Hadoop과 SQL-on-Hadoop (A short intro to Hadoop and SQL-on-Hadoop)
150 likes18,426 views

얼마전 비전공자들에게 하둡 개요를 주제로 발표했던 슬라이드입니다. 하둡의 개발 배경과 기본 컨셉, 최근 유행하고 있는 SQL-on-Hadoop에 대해서 설명합니다.



















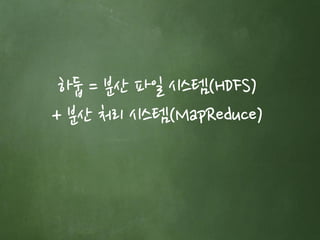




























![/authenticate 1
/category/list 1
/category/list 1
/authenticate 1
입력 파일 (아파치 웹 서버 access 로그 파일)
맵
192.168.56.10 - - [11/Nov/2014:22:12:32 +0900] "GET /authenticate HTTP/1.1”
192.168.56.11 - - [11/Nov/2014:22:12:35 +0900] "GET /category/list HTTP/1.1”
192.168.56.12 - - [11/Nov/2014:22:12:38 +0900] "GET /category/list HTTP/1.1”
192.168.56.13 - - [11/Nov/2014:22:13:32 +0900] "GET /authenticate HTTP/1.1”
192.168.56.20 - - [11/Nov/2014:22:14:32 +0900] "GET /mypage HTTP/1.1”
192.168.56.21 - - [11/Nov/2014:22:14:35 +0900] "GET /mypage HTTP/1.1”
192.168.56.22 - - [11/Nov/2014:22:14:36 +0900] "GET /authenticate HTTP/1.1”
192.168.56.23 - - [11/Nov/2014:22:14:40 +0900] "GET /authenticate HTTP/1.1”
/mypage 1
/mypage 1
/authenticate 1
/authenticate 1
192.168.56.10 - - [11/Nov/2014:22:12:32 +0900] "GET /authenticate HTTP/1.1”
192.168.56.11 - - [11/Nov/2014:22:12:35 +0900] "GET /category/list HTTP/1.1”
192.168.56.12 - - [11/Nov/2014:22:12:38 +0900] "GET /category/list HTTP/1.1”
192.168.56.13 - - [11/Nov/2014:22:13:32 +0900] "GET /authenticate HTTP/1.1”
192.168.56.20 - - [11/Nov/2014:22:14:32 +0900] "GET /mypage HTTP/1.1”
192.168.56.21 - - [11/Nov/2014:22:14:35 +0900] "GET /mypage HTTP/1.1”
192.168.56.22 - - [11/Nov/2014:22:14:36 +0900] "GET /authenticate HTTP/1.1”
192.168.56.23 - - [11/Nov/2014:22:14:40 +0900] "GET /authenticate HTTP/1.1
입력 스플릿
1. 스플릿 1. 스플릿
2.레코드
읽기
2.레코드
읽기
Map 단계](https://image.slidesharecdn.com/hadoopintro201512122-150113145543-conversion-gate01/85/Hadoop-SQL-on-Hadoop-A-short-intro-to-Hadoop-and-SQL-on-Hadoop-50-320.jpg)














































Ad
More Related Content
What's hot (20)
Viewers also liked (16)


![[SSA] 03.newsql database (2014.02.05)](https://cdn.slidesharecdn.com/ss_thumbnails/03-140225072436-phpapp01-thumbnail.jpg?width=560&fit=bounds)






![[SSA] 04.sql on hadoop(2014.02.05)](https://cdn.slidesharecdn.com/ss_thumbnails/04-140225072610-phpapp01-thumbnail.jpg?width=560&fit=bounds)


![[SSA] 01.bigdata database technology (2014.02.05)](https://cdn.slidesharecdn.com/ss_thumbnails/01-140225072202-phpapp02-thumbnail.jpg?width=560&fit=bounds)

Ad
Similar to Hadoop과 SQL-on-Hadoop (A short intro to Hadoop and SQL-on-Hadoop) (20)

![[211] HBase 기반 검색 데이터 저장소 (공개용)](https://cdn.slidesharecdn.com/ss_thumbnails/211hbase-171016101436-thumbnail.jpg?width=560&fit=bounds)
![[124]네이버에서 사용되는 여러가지 Data Platform, 그리고 MongoDB](https://cdn.slidesharecdn.com/ss_thumbnails/124mongodb-181011042943-thumbnail.jpg?width=560&fit=bounds)




![[223]rye, 샤딩을 지원하는 오픈소스 관계형 dbms](https://cdn.slidesharecdn.com/ss_thumbnails/223ryedbms-171016104435-thumbnail.jpg?width=560&fit=bounds)






![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [하둡메이트 팀] : 하둡 설정 고도화 및 맵리듀스 모니터링](https://cdn.slidesharecdn.com/ss_thumbnails/random-220728094615-7bbbfc3e-thumbnail.jpg?width=560&fit=bounds)





Ad
Hadoop과 SQL-on-Hadoop (A short intro to Hadoop and SQL-on-Hadoop)
- 1. Hadoop과 SQL-on-Hadoop 그루터 / 정재화
- 2. About me • Bigdata Platform, Gruter Inc • Apache Tajo Committer • [email protected] • http://blrunner.com • 저서: 시작하세요!하둡 프로그래밍
- 3. 목차 1. RDBMS의 문제점 2. 하둡이란? 3. HDFS 4. MapReduce 5. SQL-on-Hadoop
- 4. 1.RDBMS의 문제점
- 5. RDBMS (Relational Database Management system) : 관계형 데이터베이스 관리 시스템
- 7. MS(management system) : DB에 레코드를 삽입(Insert), 수정(Update), 삭제 (Delete)할 수 있도록 해주는 소프트웨어 SQL (Structured Query Language) 지원 DROP TABLE table1; CREATE TABLE table1 ( id int, name varchar2(255), score float); INSERT INTO table1(id, name, score) VALUES(1, ‘TAJO’, 10.0);
- 8. R(Relational) DBMS의 종류를 의미 여러 개의 테이블을 조합해서 원하는 데이터를 조회 트랜잭션(transaction) 지원
- 9. RDBMS란 관계형 데이터베이스를 생성, 수정, 관리할 수 있는 소프트웨어입니다.
- 11. RDBMS는 데이터를 가져와서, 로직을 수행합니다.
- 12. Compute Server Storage Server Network 1. Copy input data
- 13. Compute Server Storage Server Network 2. Compute data
- 14. Compute Server Storage Server Network 3. Copy output data
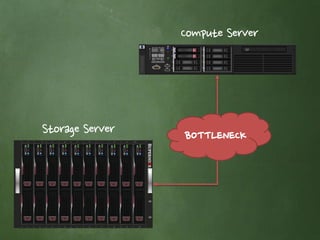
- 15. 문제점은 …
- 16. Compute Server Storage Server BOTTLENECK
- 17. 또 다른 문제점은…
- 19. 2. 하둡이란?
- 20. 하둡이란 대용량 데이터를 분산 처리할 수 있는 자바 기반의 오픈소스 프레임워크입니다.
- 21. 하둡 = 분산 파일 시스템(HDFS) + 분산 처리 시스템(MapReduce)
- 22. 하둡의 주요 특징은 무엇이 있을까요?
- 23. 데이터가 있는 곳에서 로직을 수행합니다. Data Locality
- 24. 하둡은 x86 서버에 설치할 수 있습니다. (vs 유닉스 서버) 하드웨어 장애는 피할 수 없다는 가정하에 설계됐습니다. Fault Tolerant
- 25. 서버(노드)를 추가하면, 용량과 컴퓨팅 성능의 선형적 인 확장이 가능합니다. Scalable
- 26. 다수의 클러스터를 하나의 스토리지처럼 사용합니다. Simple Hdfs://hadoop-cluster/Xyz
- 27. 하둡의 발자취를 따라가 볼까요?
- 28. 2003년 구글 GFS 논문 발표
- 29. 2004년 구글 MapReduce 논문 발표
- 30. 2005년 더그 커팅이 Nutch 크롤 / 검색 패키지에 구글 논문을 기반으로, HDFS/MapReduce를 추가하면서 시작됩니다.
- 31. 2006년 더그 커팅이 야후에 입사한 후, 20 노드 클러스터를 셋업합니다. 2008년 야후에서 1000 노드 클러스터를 프러덕션에서 사용 하기 시작합니다. 2008년 하둡이 아파치 탑레벨 프로젝트로 승격됩니다. 2011년 하둡1.0 GA 버전이 릴리즈됩니다. 2013년 하둡2.0 GA 버전이 릴리즈됩니다.
- 32. 지금까지 들은 이야기로는 꼭…
- 34. 하지만 하둡도 단점이 있습니다.
- 35. 배치 프로세싱에 최적화되어 있습니다. 하둡 버전과 에코 시스템이 너무 다양합니다. 로그 수 집 하나만 해도 Flume, Chuckwa, Scribe… 설치와 사용이 쉽지 않습니다. 엔지니어를 고용하기 쉽지 않습니다.
- 36. 3. HDFS
- 37. 블록1 200MB 파일 64MB 블록2 64MB 블록3 64MB 파일 저장 HDFS 클러스터 DataNode #3 블록3 블록2 블록4 DataNode #2 블록2 블록1 블록3 DataNode #1 블록1 블록3 블록4 DataNode #4 블록4 블록1 블록2 블록4 8MB HDFS 파일 복제 구조
- 38. HDFS 시스템 구성 Client DataNode #3 블록3 블록2 블록4 DataNode #2 블록2 블록1 블록3 DataNode #1 블록1 블록3 블록4 DataNode #4 블록4 블록1 블록2 NameNode 하트비트 전송 파일 제어 요청 파일 읽기/쓰기 요청 파일 읽기/쓰기 응답 DataNode 상태 모니터링 메타데이터 Secondary NameNode 체크포인트
- 39. 4. MapReduce
- 40. 사실 MapReduce는 예전부터 있던, 프로그래밍 모델입니다.
- 41. MapReduce는 Map과 Reduce라는 두 단계로 데이터를 처리합니다.
- 42. Map은 입력 파일을 한 줄씩 읽어서 데이터를 변형(transformation)합니다.
- 44. MapReudce의 HelloWorld인 WordCount 예제를 살펴보겠습니다.
- 45. read a book read 1 a 1 book 1 write1 a 1 book 1 read 1 a 1 book 1 write 1 a 1 book 1 read 1 a 2 book 2 write 1 입력 파일 맵 리듀스 출력 파일 write a book 입력 파일의 글자 개수 계산하기…
- 46. 하둡 MapReduce 프레임워크는 개발자가 MapReduce 프로그램 로직 구현에 집중하 게 해주고, 데이터에 대한 분산과 병렬 처리를 프레임워크가 담당합니다.
- 47. 마스터 서버 JobTracker 슬레이브 서버 TaskTracker Task Task 슬레이브 서버 TaskTracker Task Task 슬레이브 서버 TaskTracker Task Task Task 실행 및 모니터링 클라이언트 잡 실행요청 잡 진행 상황 및 완료 결과 공유 Task 실행 요청 하트비트 전송
- 48. 아직 WordCount만으로는 감이 잘 오지 않기 때문에,
- 49. MapReduce를 이용하여, 웹 서비스 접속 통계를 구해보겠습니다.
- 50. /authenticate 1 /category/list 1 /category/list 1 /authenticate 1 입력 파일 (아파치 웹 서버 access 로그 파일) 맵 192.168.56.10 - - [11/Nov/2014:22:12:32 +0900] "GET /authenticate HTTP/1.1” 192.168.56.11 - - [11/Nov/2014:22:12:35 +0900] "GET /category/list HTTP/1.1” 192.168.56.12 - - [11/Nov/2014:22:12:38 +0900] "GET /category/list HTTP/1.1” 192.168.56.13 - - [11/Nov/2014:22:13:32 +0900] "GET /authenticate HTTP/1.1” 192.168.56.20 - - [11/Nov/2014:22:14:32 +0900] "GET /mypage HTTP/1.1” 192.168.56.21 - - [11/Nov/2014:22:14:35 +0900] "GET /mypage HTTP/1.1” 192.168.56.22 - - [11/Nov/2014:22:14:36 +0900] "GET /authenticate HTTP/1.1” 192.168.56.23 - - [11/Nov/2014:22:14:40 +0900] "GET /authenticate HTTP/1.1” /mypage 1 /mypage 1 /authenticate 1 /authenticate 1 192.168.56.10 - - [11/Nov/2014:22:12:32 +0900] "GET /authenticate HTTP/1.1” 192.168.56.11 - - [11/Nov/2014:22:12:35 +0900] "GET /category/list HTTP/1.1” 192.168.56.12 - - [11/Nov/2014:22:12:38 +0900] "GET /category/list HTTP/1.1” 192.168.56.13 - - [11/Nov/2014:22:13:32 +0900] "GET /authenticate HTTP/1.1” 192.168.56.20 - - [11/Nov/2014:22:14:32 +0900] "GET /mypage HTTP/1.1” 192.168.56.21 - - [11/Nov/2014:22:14:35 +0900] "GET /mypage HTTP/1.1” 192.168.56.22 - - [11/Nov/2014:22:14:36 +0900] "GET /authenticate HTTP/1.1” 192.168.56.23 - - [11/Nov/2014:22:14:40 +0900] "GET /authenticate HTTP/1.1 입력 스플릿 1. 스플릿 1. 스플릿 2.레코드 읽기 2.레코드 읽기 Map 단계
- 51. /authenticate 1 /category/list 1 /category/list 1 /authenticate 1 맵 /mypage 1 /mypage 1 /authenticate 1 /authenticate 1 /authenticate 1 /authenticate 1 /authenticate 1 /authenticate 1 /category/list 1 /category/list 1 /mypage 1 /mypage 1 파티셔너 파티셔너 파티셔너 /authenticate {1,1,1,1} /category/list 1 {1,1} /mypage {1, 1} 리듀스 중간 파일 1. 파티셔닝 2.병합정렬 2.병합정렬 2.병합정렬 1. 파티셔닝 3. 레코드 읽기 3. 레코드 읽기 3. 레코드 읽기 Shuffle 단계
- 52. /authenticate {1,1,1,1} /category/list 1 {1,1} /mypage {1, 1} 리듀스 /authenticate 4 /category/list 1 2 /mypage 2 출력 파일 1. 출력 1. 출력 1. 출력 Reduce 단계
- 53. 5. SQL-on-Hadoop
- 55. 관계형 처리를 위해 고안된 것이 아니기 때문에, 데이터 처리 모델상의 한계가 있습니다. Pig, Hive는 MapReduce가 제공하는 기능 이상의 최적 화 불가능합니다. 초기화 및 스케쥴링 시간이 느립니다. 개발 노력이 많이 들어가고, 성능 보장이 어렵습니다. Ad-hoc 질의에 대한 속도 문제로,DBMS 병행 사용이 불 가피합니다.
- 57. HDFS에 저장된 데이터를 SQL로 처리하는 시스템 탈 MapReduce 모델 다양한 설계 목표 : DataWarehouse VS Query Engine
- 58. Function Tajo Hive Impala Spark Computing 자체 MapReduce or Tez 자체 자체 Resource Management 자체 or YARN YARN 자체 자체 or YARN Scheduler FIFO, Fair FIFO, Fair, Capacity FIFO, Fair FIFO, Fair Storage HDFS, S3, HBase HDFS, HBase, S3 HDFS, HBase 자체 RDD (HDSF 등) File Format CSV, RC, Parquet, Avro 등 CSV, RC, ORC, Parquet, Avro 등 CSV, RC, Parquet, Avro 등 CSV, RC, Parquet, Avro 등 Data Model Relational Relational Relational Relational Query ANSI-SQL HiveQL HiveQL HiveQL
- 59. Function Tajo Hive Impala Spark 구현 언어 Java Java C++ Scala Client Java API, JDBC, CLI CLI, JDBC, ODBC, Thrift Server API CLI, JDBC, ODBC Shark JDBC/ODBC, Scala, Java, Python API Query Latency Long run, Interactive Long run, (Interactive- Tez) Interactive Interactive 컴퓨팅 특징 데이터는 Disk, 중 간 데이터는 Memory/Disk 모 두 사용 데이터는 Disk, 중 간 데이터는 Memory/Disk 모 두 사용 중간 데이터가 In- Memory (최근 On-Disk 지 원) 분석 대상 데이터 가 In-Memory 에 로딩 License Apache Apache Apache Apache Main Sponsor Gruter Hortonworks Cloudera Databricks
- 60. Apache Tajo 란?
- 61. 빅데이터 처리를 위한 데이터웨어하우스 시스템입니다. 2014년 아파치 탑레벨 프로젝트에 선정됐습니다. (http://tajo.apache.org) 표준 SQL과 호환됩니다. 질의 전체를 분산 처리합니다. Batch 질의와 Interactive Ad-hoc 질의를 모두 지원 합니다. (100ms ~ 수시간)
- 62. Q&A
- 63. 참고 문헌
- 64. 시작하세요! 하둡 프로그래밍 개정증보판 (위키북스) 하둡 소개 (http://slidesha.re/1AVpyCN) 하둡 좋은 약이지만, 만병 통치약은 아니다 (http://slidesha.re/1wTNv7d) RDBMS란? (http://bit.ly/1stUhnt)
- 65. 이미지 출처