






















































Ad
More Related Content
What's hot (20)
Similar to Hadoop: A distributed framework for Big Data (20)


















Ad
Recently uploaded (20)




















Ad
Hadoop: A distributed framework for Big Data
- 2. What is Big-Data? What is Hadoop? Why Distributed File System? Hadoop Distributed File System (HDFS) Replication & Rack Awareness
- 3. Major Problems in Distributed File System Hadoop Computing Model(MapReduce) Advantages Of Hadoop Disadvantages Of Hadoop Prominent Users Tools
- 4. Big data refers to data volumes in the range of exabytes (1018) and beyond.i.e.large amount of data We define “Big Data” as the amount of data just beyond technology’s capability to store,manage and process efficiently.
- 6. Doug Cutting 2005: Doug Cutting and Michael J. Cafarella developed Hadoop to support distribution for the Nutch search engine project. The project was funded by Yahoo. 2006: Yahoo gave the project to Apache Software Foundation.
- 7. • Hadoop was created by Doug Cutting and Mike Cafarella in 2005. Cutting, who was working at Yahoo! • Hadoop is a software framework for distributed processing of large datasets across large clusters of computers • Hadoop is open-source implementation for Google MapReduce • Hadoop is based on a simple programming model called MapReduce
- 8. • Hadoop is based on a simple data model, any data will fit. • ApacheHadoop is an open-source software framework written in Java for distributed storage • Hadoop framework consists on two main layers • Distributed file system (HDFS) • Execution engine (MapReduce) • Hadoop is one time write many time read.
- 9. Parallel processing used in hadoop for processing data so less time required for processing huge amount of data.
- 10. Datanodes can be organized into racks
- 11. Single name node and many data nodes Name node maintains the file system metadata Files are split into fixed sized blocks and stored on data nodes (Default 64MB) Data blocks are replicated for fault tolerance and fast access (Default is 3) Datanodes periodically send heartbeats to namenode HDFS is a master-slave architecture Master: name node Slaves: data nodes (100s or 1000s of nodes)
- 13. Under Replication:- Total Replication < Replication Factor Over Replication:- Total Replication > Replication Factor
- 17. 1)Hardware Failure 2)Large Data Sets 3) Redundancy Of Data
- 18. Two main phases: Map and Reduce • Any job is converted into map and reduce tasks • Developers need ONLY to implement the Map and Reduce classes MapReduce is a master-slave architecture • Master: JobTracker • Slaves: TaskTrackers (100s or 1000s of tasktrackers) • Every data node is running a tasktracker
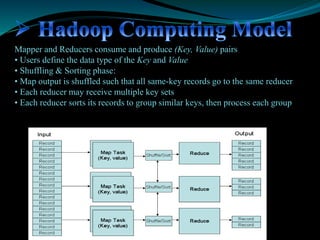
- 19. Mapper and Reducers consume and produce (Key, Value) pairs • Users define the data type of the Key and Value • Shuffling & Sorting phase: • Map output is shuffled such that all same-key records go to the same reducer • Each reducer may receive multiple key sets • Each reducer sorts its records to group similar keys, then process each group
- 20. Job: Count the occurrences of each word in a data set Map Tasks Reduce Tasks Reduce phase is optional: Jobs can be Map Only
- 22. 1)Security Concerns 2)Vulnerable By Nature 3)Not Fit for Small Data 4)Potential Stability Issues 5)General Limitations
- 23. 1)Yahoo! 2)Facebook 3)Hadoop hosting in the Cloud 4)Hadoop on Microsoft Azure 5)Hadoop on Amazon EC2/S3 services 6)Amazon Elastic MapReduce
- 24. NoSQL:- Databases,MongoDB, CouchDB, Cassandra, Redis, BigTable, Hbase, Hypertable, ZooKeeper . MapReduce :- Hadoop, Hive, Pig, Cascading, Caffeine, S4, MapR, Flume, Kafka, Oozie, Greenplum Storage:- S3, Hadoop Distributed File System
- 25. Servers :- EC2, Google App Engine, Elastic, Beanstalk. Processing :- R, Yahoo! Pipes, Mechanical Turk,ElasticSearch, BigSheets, Tinkerpop.