Hadoop Demystified + MapReduce (Java and C#), Pig, and Hive Demos
Download as PPTX, PDF6 likes3,777 views

A walk-thru of core Hadoop, the ecosystem tools, and Hortonworks Data Platform (HDP) followed by code examples in MapReduce (Java and C#), Pig, and Hive. Presented at the Atlanta .NET User Group meeting in July 2014.









































![MapReduce Example: Reduce Phase
Page 44
• Input to the Reducer
• Notice keys are sorted and
associated values for same key
are in a single list
– Shuffle & Sort did this for us
• Output from the Reducer
• All done!
(‘I’, [1, 1, 1])
(‘Sam’, [1])
(‘am’, [1])
(‘and’, [1])
(‘eat’, [1, 1])
(‘eggs’, [1])
(‘green’, [1])
(‘ham’, [1])
(‘not’, [1, 1])
(‘them’, [1])
(‘will’, [1, 1])
(‘I’, 3)
(‘Sam’, 1)
(‘am’, 1)
(‘and’, 1)
(‘eat’, 2)
(‘eggs’, 1)
(‘green’, 1)
(‘ham’, 1)
(‘not’, 2)
(‘them’, 1)
(‘will’, 2)](https://image.slidesharecdn.com/hadoopdemystifiedatl-140728000121-phpapp02/85/Hadoop-Demystified-MapReduce-Java-and-C-Pig-and-Hive-Demos-42-320.jpg)





































Ad
More Related Content
What's hot (20)
Viewers also liked (20)














![[SSA] 04.sql on hadoop(2014.02.05)](https://cdn.slidesharecdn.com/ss_thumbnails/04-140225072610-phpapp01-thumbnail.jpg?width=560&fit=bounds)



Ad
Similar to Hadoop Demystified + MapReduce (Java and C#), Pig, and Hive Demos (20)




















Ad
Recently uploaded (20)




















Hadoop Demystified + MapReduce (Java and C#), Pig, and Hive Demos
- 1. Hadoop Demystified What is it? How does Microsoft fit in? and… of course… some demos! Presentation for ATL .NET User Group (July, 2014) Lester Martin Page 1
- 2. Agenda • Hadoop 101 –Fundamentally, What is Hadoop? –How is it Different? –History of Hadoop • Components of the Hadoop Ecosystem • MapReduce, Pig, and Hive Demos –Word Count –Open Georgia Dataset Analysis Page 2
- 3. Connection before Content • Lester Martin • Hortonworks – Professional Services • [email protected] • http://about.me/lestermartin (links to blog, github, twitter, LI, FB, etc) Page 3
- 4. © Hortonworks Inc. 2012 Scale-Out Processing Scalable, Fault Tolerant, Open Source Data Storage and Processing Page 7 MapReduce What is Core Apache Hadoop? Flexibility to Store and Mine Any Type of Data Ask questions that were previously impossible to ask or solve Not bound by a single, fixed schema Excels at Processing Complex Data Scale-out architecture divides workloads across multiple nodes Eliminates ETL bottlenecks Scales Economically Deployed on “commodity” hardware Open source platform guards against vendor lock Scale-Out Storage HDFS Scale-Out Resource Mgt YARN
- 5. The Need for Hadoop • Store and use all types of data • Process ALL the data; not just a sample • Scalability to 1000s of nodes • Commodity hardware Page 5
- 6. Relational Database vs. Hadoop Relational Hadoop Required on write schema Required on Read Reads are fast speed Writes are fast Standards and structure governance Loosely structured Limited, no data processing processing Processing coupled with data Structured data types Multi and unstructured Interactive OLAP Analytics Complex ACID Transactions Operational Data Store best fit use Data Discovery Processing unstructured data Massive storage/processing P
- 7. Fundamentally, a Simple Algorithm 1. Review stack of quarters 2. Count each year that ends in an even number Page 7
- 9. Distributed Algorithm – Map:Reduce Page 9 Map (total number of quarters) Reduce (sum each person’s total)
- 10. A Brief History of Apache Hadoop Page 10 2013 Focus on INNOVATION 2005: Hadoop created at Yahoo! Focus on OPERATIONS 2008: Yahoo team extends focus to operations to support multiple projects & growing clusters Yahoo! begins to Operate at scale Enterprise Hadoop Apache Project Established Hortonworks Data Platform 2004 2008 2010 20122006 STABILITY 2011: Hortonworks created to focus on “Enterprise Hadoop“. Starts with 24 key Hadoop engineers from Yahoo
- 11. HDP / Hadoop Components Page 11
- 12. HDP: Enterprise Hadoop Platform Page 12 Hortonworks Data Platform (HDP) • The ONLY 100% open source and complete platform • Integrates full range of enterprise-ready services • Certified and tested at scale • Engineered for deep ecosystem interoperability OS/VM Cloud Appliance PLATFORM SERVICES HADOOP CORE Enterprise Readiness High Availability, Disaster Recovery, Rolling Upgrades, Security and Snapshots HORTONWORKS DATA PLATFORM (HDP) OPERATIONAL SERVICES DATA SERVICES HDFS SQOOP FLUME NFS LOAD & EXTRACT WebHDFS KNOX* OOZIE AMBARI FALCON* YARN MAP TEZREDUCE HIVE & HCATALOG PIGHBASE
- 13. Typical Hadoop Cluster Page 13
- 14. HDFS - Writing Files Rack1 Rack2 Rack3 RackN request write Hadoop Client return DNs, etc. DN | NM DN | NM DN | NM DN | NM DN | NM DN | NM DN | NM DN | NM DN | NM DN | NM DN | NM DN | NM write blocks block report fs sync Backup NN per NN checkpoint Name Node
- 15. Hive • Data warehousing package built on top of Hadoop • Bringing structure to unstructured data • Query petabytes of data with HiveQL • Schema on read 1 • • – –
- 16. Hive: SQL-Like Interface to Hadoop • Provides basic SQL functionality using MapReduce to execute queries • Supports standard SQL clauses INSERT INTO SELECT FROM … JOIN … ON WHERE GROUP BY HAVING ORDER BY LIMIT • Supports basic DDL CREATE/ALTER/DROP TABLE, DATABASE Page 17
- 17. Hortonworks Investment in Apache Hive Batch AND Interactive SQL-IN-Hadoop Stinger Initiative A broad, community-based effort to drive the next generation of HIVE Page 18 Stinger Phase 3 • Hive on Apache Tez • Query Service (always on) • Buffer Cache • Cost Based Optimizer (Optiq) Stinger Phase 1: • Base Optimizations • SQL Types • SQL Analytic Functions • ORCFile Modern File Format Stinger Phase 2: • SQL Types • SQL Analytic Functions • Advanced Optimizations • Performance Boosts via YARN Speed Improve Hive query performance by 100X to allow for interactive query times (seconds) Scale The only SQL interface to Hadoop designed for queries that scale from TB to PB Goals: …70% complete in 6 months…all IN Hadoop SQL Support broadest range of SQL semantics for analytic applications running against Hadoop
- 18. Stinger: Enhancing SQL Semantics Page 19 Hive SQL Datatypes Hive SQL Semantics INT SELECT, LOAD, INSERT from query TINYINT/SMALLINT/BIGINT Expressions in WHERE and HAVING BOOLEAN GROUP BY, ORDER BY, SORT BY FLOAT Sub-queries in FROM clause DOUBLE GROUP BY, ORDER BY STRING CLUSTER BY, DISTRIBUTE BY TIMESTAMP ROLLUP and CUBE BINARY UNION DECIMAL LEFT, RIGHT and FULL INNER/OUTER JOIN ARRAY, MAP, STRUCT, UNION CROSS JOIN, LEFT SEMI JOIN CHAR Windowing functions (OVER, RANK, etc.) VARCHAR INTERSECT, EXCEPT, UNION DISTINCT DATE Sub-queries in HAVING Sub-queries in WHERE (IN/NOT IN, EXISTS/NOT EXISTS Hive 0.10 Hive 12 Hive 0.11 Compete Subset Hive 13
- 19. Pig • Pig was created at Yahoo! to analyze data in HDFS without writing Map/Reduce code. • Two components: – SQL like processing language called “Pig Latin” – PIG execution engine producing Map/Reduce code • Popular uses: – ETL at scale (offloading) – Text parsing and processing to Hive or HBase – Aggregating data from multiple sources • • •
- 20. Pig Sample Code to find dropped call data: 4G_Data = LOAD ‘/archive/FDR_4G.txt’ using TextLoader(); Customer_Master = LOAD ‘masterdb.customer_data’ using HCatLoader(); 4G_Data_Full = JOIN 4G_Data by customerID, CustomerMaster by customerID; X = FILTER 4G_Data_Full BY State == ‘call_dropped’; • • •
- 21. Typical Data Analysis Workflow
- 22. Powering the Modern Data Architecture HADOOP 2.0 Multi Use Data Platform Batch, Interactive, Online, Streaming, … Page 23 Interact with all data in multiple ways simultaneously Redundant, Reliable Storage HDFS 2 Cluster Resource Management YARN Standard SQL Processing Hive Batch MapReduce Interactive Tez Online Data Processing HBase, Accumulo Real Time Stream Processing Storm others … HADOOP 1.0 HDFS 1 (redundant, reliable storage) MapReduce (distributed data processing & cluster resource management) Single Use System Batch Apps Data Processing Frameworks (Hive, Pig, Cascading, …)
- 23. Word Counting Time!! Hadoop’s “Hello Whirled” Example A quick refresher of core elements of Hadoop and then code walk-thrus with Java MapReduce and Pig Page 25
- 24. Core Hadoop Concepts • Applications are written in high-level code –Developers need not worry about network programming, temporal dependencies or low-level infrastructure • Nodes talk to each other as little as possible –Developers should not write code which communicates between nodes –“Shared nothing” architecture • Data is spread among machines in advance –Computation happens where the data is stored, wherever possible – Data is replicated multiple times on the system for increased availability and reliability Page 26
- 25. Hadoop: Very High-Level Overview • When data is loaded in the system, it is split into “blocks” –Typically 64MB or 128MB • Map tasks (first part of MapReduce) work on relatively small portions of data –Typically a single block • A master program allocates work to nodes such that a Map tasks will work on a block of data stored locally on that node whenever possible –Many nodes work in parallel, each on their own part of the overall dataset Page 27
- 26. Fault Tolerance • If a node fails, the master will detect that failure and re-assign the work to a different node on the system • Restarting a task does not require communication with nodes working on other portions of the data • If a failed node restarts, it is automatically added back to the system and assigned new tasks • If a nodes appears to be running slowly, the master can redundantly execute another instance of the same task –Results from the first to finish will be used –Known as “speculative execution” Page 28
- 27. Hadoop Components • Hadoop consists of two core components –The Hadoop Distributed File System (HDFS) –MapReduce • Many other projects based around core Hadoop (the “Ecosystem”) –Pig, Hive, Hbase, Flume, Oozie, Sqoop, Datameer, etc • A set of machines running HDFS and MapReduce is known as a Hadoop Cluster –Individual machines are known as nodes –A cluster can have as few as one node, as many as several thousand – More nodes = better performance! Page 29
- 28. Hadoop Components: HDFS • HDFS, the Hadoop Distributed File System, is responsible for storing data on the cluster • Data is split into blocks and distributed across multiple nodes in the cluster –Each block is typically 64MB (the default) or 128MB in size • Each block is replicated multiple times –Default is to replicate each block three times –Replicas are stored on different nodes – This ensures both reliability and availability Page 30
- 29. HDFS Replicated Blocks Visualized Page 31
- 30. HDFS *is* a File System • Screenshot for “Name Node UI” Page 32
- 31. Accessing HDFS • Applications can read and write HDFS files directly via a Java API • Typically, files are created on a local filesystem and must be moved into HDFS • Likewise, files stored in HDFS may need to be moved to a machine’s local filesystem • Access to HDFS from the command line is achieved with the hdfs dfs command –Provides various shell-like commands as you find on Linux –Replaces the hadoop fs command • Graphical tools available like the Sandbox’s Hue File Browser and Red Gate’s HDFS Explorer Page 33
- 32. hdfs dfs Examples • Copy file foo.txt from local disk to the user’s directory in HDFS –This will copy the file to /user/username/fooHDFS.txt • Get a directory listing of the user’s home directory in HDFS • Get a directory listing of the HDFS root directory Page 34 hdfs dfs –put fooLocal.txt fooHDFS.txt hdfs dfs –ls hdfs dfs –ls /
- 33. hdfs dfs Examples (continued) • Display the contents of a specific HDFS file • Move that file back to the local disk • Create a directory called input under the user’s home directory • Delete the HDFS directory input and all its contents Page 35 hdfs dfs –cat /user/fred/fooHDFS.txt hdfs dfs –mkdir input hdfs dfs –rm –r input hdfs dfs –get /user/fred/fooHDFS.txt barLocal.txt
- 34. Hadoop Components: MapReduce • MapReduce is the system used to process data in the Hadoop cluster • Consists of two phases: Map, and then Reduce –Between the two is a stage known as the shuffle and sort • Each Map task operates on a discrete portion of the overall dataset –Typically one HDFS block of data • After all Maps are complete, the MapReduce system distributes the intermediate data to nodes which perform the Reduce phase –Source code examples and live demo coming! Page 36
- 35. Features of MapReduce • Hadoop attempts to run tasks on nodes which hold their portion of the data locally, to avoid network traffic • Automatic parallelization, distribution, and fault- tolerance • Status and monitoring tools • A clean abstraction for programmers –MapReduce programs are usually written in Java – Can be written in any language using Hadoop Streaming – All of Hadoop is written in Java –With “housekeeping” taken care of by the framework, developers can concentrate simply on writing Map and Reduce functions Page 37
- 37. Detailed Administrative Console • Screenshot from “Job Tracker UI” Page 39
- 38. MapReduce: The Mapper • The Mapper reads data in the form of key/value pairs (KVPs) • It outputs zero or more KVPs • The Mapper may use or completely ignore the input key –For example, a standard pattern is to read a line of a file at a time – The key is the byte offset into the file at which the line starts – The value is the contents of the line itself – Typically the key is considered irrelevant with this pattern • If the Mapper writes anything out, it must in the form of KVPs –This “intermediate data” is NOT stored in HDFS (local storage only without replication) Page 40
- 39. MapReducer: The Reducer • After the Map phase is over, all the intermediate values for a given intermediate key are combined together into a list • This list is given to a Reducer –There may be a single Reducer, or multiple Reducers –All values associated with a particular intermediate key are guaranteed to go to the same Reducer –The intermediate keys, and their value lists, are passed in sorted order • The Reducer outputs zero or more KVPs –These are written to HDFS –In practice, the Reducer often emits a single KVP for each input key Page 41
- 40. MapReduce Example: Word Count • Count the number of occurrences of each word in a large amount of input data Page 42 map(String input_key, String input_value) foreach word in input_value: emit(w,1) reduce(String output_key, Iter<int> intermediate_vals) set count = 0 foreach val in intermediate_vals: count += val emit(output_key, count)
- 41. MapReduce Example: Map Phase Page 43 • Input to the Mapper • Ignoring the key – It is just an offset • Output from the Mapper • No attempt is made to optimize within a record in this example – This is a great use case for a “Combiner” (8675, ‘I will not eat green eggs and ham’) (8709, ‘I will not eat them Sam I am’) (‘I’, 1), (‘will’, 1), (‘not’, 1), (‘eat’, 1), (‘green’, 1), (‘eggs’, 1), (‘and’, 1), (‘ham’, 1), (‘I’, 1), (‘will’, 1), (‘not’, 1), (‘eat’, 1), (‘them’, 1), (‘Sam’, 1), (‘I’, 1), (‘am’, 1)
- 42. MapReduce Example: Reduce Phase Page 44 • Input to the Reducer • Notice keys are sorted and associated values for same key are in a single list – Shuffle & Sort did this for us • Output from the Reducer • All done! (‘I’, [1, 1, 1]) (‘Sam’, [1]) (‘am’, [1]) (‘and’, [1]) (‘eat’, [1, 1]) (‘eggs’, [1]) (‘green’, [1]) (‘ham’, [1]) (‘not’, [1, 1]) (‘them’, [1]) (‘will’, [1, 1]) (‘I’, 3) (‘Sam’, 1) (‘am’, 1) (‘and’, 1) (‘eat’, 2) (‘eggs’, 1) (‘green’, 1) (‘ham’, 1) (‘not’, 2) (‘them’, 1) (‘will’, 2)
- 43. Code Walkthru & Demo Time!! • Word Count Example –Java MapReduce –Pig Page 45
- 44. Additional Demonstrations A Real-World Analysis Example Compare/contrast solving the same problem with Java MapReduce, Pig, and Hive Page 46
- 45. Dataset: Open Georgia • Salaries & Travel Reimbursements –Organization – Local Boards of Education – Several Atlanta-area districts; multiple years – State Agencies, Boards, Authorities and Commissions – Dept of Public Safety; 2010 Page 47
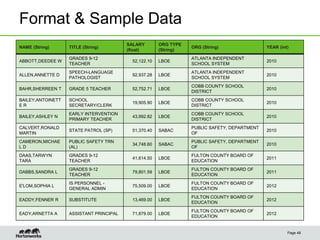
- 46. Format & Sample Data Page 48 NAME (String) TITLE (String) SALARY (float) ORG TYPE (String) ORG (String) YEAR (int) ABBOTT,DEEDEE W GRADES 9-12 TEACHER 52,122.10 LBOE ATLANTA INDEPENDENT SCHOOL SYSTEM 2010 ALLEN,ANNETTE D SPEECH-LANGUAGE PATHOLOGIST 92,937.28 LBOE ATLANTA INDEPENDENT SCHOOL SYSTEM 2010 BAHR,SHERREEN T GRADE 5 TEACHER 52,752.71 LBOE COBB COUNTY SCHOOL DISTRICT 2010 BAILEY,ANTOINETT E R SCHOOL SECRETARY/CLERK 19,905.90 LBOE COBB COUNTY SCHOOL DISTRICT 2010 BAILEY,ASHLEY N EARLY INTERVENTION PRIMARY TEACHER 43,992.82 LBOE COBB COUNTY SCHOOL DISTRICT 2010 CALVERT,RONALD MARTIN STATE PATROL (SP) 51,370.40 SABAC PUBLIC SAFETY, DEPARTMENT OF 2010 CAMERON,MICHAE L D PUBLIC SAFETY TRN (AL) 34,748.60 SABAC PUBLIC SAFETY, DEPARTMENT OF 2010 DAAS,TARWYN TARA GRADES 9-12 TEACHER 41,614.50 LBOE FULTON COUNTY BOARD OF EDUCATION 2011 DABBS,SANDRA L GRADES 9-12 TEACHER 79,801.59 LBOE FULTON COUNTY BOARD OF EDUCATION 2011 E'LOM,SOPHIA L IS PERSONNEL - GENERAL ADMIN 75,509.00 LBOE FULTON COUNTY BOARD OF EDUCATION 2012 EADDY,FENNER R SUBSTITUTE 13,469.00 LBOE FULTON COUNTY BOARD OF EDUCATION 2012 EADY,ARNETTA A ASSISTANT PRINCIPAL 71,879.00 LBOE FULTON COUNTY BOARD OF EDUCATION 2012
- 47. Simple Use Case • For all loaded State of Georgia salary information –Produce statistics for each specific job title – Number of employees – Salary breakdown – Minimum – Maximum – Average –Limit the data to investigate – Fiscal year 2010 – School district employees Page 49
- 48. Code Walkthru & Demo; Part Deux! • Word Count Example –Java MapReduce –Pig –Hive Page 50
- 49. Demo Wrap-Up • All code, test data, wiki pages, and blog posting can be found, or linked to, from –https://github.com/lestermartin/hadoop-exploration • This deck can be found on SlideShare –http://www.slideshare.net/lestermartin • Questions? Page 51
- 50. Thank You!! • Lester Martin • Hortonworks – Professional Services • [email protected] • http://about.me/lestermartin (links to blog, github, twitter, LI, FB, etc) Page 52
Editor's Notes
- #6: Hadoop fills several important needs in your data storage and processing infrastructure Store and use all types of data: Allows semi-structured, unstructured and structured data to be processed in a way to create new insights of significant business value. Process all the data: Instead of looking at samples of data or small sections of data, organizations can look at large volumes of data to get new perspective and make business decisions with higher degree of accuracy. Scalability: Reducing latency in business is critical for success. The massive scalability of Big Data systems allow organizations to process massive amounts of data in a fraction of the time required for traditional systems. Commodity hardware: Self-healing, extremely scalable, highly available environment with cost-effective commodity hardware.
- #7: KEY CALLOUT: Schema on Read IMPORTANT NOTE: Hadoop is not meant to replace your relational database. Hadoop is for storing Big Data, which is often the type of data that you would otherwise not store in a database due to size or cost constraints You will still have your database for relational, transactional data.
- #11: I can’t really talk about Hortonworks without first taking a moment to talk about the history of Hadoop. What we now know of as Hadoop really started back in 2005, when the team at yahoo! – started to work on a project that to build a large scale data storage and processing technology that would allow them to store and process massive amounts of data to underpin Yahoo’s most critical application, Search. The initial focus was on building out the technology – the key components being HDFS and MapReduce – that would become the Core of what we think of as Hadoop today, and continuing to innovate it to meet the needs of this specific application. By 2008, Hadoop usage had greatly expanded inside of Yahoo, to the point that many applications were now using this data management platform, and as a result the team’s focus extended to include a focus on Operations: now that applications were beginning to propagate around the organization, sophisticated capabilities for operating it at scale were necessary. It was also at this time that usage began to expand well beyond Yahoo, with many notable organizations (including Facebook and others) adopting Hadoop as the basis of their large scale data processing and storage applications and necessitating a focus on operations to support what as by now a large variety of critical business applications. In 2011, recognizing that more mainstream adoption of Hadoop was beginning to take off and with an objective of facilitating it, the core team left – with the blessing of Yahoo – to form Hortonworks. The goal of the group was to facilitate broader adoption by addressing the Enterprise capabilities that would would enable a larger number of organizations to adopt and expand their usage of Hadoop. [note: if useful as a talk track, Cloudera was formed in 2008 well BEFORE the operational expertise of running Hadoop at scale was established inside of Yahoo]
- #18: SQL is a query language Declarative, what not how Oriented around answering a question Requires uniform schema Requires metadata Known by everyone A great choice for answering queries, building reports, use with automated tools
- #20: With Hive and Stinger we are focused on enabling the SQL ecosystem and to do that we’ve put Hive on a clear roadmap to SQL compliance. That includes adding critical datatypes like character and date types as well as implementing common SQL semantics seen in most databases.
- #35: “hdfs dfs” is the *new* “hadoop fs” Blank acts like ~
- #36: These two slides were just to make folks feel at home with CLI access to HDFS
- #48: See https://martin.atlassian.net/wiki/x/FwAvAQ for more details Surely not the typical Volume/Velocity/Variety definition of “Big Data”, but gives us a controlled environment to do some simple prototyping and validating with
- #49: See https://martin.atlassian.net/wiki/x/NYBmAQ for more details
- #51: See https://martin.atlassian.net/wiki/x/FwAvAQ for more information