Hadoop Interview Questions And Answers Part-1 | Big Data Interview Questions & Answers | Simplilearn

This video on Hadoop interview questions part-1 will take you through the general Hadoop questions and questions on HDFS, MapReduce and YARN, which are very likely to be asked in any Hadoop interview. It covers all the topics on the major components of Hadoop. This Hadoop tutorial will give you an idea about the different scenario-based questions you could face and some multiple-choice questions as well. Now, let us dive into this Hadoop interview questions video and gear up for youe next Hadoop Interview. What is this Big Data Hadoop training course about? The Big Data Hadoop and Spark developer course have been designed to impart an in-depth knowledge of Big Data processing using Hadoop and Spark. The course is packed with real-life projects and case studies to be executed in the CloudLab. What are the course objectives? This course will enable you to: 1. Understand the different components of the Hadoop ecosystem such as Hadoop 2.7, Yarn, MapReduce, Pig, Hive, Impala, HBase, Sqoop, Flume, and Apache Spark 2. Understand Hadoop Distributed File System (HDFS) and YARN as well as their architecture, and learn how to work with them for storage and resource management 3. Understand MapReduce and its characteristics, and assimilate some advanced MapReduce concepts 4. Get an overview of Sqoop and Flume and describe how to ingest data using them 5. Create database and tables in Hive and Impala, understand HBase, and use Hive and Impala for partitioning 6. Understand different types of file formats, Avro Schema, using Arvo with Hive, and Sqoop and Schema evolution 7. Understand Flume, Flume architecture, sources, flume sinks, channels, and flume configurations 8. Understand HBase, its architecture, data storage, and working with HBase. You will also understand the difference between HBase and RDBMS 9. Gain a working knowledge of Pig and its components 10. Do functional programming in Spark 11. Understand resilient distribution datasets (RDD) in detail 12. Implement and build Spark applications 13. Gain an in-depth understanding of parallel processing in Spark and Spark RDD optimization techniques 14. Understand the common use-cases of Spark and the various interactive algorithms 15. Learn Spark SQL, creating, transforming, and querying Data frames Learn more at https://www.simplilearn.com/big-data-and-analytics/big-data-and-hadoop-training





















![How to copy data from local system on to HDFS?
Following command helps to copy data from local file system into HDFS:
hadoop fs –copyFromLocal [source] [destination]
Example: hadoop fs –copyFromLocal /tmp/data.csv /user/test/data.csv
14](https://image.slidesharecdn.com/hadoopinterviewquestions-part1-190531091226/85/Hadoop-Interview-Questions-And-Answers-Part-1-Big-Data-Interview-Questions-Answers-Simplilearn-22-320.jpg)






































































More Related Content
What's hot (20)
Similar to Hadoop Interview Questions And Answers Part-1 | Big Data Interview Questions & Answers | Simplilearn (20)


















More from Simplilearn (20)




















Recently uploaded (20)




















Hadoop Interview Questions And Answers Part-1 | Big Data Interview Questions & Answers | Simplilearn
- 3. What are the different vendor specific distributions of Hadoop?1
- 4. What are the different Hadoop configuration files? hadoop-env.sh core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml Master and slaves 2
- 5. What are the 3 modes in which Hadoop can run? Standalone mode Pseudo-distributed mode 1 2 3 Fully-distributed mode This is the default mode. It uses the local filesystem and a single Java process to run the Hadoop services It uses a single node Hadoop deployment to execute all the Hadoop services It uses separate nodes to run Hadoop master and slave services 3
- 6. What are the differences between Regular file system and HDFS?4 1 2 3 1 2 3 Regular File System HDFS Data is maintained in a single system If the machine crashes, data recovery is very difficult due to low fault tolerance Seek time is more and hence it takes more time to process the data Data is distributed and maintained on multiple systems If a datanode crashes, data can still be recovered from other nodes in the cluster Time taken to read data is comparatively more as there is local data read to disc and coordination of data from multiple systems
- 8. Why is HDFS fault tolerant? HDFS is fault tolerant as it replicates data on different datanodes. By default, a block of data gets replicated on 3 datanodes. Data Data block1 Data block2 Data block3 Data gets divided into multiple blocks Data blocks are stored in different datanodes. If one node crashes, the data can still be retrieved from other datanodes. This makes HDFS fault tolerant 5
- 9. Explain the architecture of HDFS. Namenode Client MetaData (Name, replicas, ….): /home/foo/data, 3, …. Metadata ops Block ops Rack 1 DatanodesDatanodes Rack 2 Client Write Write Replication Read 6
- 10. Explain the architecture of HDFS. Namenode Client MetaData (Name, replicas, ….): /home/foo/data, 3, …. Metadata ops Block ops Rack 1 DatanodesDatanodes Rack 2 Client Write Write Replication Read NameNode is the master severs that host metadata in disc and RAM. It holds information about the various datanodes, their location, the size of each block, etc. Namenode Metadata in Disk Edit log Fsimage Metadata in RAM Metadata (Name, replicas,….): /home/foo/data, 3, … 6
- 11. Explain the architecture of HDFS. Namenode Client MetaData (Name, replicas, ….): /home/foo/data, 3, …. Metadata ops Block ops Rack 1 DatanodesDatanodes Rack 2 Client Write Write Replication Read • Datanodes hold the actual data blocks and send block reports to Namenode every 10 seconds. • Datanode stores and retrieves the blocks when asked by the Namenode. It reads and writes client’s request and performs block creation, deletion and replication on instruction from the Namenode 6
- 12. What are the 2 types of metadata a Namenode server holds? Namenode server Metadata in Disk Metadata in RAM Edit log Fsimage Metadata (Name, replicas,….): /home/foo/data, 3, … 7
- 13. What is difference between Federation and High Availability? HDFS Federation HDFS High Availability There is no limitation to the number of namenodes and the namenodes are not related to each other There are 2 namenodes which are related to each other. Both active and standby namenodes work all the time All the namenodes share a pool of metadata in which each namenode will have its dedicated pool At a time, active namenode will be up and running while standby namenode will be idle and updating it’s metadata once in a while Provides fault tolerance i.e. if one namenode goes down, that will not affect the data of the other namenode Requires two separate machines. On first, the active namenode will be configured while the secondary namenode will be configured on the other system 8
- 14. If you have an input file of 350 MB, how many input splits will be created by HDFS and what is the size of each input split? 128 MB 350 MB Data 128 MB 94 MB • Each block by default is divided into 128 MB. • The size of all blocks except the last block will be 128 MB. • So, there are 3 input splits in total. • The size of each split is 128 MB, 128 MB and 94 MB. 9
- 15. How does Rack Awareness work in HDFS? HDFS Rack Awareness is about having knowledge of different data nodes and how it is distributed across the racks of a Hadoop Cluster Block A Block B Block C By default, each block of data gets replicated thrice on various datanodes present on different racks 10
- 16. How does Rack Awareness work in HDFS? HDFS Rack Awareness is about having knowledge of different data nodes and how it is distributed across the racks of a Hadoop Cluster Block A Block B Block C 2 identical blocks cannot be placed on the same datanode 10
- 17. How does Rack Awareness work in HDFS? HDFS Rack Awareness is about having knowledge of different data nodes and how it is distributed across the racks of a Hadoop Cluster Block A Block B Block C When a cluster is rack aware, all the replicas of a block cannot be placed on the same rack 10
- 18. How does Rack Awareness work in HDFS? HDFS Rack Awareness is about having knowledge of different data nodes and how it is distributed across the racks of a Hadoop Cluster Block A Block B Block C If a datanode crashes, you can retrieve the data block from different datanodes 10
- 19. How can you restart Namenode and all the daemons in Hadoop? Following are the methods to do so: Stop the Namenode with ./sbin /Hadoop-daemon.sh stop namenode and then start the Namenode using ./sbin/Hadoop-daemon.sh start namenode Stop all the daemons with ./sbin /stop-all.sh and then start the daemons using ./sbin/start-all.sh 1 2 11
- 20. Which command will help you find the status of blocks and filesystem health? hdfs fsck <path> -files -blocks hdfs fsck / -files –blocks –locations > dfs-fsck.log To check the status of the blocks To check the health status of filesystem 12
- 21. What would happen if you store too many small files in a cluster on HDFS? small files • Storing a lot of small files on HDFS generates a lot of metadata files • Storing these metadata in the RAM is a challenge as each file, block or directory takes 150 bytes just for metadata • Thus, the cumulative size of all the metadata will be too big 13
- 22. How to copy data from local system on to HDFS? Following command helps to copy data from local file system into HDFS: hadoop fs –copyFromLocal [source] [destination] Example: hadoop fs –copyFromLocal /tmp/data.csv /user/test/data.csv 14
- 23. When do you use dfsadmin –refreshNodes and rmadmin –refreshNodes command? dfsadmin -refreshNodes This is used to run HDFS client and it refreshes node configuration for the NameNode rmadmin -refreshNodes This is used to perform administrative tasks for ResourceManager 15 These commands are used to refresh the node information while commissioning or decommissioning of nodes is done
- 24. Is there anyway to change replication of files on HDFS after they are already written to HDFS? 16 Following are the ways to change the replication of files on HDFS: We can change the dfs.replication value to a particular number in $HADOOP_HOME/conf/hadoop-site.xml file which will start replicating to the factor of that number for any new content that comes in If you want to change the replication factor for a particular file or directory, then use: $HADOOP_HOME/bin/Hadoop dfs –setrep –w4 /path of the file Example: $HADOOP_HOME/bin/Hadoop dfs –setrep –w4 /user/temp/test.csv
- 25. Who takes care of replication consistency in a Hadoop cluster and what do you mean by under/over replicated blocks? 17 NameNode Namenode takes care of replication consistency in a Hadoop cluster and fsck command gives the information regarding over and under replicated block Under-replicated blocks: • These are blocks that do not meet their target replication for the file they belong to • HDFS will automatically create new replicas of under-replicated blocks until they meet the target replication Over-replicated blocks: • These are blocks that exceed their target replication for the file they belong to • Normally, over-replication is not a problem, and HDFS will automatically delete excess replicas
- 27. What is distributed cache in MapReduce? It is a mechanism supported by the Hadoop MapReduce framework. The data coming from the disk can be cached and made available for all worker nodes where the map/reduce tasks are running for a given job Once a file is cached for our job, Hadoop will make it available on each datanode where map/reduce tasks are running Copy the file to HDFS: $ hdfs dfs-put /user/Simplilearn/lib/jar_file.jar DistributedCache.addFileToClasspath(new path(“/user/Simplilearn/lib/jar_file.jar”), conf) Setup the application’s JobConf: Add it in Driver class 18
- 28. What role do RecordReader, Combiner and Partitioner play in a MapReduce operation? RecordReader RecordReader communicates with the InputSplit and converts the data into key-value pairs suitable for reading by the mapper Combiner Combiner is also known as the mini reducer and for every combiner, there is one mapper. It substitutes intermediate key value pairs and passes it to the partitioner Partitioner Partitioner decides how many reduced tasks would be used to summarize the data. Partitioner also confirms how outputs from the combiners are sent to the reducers. It controls the partitioning of keys of the intermediate map outputs 19
- 29. Why is MapReduce slower in processing data in comparision to other processing frameworks? 20 MapReduce uses batch processing to process data Mostly uses Java language which is difficult to program as it has multiple lines of code Reads data from the disk and, after a particular iteration, sends results to the HDFS. Such a process increases latency and makes graph processing slow
- 30. For a MapReduce job, is it possible to change the number of mappers to be created? 21 By default, the number of mappers is always equal to the number of input splits. So, it cannot be changed Example: If you have 1GB of file that is split into 8 blocks (of 128MB each), so there will be only 8 mappers running on the cluster But, there are different ways in which you can either set a property or customize your code to change the number of mappers
- 31. Name some Hadoop specific data types that are used in a MapReduce program. 22 Following are some Hadoop specific data types used in a MapReduce program: IntWritable FloatWritable LongWritable BooleanWritableDoubleWritable ArrayWritable MapWritable ObjectWritable
- 32. What is speculative execution in Hadoop?23 • If a datanode is executing any task slowly, the master node can redundantly execute another instance of the same task on another node • The task that finishes first will be accepted and the other task is killed
- 33. What is speculative execution in Hadoop? Scheduler Node A Task slow Task progress 23 • If a datanode is executing any task slowly, the master node can redundantly execute another instance of the same task on another node • The task that finishes first will be accepted and the other task is killed
- 34. What is speculative execution in Hadoop? Scheduler Node A Task slow Task progress Node B Task duplicate Launch speculative 23 • If a datanode is executing any task slowly, the master node can redundantly execute another instance of the same task on another node • The task that finishes first will be accepted and the other task is killed
- 35. What is speculative execution in Hadoop? Output Node A Task slow Node B Task duplicate 23 • If a datanode is executing any task slowly, the master node can redundantly execute another instance of the same task on another node • The task that finishes first will be accepted and the other task is killed
- 36. What is speculative execution in Hadoop? Output Node A Task slow Node B Task duplicate If Node A task is slower, then the output is accepted from Node B 23 • If a datanode is executing any task slowly, the master node can redundantly execute another instance of the same task on another node • The task that finishes first will be accepted and the other task is killed
- 37. How is identity mapper different from chain mapper? Identity Mapper Chain Mapper It the default mapper which is chosen when no mapper is specified in MapReduce driver class It implements identity function, which directly writes all its key-value pairs into output This class is used to run multiple mappers in a single map task It is defined in org.apache.Hadoop.mapreduce.lib.chain.ChainMapper package It is defined in old MapReduce API (MR1) in org.apache.Hadoop.mapred.lib.package The output of the first mapper becomes the input to the second mapper, second to third and so on 24
- 38. What are the major configuration parameters required in a MapReduce program? Input location of the job in HDFS Output location of the job in HDFS Input and output format Classes containing map and reduce functions .jar file for mapper, reducer and driver classes 1 2 3 4 5 25
- 39. What do you mean by map-side join and reduce-side join in MapReduce? Map-side join Reduce-side join Here the join is performed by the mapper Here the join is performed by the reducer Each input data must be divided in same number of partitions Input to each map is in the form of a structured partition and is in sorted order No need to have the dataset in a structured form (or partitioned) Easier to implement than the map side join as the sorting and shuffling phase sends the values having identical keys to the same reducer 26
- 40. What is the role of OutputCommitter class in a MapReduce job? OutputCommitter describes the commit of task output for a MapReduce job Example: org.apache.hadoop.mapreduce.OutputCommitter public abstract class OutputCommmitter extends OutputCommitter 27 MapReduce framework relies on the OutputCommitter of the job to: • Set’s up the job initialization • Cleanup the job after the job completion • Setup the task temporary output • Check whether a task need a commit • Commit of the task output • Discard the task commit
- 41. Explain the process of spilling in MapReduce. • Spilling is a process of copying the data from memory buffer to disc when the content of the buffer reaches a certain threshold size • Spilling happens when there is not enough memory to fit all of the mapper output 28 • By default, a background thread starts spilling the content from memory to disc after 80% of the buffer size is filled • For a 100 MB size buffer, the spilling will start after the content of the buffer reach a size of 80 MB
- 42. How can you set the mappers and reducers for a MapReduce job? The number of mappers and reducers can be set in the command line using: -D mapred.map.tasks=5 –D mapred.reduce.tasks=2 In the code, one can configure JobConf variables: job.setNumMapTasks(5); // 5 mappers job.setNumReduceTasks(2); // 2 reducers 29
- 43. What happens when a node running a map task fails before sending the output to the reducer? If such a case happens, map tasks will be assigned to a new node and the whole task will be run again to re-create the map output Map Task New node Run again to create the map output 30
- 44. Can we write the output of MapReduce in different formats? Yes, we can write the output of MapReduce in different formats. Following are the examples: TextOutputFormat MapFileOutputFormatSequenceFileOutputFormat SequenceFileAsBinaryOutputFormat DBOutputFormat 31 Default output format and it writes records as lines of text Useful to write sequence files when the output files need to be fed into another mapreduce jobs as input files Used to write output as map files Used for writing to relational databases and HBase. This format also sends the reduce output to a SQL table Another variant of SequenceFileInputFormat. It also writes keys and values to sequence file in binary format
- 45. YARN
- 46. What benefits did YARN bring in Hadoop 2.0 and how did it solve the issues of MapReduce V1? Managing jobs using a single job tracker and utilization of computational resources was inefficient in MapReduce 1 In Hadoop 1.0, MapReduce performed both data processing and resource management Data processing Resource management MapReduce consisted of Job Tracker and Task Tracker 32
- 47. What benefits did YARN bring in Hadoop 2.0 and how did it solve the issues of MapReduce V1? Managing jobs using a single job tracker and utilization of computational resources was inefficient in MR 1 In Hadoop 1.0, MapReduce performed both data processing and resource management Data processing Resource management MapReduce consisted of Job Tracker and Task Tracker 32 Scalability Availability issue Resource utilization Can’t run non- MapReduce jobs Following were some major issues:
- 48. What benefits did YARN bring in Hadoop 2.0 and how did it solve the issues of MapReduce V1? Scalability Can have a cluster size of more than 10,000 nodes and can run more than 1,00,000 concurrent tasks Resource utilization Multitenancy Can use open-source and propriety data access engines and perform real- time analysis and running ad-hoc query Compatibility Allows dynamic allocation of cluster resources to improve resource utilization Applications developed for Hadoop 1 runs on YARN without any disruption or availability issues 32
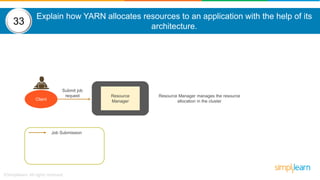
- 49. Explain how YARN allocates resources to an application with the help of its architecture. Resource ManagerClient Job Submission Submit job request Resource Manager manages the resource allocation in the cluster 33
- 50. Explain how YARN allocates resources to an application with the help of its architecture. Resource ManagerClient Job Submission Submit job request Applications Manager Scheduler • Scheduler allocates resources to various running applications • Schedules resources based on the requirements of the applications • Does not monitor or track the status of the applications • Applications Manager accepts job submissions • Monitors and restarts application masters in case of failure 33
- 51. Explain how YARN allocates resources to an application with the help of its architecture. Resource ManagerClient Node Manager container App Master App Master container Node Manager Node Manager container container Job Submission Node Status MapReduce Status Resource Request Submit job request • Node Manager is a tracker that tracks the jobs running • Monitors each container’s resource utilization 33
- 52. Explain how YARN allocates resources to an application with the help of its architecture. Resource ManagerClient Node Manager container App Master App Master container Node Manager Node Manager container container Job Submission Node Status MapReduce Status Resource Request Submit job request • Application Master manages resource needs of individual applications • Interacts with Scheduler to acquire required resources • Interacts with Node Manager to execute and monitor tasks 33
- 53. Explain how YARN allocates resources to an application with the help of its architecture. Resource ManagerClient Node Manager container App Master App Master container Node Manager Node Manager container container Job Submission Node Status MapReduce Status Resource Request Submit job request • Container is a collection of resources like RAM, CPU, Network Bandwidth • Provides rights to an application to use specific amount of resources 33
- 54. (a) NodeManager (b) ApplicationMaster (c) ResourceManager (d) Scheduler 34 Which of the following has occupied the place of JobTracker of MapReduce V1?
- 55. Which of the following has occupied the place of JobTracker of MapReduce V1? (a) NodeManager (b) ApplicationMaster (c) ResourceManager (d) Scheduler 34
- 56. Write the YARN commands to check the status of an application and kill an application. To check the status of an application: yarn application -status ApplicationID To kill or terminate an application: yarn application –kill ApplicationID 35
- 57. Can we have more than 1 ResourceManager in a YARN based cluster? Yes, there can be more than 1 ResourceManager in case of a High Availability cluster Active ResourceManager Standby ResourceManager 36
- 58. Can we have more than 1 ResourceManager in a YARN based cluster? Yes, there can be more than 1 ResourceManager in case of a High Availability cluster Active ResourceManager Standby ResourceManager 36 At a particular time, there can only be one active ResourceManager. In case the active ResourceManager fails, then the standby ResourceManager comes to rescue
- 59. What are the different schedulers available in YARN?. The different schedulers available in YARN are: 1. FIFO scheduler: The FIFO Scheduler places applications in a queue and runs them in the order of submission (first in, first out) 2. Capacity scheduler: A separate dedicated queue allows the small job to start as soon as it is submitted. The large job finishes later than when using the FIFO Scheduler 3. Fair scheduler: There is no need to reserve a set amount of capacity, since it will dynamically balance resources between all the running jobs 37
- 60. What happens if a ResourceManager fails while executing an application in a high availability cluster? If a ResourceManager fails in case of a high availability cluster, the newly active ResourceManager instructs the ApplicationsMaster to abort Resource Manager recovers its running state by taking advantage of the container statuses sent from all Node Managers 2 3 38 In a high availability cluster, if one ResourceManager fails, another ResourceManager becomes active1
- 61. In a cluster of 10 datanodes, each having 16 GB RAM and 10 cores, what would be the total processing capacity of the cluster? 39 • Every node in a Hadoop cluster would have multiple processes running and these would need RAM • The machine will also have its own processes, would also need some ram usage • So, if have 10 datanodes, you need to deduct at least 20- 30% towards the overheads, cloudera based services, etc. • you could have 11-12 GB available on every machine for processing and 6-7 cores. Multiply that by 10. That’s the processing capacity • Every node in a Hadoop cluster have multiple processes running and these processes need RAM • The machine which has its own processes, would also need some ram usage • So, if you have 10 datanodes, you need to allocate at least 20-30% towards the overheads, cloudera based services, etc. • You could have 11-12 GB and 6-7 cores available on every machine for processing. Multiply that by 10 and that’s the processing capacity
- 62. What happens if requested memory or CPU cores goes beyond the size of container allocation? 40 If an application needs more memory and CPU cores, it cannot fit into a container allocation. So the application fails
Editor's Notes
- #2: Style - 01