Hadoop and Graph Databases (Neo4j): Winning Combination for Bioanalytics - Jonathan Freeman @ GraphConnect NY 2013
19 likes16,753 views

This talk will describe a prototype application designed to demonstrate the ability to utilize both Hadoop and Neo4j for Big Data analysis.


































![Hadoop + Neo4j = Bioinformatics Win
Jonathan Freeman
@freethejazz
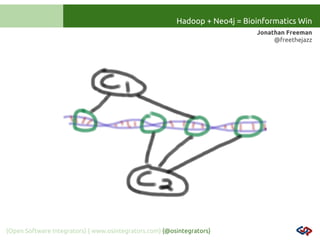
MATCH (snp)<-[:INFLUENCED_BY]-(conditions)
WHERE snp.id = “rs1234”
RETURN conditions;
{Open Software Integrators} { www.osintegrators.com} {@osintegrators}](https://image.slidesharecdn.com/hadoopandneo-bioanalytics-131108195004-phpapp01/85/Hadoop-and-Graph-Databases-Neo4j-Winning-Combination-for-Bioanalytics-Jonathan-Freeman-GraphConnect-NY-2013-36-320.jpg)
![Hadoop + Neo4j = Bioinformatics Win
Jonathan Freeman
@freethejazz
MATCH (p)-[:GENOME_CONTAINS]->(snp)
(snp)<-[:INFLUENCED_BY]-(conditions)
WHERE p.name = “Jonathan Freeman”
RETURN conditions;
{Open Software Integrators} { www.osintegrators.com} {@osintegrators}](https://image.slidesharecdn.com/hadoopandneo-bioanalytics-131108195004-phpapp01/85/Hadoop-and-Graph-Databases-Neo4j-Winning-Combination-for-Bioanalytics-Jonathan-Freeman-GraphConnect-NY-2013-37-320.jpg)
![Hadoop + Neo4j = Bioinformatics Win
Jonathan Freeman
@freethejazz
MATCH (p)-[:GENOME_CONTAINS]->(snp)
(snp)<-[:INFLUENCED_BY]-(conditions)
WHERE c.name = “Parkinsons”
RETURN p;
{Open Software Integrators} { www.osintegrators.com} {@osintegrators}](https://image.slidesharecdn.com/hadoopandneo-bioanalytics-131108195004-phpapp01/85/Hadoop-and-Graph-Databases-Neo4j-Winning-Combination-for-Bioanalytics-Jonathan-Freeman-GraphConnect-NY-2013-38-320.jpg)







































Ad
More Related Content
What's hot (20)
Similar to Hadoop and Graph Databases (Neo4j): Winning Combination for Bioanalytics - Jonathan Freeman @ GraphConnect NY 2013 (20)


















Ad
More from Neo4j (20)




















Ad
Recently uploaded (20)




















Hadoop and Graph Databases (Neo4j): Winning Combination for Bioanalytics - Jonathan Freeman @ GraphConnect NY 2013
- 1. {GraphConnect NYC} Hadoop and Graph Databases (Neo4j): Winning Combination for Bioinformatics Jonathan Freeman @freethejazz {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 2. Hadoop + Neo4j = Bioanalytics Win Open Software Integrators ● Jonathan Freeman @freethejazz Founded January 2008 by Andrew C. Oliver ○ Durham, NC Revenue and staff has at least doubled every year since 2009. ● New office (2012) in Chicago, IL ○ We're hiring associate to senior level as well as UI Developers (JQuery, Javascript, HTML, CSS) ○ Up to 50% travel (probably less), salary + bonus, 401k, health, etc etc ○ Preferred: Java, Tomcat, JBoss, Hibernate, Spring, RDBMS, JQuery ○ Nice to have: Hadoop, Neo4j, MongoDB, Ruby a/o at least one Cloud platform {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 3. Hadoop + Neo4j = Bioinformatics Win Questions to answer ● ● ● ● uhh, bioinformatics? What is Hadoop? Why is it a good fit? And Neo4j? Why the combination? I want this now! How do I do it?!?! {Open Software Integrators} { www.osintegrators.com} {@osintegrators} Jonathan Freeman @freethejazz
- 4. {Hadoop + Neo4j = Bioinformatics Win} Bioinformatics {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 5. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz “ dynamic information processing system {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 6. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz Life http://www.labtimes.org/labtimes/issues/lt2011/lt07/lt_2011_07_26_29.pdf {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 7. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz ● Storing/Retrieving Biological Data ● Organizing Biological Data ● Analyzing Biological Data {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 8. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz Biological Data ● amino acid sequences ● nucleotide sequences ● protein structures {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 9. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz ● ● ● ● ● Genetic sequence analysis Tracing biological evolution Analysis of gene expression Studying mutations in cancer Predicting protein structure and function ● Molecular Interaction {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 10. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz ● ● ● ● ● Genetic sequence analysis Tracing biological evolution Analysis of gene expression Studying mutations in cancer Predicting protein structure and function ● Molecular Interaction {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 11. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz Full Human Genome Sequencing Then 13 Years $2,700,000,000 {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 12. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz Full Human Genome Sequencing Then 1 Day {Open Software Integrators} { www.osintegrators.com} {@osintegrators} $5,000
- 13. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz http://www.genome.gov/images/content/cost_per_genome_apr.jpg {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 14. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz So what are we waiting for? {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 15. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 16. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz well, the thing about that… {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 17. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 18. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 19. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz ... ATTCCAGGAGTATTGACACCAT... {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 20. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 21. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 22. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 23. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz AGGATTACCAGGA CAAAGGATT TTACCAGGATACCAG TGACAA AAGGATTAC GATACCAGTA CAAGGATT GTGACAA {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 24. {Hadoop + Neo4j = Bioinformatics Win} Hadoop {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 25. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz Infrastructure for distributed computing HDFS MapReduce A distributed file system. An implementation of a programming model for processing very large data sets. {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 26. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz … {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 27. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 28. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 29. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz Infrastructure for distributed computing HDFS MapReduce A distributed file system. An implementation of a programming model for processing very large data sets. {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 30. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz AGGATTACCAGGA CAAAGGATT TTACCAGGATACCAG TGACAA AAGGATTAC GATACCAGTA CAAGGATT GTGACAA {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 31. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz ... ATTCCAGGAGTATTGACACCAT... {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 32. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz 1000 CPU hours {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 33. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz 3 hours $85 OSS http://bowtie-bio.sourceforge.net/crossbow/index.shtml {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 34. {Hadoop + Neo4j = Bioinformatics Win} And Neo4j? {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 35. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 36. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz MATCH (snp)<-[:INFLUENCED_BY]-(conditions) WHERE snp.id = “rs1234” RETURN conditions; {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 37. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz MATCH (p)-[:GENOME_CONTAINS]->(snp) (snp)<-[:INFLUENCED_BY]-(conditions) WHERE p.name = “Jonathan Freeman” RETURN conditions; {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 38. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz MATCH (p)-[:GENOME_CONTAINS]->(snp) (snp)<-[:INFLUENCED_BY]-(conditions) WHERE c.name = “Parkinsons” RETURN p; {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 39. {Hadoop + Neo4j = Bioinformatics Win} How can I haz?!?!?!1 {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 40. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz Step 1: Get local copies ● Hadoop: http://www.neo4j.org/download ● Neo4j: http://hadoop.apache.org/releases.html#Download ● Batch Importer: https://github.com/jexp/batch-import {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 41. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz Step 2: Familiarize yourself with the languages ● ● ● MapReduce: http://hadoop.apache.org/docs/r0.18.3/mapred_tutorial.html Pig: http://pig.apache.org/docs/r0.12.0/start.html Hive: https://cwiki.apache.org/confluence/display/Hive/GettingStarted {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 42. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz Step 3: Find a dataset ● ● Typical starter data: http://www.gutenberg.org/ Amazon’s public data sets: http://aws.amazon.com/publicdatasets/ {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 43. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz Step 4: Start Playing!!! {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 44. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz Step 5: Take Hadoop to the cloud ● http://aws.amazon.com/elasticmapreduce/ {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 45. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz Doing this in production? http://blog.xebia.com/2012/11/13/combining-neo4j-and-hadoop-part-i/ http://blog.xebia.com/2013/01/17/combining-neo4j-and-hadoop-part-ii/ {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 46. {Hadoop + Neo4j = Bioinformatics Win} Thank You @freethejazz {Open Software Integrators} { www.osintegrators.com} {@osintegrators}
- 47. Hadoop + Neo4j = Bioinformatics Win Jonathan Freeman @freethejazz Image Attribution: Sand Timer: http://bit.ly/HyCAgy Money: http://bit.ly/1e4lhS6 Scraggly DNA drawings: Jonathan Freeman :) {Open Software Integrators} { www.osintegrators.com} {@osintegrators}