Hadoop - Just the Basics for Big Data Rookies (SpringOne2GX 2013)
Download as PPTX, PDF•11 likes•4,950 views

The document provides an overview of Hadoop, a distributed framework for storage and processing of large datasets. It covers key components such as HDFS for data storage, MapReduce for processing, and the broader Hadoop ecosystem that includes tools like Hive and Flume. The document also discusses the architecture, functionality, and use cases of Hadoop, emphasizing its scalability and flexibility in handling big data.





































































Hadoop - Just the Basics for Big Data Rookies (SpringOne2GX 2013)
- 1. © 2013 SpringOne 2GX. All rights reserved. Do not distribute without permission. Hadoop Just the Basics for Big Data Rookies Adam Shook [email protected]
- 2. Agenda • Hadoop Overview • HDFS Architecture • Hadoop MapReduce • Hadoop Ecosystem • MapReduce Primer • Buckle up!
- 4. Hadoop Core • Open-source Apache project out of Yahoo! in 2006 • Distributed fault-tolerant data storage and batch processing • Provides linear scalability on commodity hardware • Adopted by many: – Amazon, AOL, eBay, Facebook, Foursquare, Google, IBM, Netflix, Twitter, Yahoo!, and many, many more
- 5. Why? • Bottom line: – Flexible – Scalable – Inexpensive
- 6. Overview • Great at – Reliable storage for multi-petabyte data sets – Batch queries and analytics – Complex hierarchical data structures with changing schemas, unstructured and structured data • Not so great at – Changes to files (can’t do it…) – Low-latency responses – Analyst usability • This is less of a concern now due to higher-level languages
- 7. Data Structure • Bytes! • No more ETL necessary • Store data now, process later • Structure on read – Built-in support for common data types and formats – Extendable – Flexible
- 8. Versioning • Version 0.20.x, 0.21.x, 0.22.x, 1.x.x – Two main MR packages: • org.apache.hadoop.mapred (deprecated) • org.apache.hadoop.mapreduce (new hotness) • Version 2.x.x, alpha’d in May 2012 – NameNode HA – YARN – Next Gen MapReduce
- 10. HDFS Overview • Hierarchical UNIX-like file system for data storage – sort of • Splitting of large files into blocks • Distribution and replication of blocks to nodes • Two key services – Master NameNode – Many DataNodes • Checkpoint Node (Secondary NameNode)
- 11. NameNode • Single master service for HDFS • Single point of failure (HDFS 1.x) • Stores file to block to location mappings in the namespace • All transactions are logged to disk • NameNode startup reads namespace image and logs
- 12. Checkpoint Node (Secondary NN) • Performs checkpoints of the NameNode’s namespace and logs • Not a hot backup! 1. Loads up namespace 2. Reads log transactions to modify namespace 3. Saves namespace as a checkpoint
- 13. DataNode • Stores blocks on local disk • Sends frequent heartbeats to NameNode • Sends block reports to NameNode • Clients connect to DataNode for I/O
- 14. How HDFS Works - Writes DataNode A DataNode B DataNode C DataNode D NameNode 1 Client 2 A1 3 A2 A3 A4 Client contacts NameNode to write data NameNode says write it to these nodes Client sequentially writes blocks to DataNode
- 15. How HDFS Works - Writes DataNode A DataNode B DataNode C DataNode D NameNodeClient A1 A2 A3 A4 A1A1 A2A2 A3A3A4 A4 DataNodes replicate data blocks, orchestrated by the NameNode
- 16. How HDFS Works - Reads DataNode A DataNode B DataNode C DataNode D NameNodeClient A1 A2 A3 A4 A1A1 A2A2 A3A3A4 A4 1 2 3 Client contacts NameNode to read data NameNode says you can find it here Client sequentially reads blocks from DataNode
- 17. DataNode A DataNode B DataNode C DataNode D NameNodeClient A1 A2 A3 A4 A1A1 A2A2 A3A3A4 A4 Client connects to another node serving that block How HDFS Works - Failure
- 18. Block Replication • Default of three replicas • Rack-aware system – One block on same rack – One block on same rack, different host – One block on another rack • Automatic re-copy by NameNode, as needed Rack 1 DN DN DN … Rack 2 DN DN DN …
- 19. HDFS 2.0 Features • NameNode High-Availability (HA) – Two redundant NameNodes in active/passive configuration – Manual or automated failover • NameNode Federation – Multiple independent NameNodes using the same collection of DataNodes
- 20. Hadoop MapReduce
- 21. Hadoop MapReduce 1.x • Moves the code to the data • JobTracker – Master service to monitor jobs • TaskTracker – Multiple services to run tasks – Same physical machine as a DataNode • A job contains many tasks • A task contains one or more task attempts
- 22. JobTracker • Monitors job and task progress • Issues task attempts to TaskTrackers • Re-tries failed task attempts • Four failed attempts = one failed job • Schedules jobs in FIFO order – Fair Scheduler • Single point of failure for MapReduce
- 23. TaskTrackers • Runs on same node as DataNode service • Sends heartbeats and task reports to JobTracker • Configurable number of map and reduce slots • Runs map and reduce task attempts – Separate JVM!
- 24. Exploiting Data Locality • JobTracker will schedule task on a TaskTracker that is local to the block – 3 options! • If TaskTracker is busy, selects TaskTracker on same rack – Many options! • If still busy, chooses an available TaskTracker at random – Rare!
- 25. How MapReduce Works DataNode A A1 A2 A4 A2 A1 A3 A3 A2 A4 A4 A1 A3 JobTracker 1 Client 4 2 B1 B3 B4 B2 B3 B1 B3 B2 B4 B4 B1 B2 3 DataNode B DataNode C DataNode D TaskTracker A TaskTracker B TaskTracker C TaskTracker D Client submits job to JobTracker JobTracker submits tasks to TaskTrackers Job output is written to DataNodes w/replication JobTracker reports metrics
- 26. DataNode A A1 A2 A4 A2 A1 A3 A3 A2 A4 A4 A1 A3 JobTrackerClient B1 B3 B4 B2 B3 B1 B3 B2 B4 B4 B1 B2 DataNode B DataNode C DataNode D TaskTracker A TaskTracker B TaskTracker C TaskTracker D How MapReduce Works - Failure JobTracker assigns task to different node
- 27. YARN • Abstract framework for distributed application development • Split functionality of JobTracker into two components – ResourceManager – ApplicationMaster • TaskTracker becomes NodeManager – Containers instead of map and reduce slots • Configurable amount of memory per NodeManager
- 28. MapReduce 2.x on YARN • MapReduce API has not changed – Rebuild required to upgrade from 1.x to 2.x • Application Master launches and monitors job via YARN • MapReduce History Server to store… history
- 29. Hadoop Ecosystem
- 30. Hadoop Ecosystem • Core Technologies – Hadoop Distributed File System – Hadoop MapReduce • Many other tools… – Which I will be describing… now
- 31. Moving Data • Sqoop – Moving data between RDBMS and HDFS – Say, migrating MySQL tables to HDFS • Flume – Streams event data from sources to sinks – Say, weblogs from multiple servers into HDFS
- 33. Higher Level APIs • Pig – Data-flow language – aptly named PigLatin -- to generate one or more MapReduce jobs against data stored locally or in HDFS • Hive – Data warehousing solution, allowing users to write SQL-like queries to generate a series of MapReduce jobs against data stored in HDFS
- 34. Pig Word Count A = LOAD '$input'; B = FOREACH A GENERATE FLATTEN(TOKENIZE($0)) AS word; C = GROUP B BY word; D = FOREACH C GENERATE group AS word, COUNT(B); STORE D INTO '$output';
- 35. Key/Value Stores • HBase • Accumulo • Implementations of Google’s Big Table for HDFS • Provides random, real-time access to big data • Supports updates and deletes of key/value pairs
- 37. Data Structure • Avro – Data serialization system designed for the Hadoop ecosystem – Expressed as JSON • Parquet – Compressed, efficient columnar storage for Hadoop and other systems
- 38. Scalable Machine Learning • Mahout – Library for scalable machine learning written in Java – Very robust examples! – Classification, Clustering, Pattern Mining, Collaborative Filtering, and much more
- 39. Workflow Management • Oozie – Scheduling system for Hadoop Jobs – Support for: • Java MapReduce • Streaming MapReduce • Pig, Hive, Sqoop, Distcp • Any ol’ Java or shell script program
- 40. Real-time Stream Processing • Storm – Open-source project which runs a streaming of data, called a spout, to a series of execution agents called bolts – Scalable and fault- tolerant, with guaranteed processing of data – Benchmarks of over a million tuples processed per second per node
- 41. Distributed Application Coordination • ZooKeeper – An effort to develop and maintain an open-source server which enables highly reliable distributed coordination – Designed to be simple, replicated, ordered, and fast – Provides configuration management, distributed synchronization, and group services for applications
- 43. Hadoop Streaming • Write MapReduce mappers and reducers using stdin and stdout • Execute on command line using Hadoop Streaming JAR // TODO verify hadoop jar hadoop-streaming.jar -input input -output outputdir -mapper org.apache.hadoop.mapreduce.Mapper -reduce /bin/wc
- 44. SQL on Hadoop • Apache Drill • Cloudera Impala • Hive Stinger • Pivotal HAWQ • MPP execution of SQL queries against HDFS data
- 46. That’s a lot of projects • I am likely missing several (Sorry, guys!) • Each cropped up to solve a limitation of Hadoop Core • Know your ecosystem • Pick the right tool for the right job
- 47. Sample Architecture HDFS Flume Agent Flume Agent Flume Agent MapReduce Pig HBase Storm Website Oozie Webserve r Sales Call Center SQL SQL
- 48. MapReduce Primer
- 49. MapReduce Paradigm • Data processing system with two key phases • Map – Perform a map function on input key/value pairs to generate intermediate key/value pairs • Reduce – Perform a reduce function on intermediate key/value groups to generate output key/value pairs • Groups created by sorting map output
- 50. Reduce Task 0 Reduce Task 1 Map Task 0 Map Task 1 Map Task 2 (0, "hadoop is fun") (52, "I love hadoop") (104, "Pig is more fun") ("hadoop", 1) ("is", 1) ("fun", 1) ("I", 1) ("love", 1) ("hadoop", 1) ("Pig", 1) ("is", 1) ("more", 1) ("fun", 1) ("hadoop", {1,1}) ("is", {1,1}) ("fun", {1,1}) ("love", {1}) ("I", {1}) ("Pig", {1}) ("more", {1}) ("hadoop", 2) ("fun", 2) ("love", 1) ("I", 1) ("is", 2) ("Pig", 1) ("more", 1) SHUFFLE AND SORT Map Input Map Output Reducer Input Groups Reducer Output
- 51. Hadoop MapReduce Components • Map Phase – Input Format – Record Reader – Mapper – Combiner – Partitioner • Reduce Phase – Shuffle – Sort – Reducer – Output Format – Record Writer
- 52. Writable Interfaces public interface Writable { void write(DataOutput out); void readFields(DataInput in); } public interface WritableComparable<T> extends Writable, Comparable<T> { } • BooleanWritable • BytesWritable • ByteWritable • DoubleWritable • FloatWritable • IntWritable • LongWritable • NullWritable • Text
- 53. InputFormat public abstract class InputFormat<K, V> { public abstract List<InputSplit> getSplits(JobContext context); public abstract RecordReader<K, V> createRecordReader(InputSplit split, TaskAttemptContext context); }
- 54. RecordReader public abstract class RecordReader<KEYIN, VALUEIN> implements Closeable { public abstract void initialize(InputSplit split, TaskAttemptContext context); public abstract boolean nextKeyValue(); public abstract KEYIN getCurrentKey(); public abstract VALUEIN getCurrentValue(); public abstract float getProgress(); public abstract void close(); }
- 55. Mapper public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { protected void setup(Context context) { /* NOTHING */ } protected void cleanup(Context context) { /* NOTHING */ } protected void map(KEYIN key, VALUEIN value, Context context) { context.write((KEYOUT) key, (VALUEOUT) value); } public void run(Context context) { setup(context); while (context.nextKeyValue()) map(context.getCurrentKey(), context.getCurrentValue(), context); cleanup(context); } }
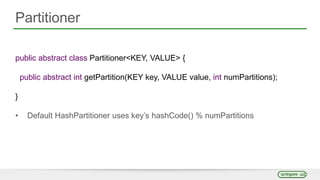
- 56. Partitioner public abstract class Partitioner<KEY, VALUE> { public abstract int getPartition(KEY key, VALUE value, int numPartitions); } • Default HashPartitioner uses key’s hashCode() % numPartitions
- 57. Reducer public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { protected void setup(Context context) { /* NOTHING */ } protected void cleanup(Context context) { /* NOTHING */ } protected void reduce(KEYIN key, Iterable<VALUEIN> value, Context context) { for (VALUEIN value : values) context.write((KEYOUT) key, (VALUEOUT) value); } public void run(Context context) { setup(context); while (context.nextKey()) reduce(context.getCurrentKey(), context.getValues(), context); cleanup(context); } }
- 58. OutputFormat public abstract class OutputFormat<K, V> { public abstract RecordWriter<K, V> getRecordWriter(TaskAttemptContext context); public abstract void checkOutputSpecs(JobContext context); public abstract OutputCommitter getOutputCommitter(TaskAttemptContext context); }
- 59. RecordWriter public abstract class RecordWriter<K, V> { public abstract void write(K key, V value); public abstract void close(TaskAttemptContext context); }
- 61. Problem • Count the number of times each word is used in a body of text • Uses TextInputFormat and TextOutputFormat map(byte_offset, line) foreach word in line emit(word, 1) reduce(word, counts) sum = 0 foreach count in counts sum += count emit(word, sum)
- 62. Mapper Code public class WordMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ private final static IntWritable ONE = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, Context context) { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, ONE); } } }
- 63. Shuffle and Sort P0 P1 1P2 P3 P0 P1 P2 P3 P0 P1 P2 P3 P0 P1 P2 P3 P0 P0 P0 P0 P1 P1 P1 P1 P2 P2 P2 P2 P3 P3 P3 P3 2 3 P0 P1 P2 P3 Reducer 0 Reducer 1 Reducer 2 Reducer 3 Mapper 0 Mapper 1 Mapper 2 Mapper 3 Mapper outputs to a single logically partitioned file Reducers copy their parts Reducer merges partitions, sorting by key
- 64. Reducer Code public class IntSumReducer extends Reducer<Text, LongWritable, Text, IntWritable> { private IntWritable outvalue = new IntWritable(); private int sum = 0; public void reduce(Text key, Iterable<IntWritable> values, Context context) { sum = 0; for (IntWritable val : values) { sum += val.get(); } outvalue.set(sum); context.write(key, outvalue); } }
- 65. So what’s so hard about it? MapReduce that’s a tiny box All the problems you'll ever have ever
- 66. So what’s so hard about it? • MapReduce is a limitation • Entirely different way of thinking • Simple processing operations such as joins are not so easy when expressed in MapReduce • Proper implementation is not so easy • Lots of configuration and implementation details for optimal performance – Number of reduce tasks, data skew, JVM size, garbage collection
- 67. So what does this mean for you? • Hadoop is written primarily in Java • Components are extendable and configurable • Custom I/O through Input and Output Formats – Parse custom data formats – Read and write using external systems • Higher-level tools enable rapid development of big data analysis
- 68. Resources, Wrap-up, etc. • http://hadoop.apache.org • Very supportive community • Strata + Hadoop World Oct. 28th – 30th in Manhattan • Plenty of resources available to learn more – Blogs – Email lists – Books – Shameless Plug -- MapReduce Design Patterns
- 69. Getting Started • Pivotal HD Single-Node VM and Community Edition – http://gopivotal.com/pivotal-products/data/pivotal-hd • For the brave and bold -- Roll-your-own! – http://hadoop.apache.org/docs/current
- 70. Acknowledgements • Apache Hadoop, the Hadoop elephant logo, HDFS, Accumulo, Avro, Drill, Flume, HBase, Hive, Mahout, Oozie, Pig, Sqoop, YARN, and ZooKeeper are trademarks of the Apache Software Foundation • Cloudera Impala is a trademark of Cloudera • Parquet is copyright Twitter, Cloudera, and other contributors • Storm is licensed under the Eclipse Public License
- 71. Learn More. Stay Connected. • Talk to us on Twitter: @springcentral • Find Session replays on YouTube: spring.io/video
Editor's Notes
- #5: Apache project based on two Google papers in 2003 and 2004 on the Google File System and MapReduce Spawned off of Nutch, open-source web-search software, when looking to store the data Linear scalability using commodity hardware – Facebook adopted hadoop, 10TB to 15PB Not for random reads/writes, not for updates – batch processing of large amounts of data Fault tolerant system primarily around distribution and replication of resources There is no true backup of your Hadoop cluster
- #8: Use HDFS to store petabytes of data using thousands of nodes Largest Hadoop cluster (March 2011) could hold 30 PB of data
- #11: Looks a lot like UNIX file system – contains files, folders, permissions, users, and groups Isn’t actually stored that way – Large data files are split into blocks and placed on DataNode services NameNode is the name server for the file name to block mapping – it knows how the file is split and where the data is in the cluster All read and write requests go through the namenode, but data is served from the DataNodes via HTTP Namespace is stored in memory, transactions are logged on the local file system Secondary NameNode or checkpoint node creates snapshots of the NameNode namespace for fault tolerance and faster restarts
- #12: Now, namenode does not persist the data block locations themselves (but does store them in memory). DataNodes tell NameNode what they have
- #14: Block reports contain all the block IDs it is holding onto, md5 checksums, etc.
- #15: Client contacts the namenode with a request to write some data Namenode responds and says okay write it to these data nodes Client connects to each data node and writes out four blocks, one per node
- #16: After the file is closed, the data nodes traffic data around to replicate the blocks to a triplicate, all orchestrated by the namenode In the event of a node failure, data can be accessed on other nodes and the namenode will move data blocks to other nodes
- #17: Client contacts the namenode with a request to write some data Namenode responds and says okay write it to these data nodes Client connects to each data node and writes out four blocks, one per node
- #18: Client contacts the namenode with a request to write some data Namenode responds and says okay write it to these data nodes Client connects to each data node and writes out four blocks, one per node
- #22: Job tracker takes submitted jobs from clients and determines the locations of the blocks that make up the input One data block equals one task Task attempts are distributed to TaskTrackers running in parallel with each DataNode, thus giving data locality for reading the data Successful task attempts are good! Failed task attempts are given to another TaskTracker for processing 4 single failed task attempts equals one failed job
- #26: Client submits a job to the JobTracker for processing JobTracker uses the input of the job to determine where the blocks are located (through the NameNode), and then distributed task attempts to the task trackers TaskTrackers coordinate the task attempts and data output is written back to the datanodes, which is distributed and replicated as normal HDFS operations Job statistics – not output – is reported back to the client upon job completion
- #27: Client submits a job to the JobTracker for processing JobTracker uses the input of the job to determine where the blocks are located (through the NameNode), and then distributed task attempts to the task trackers TaskTrackers coordinate the task attempts and data output is written back to the datanodes, which is distributed and replicated as normal HDFS operations Job statistics – not output – is reported back to the client upon job completion
- #29: RM manages global assignment of compute resources to applications AM manages application life cycle – tasked to negotiate resources form the RM and works with NM to execute and monitor tasks NodeManager executes containers which In YARN, a MapReduce application is equivalent to a job, executed by the MapReduce AM
- #37: HBase Master Can run multiple HBase Master’s for high availability with automatic failover HBase RegionServer Hosts a table’s Regions, much how a DataNode hosts a file’s blocks
- #47: How do I get data into this file system? How do we take all the boiler-plate code away? How do we update data in HDFS? Common data format for the ecosystem that plays well with Hadoop Stream processing, etc Common Data Format
- #50: Uses key value pairs as input and output to both phases Highly parallelizable paradigm – very easy choice for data processing on a Hadoop cluster
- #51: Uses key value pairs as input and output to both phases Highly parallelizable paradigm – very easy choice for data processing on a Hadoop cluster
- #52: Talk about each piece
- #53: Talk about each piece, mention keys must be writable comparable instances
- #54: Defines the splits for the mapreduce job as well as the record reader
- #55: Given an input split, used to create key value pairs out of the logical split. Responsible for respecting record boundaries
- #56: Mapper is where the good stuff happens This is the Identity Mapper and the class that is overwritten.
- #57: Talk about HashPartitioner
- #58: Context is a subclass of Reducer
- #64: Mapper outputs data to a single file that is logically partitioned by key Reducers copy their partition over to the local machine – “shuffle” Each reducer then sorts their partitions into a single sorted local file for processing
- #67: HDFS is great and storing data, and MapReduce is great at scaling out processing However, MapReduce is a limitation as everything needs to be expressed in key/value pairs, and needs to fit in this box of map, shuffle, sort, reduce Many different ways to execute a join using MapReduce, need to choose which you want to do based on type of join, data size, etc Number of reducers is configurable Fewer reducers get more data to process Key skew will cause some reducers to get too much work
- #68: Java is nice, since a lot of other things are written in Java and it is pretty easy to get something going soon Because of this, anything you can do in Java, you can apply to MapReduce Just need to ensure you don’t break the paradigm and leave everything parallel
- #69: Easy to install on VM and begin exploring