access nearby memory locations Peak bandwidth utilization occurs when all threads in a warp access one cache line Md Nd WIDTH WIDTH Thread 1 Thread 2 Not coalesced Coalesced Memory Coalescing 43 Slide credit: Hwu & Kirk
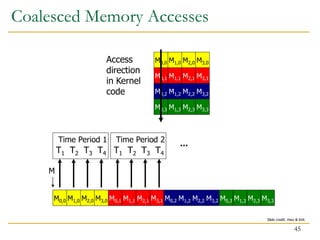
- 44. Uncoalesced Memory Accesses M2,0 M1,1 M1,0 M0,0 M0,1 M3,0 M2,1M3,1 M2,0 M1,0 M0,0 M3,0 M1,1 M0,1 M2,1M3,1 M1,2 M0,2 M2,2M3,2 M1,2 M0,2 M2,2M3,2 M1,3 M0,3 M2,3M3,3 M1,3 M0,3 M2,3M3,3 M T1 T2 T3 T4 Time Period 1 T1 T2 T3 T4 Time Period 2 Access direction in Kernel code … 44 Slide credit: Hwu & Kirk
- 45. Coalesced Memory Accesses M2,0 M1,1 M1,0 M0,0 M0,1 M3,0 M2,1 M3,1 M2,0 M1,0 M0,0 M3,0 M1,1 M0,1 M2,1 M3,1 M1,2 M0,2 M2,2 M3,2 M1,2 M0,2 M2,2 M3,2 M1,3 M0,3 M2,3 M3,3 M1,3 M0,3 M2,3 M3,3 M T1 T2 T3 T4 Time Period 1 T1 T2 T3 T4 Time Period 2 Access direction in Kernel code … 45 Slide credit: Hwu & Kirk
- 46. AoS vs. SoA Array of Structures vs. Structure of Arrays Tenemos 2 data layouts principales (AoS y SoA) y uno nuevo propuesto (A ASTA permite transformar uno en otro más rápidamente y facilita hacerlo in-place ahorrar memoria. En la siguiente figura se ven los tres: Data Layout Alternatives Array of Structures (AoS) Array of Structure of Tiled Array (ASTA) struct foo{ float a; float b; float c; int d; } A[8]; struct foo{ float a[4]; float b[4]; float c[4]; int d[4]; } A[2]; Structure of Arrays (SoA) struct foo{ float a[8]; float b[8]; float c[8]; int d[8]; } A; Layout Conversion and Transposition 46
- 47. CPUs Prefer AoS, GPUs Prefer SoA Linear and strided accesses 0.0 1.0 2.0 3.0 4.0 5.0 6.0 7.0 8.0 9.0 10.0 11.0 12.0 1 2 4 8 16 32 64 128 256 512 1024 Throughput (GB/s) Stride (Structure size) GPU 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 1 2 4 8 16 32 64 128 256 512 1024 Throughput (GB/s) Stride (Structure size) 1CPU 2CPU 4CPU AMD Kaveri A10-7850K GPU CPU 47 Sung+, “DL: A data layout transformation system for heterogeneous computing,” INPAR 2012
- 48. Data Reuse Same memory locations accessed by neighboring threads for (int i = 0; i < 3; i++){ for (int j = 0; j < 3; j++){ sum += gauss[i][j] * Image[(i+row-1)*width + (j+col-1)]; } } 48
- 49. Data Reuse: Tiling To take advantage of data reuse, we divide the input into tiles that can be loaded into shared memory __shared__ int l_data[(L_SIZE+2)*(L_SIZE+2)]; … Load tile into shared memory __syncthreads(); for (int i = 0; i < 3; i++){ for (int j = 0; j < 3; j++){ sum += gauss[i][j] * l_data[(i+l_row-1)*(L_SIZE+2)+j+l_col-1]; } } 49
- 50. Shared Memory Shared memory is an interleaved (banked) memory Each bank can service one address per cycle Typically, 32 banks in NVIDIA GPUs Successive 32-bit words are assigned to successive banks Bank = Address % 32 Bank conflicts are only possible within a warp No bank conflicts between different warps 50
- 51. Shared Memory Bank Conflicts (I) Bank conflict free Bank 15 Bank 7 Bank 6 Bank 5 Bank 4 Bank 3 Bank 2 Bank 1 Bank 0 Thread 15 Thread 7 Thread 6 Thread 5 Thread 4 Thread 3 Thread 2 Thread 1 Thread 0 Bank 15 Bank 7 Bank 6 Bank 5 Bank 4 Bank 3 Bank 2 Bank 1 Bank 0 Thread 15 Thread 7 Thread 6 Thread 5 Thread 4 Thread 3 Thread 2 Thread 1 Thread 0 Linear addressing: stride = 1 Random addressing 1:1 51 Slide credit: Hwu & Kirk
- 52. Shared Memory Bank Conflicts (II) N-way bank conflicts 2-way bank conflict: stride = 2 8-way bank conflict: stride = 8 Thread 11 Thread 10 Thread 9 Thread 8 Thread 4 Thread 3 Thread 2 Thread 1 Thread 0 Bank 15 Bank 7 Bank 6 Bank 5 Bank 4 Bank 3 Bank 2 Bank 1 Bank 0 Thread 15 Thread 7 Thread 6 Thread 5 Thread 4 Thread 3 Thread 2 Thread 1 Thread 0 Bank 9 Bank 8 Bank 15 Bank 7 Bank 2 Bank 1 Bank 0 x8 x8 52 Slide credit: Hwu & Kirk
- 53. Reducing Shared Memory Bank Conflicts Bank conflicts are only possible within a warp No bank conflicts between different warps If strided accesses are needed, some optimization techniques can help Padding Randomized mapping Rau, “Pseudo-randomly interleaved memory,” ISCA 1991 Hash functions V.d.Braak+, “Configurable XOR Hash Functions for Banked Scratchpad Memories in GPUs,” IEEE TC, 2016 53
- 54. SIMD Utilization
- 55. Control Flow Problem in GPUs/SIMT A GPU uses a SIMD pipeline to save area on control logic Groups scalar threads into warps Branch divergence occurs when threads inside warps branch to different execution paths 55 Branch Path A Path B Branch Path A Path B Slide credit: Tor Aamodt This is the same as conditional/predicated/masked execution. Recall the Vector Mask and Masked Vector Operations?
- 56. SIMD Utilization Intra-warp divergence Compute(threadIdx.x); if (threadIdx.x % 2 == 0){ Do_this(threadIdx.x); } else{ Do_that(threadIdx.x); } Compute If Else 56
- 57. Increasing SIMD Utilization Divergence-free execution Compute(threadIdx.x); if (threadIdx.x < 32){ Do_this(threadIdx.x * 2); } else{ Do_that((threadIdx.x%32)*2+1); } Compute If Else 57
- 58. Vector Reduction: Naïve Mapping (I) 0 1 2 3 4 5 7 6 10 9 8 11 0+1 2+3 4+5 6+7 10+11 8+9 0...3 4..7 8..11 0..7 8..15 1 2 3 iterations Thread 0 Thread 8 Thread 2 Thread 4 Thread 6 Thread 10 58 Slide credit: Hwu & Kirk
- 59. Vector Reduction: Naïve Mapping (II) Program with low SIMD utilization __shared__ float partialSum[] unsigned int t = threadIdx.x; for (int stride = 1; stride < blockDim.x; stride *= 2) { __syncthreads(); if (t % (2*stride) == 0) partialSum[t] += partialSum[t + stride]; } 59
- 60. Divergence-Free Mapping (I) All active threads belong to the same warp Thread 0 0 1 2 3 … 13 15 14 18 17 16 19 0+16 15+31 1 2 3 Thread 1 Thread 2 Thread 14 Thread 15 iterations 60 Slide credit: Hwu & Kirk
- 61. Divergence-Free Mapping (II) Program with high SIMD utilization __shared__ float partialSum[] unsigned int t = threadIdx.x; for (int stride = blockDim.x; stride > 1; stride >> 1){ __syncthreads(); if (t < stride) partialSum[t] += partialSum[t + stride]; } 61
- 63. Atomic Operations are needed when threads might update the same memory locations at the same time CUDA: int atomicAdd(int*, int); PTX: atom.shared.add.u32 %r25, [%rd14], %r24; SASS: /*00a0*/ LDSLK P0, R9, [R8]; /*00a8*/ @P0 IADD R10, R9, R7; /*00b0*/ @P0 STSCUL P1, [R8], R10; /*00b8*/ @!P1 BRA 0xa0; /*01f8*/ ATOMS.ADD RZ, [R7], R11; Native atomic operations for 32-bit integer, and 32-bit and 64-bit atomicCAS Tesla, Fermi, Kepler Maxwell, Pascal, Volta Shared Memory Atomic Operations 63
- 64. We define the intra-warp conflict degree as the number of threads in a warp that update the same memory position The conflict degree can be between 1 and 32 tbase tconflict Shared memory Shared memory tbase No atomic conflict = concurrent updates Atomic conflict = serialized updates Atomic Conflicts 64
- 65. Histogram Calculation Histograms count the number of data instances in disjoint categories (bins) for (each pixel i in image I){ Pixel = I[i] // Read pixel Pixel’ = Computation(Pixel) // Optional computation Histogram[Pixel’]++ // Vote in histogram bin } Atomic additions 65
- 66. Histogram Calculation of Natural Images Frequent conflicts in natural images 66
- 67. Optimizing Histogram Calculation Privatization: Per-block sub-histograms in shared memory Block 0’s sub-histo Block 1’s sub-histo Block 2’s sub-histo Block 3’s sub-histo Global memory Final histogram Shared memory 67 Gomez-Luna+, “Performance Modeling of Atomic Additions on GPU Scratchpad Memory,” IEEE TPDS, 2013.
- 68. Data Transfers between CPU and GPU
- 69. Data Transfers Synchronous and asynchronous transfers Streams (Command queues) Sequence of operations that are performed in order CPU-GPU data transfer Kernel execution D input data instances, B blocks GPU-CPU data transfer Default stream 69
- 70. Asynchronous Transfers Computation divided into nStreams D input data instances, B blocks nStreams D/nStreams data instances B/nStreams blocks Estimates tT + tE nStreams tE + tT nStreams tE >= tT (dominant kernel) tT > tE (dominant transfers) 70
- 71. Applications with independent computation on different data instances can benefit from asynchronous transfers For instance, video processing Overlap of Communication and Computation 71 Gomez-Luna+, “Performance models for asynchronous data transfers on consumer Graphics Processing Units,” JPDC, 2012.
- 72. Summary GPU as an accelerator Program structure Bulk synchronous programming model Memory hierarchy and memory management Performance considerations Memory access Latency hiding: occupancy (TLP) Memory coalescing Data reuse: shared memory SIMD utilization Atomic operations Data transfers 72
- 74. // Allocate input malloc(input, ...); cudaMalloc(d_input, ...); cudaMemcpy(d_input, input, ..., HostToDevice); // Copy to device memory // Allocate output malloc(output, ...); cudaMalloc(d_output, ...); // Launch GPU kernel gpu_kernel<<<blocks, threads>>> (d_output, d_input, ...); // Synchronize cudaDeviceSynchronize(); // Copy output to host memory cudaMemcpy(output, d_output, ..., DeviceToHost); Review Device allocation, CPU-GPU transfer, and GPU-CPU transfer cudaMalloc(); cudaMemcpy(); 74
- 75. Unified Memory (I) Unified Virtual Address Since CUDA 6.0: Unified memory Since CUDA 8.0 + Pascal: GPU page faults 75
- 76. // Allocate input malloc(input, ...); cudaMallocManaged(d_input, ...); memcpy(d_input, input, ...); // Copy to managed memory // Allocate output cudaMallocManaged(d_output, ...); // Launch GPU kernel gpu_kernel<<<blocks, threads>>> (d_output, d_input, ...); // Synchronize cudaDeviceSynchronize(); Unified Memory (II) Easier programming with Unified Memory cudaMallocManaged(); 76
- 77. Case studies using CPU and GPU Kernel launches are asynchronous CPU can work while waits for GPU to finish Traditionally, this is the most efficient way to exploit heterogeneity // Allocate input malloc(input, ...); cudaMalloc(d_input, ...); cudaMemcpy(d_input, input, ..., HostToDevice); // Copy to device memory // Allocate output malloc(output, ...); cudaMalloc(d_output, ...); // Launch GPU kernel gpu_kernel<<<blocks, threads>>> (d_output, d_input, ...); // CPU can do things here // Synchronize cudaDeviceSynchronize(); // Copy output to host memory cudaMemcpy(output, d_output, ..., DeviceToHost); Collaborative Computing Algorithms 77
- 78. Fine-grain heterogeneity becomes possible with Pascal/Volta architecture Pascal/Volta Unified Memory CPU-GPU memory coherence System-wide atomic operations // Allocate input cudaMallocManaged(input, ...); // Allocate output cudaMallocManaged(output, ...); // Launch GPU kernel gpu_kernel<<<blocks, threads>>> (output, input, ...); // CPU can do things here output[x] = input[y]; output[x+1].fetch_add(1); Fine-Grained Heterogeneity 78
- 79. Since CUDA 8.0 Unified memory cudaMallocManaged(&h_in, in_size); System-wide atomics old = atomicAdd_system(&h_out[x], inc); 79
- 80. Since OpenCL 2.0 Shared virtual memory XYZ * h_in = (XYZ *)clSVMAlloc( ocl.clContext, CL_MEM_SVM_FINE_GRAIN_BUFFER, in_size, 0); More flags: CL_MEM_READ_WRITE CL_MEM_SVM_ATOMICS C++11 atomic operations (memory_scope_all_svm_devices) old = atomic_fetch_add(&h_out[x], inc); 80
- 81. C++AMP (HCC) Unified memory space (HSA) XYZ *h_in = (XYZ *)malloc(in_size); C++11 atomic operations (memory_scope_all_svm_devices) Platform atomics (HSA) old = atomic_fetch_add(&h_out[x], inc); 81
- 82. … … data-parallel tasks sequential sub-tasks coarse-grained synchronization Program Structure Data Partitioning … … Device 1 Device 2 … … Collaborative Patterns (I) 82
- 83. … … data-parallel tasks sequential sub-tasks coarse-grained synchronization Program Structure … … Device 1 Device 2 Coarse-grained Task Partitioning Collaborative Patterns (II) 83
- 84. … … data-parallel tasks sequential sub-tasks coarse-grained synchronization Program Structure Fine-grained Task Partitioning Device 1 Device 2 … … … … … … Collaborative Patterns (III) 84
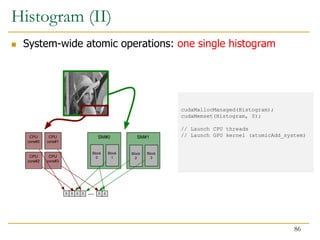
- 85. SM#0 SM#1 CPU core#0 Block 0 Block 1 Block 2 Block 3 CPU core#1 CPU core#2 CPU core#3 0 0 0 0 0 0 ... 0 0 0 0 0 0 ... 0 0 0 0 0 0 ... malloc(CPU image); cudaMalloc(GPU image); cudaMemcpy(GPU image, CPU image, ..., Host to Device); malloc(CPU histogram); memset(CPU histogram, 0); cudaMalloc(GPU histogram); cudaMemset(GPU histogram, 0); // Launch CPU threads // Launch GPU kernel cudaMemcpy(GPU histogram, DeviceToHost); // Launch CPU threads for merging Histogram (I) Previous generations: separate CPU and GPU histograms are merged at the end 85
- 86. cudaMallocManaged(Histogram); cudaMemset(Histogram, 0); // Launch CPU threads // Launch GPU kernel (atomicAdd_system) SM#0 SM#1 CPU core#0 Block 0 Block 1 Block 2 Block 3 CPU core#1 CPU core#2 CPU core#3 0 0 0 0 0 0 ... Histogram (II) System-wide atomic operations: one single histogram 86
- 87. Bézier Surfaces (I) Bézier surface: 4x4 net of control points 87
- 88. Bézier Surfaces (II) Parametric non-rational formulation Bernstein polynomials Bi-cubic surface m = n = 3 88
- 89. Bézier Surfaces (III) Collaborative implementation Tiles calculated by GPU blocks or CPU threads Static distribution 89
- 90. // Allocate control points malloc(control_points, ...); generate_cp(control_points); cudaMalloc(d_control_points, ...); cudaMemcpy(d_control_points, control_points, ..., HostToDevice); // Copy to device memory // Allocate surface malloc(surface, ...); cudaMalloc(d_surface, ...); // Launch CPU threads std::thread main_thread (run_cpu_threads, control_points, surface, ...); // Launch GPU kernel gpu_kernel<<<blocks, threads>>> (d_surface, d_control_points, ...); // Synchronize main_thread.join(); cudaDeviceSynchronize(); // Copy gpu part of surface to host memory cudaMemcpy(&surface[end_of_cpu_part], d_surface, ..., DeviceToHost); Bézier Surfaces (IV) Without Unified Memory 90
- 91. Execution results Bezier surface: 300x300, 4x4 control points %Tiles to CPU NVIDIA Jetson TX1 (4 ARMv8 + 2 SMX): 17% speedup wrt GPU only 0.0 10.0 20.0 30.0 40.0 50.0 60.0 70.0 80.0 90.0 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 Execu on me (ms) %Tiles to CPU Bézier Surfaces (V) 91
- 92. // Allocate control points malloc(control_points, ...); generate_cp(control_points); cudaMalloc(d_control_points, ...); cudaMemcpy(d_control_points, control_points, ..., HostToDevice); // Copy to device memory // Allocate surface cudaMallocManaged(surface, ...); // Launch CPU threads std::thread main_thread (run_cpu_threads, control_points, surface, ...); // Launch GPU kernel gpu_kernel<<<blocks, threads>>> (surface, d_control_points, ...); // Synchronize main_thread.join(); cudaDeviceSynchronize(); Bézier Surfaces (VI) With Unified Memory (Pascal/Volta) 92
- 93. Static vs. dynamic implementation Pascal/Volta Unified Memory: system-wide atomic operations while(true){ if(threadIdx.x == 0) my_tile = atomicAdd_system(tile_num, 1); // my_tile in shared memory; tile_num in UM __syncthreads(); // Synchronization if(my_tile >= number_of_tiles) break; // Break when all tiles processed ... } Bézier Surfaces (VII) 93
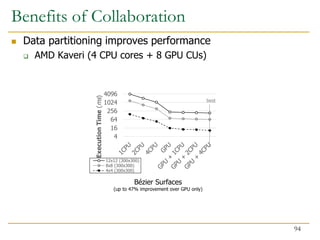
- 94. Benefits of Collaboration Data partitioning improves performance AMD Kaveri (4 CPU cores + 8 GPU CUs) 4 16 64 256 1024 4096 Execution Time ( ms ) 12x12 (300x300) 8x8 (300x300) 4x4 (300x300) Bézier Surfaces (up to 47% improvement over GPU only) best 94
- 95. Matrix padding Memory alignment Transposition of near-square matrices Traditionally, it can only be performed out-of-place Padding Padding (I) 95
- 96. Execution results Matrix size: 4000x4000, padding = 1 NVIDIA Jetson TX1 (4 ARMv8 + 2 SMX): 29% speedup wrt GPU only 0 20 40 60 80 100 120 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 0.55 0.60 Execu on me (ms) %CPU workload Padding (II) 96
- 97. 1 GPU temporary location 1 1 Coherent memory 1 1 1 1 1 1 1 1 1 1 1 1 1 1 Adjacent synchronization: CPU and GPU In-place implementation will be possible Flags CPU temporary location In-Place Padding Pascal/Volta Unified Memory 97
- 98. Benefits of Collaboration Optimal number of devices is not always max AMD Kaveri (4 CPU cores + 8 GPU CUs) 98
- 99. 2 1 3 0 0 1 3 4 0 0 2 1 2 1 3 1 3 4 2 1 Predicate: Element > 0 Input Output Stream compaction Stream Compaction (I) Stream compaction Saving memory storage in sparse data Similar to padding, but local reduction result (non-zero element count) is propagated 99
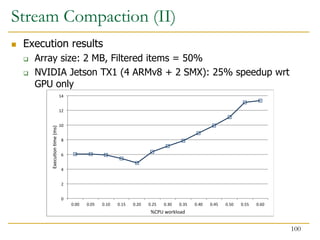
- 100. 0 2 4 6 8 10 12 14 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 0.55 0.60 Execu on me (ms) %CPU workload Stream Compaction (II) Execution results Array size: 2 MB, Filtered items = 50% NVIDIA Jetson TX1 (4 ARMv8 + 2 SMX): 25% speedup wrt GPU only 100
- 101. Benefits of Collaboration Data partitioning improves performance AMD Kaveri (4 CPU cores + 8 GPU CUs) 8 32 128 512 Execution Time ( ms ) 1 0.5 0 Stream Compaction (up to 82% improvement over GPU only) best 101
- 102. Breadth-First Search Small-sized and big-sized frontiers Top-down approach Kernel 1 and Kernel 2 Atomic-based block synchronization Avoids kernel re-launch Very small frontiers Underutilize GPU resources Collaborative implementation 102
- 103. SM#0 SM#1 Block 0 Block 1 Block 2 Block 3 Block 2n Block 2n Block 2n Block 2n Block 4 SM#0 SM#1 Block 0 Block 1 Block 2 Block 3 Block 2n Block 2n Block 2n Block 2n Block 4 Atomic-Based Block Synchronization (I) Combine Kernel 1 and Kernel 2 We can avoid kernel re-launch We need to use persistent thread blocks Kernel 2 launches (frontier_size / block_size) blocks Persistent blocks: up to (number_SMs x max_blocks_SM) 103
- 104. // GPU kernel const int gtid = blockIdx.x * blockDim.x + threadIdx.x; while(frontier_size != 0){ for(node = gtid; node < frontier_size; node += blockDim.x*gridDim.x){ // Visit neighbors // Enqueue in output queue if needed (global or local queue) } // Update frontier_size // Global synchronization } Atomic-Based Block Synchronization (II) Code (simplified) 104
- 105. const int tid = threadIdx.x; const int gtid = blockIdx.x * blockDim.x + threadIdx.x; atomicExch(ptr_threads_run, 0); atomicExch(ptr_threads_end, 0); int frontier = 0; ... frontier++; if(tid == 0){ atomicAdd(ptr_threads_end, 1); // Thread block finishes iteration } if(gtid == 0){ while(atomicAdd(ptr_threads_end, 0) != gridDim.x){;} // Wait until all blocks finish atomicExch(ptr_threads_end, 0); // Reset atomicAdd(ptr_threads_run, 1); // Count iteration } if(tid == 0 && gtid != 0){ while(atomicAdd(ptr_threads_run, 0) < frontier){;} // Wait until ptr_threads_run is updated } __syncthreads(); // Rest of threads wait here ... Atomic-Based Block Synchronization (III) Global synchronization (simplified) At the end of each iteration 105
- 106. Collaborative Implementation (I) Motivation Small-sized frontiers underutilize GPU resources NVIDIA Jetson TX1 (4 ARMv8 CPUs + 2 SMXs) New York City roads 106
- 107. Collaborative Implementation (II) Choose the most appropriate device CPU GPU small frontiers processed on CPU large frontiers processed on GPU 107
- 108. Choose CPU or GPU depending on frontier size CPU threads or GPU kernel keep running while the condition is satisfied // Host code while(frontier_size != 0){ if(frontier_size < LIMIT){ // Launch CPU threads } else{ // Launch GPU kernel } } Collaborative Implementation (III) 108
- 109. 15% Collaborative Implementation (IV) Execution results 109
- 110. // Host code while(frontier_size != 0){ if(frontier_size < LIMIT){ // Launch CPU threads } else{ // Copy from host to device (queues and synchronization variables) // Launch GPU kernel // Copy from device to host (queues and synchronization variables) } } Collaborative Implementation (V) Without Unified Memory Explicit memory copies 110
- 111. // Host code while(frontier_size != 0){ if(frontier_size < LIMIT){ // Launch CPU threads } else{ // Launch GPU kernel cudaDeviceSynchronize(); } } Collaborative Implementation (VI) Unified Memory cudaMallocManaged(); Easier programming No explicit memory copies 111
- 112. Collaborative Implementation (VII) Pascal/Volta Unified Memory CPU/GPU coherence System-wide atomic operations No need to re-launch kernel or CPU threads Possibility of CPU and GPU working on the same frontier 112
- 113. Benefits of Collaboration SSSP performs more computation than BFS 16 128 1024 8192 65536 524288 Execution Time ( ms ) NE NY UT Single Source Shortest Path (up to 22% improvement over GPU only) 113
- 114. Egomotion Compensation and Moving Objects Detection (I) Hexapod robot OSCAR Rescue scenarios Strong egomotion on uneven terrains Algorithm Random Sample Consensus (RANSAC): F-o-F model 114
- 115. Egomotion Compensation and Moving Objects Detection (II) 115
- 116. While (iteration < MAX_ITER){ Fitting stage (Compute F-o-F model) // SISD phase Evaluation stage (Count outliers) // SIMD phase Comparison to best model // SISD phase Check if best model is good enough and iteration >= MIN_ITER // SISD phase } SISD and SIMD phases RANSAC (Fischler et al. 1981) Fitting stage picks two flow vectors randomly Evaluation generates motion vectors from F-o-F model, and compares them to real flow vectors 116
- 117. Collaborative Implementation Randomly picked vectors: Iterations are independent We assign one iteration to one CPU thread and one GPU block 117
- 118. https://chai-benchmarks.github.io Chai Benchmark Suite (I) Collaboration patterns 8 data partitioning benchmarks 3 coarse-grain task partitioning benchmarks 3 fine-grain task partitioning benchmarks 118
- 119. Chai Benchmark Suite (II) 119
- 120. We did not cover the following slides in lecture. These are for your preparation for the next lecture.
- 121. Benefits of Unified Memory (I) 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 D U D U D U D U D U D U D U D U D U D U D U D U D U D U BS CEDDHSTIHSTOPADRSCD SC TRNS RSCT TQ TQH BFS CEDTSSSP Fine-grain Coarse-grain Data Partitioning Task Partitioning Execution Time ( normalized ) Kernel Comparable (same kernels, system-wide atomics make Unified sometimes slower) Unified kernels can exploit more parallelism Unified kernels avoid kernel launch overhead 121
- 122. Benefits of Unified Memory (II) 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 D U D U D U D U D U D U D U D U D U D U D U D U D U D U BS CEDDHSTIHSTOPADRSCD SC TRNS RSCT TQ TQH BFS CEDTSSSP Fine-grain Coarse-grain Data Partitioning Task Partitioning Execution Time ( normalized ) Kernel Copy Back & Merge Copy To Device Unified versions avoid copy overhead 122
- 123. Benefits of Unified Memory (III) 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 D U D U D U D U D U D U D U D U D U D U D U D U D U D U BS CEDDHSTIHSTOPADRSCD SC TRNS RSCT TQ TQH BFS CEDTSSSP Fine-grain Coarse-grain Data Partitioning Task Partitioning Execution Time ( normalized ) Kernel Copy Back & Merge Copy To Device Allocation SVM allocation seems to take longer 123
- 124. Benefits of Collaboration on FPGA (I) 0.0 0.2 0.4 0.6 0.8 1.0 1.2 C F C F C F C F C F C F C F C F CPU FPGA Data Task CPU FPGA Data Task Single device Collaborative Single device Collaborative Stratix V Arria 10 Execution Time (s) Idle Copy Compute Case Study: Canny Edge Detection Source: Collaborative Computing for Heterogeneous Integrated Systems. ICPE’17 Vision Track. Similar improvement from data and task partitioning 124
- 125. Benefits of Collaboration on FPGA (II) Case Study: Random Sample Consensus 0 5 10 15 20 25 30 35 40 45 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Execution Time (ms) Data Partitioning (Stratix V) Task Partitioning (Stratix V) Data Partitioning (Arria 10) Task Partitioning (Arria 10) Source: Collaborative Computing for Heterogeneous Integrated Systems. ICPE’17 Vision Track. Task partitioning exploits disparity in nature of tasks 125
- 126. Benefits of Collaboration on FPGA (III) 126 Sitao Huang, Li-Wen Chang, Izzat El Hajj, Simon Garcia De Gonzalo, Juan Gomez-Luna, Sai Rahul Chalamalasetti, Mohamed El-Hadedy, Dejan Milojicic, Onur Mutlu, Deming Chen, and Wen-mei Hwu, "Analysis and Modeling of Collaborative Execution Strategies for Heterogeneous CPU- FPGA Architectures" Proceedings of the 10th ACM/SPEC International Conference on Performance Engineering (ICPE), Mumbai, India, April 2019. [Slides (pptx) (pdf)] [Chai CPU-FPGA Benchmark Suite]
- 127. Conclusions Possibility of having CPU threads and GPU blocks collaborating on the same workload Or having the most appropriate cores for each workload Easier programming with Unified Memory or Shared Virtual Memory System-wide atomic operations in NVIDIA Pascal/Volta and HSA Fine-grain collaboration 127
- 128. Computer Architecture Lecture 17: GPU Programming Dr. Juan Gómez Luna Prof. Onur Mutlu ETH Zürich Fall 2019 21 November 2019