Hadoop Map Reduce 程式設計
179 likes40,392 views

Hadoop Map Reduce 概念,架構原理,開發方法,程式設計,專案分享... 2010-01/28製作
![Map Reduce 王耀聰 陳威宇 [email_address] [email_address] 教育訓練課程](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-1-320.jpg)
















![Map Reduce 原理說明 王耀聰 陳威宇 [email_address] [email_address]](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-18-320.jpg)
![Algorithms Functional Programming : Map Reduce map(...) : [ 1,2,3,4 ] – (*2) -> [ 2,4,6,8 ] reduce(...): [ 1,2,3,4 ] - (sum) -> 10 對應演算法中的 Divide and conquer 將問題分解成很多個小問題之後,再做總和](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-19-320.jpg)



![Reduce Example: Sum Reducer let reduce(k, vals) = sum = 0 foreach int v in vals: sum += v emit(k, sum) (“A”, [42, 100, 312]) (“A”, 454) (“B”, [12, 6, -2]) (“B”, 16)](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-23-320.jpg)



![Console 端 編譯與執行 王耀聰 陳威宇 [email_address] [email_address]](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-28-320.jpg)






![透過 Eclipse 開發 王耀聰 陳威宇 [email_address] [email_address]](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-35-320.jpg)























![Map Reduce 程式架構 王耀聰 陳威宇 [email_address] [email_address]](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-59-320.jpg)

![Class MR { static public Class Mapper … { } static public Class Reducer … { } main(){ Configuration conf = new Configuration(); Job job = new Job( conf , “job name"); job . setJarByClass ( thisMainClass.class ); job .setMapperClass(Mapper.class); job .setReduceClass(Reducer.class); FileInputFormat.addInputPaths (job, new Path(args[0])); FileOutputFormat.setOutputPath (job, new Path(args[1])); job . waitForCompletion (true); }} Program Prototype (v 0.20) Map 程式碼 Reduce 程式碼 其他的設定參數程式碼 Map 區 Reduce 區 設定區](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-61-320.jpg)






![範例一 (3) - main public static void main (String[] args) throws IOException, InterruptedException, ClassNotFoundException { Configuration conf = new Configuration(); Job job = new Job( conf , "Hadoop Hello World"); job . setJarByClass (HelloHadoop.class); FileInputFormat. setInputPaths (job, " input "); FileOutputFormat. setOutputPath (job, new Path(" output-hh1 ")); job . setMapperClass (HelloMapper.class); job . setReducerClass (HelloReducer.class); job. waitForCompletion (true); } // main end } // wordcount class end // 完](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-68-320.jpg)






![範例二 (2) public class HelloHadoopV2 { public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { Configuration conf = new Configuration(); Job job = new Job(conf, "Hadoop Hello World 2"); job.setJarByClass(HelloHadoopV2.class); // 設定 map and reduce 以及 Combiner class job.setMapperClass(HelloMapperV2.class); job.setCombinerClass(HelloReducerV2.class); job.setReducerClass(HelloReducerV2.class); // 設定 map 的輸出型態 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); // 設定 reduce 的輸出型態 job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.addInputPath (job, new Path("input")); FileOutputFormat.setOutputPath (job, new Path("output-hh2")); // 呼叫 checkAndDelete 函式, // 檢查是否存在該資料夾,若有則刪除之 CheckAndDelete.checkAndDelete("output-hh2", conf); boolean status = job.waitForCompletion(true); if (status) { System.err.println("Integrate Alert Job Finished !"); } else { System.err.println("Integrate Alert Job Failed !"); System.exit(1); } } }](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-75-320.jpg)


![範例三 (2) public class HelloHadoopV3 { public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { String hdfs_input = "HH3_input"; String hdfs_output = "HH3_output"; Configuration conf = new Configuration(); // 宣告取得參數 String[] otherArgs = new GenericOptionsParser(conf, args) .getRemainingArgs(); // 如果參數數量不為 2 則印出提示訊息 if (otherArgs.length != 2) { System.err .println("Usage: hadoop jar HelloHadoopV3.jar <local_input> <local_output>"); System.exit(2); } Job job = new Job(conf, "Hadoop Hello World"); job.setJarByClass(HelloHadoopV3.class); // 再利用上個範例的 map 與 reduce job.setMapperClass(HelloMapperV2.class); job.setCombinerClass(HelloReducerV2.class); job.setReducerClass(HelloReducerV2.class); // 設定 map reduce 的 key value 輸出型態 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class);](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-78-320.jpg)
![範例三 (2) // 用 checkAndDelete 函式防止 overhead 的錯誤 CheckAndDelete.checkAndDelete(hdfs_input, conf); CheckAndDelete.checkAndDelete(hdfs_output, conf); // 放檔案到 hdfs PutToHdfs.putToHdfs(args[0], hdfs_input, conf); // 設定 hdfs 的輸入輸出來源路定 FileInputFormat.addInputPath(job, new Path(hdfs_input)); FileOutputFormat.setOutputPath(job, new Path(hdfs_output)); long start = System.nanoTime(); job.waitForCompletion(true); // 把 hdfs 的結果取下 GetFromHdfs.getFromHdfs(hdfs_output, args[1], conf); boolean status = job.waitForCompletion(true); // 計算時間 if (status) { System.err.println("Integrate Alert Job Finished !"); long time = System.nanoTime() - start; System.err.println(time * (1E-9) + " secs."); } else { System.err.println("Integrate Alert Job Failed !"); System.exit(1); } } }](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-79-320.jpg)
![範例四 (1) public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: hadoop jar WordCount.jar <input> <output>"); System.exit(2); } Job job = new Job(conf, "Word Count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); CheckAndDelete.checkAndDelete(args[1], conf); System.exit(job.waitForCompletion(true) ? 0 : 1); }](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-80-320.jpg)

![範例四 (3) class IntSumReducer extends Reducer< Text , IntWritable , Text, IntWritable > { IntWritable result = new IntWritable(); public void reduce( Text key , Iterable < IntWritable > values , Context context ) throws IOException , InterruptedException { int sum = 0; for ( IntWritable val : values ) sum += val .get(); result.set(sum); context .write ( key, result ); }} 1 2 3 4 5 6 7 8 < news , 2 > <key,SunValue> <word,one> news 1 1 < a, 1 > < good, 1 > < is, 1 > < news, 1 1 > < no, 1 > for ( int i ; i < values.length ; i ++ ){ sum += values[i].get() }](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-82-320.jpg)

![範例五 (2) public class WordCountV2 extends Configured implements Tool { public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { static enum Counters { INPUT_WORDS } private final static IntWritable one = new IntWritable(1); private Text word = new Text(); private boolean caseSensitive = true; private Set<String> patternsToSkip = new HashSet<String>(); private long numRecords = 0; private String inputFile; public void configure(JobConf job) { caseSensitive = job.getBoolean("wordcount.case.sensitive", true); inputFile = job.get("map.input.file"); if (job.getBoolean("wordcount.skip.patterns", false)) { Path[] patternsFiles = new Path[0]; try { patternsFiles = DistributedCache.getLocalCacheFiles(job); } catch (IOException ioe) { System.err .println("Caught exception while getting cached files: " + StringUtils.stringifyException(ioe)); } for (Path patternsFile : patternsFiles) { parseSkipFile(patternsFile); }}} private void parseSkipFile(Path patternsFile) { try { BufferedReader fis = new BufferedReader(new FileReader( patternsFile.toString())); String pattern = null; while ((pattern = fis.readLine()) != null) { patternsToSkip.add(pattern); } } catch (IOException ioe) { System.err.println("Caught exception while parsing the cached file '"+ patternsFile + "' : " + tringUtils.stringifyException(ioe)); }} public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = (caseSensitive) ? value.toString() : value.toString() .toLowerCase(); for (String pattern : patternsToSkip) line = line.replaceAll(pattern, ""); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); output.collect(word, one); reporter.incrCounter(Counters.INPUT_WORDS, 1); }](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-84-320.jpg)
![範例五 (3) if ((++numRecords % 100) == 0) { reporter.setStatus("Finished processing " + numRecords + " records " + "from the input file: " + inputFile); } } } public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } } public int run(String[] args) throws Exception { JobConf conf = new JobConf(getConf(), WordCount.class); conf.setJobName("wordcount"); String[] otherArgs = new GenericOptionsParser(conf, args) .getRemainingArgs(); if (otherArgs.length < 2) { System.out.println("WordCountV2 [-Dwordcount.case.sensitive=<false|true>] \\ "); System.out.println(" <inDir> <outDir> [-skip Pattern_file]"); return 0; } conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(Map.class); conf.setCombinerClass(Reduce.class); conf.setReducerClass(Reduce.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); List<String> other_args = new ArrayList<String>(); for (int i = 0; i < args.length; ++i) { if ("-skip".equals(args[i])) { DistributedCache .addCacheFile(new Path(args[++i]).toUri(), conf); conf.setBoolean("wordcount.skip.patterns", true); } else {other_args.add(args[i]); } } FileInputFormat.setInputPaths(conf, new Path(other_args.get(0))); FileOutputFormat.setOutputPath(conf, new Path(other_args.get(1))); CheckAndDelete.checkAndDelete(other_args.get(1), conf); JobClient.runJob(conf); return 0; } public static void main(String[] args) throws Exception { int res = ToolRunner.run(new Configuration(), new WordCountV2(), args); System.exit(res); }}](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-85-320.jpg)


![範例六 (2) public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args) .getRemainingArgs(); if (otherArgs.length < 2) { System.out.println("hadoop jar WordIndex.jar <inDir> <outDir>"); return; } Job job = new Job(conf, "word index"); job.setJobName("word inverted index"); job.setJarByClass(WordIndex.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); job.setMapperClass(wordindexM.class); job.setReducerClass(wordindexR.class); job.setCombinerClass(wordindexR.class); FileInputFormat.setInputPaths(job, args[0]); CheckAndDelete.checkAndDelete(args[1], conf); FileOutputFormat.setOutputPath(job, new Path(args[1])); long start = System.nanoTime(); job.waitForCompletion(true); long time = System.nanoTime() - start; System.err.println(time * (1E-9) + " secs."); }}](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-88-320.jpg)

![範例七 (2) public class TsmMenu { public static void main(String argv[]) { int exitCode = -1; ProgramDriver pgd = new ProgramDriver(); if (argv.length < 1) { System.out.print("******************************************\n" + " 歡迎使用 TSM 的運算功能 \n" + " 指令: \n" + " Hadoop jar TSM-example-*.jar < 功能 > \n" + " 功能: \n" + " HelloHadoop: 秀出 Hadoop 的 <Key,Value> 為何 \n" + " HelloHadoopV2: 秀出 Hadoop 的 <Key,Value> 進階版 \n" + " HelloHadoopV3: 秀出 Hadoop 的 <Key,Value> 進化版 \n" + " WordCount: 計算輸入資料夾內分別在每個檔案的字數統計 \n" + " WordCountV2: WordCount 進階版 \n" + " WordIndex: 索引每個字與其所有出現的所在列 \n" + "******************************************\n"); } else { try { pgd.addClass("HelloHadoop", HelloHadoop.class, " Hadoop hello world"); pgd.addClass("HelloHadoopV2", HelloHadoopV2.class, " Hadoop hello world V2"); pgd.addClass("HelloHadoopV3", HelloHadoopV3.class, " Hadoop hello world V3"); pgd.addClass("WordCount", WordCount.class, " word count."); pgd.addClass("WordCountV2", WordCountV2.class, " word count V2."); pgd.addClass("WordIndex", WordIndex.class, "invert each word in line"); pgd.driver(argv); // Success exitCode = 0; System.exit(exitCode); } catch (Throwable e) { e.printStackTrace(); }}}}](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-90-320.jpg)

![Class MR { Class Mapper … { } Class Reducer … { } main(){ JobConf conf = new JobConf( “ MR.class ” ); conf.setMapperClass(Mapper.class); conf.setReduceClass(Reducer.class); FileInputFormat.setInputPaths (conf, new Path(args[0])); FileOutputFormat.setOutputPath (conf, new Path(args[1])); JobClient.runJob(conf); }} Program Prototype (v 0.18) Map 程式碼 Reduce 程式碼 其他的設定參數程式碼 Map 區 Reduce 區 設定區 補充](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-92-320.jpg)



![Map Reduce 專案分享 王耀聰 陳威宇 [email_address] [email_address]](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-96-320.jpg)



![[**] [1:538:15] NETBIOS SMB IPC$ unicode share access [**] [Classification: Generic Protocol Command Decode] [Priority: 3] 09/04-17:53:56.363811 168.150.177.165:1051 -> 168.150.177.166:139 TCP TTL:128 TOS:0x0 ID:4000 IpLen:20 DgmLen:138 DF ***AP*** Seq: 0x2E589B8 Ack: 0x642D47F9 Win: 0x4241 TcpLen: 20 [**] [1:1917:6] SCAN UPnP service discover attempt [**] [Classification: Detection of a Network Scan] [Priority: 3] 09/04-17:53:56.385573 168.150.177.164:1032 -> 239.255.255.250:1900 UDP TTL:1 TOS:0x0 ID:80 IpLen:20 DgmLen:161 Len: 133 [**] [1:1917:6] SCAN UPnP service discover attempt [**] [Classification: Detection of a Network Scan] [Priority: 3] 09/04-17:53:56.386910 168.150.177.164:1032 -> 239.255.255.250:1900 UDP TTL:1 TOS:0x0 ID:82 IpLen:20 DgmLen:161 Len: 133 [**] [1:1917:6] SCAN UPnP service discover attempt [**] [Classification: Detection of a Network Scan] [Priority: 3] 09/04-17:53:56.388244 168.150.177.164:1032 -> 239.255.255.250:1900 UDP TTL:1 TOS:0x0 ID:84 IpLen:20 DgmLen:161 Len: 133 [**] [1:1917:6] SCAN UPnP service discover attempt [**] [Classification: Detection of a Network Scan] [Priority: 3] 09/04-17:53:56.417045 168.150.177.164:45461 -> 168.150.177.1:1900 UDP TTL:1 TOS:0x0 ID:105 IpLen:20 DgmLen:161 Len: 133 [**] [1:1917:6] SCAN UPnP service discover attempt [**] [Classification: Detection of a Network Scan] [Priority: 3] 09/04-17:53:56.420759 168.150.177.164:45461 -> 168.150.177.1:1900 UDP TTL:1 TOS:0x0 ID:117 IpLen:20 DgmLen:160 Len: 132 [**] [1:1917:6] SCAN UPnP service discover attempt [**] [Classification: Detection of a Network Scan] [Priority: 3] 09/04-17:53:56.422095 168.150.177.164:45461 -> 168.150.177.1:1900 UDP TTL:1 TOS:0x0 ID:118 IpLen:20 DgmLen:161 Len: 133 [**] [1:2351:10] NETBIOS DCERPC ISystemActivator path overflow attempt little endian unicode [**] [Classification: Attempted Administrator Privilege Gain] [Priority: 1] 09/04-17:53:56.442445 198.8.16.1:10179 -> 168.150.177.164:135 TCP TTL:105 TOS:0x0 ID:49809 IpLen:20 DgmLen:1420 DF ***A**** Seq: 0xF9589BBF Ack: 0x82CCF5B7 Win: 0xFFFF TcpLen: 20 [Xref => http://www.microsoft.com/technet/security/bulletin/MS03-026.mspx][Xref => http://cgi.nessus.org/plugins/dump.php3?id=11808][Xref => http://cve.mitre.org/cgi-bin/cvename.cgi?name=2003-0352][Xref => http://www.securityfocus.com/bid/8205] 輸入資料](https://image.slidesharecdn.com/hadoopmapreduce-100128205456-phpapp01/85/Hadoop-Map-Reduce-100-320.jpg)













![[系列活動] 給工程師的統計學及資料分析 123](https://cdn.slidesharecdn.com/ss_thumbnails/0114lckungtdsaprerequisite-170110090917-thumbnail.jpg?width=560&fit=bounds)




![[D35] インメモリーデータベース徹底比較 by Komori](https://cdn.slidesharecdn.com/ss_thumbnails/d35hp-140623212142-phpapp01-thumbnail.jpg?width=560&fit=bounds)

















Ad
More Related Content
What's hot (20)
Similar to Hadoop Map Reduce 程式設計 (20)


















Ad
More from Wei-Yu Chen (9)









Ad
Hadoop Map Reduce 程式設計
- 1. Map Reduce 王耀聰 陳威宇 [email_address] [email_address] 教育訓練課程
- 2. Computing with big datasets is a fundamentally different challenge than doing “big compute” over a small dataset
- 3. 平行分散式運算 Grid computing MPI, PVM, Condor… 著重於 : 分散工作量 目前的問題在於:如何分散資料量 Reading 100 GB off a single filer would leave nodes starved – just store data locally
- 4. 分散大量資料: Slow and Tricky 交換資料需同步處理 Deadlock becomes a problem 有限的頻寬 Failovers can cause cascading failure
- 5. 數字會說話 Data processed by Google every month: 400 PB … in 2007 Max data in memory: 32 GB Max data per computer: 12 TB Average job size: 180 GB 光一個 device 的讀取時間 = 45 minutes
- 6. 所以 … 運算資料可以很快速,但瓶頸在於硬碟的 I/O 1 HDD = 75 MB/sec 解法 : parallel reads 1000 HDDs = 75 GB/sec
- 7. MapReduce 的動機 Data > 1 TB 交互運算於大量的 CPU 容易開發與使用 High-level applications written in MapReduce Programmers don’t worry about socket(), etc.
- 8. How MapReduce is Structured 以 Functional programming 架構分散式運算 批次處理系統 可靠性
- 9. By Using Map / Reduce MapReduce is a software framework to support distributed computing on large data sets on clusters of computers.
- 10. Hadoop MapReduse Hadoop MapReduce 是一套儲存並處理 petabytes 等級資訊的雲端運算技術
- 11. Hadoop 提供 Automatic parallelization & distribution Fault-tolerance Status and monitoring tools A clean abstraction and API for programmers
- 12. Hadoop Applications (1) Adknowledge - Ad network behavioral targeting, clickstream analytics Alibaba processing sorts of business data dumped out of database and joining them together. These data will then be fed into iSearch, our vertical search engine. Baidu - the leading Chinese language search engine Hadoop used to analyze the log of search and do some mining work on web page database
- 13. Hadoop Applications (3) Facebook 處理 internal log and dimension data sources as a source for reporting/analytics and machine learning. Freestylers - Image retrieval engine use Hadoop 影像處理 Hosting Habitat 取得所有 clients 的軟體資訊 分析並告知 clients 未安裝或未更新的軟體
- 14. Hadoop Applications (4) IBM Blue Cloud Computing Clusters Journey Dynamics 用 Hadoop MapReduce 分析 billions of lines of GPS data 並產生交通路線資訊 . Krugle 用 Hadoop and Nutch 建構 原始碼搜尋引擎
- 15. Hadoop Applications (5) SEDNS - Security Enhanced DNS Group 收集全世界的 DNS 以探索網路分散式內容 . Technical analysis and Stock Research 分析股票資訊 University of Maryland 用 Hadoop 執行 machine translation, language modeling, bioinformatics, email analysis, and image processing 相關研究 University of Nebraska Lincoln, Research Computing Facility 用 Hadoop 跑約 200TB 的 CMS 經驗分析 緊湊渺子線圈 ( CMS , C ompact M uon S olenoid )為 瑞士 歐洲核子研究組織 CERN 的 大型強子對撞器 計劃的兩大通用型 粒子偵測器 中的一個。
- 16. Hadoop Applications (6) Yahoo! Used to support research for Ad Systems and Web Search 使用 Hadoop 平台來發現發送垃圾郵件的殭屍網絡 趨勢科技 過濾像是釣魚網站或惡意連結的網頁內容
- 17. MapReduce Conclusions 適用於 large-scale applications 以及 large-scale computations 程式設計者只需要解決”真實的”問題,架構面留給 MapReduce MapReduce 可應用於多種領域 : Text tokenization, Indexing and Search, Data mining, machine learning…
- 18. Map Reduce 原理說明 王耀聰 陳威宇 [email_address] [email_address]
- 19. Algorithms Functional Programming : Map Reduce map(...) : [ 1,2,3,4 ] – (*2) -> [ 2,4,6,8 ] reduce(...): [ 1,2,3,4 ] - (sum) -> 10 對應演算法中的 Divide and conquer 將問題分解成很多個小問題之後,再做總和
- 20. Divide and Conquer 範例四: 眼前有五階樓梯,每次可踏上一階或踏上兩階,那麼爬完五階共有幾種踏法? Ex : (1,1,1,1,1) or (1,2,1,1) 範例一:十分逼近法 範例二:方格法求面積 範例三:鋪滿 L 形磁磚
- 21. Programming Model Users implement interface of two functions: map (in_key, in_value) (out_key, intermediate_value) list reduce (out_key, intermediate_value list) out_value list
- 22. Map One-to-one Mapper Explode Mapper Filter Mapper (“Foo”, “other”) (“FOO”, “OTHER”) (“key2”, “data”) (“KEY2”, “DATA”) (“A”, “cats”) (“A”, “c”), (“A”, “a”), (“A”, “t”), (“A”, “s”) (“foo”, 7) (“foo”, 7) (“test”, 10) (nothing) let map(k, v) = Emit(k.toUpper(), v.toUpper()) let map(k, v) = foreach char c in v: emit(k, c) let map(k, v) = if (isPrime(v)) then emit(k, v)
- 23. Reduce Example: Sum Reducer let reduce(k, vals) = sum = 0 foreach int v in vals: sum += v emit(k, sum) (“A”, [42, 100, 312]) (“A”, 454) (“B”, [12, 6, -2]) (“B”, 16)
- 24. MapReduce 運作流程 part0 map map map reduce reduce part1 input HDFS sort/copy merge output HDFS JobTracker 跟 NameNode 取得需要運算的 blocks JobTracker 選數個 TaskTracker 來作 Map 運算,產生些中間檔案 JobTracker 將中間檔案整合排序後,複製到需要的 TaskTracker 去 JobTracker 派遣 TaskTracker 作 reduce reduce 完後通知 JobTracker 與 Namenode 以產生 output split 0 split 1 split 2 split 3 split 4
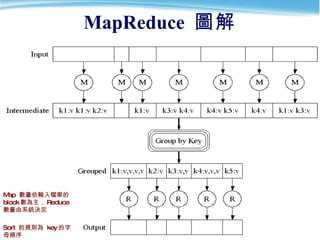
- 25. MapReduce 圖解 Map 數量依輸入檔案的 block 數為主, Reduce 數量由系統決定 Sort 的規則為 key 的字母順序
- 27. 範例 JobTracker 先選了三個 Tracker 做 map I am a tiger, you are also a tiger a,2 also,1 am,1 are,1 I,1 tiger,2 you,1 reduce reduce map map map Map 結束後, hadoop 進行中間資料的整理與排序 JobTracker 再選兩個 TaskTracker 作 reduce I,1 am,1 a,1 tiger,1 you,1 are,1 also,1 a, 1 tiger,1 a,2 also,1 am,1 are,1 I, 1 tiger,2 you,1 a, 1 a,1 also,1 am,1 are,1 I,1 tiger,1 tiger,1 you,1
- 28. Console 端 編譯與執行 王耀聰 陳威宇 [email_address] [email_address]
- 29. Java 之編譯與執行 編譯 javac Δ -classpath Δ hadoop-*-core.jar Δ -d Δ MyJava Δ MyCode.java 封裝 jar Δ -cvf Δ MyJar.jar Δ -C Δ MyJava Δ . 執行 bin/hadoop Δ jar Δ MyJar.jar Δ MyCode Δ HDFS_Input/ Δ HDFS_Output/ 所在的執行目錄為 Hadoop_Home ./MyJava = 編譯後程式碼目錄 Myjar.jar = 封裝後的編譯檔 先放些文件檔到 HDFS 上的 input 目錄 ./input; ./ouput = hdfs 的輸入、輸出目錄
- 30. WordCount1 練習 (I) cd $HADOOP_HOME bin/hadoop dfs -mkdir input echo "I like NCHC Cloud Course." > inputwc/input1 echo "I like nchc Cloud Course, and we enjoy this crouse." > inputwc/input2 bin/hadoop dfs -put inputwc inputwc bin/hadoop dfs -ls input
- 31. WordCount1 練習 (II) 編輯 WordCount.java http://trac.nchc.org.tw/cloud/attachment/wiki/jazz/Hadoop_Lab6/WordCount.java?format=raw mkdir MyJava javac -classpath hadoop-*-core.jar -d MyJava WordCount.java jar -cvf wordcount.jar -C MyJava . bin/hadoop jar wordcount.jar WordCount input/ output/ 所在的執行目錄為 Hadoop_Home (因為 hadoop-*-core.jar ) javac 編譯時需要 classpath, 但 hadoop jar 時不用 wordcount.jar = 封裝後的編譯檔,但執行時需告知 class name Hadoop 進行運算時,只有 input 檔要放到 hdfs 上,以便 hadoop 分析運算; 執行檔( wordcount.jar )不需上傳,也不需每個 node 都放,程式的載入交由 java 處理
- 32. WordCount1 練習 (III)
- 33. WordCount1 練習 (IV)
- 34. BTW … 雖然 Hadoop 框架是用 Java 實作,但 Map/Reduce 應用程序則不一定要用 Java 來寫 Hadoop Streaming : 執行作業的工具,使用者可以用其他語言 (如: PHP )套用到 Hadoop 的 mapper 和 reducer Hadoop Pipes : C++ API
- 35. 透過 Eclipse 開發 王耀聰 陳威宇 [email_address] [email_address]
- 36. Requirements Hadoop 0.20.0 up Java 1.6 Eclipse 3.3 up Hadoop Eclipse Plugin 0.20.0 up
- 37. 安裝 Hadoop Eclipse Plugin Hadoop Eclipse Plugin 0.20.0 From $Hadoop_0.20.0_home/contrib/eclipse-plugin/hadoop-0.20.0-eclipse-plugin.jar Hadoop Eclipse Plugin 0.20.1 Compiler needed Or download from http://hadoop-eclipse-plugin.googlecode.com/files/hadoop-0.20.1-eclipse-plugin.jar copy to $Eclipse_home/plugins/
- 38. 1 打開 Eclipse, 設定專案目錄
- 39. 2. 使用 Hadoop mode 視野 Window Open Perspective Other 若有看到 MapReduce 的大象圖示代表 Hadoop Eclipse plugin 有安裝成功, 若沒有請檢查是否有安之裝正確
- 40. 3. 使用 Hadoop 視野,主畫面將出現三個功能
- 41. 4. 建立一個 Hadoop 專案 開出新專案 選擇 Map/Reduce 專案
- 42. 4-1. 輸入專案名稱並點選設定 Hadoop 安裝路徑 由此設定 Hadoop 的安裝路徑 由此設定專案名稱
- 43. 4-1-1. 填入 Hadoop 安裝路徑 於此輸入您 Hadoop 的安裝路徑,之後選擇 ok
- 44. 5. 設定 Hadoop 專案細節 1. 右鍵點選 2. 選擇 Properties
- 45. 5-1. 設定原始碼與文件路徑 以下請輸入正確的 Hadoop 原始碼與 API 文件檔路徑,如 source : /opt/hadoop/src/core/ javadoc : file:/opt/hadoop/docs/api/ 選擇 Java Build Path
- 46. 5-1-1. 完成圖
- 47. 5-2. 設定 java doc 的完整路徑 輸入 java 6 的 API 正確路徑,輸入完後可選擇 validate 以驗證是否正確 選擇 Javadoc Location
- 48. 6. 連結 Hadoop Server 與 Eclipse 點選此圖示
- 49. 6-1 . 設定你要連接的 Hadoop 主機 輸入主機位址或 domain name MapReduce 監聽的 Port ( 設定於 mapred-site.xml) HDFS 監聽的 Port ( 設定於 core-site.xml) 你在此 Hadoop Server 上的 Username 任意填一個名稱
- 50. 6-2 若正確設定則可得到以下畫面 HDFS 的資訊,可直接於此操作檢視、新增、上傳、刪除等命令 若有 Job 運作,可於此視窗檢視
- 51. 7. 新增一個 Hadoop 程式 首先先建立一個 WordCount 程式,其他欄位任意
- 52. 7.1 於程式窗格內輸入程式碼 此區為程式窗格
- 53. 7.2 補充:若之前 doc 部份設定正確,則滑鼠移至程式碼可取得 API 完整說明
- 54. 8. 運作 於欲運算的 程式碼 處點選右鍵 Run As Run on Hadoop
- 56. 8.2 運算資訊出現於 Eclipse 右下方的 Console 視窗 放大
- 57. 8.3 剛剛運算的結果出現如下圖 放大
- 58. Conclusions 優點 快速開發程式 易於除錯 智慧尋找函式庫 自動鍊結 API 直接操控 HDFS 與 JobTracker … 缺點 Plugin 並會因 Eclipse 版本而有不同的狀況
- 59. Map Reduce 程式架構 王耀聰 陳威宇 [email_address] [email_address]
- 60. <Key, Value> Pair Row Data Map Reduce Reduce Input Output key values key1 val key2 val key1 val … … Map Input Output Select Key key1 val val … . val
- 61. Class MR { static public Class Mapper … { } static public Class Reducer … { } main(){ Configuration conf = new Configuration(); Job job = new Job( conf , “job name"); job . setJarByClass ( thisMainClass.class ); job .setMapperClass(Mapper.class); job .setReduceClass(Reducer.class); FileInputFormat.addInputPaths (job, new Path(args[0])); FileOutputFormat.setOutputPath (job, new Path(args[1])); job . waitForCompletion (true); }} Program Prototype (v 0.20) Map 程式碼 Reduce 程式碼 其他的設定參數程式碼 Map 區 Reduce 區 設定區
- 62. Class Mapper (v 0.20) class MyMap extends Mapper < , , , > { // 全域變數區 public void map ( key, value , Context context ) throws IOException,InterruptedException { // 區域變數與程式邏輯區 context.write ( NewKey, NewValue ); } } 1 2 3 4 5 6 7 8 9 INPUT KEY Class OUTPUT VALUE Class OUTPUT KEY Class INPUT VALUE Class INPUT VALUE Class INPUT KEY Class import org.apache.hadoop.mapreduce.Mapper;
- 63. Class Reducer (v 0.20) class MyRed extends Reducer < , , , > { // 全域變數區 public void reduce ( key, Iterable< > values , Context context ) throws IOException, InterruptedException { // 區域變數與程式邏輯區 context. write( NewKey, NewValue ); } } 1 2 3 4 5 6 7 8 9 INPUT KEY Class OUTPUT VALUE Class OUTPUT KEY Class INPUT VALUE Class INPUT KEY Class INPUT VALUE Class import org.apache.hadoop.mapreduce.Reducer;
- 64. 其他常用的設定參數 設定 Combiner Job.setCombinerClass ( … ); 設定 output class Job.setMapOutputKeyClass( … ); Job.setMapOutputValueClass( … ); Job.setOutputKeyClass( … ); Job.setOutputValueClass( … );
- 65. Class Combiner 指定一個 combiner ,它負責對中間過程的輸出進行聚集,這會有助於降低從 Mapper 到 Reducer 數據傳輸量。 可不用設定交由 Hadoop 預設 也可不實做此程式,引用 Reducer 設定 JobConf.setCombinerClass(Class)
- 66. 範例一 (1) - mapper public class HelloHadoop { static public class HelloMapper extends Mapper< LongWritable , Text , LongWritable, Text > { public void map( LongWritable key, Text value, Context context ) throws IOException, InterruptedException { context.write ((LongWritable) key, (Text) value); } } // HelloReducer end ..( 待續 ) …
- 67. 範例一 (2) - reducer static public class HelloReducer extends Reducer< LongWritable , Text , LongWritable, Text > { public void reduce( LongWritable key, Iterable <Text> values, Context context ) throws IOException, InterruptedException { Text val = new Text(); for (Text str : values) { val.set(str.toString()); } context.write (key, val); } } // HelloReducer end ..( 待續 ) …
- 68. 範例一 (3) - main public static void main (String[] args) throws IOException, InterruptedException, ClassNotFoundException { Configuration conf = new Configuration(); Job job = new Job( conf , "Hadoop Hello World"); job . setJarByClass (HelloHadoop.class); FileInputFormat. setInputPaths (job, " input "); FileOutputFormat. setOutputPath (job, new Path(" output-hh1 ")); job . setMapperClass (HelloMapper.class); job . setReducerClass (HelloReducer.class); job. waitForCompletion (true); } // main end } // wordcount class end // 完
- 69. 程式設計一 HDFS 操作篇
- 70. 傳送檔案至 HDFS public class PutToHdfs { static boolean putToHdfs(String src, String dst, Configuration conf) { Path dstPath = new Path(dst); try { // 產生操作 hdfs 的物件 FileSystem hdfs = dstPath.getFileSystem(conf); // 上傳 hdfs.copyFromLocalFile(false, new Path(src),new Path(dst)); } catch (IOException e) { e.printStackTrace(); return false; } return true; } // 將檔案從 local 上傳到 hdfs , src 為 local 的來源 , dst 為 hdfs 的目的端
- 71. 從 HDFS 取回檔案 public class GetFromHdfs { static boolean getFromHdfs(String src,String dst, Configuration conf) { Path dstPath = new Path(src); try { // 產生操作 hdfs 的物件 FileSystem hdfs = dstPath.getFileSystem(conf); // 下載 hdfs.copyToLocalFile(false, new Path(src),new Path(dst)); } catch (IOException e) { e.printStackTrace(); return false; } return true; } // 將檔案從 hdfs 下載回 local, src 為 hdfs 的來源 , dst 為 local 的目的端
- 72. 檢查與刪除檔案 public class CheckAndDelete { static boolean checkAndDelete(final String path, Configuration conf) { Path dst_path = new Path(path); try { // 產生操作 hdfs 的物件 FileSystem hdfs = dst_path.getFileSystem(conf); // 檢查是否存在 if (hdfs.exists(dst_path)) { // 有則刪除 hdfs.delete(dst_path, true); } } catch (IOException e) { e.printStackTrace(); return false; } return true; } // checkAndDelete 函式,檢查是否存在該資料夾,若有則刪除之
- 73. 程式設計二 範例程式
- 74. 範例二 (1) HelloHadoopV2 說明: 此程式碼比 HelloHadoop 增加了 * 檢查輸出資料夾是否存在並刪除 * input 資料夾內的資料若大於兩個,則資料不會被覆蓋 * map 與 reduce 拆開以利程式再利用 測試方法: 將此程式運作在 hadoop 0.20 平台上,執行: --------------------------- hadoop jar V2.jar HelloHadoopV2 --------------------------- 注意: 1. 在 hdfs 上來源檔案的路徑為 "/user/$YOUR_NAME/input" , 請注意必須先放資料到此 hdfs 上的資料夾內,且此資料夾內只能放檔案,不可再放資料夾 2. 運算完後,程式將執行結果放在 hdfs 的輸出路徑為 "/user/$YOUR_NAME/output-hh2"
- 75. 範例二 (2) public class HelloHadoopV2 { public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { Configuration conf = new Configuration(); Job job = new Job(conf, "Hadoop Hello World 2"); job.setJarByClass(HelloHadoopV2.class); // 設定 map and reduce 以及 Combiner class job.setMapperClass(HelloMapperV2.class); job.setCombinerClass(HelloReducerV2.class); job.setReducerClass(HelloReducerV2.class); // 設定 map 的輸出型態 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); // 設定 reduce 的輸出型態 job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.addInputPath (job, new Path("input")); FileOutputFormat.setOutputPath (job, new Path("output-hh2")); // 呼叫 checkAndDelete 函式, // 檢查是否存在該資料夾,若有則刪除之 CheckAndDelete.checkAndDelete("output-hh2", conf); boolean status = job.waitForCompletion(true); if (status) { System.err.println("Integrate Alert Job Finished !"); } else { System.err.println("Integrate Alert Job Failed !"); System.exit(1); } } }
- 76. 範例二 (3) public class HelloMapperV2 extends Mapper <LongWritable, Text, Text, Text> { public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { context.write(new Text(key.toString()), value); } } public class HelloReducerV2 extends Reducer<Text, Text, Text, Text> { public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { String str = new String(""); Text final_key = new Text(); Text final_value = new Text(); // 將 key 值相同的 values ,透過 && 符號分隔之 for (Text tmp : values) { str += tmp.toString() + " &&"; } final_key.set(key); final_value.set(str); context.write(final_key, final_value); } }
- 77. 範例三 (1) HelloHadoopV3 說明: 此程式碼再利用了 HelloHadoopV2 的 map , reduce 檔,並且 自動將檔案上傳到 hdfs 上運算並自動取回結果,還有 提示訊息 、參數輸入 與 印出運算時間 的功能 測試方法: 將此程式運作在 hadoop 0.20 平台上,執行: --------------------------- hadoop jar V3.jar HelloHadoopV3 <local_input> <local_output> --------------------------- 注意: 1. 第一個輸入的參數是在 local 的 輸入資料夾,請確認此資料夾內有資料並無子目錄 2. 第二個輸入的參數是在 local 的 運算結果資料夾,由程式產生不用事先建立,若有請刪除之
- 78. 範例三 (2) public class HelloHadoopV3 { public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { String hdfs_input = "HH3_input"; String hdfs_output = "HH3_output"; Configuration conf = new Configuration(); // 宣告取得參數 String[] otherArgs = new GenericOptionsParser(conf, args) .getRemainingArgs(); // 如果參數數量不為 2 則印出提示訊息 if (otherArgs.length != 2) { System.err .println("Usage: hadoop jar HelloHadoopV3.jar <local_input> <local_output>"); System.exit(2); } Job job = new Job(conf, "Hadoop Hello World"); job.setJarByClass(HelloHadoopV3.class); // 再利用上個範例的 map 與 reduce job.setMapperClass(HelloMapperV2.class); job.setCombinerClass(HelloReducerV2.class); job.setReducerClass(HelloReducerV2.class); // 設定 map reduce 的 key value 輸出型態 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class);
- 79. 範例三 (2) // 用 checkAndDelete 函式防止 overhead 的錯誤 CheckAndDelete.checkAndDelete(hdfs_input, conf); CheckAndDelete.checkAndDelete(hdfs_output, conf); // 放檔案到 hdfs PutToHdfs.putToHdfs(args[0], hdfs_input, conf); // 設定 hdfs 的輸入輸出來源路定 FileInputFormat.addInputPath(job, new Path(hdfs_input)); FileOutputFormat.setOutputPath(job, new Path(hdfs_output)); long start = System.nanoTime(); job.waitForCompletion(true); // 把 hdfs 的結果取下 GetFromHdfs.getFromHdfs(hdfs_output, args[1], conf); boolean status = job.waitForCompletion(true); // 計算時間 if (status) { System.err.println("Integrate Alert Job Finished !"); long time = System.nanoTime() - start; System.err.println(time * (1E-9) + " secs."); } else { System.err.println("Integrate Alert Job Failed !"); System.exit(1); } } }
- 80. 範例四 (1) public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: hadoop jar WordCount.jar <input> <output>"); System.exit(2); } Job job = new Job(conf, "Word Count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); CheckAndDelete.checkAndDelete(args[1], conf); System.exit(job.waitForCompletion(true) ? 0 : 1); }
- 81. 範例四 (2) class TokenizerMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map( LongWritable key, Text value, Context context ) throws IOException , InterruptedException { String line = ((Text) value).toString(); StringTokenizer itr = new StringTokenizer(line); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); }}} 1 2 3 4 5 6 7 8 9 < no , 1 > < news , 1 > < is , 1 > < a, 1 > < good , 1 > < news, 1 > <word,one> Input key Input value ………………… . ………………… No news is a good news. ………………… /user/hadooper/input/a.txt itr line no news news is good a itr itr itr itr itr itr
- 82. 範例四 (3) class IntSumReducer extends Reducer< Text , IntWritable , Text, IntWritable > { IntWritable result = new IntWritable(); public void reduce( Text key , Iterable < IntWritable > values , Context context ) throws IOException , InterruptedException { int sum = 0; for ( IntWritable val : values ) sum += val .get(); result.set(sum); context .write ( key, result ); }} 1 2 3 4 5 6 7 8 < news , 2 > <key,SunValue> <word,one> news 1 1 < a, 1 > < good, 1 > < is, 1 > < news, 1 1 > < no, 1 > for ( int i ; i < values.length ; i ++ ){ sum += values[i].get() }
- 83. 範例五 (1) WordCountV2 說明: 用於字數統計,並且增加略過大小寫辨識、符號篩除等功能 測試方法: 將此程式運作在 hadoop 0.20 平台上,執行: --------------------------- hadoop jar WCV2.jar WordCountV2 -Dwordcount.case.sensitive=false \ <input> <output> -skip patterns/patterns.txt --------------------------- 注意: 1. 在 hdfs 上來源檔案的路徑為 你所指定的 <input> 請注意必須先放資料到此 hdfs 上的資料夾內,且此資料夾內只能放檔案,不可再放資料夾 2. 運算完後,程式將執行結果放在 hdfs 的輸出路徑為 你所指定的 <output> 3. 請建立一個資料夾 pattern 並在裡面放置 pattern.txt ,內容如 (一行一個,前置提示符號 \ ) \ . \ , \ !
- 84. 範例五 (2) public class WordCountV2 extends Configured implements Tool { public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { static enum Counters { INPUT_WORDS } private final static IntWritable one = new IntWritable(1); private Text word = new Text(); private boolean caseSensitive = true; private Set<String> patternsToSkip = new HashSet<String>(); private long numRecords = 0; private String inputFile; public void configure(JobConf job) { caseSensitive = job.getBoolean("wordcount.case.sensitive", true); inputFile = job.get("map.input.file"); if (job.getBoolean("wordcount.skip.patterns", false)) { Path[] patternsFiles = new Path[0]; try { patternsFiles = DistributedCache.getLocalCacheFiles(job); } catch (IOException ioe) { System.err .println("Caught exception while getting cached files: " + StringUtils.stringifyException(ioe)); } for (Path patternsFile : patternsFiles) { parseSkipFile(patternsFile); }}} private void parseSkipFile(Path patternsFile) { try { BufferedReader fis = new BufferedReader(new FileReader( patternsFile.toString())); String pattern = null; while ((pattern = fis.readLine()) != null) { patternsToSkip.add(pattern); } } catch (IOException ioe) { System.err.println("Caught exception while parsing the cached file '"+ patternsFile + "' : " + tringUtils.stringifyException(ioe)); }} public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = (caseSensitive) ? value.toString() : value.toString() .toLowerCase(); for (String pattern : patternsToSkip) line = line.replaceAll(pattern, ""); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); output.collect(word, one); reporter.incrCounter(Counters.INPUT_WORDS, 1); }
- 85. 範例五 (3) if ((++numRecords % 100) == 0) { reporter.setStatus("Finished processing " + numRecords + " records " + "from the input file: " + inputFile); } } } public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } } public int run(String[] args) throws Exception { JobConf conf = new JobConf(getConf(), WordCount.class); conf.setJobName("wordcount"); String[] otherArgs = new GenericOptionsParser(conf, args) .getRemainingArgs(); if (otherArgs.length < 2) { System.out.println("WordCountV2 [-Dwordcount.case.sensitive=<false|true>] \\ "); System.out.println(" <inDir> <outDir> [-skip Pattern_file]"); return 0; } conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(Map.class); conf.setCombinerClass(Reduce.class); conf.setReducerClass(Reduce.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); List<String> other_args = new ArrayList<String>(); for (int i = 0; i < args.length; ++i) { if ("-skip".equals(args[i])) { DistributedCache .addCacheFile(new Path(args[++i]).toUri(), conf); conf.setBoolean("wordcount.skip.patterns", true); } else {other_args.add(args[i]); } } FileInputFormat.setInputPaths(conf, new Path(other_args.get(0))); FileOutputFormat.setOutputPath(conf, new Path(other_args.get(1))); CheckAndDelete.checkAndDelete(other_args.get(1), conf); JobClient.runJob(conf); return 0; } public static void main(String[] args) throws Exception { int res = ToolRunner.run(new Configuration(), new WordCountV2(), args); System.exit(res); }}
- 86. 範例六 (1) WordIndex 說明: 將每個字出於哪個檔案,那一行印出來 測試方法: 將此程式運作在 hadoop 0.20 平台上,執行: --------------------------- hadoop jar WI.jar WordIndex <input> <output> --------------------------- 注意: 1. 在 hdfs 上來源檔案的路徑為 你所指定的 <input> 請注意必須先放資料到此 hdfs 上的資料夾內,且此資料夾內只能放檔案,不可再放資料夾 2. 運算完後,程式將執行結果放在 hdfs 的輸出路徑為 你所指定的 <output>
- 87. 範例六 (2) public class WordIndex { public static class wordindexM extends Mapper<LongWritable, Text, Text, Text> { public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { FileSplit fileSplit = (FileSplit) context.getInputSplit(); Text map_key = new Text(); Text map_value = new Text(); String line = value.toString(); StringTokenizer st = new StringTokenizer(line.toLowerCase()); while (st.hasMoreTokens()) { String word = st.nextToken(); map_key.set(word); map_value.set(fileSplit.getPath().getName() + ":" + line); context.write(map_key, map_value); } } } static public class wordindexR extends Reducer<Text, Text, Text, Text> { public void reduce(Text key, Iterable<Text> values, OutputCollector<Text, Text> output, Reporter reporter) throws IOException { String v = ""; StringBuilder ret = new StringBuilder("\n"); for (Text val : values) { v += val.toString().trim(); if (v.length() > 0) ret.append(v + "\n"); } output.collect((Text) key, new Text(ret.toString())); } }
- 88. 範例六 (2) public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args) .getRemainingArgs(); if (otherArgs.length < 2) { System.out.println("hadoop jar WordIndex.jar <inDir> <outDir>"); return; } Job job = new Job(conf, "word index"); job.setJobName("word inverted index"); job.setJarByClass(WordIndex.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); job.setMapperClass(wordindexM.class); job.setReducerClass(wordindexR.class); job.setCombinerClass(wordindexR.class); FileInputFormat.setInputPaths(job, args[0]); CheckAndDelete.checkAndDelete(args[1], conf); FileOutputFormat.setOutputPath(job, new Path(args[1])); long start = System.nanoTime(); job.waitForCompletion(true); long time = System.nanoTime() - start; System.err.println(time * (1E-9) + " secs."); }}
- 89. 範例七 (1) TsmMenu 說明: 將之前的功能整合起來 測試方法: 將此程式運作在 hadoop 0.20 平台上,執行: --------------------------- hadoop jar TsmMenu.jar < 功能 > --------------------------- 注意: 此程式需與之前的所有範例一起打包成一個 jar 檔
- 90. 範例七 (2) public class TsmMenu { public static void main(String argv[]) { int exitCode = -1; ProgramDriver pgd = new ProgramDriver(); if (argv.length < 1) { System.out.print("******************************************\n" + " 歡迎使用 TSM 的運算功能 \n" + " 指令: \n" + " Hadoop jar TSM-example-*.jar < 功能 > \n" + " 功能: \n" + " HelloHadoop: 秀出 Hadoop 的 <Key,Value> 為何 \n" + " HelloHadoopV2: 秀出 Hadoop 的 <Key,Value> 進階版 \n" + " HelloHadoopV3: 秀出 Hadoop 的 <Key,Value> 進化版 \n" + " WordCount: 計算輸入資料夾內分別在每個檔案的字數統計 \n" + " WordCountV2: WordCount 進階版 \n" + " WordIndex: 索引每個字與其所有出現的所在列 \n" + "******************************************\n"); } else { try { pgd.addClass("HelloHadoop", HelloHadoop.class, " Hadoop hello world"); pgd.addClass("HelloHadoopV2", HelloHadoopV2.class, " Hadoop hello world V2"); pgd.addClass("HelloHadoopV3", HelloHadoopV3.class, " Hadoop hello world V3"); pgd.addClass("WordCount", WordCount.class, " word count."); pgd.addClass("WordCountV2", WordCountV2.class, " word count V2."); pgd.addClass("WordIndex", WordIndex.class, "invert each word in line"); pgd.driver(argv); // Success exitCode = 0; System.exit(exitCode); } catch (Throwable e) { e.printStackTrace(); }}}}
- 91. Conclusions 以上範例程式碼包含 Hadoop 的 key,value 架構 操作 Hdfs 檔案系統 Map Reduce 運算方式 執行 hadoop 運算時,程式檔不用上傳至 hadoop 上,但資料需要再 HDFS 內 可運用範例七的程式達成連續運算 Hadoop 0.20 與 Hadoop 0.18 有些 API 有些許差異,盡可能完全改寫
- 92. Class MR { Class Mapper … { } Class Reducer … { } main(){ JobConf conf = new JobConf( “ MR.class ” ); conf.setMapperClass(Mapper.class); conf.setReduceClass(Reducer.class); FileInputFormat.setInputPaths (conf, new Path(args[0])); FileOutputFormat.setOutputPath (conf, new Path(args[1])); JobClient.runJob(conf); }} Program Prototype (v 0.18) Map 程式碼 Reduce 程式碼 其他的設定參數程式碼 Map 區 Reduce 區 設定區 補充
- 93. Class Mapper (v0.18) 補充 class MyMap extends MapReduceBase implements Mapper < , , , > { // 全域變數區 public void map ( key, value , OutputCollector< , > output , Reporter reporter) throws IOException { // 區域變數與程式邏輯區 output .collect( NewKey, NewValue ); } } 1 2 3 4 5 6 7 8 9 INPUT KEY INPUT VALUE OUTPUT VALUE OUTPUT KEY INPUT KEY INPUT VALUE OUTPUT VALUE OUTPUT KEY import org.apache.hadoop.mapred.*;
- 94. Class Reducer (v0.18) 補充 class MyRed extends MapReduceBase implements Reducer < , , , > { // 全域變數區 public void reduce ( key, Iterator< > values , OutputCollector< , > output , Reporter reporter) throws IOException { // 區域變數與程式邏輯區 output .collect( NewKey, NewValue ); } } 1 2 3 4 5 6 7 8 9 INPUT KEY INPUT VALUE OUTPUT VALUE OUTPUT KEY INPUT KEY INPUT VALUE OUTPUT VALUE OUTPUT KEY import org.apache.hadoop.mapred.*;
- 95. News! Google 獲得 MapReduce 專利 Named” system and method for efficient large-scale data processing” Patent #7,650,331 Claimed since 2004 Not programming language, but the merge methods What does it mean for Hadoop? 2010/01/20 ~
- 96. Map Reduce 專案分享 王耀聰 陳威宇 [email_address] [email_address]
- 97. 用 Hadoop 打造 Location Plus 「 Location Plus !」服務,擊敗了其他 38 組作品獲得 Yahoo 開發競賽的優勝 從大量的批踢踢 BBS 文章中,找出臺灣 17 個城市的熱門話題 每個城市提供 30 個熱門話題和相關的參考詞 可以讓使用者用這些熱門話題來搜尋 Yahoo 知識 + 、生活 + 、無名小站等內容 提供了手機版介面,讓使用者到任何地方就知道當地有哪些熱門話題 2009/11/17
- 98. Yahoo 使用 Hadoop 平台來發現發送垃圾郵件的殭屍網絡 ( 1 ) 垃圾郵件網站 ( 2 ) 垃圾郵件 ( 3 ) 垃圾郵件軟體( 4 ) 被感染的電腦 ( 5 ) 病毒或木馬 ( 6 ) 信件伺服器 ( 7 ) 用戶 ( 8 ) 網路流量
- 99. 案例:警訊整合系統 目的: 將原本複雜難懂的警訊日誌整合成易於明瞭的報告 透過“雲端”來運算大量資料 環境: hadoop 0.20 Java 1.6 Apache 2
- 100. [**] [1:538:15] NETBIOS SMB IPC$ unicode share access [**] [Classification: Generic Protocol Command Decode] [Priority: 3] 09/04-17:53:56.363811 168.150.177.165:1051 -> 168.150.177.166:139 TCP TTL:128 TOS:0x0 ID:4000 IpLen:20 DgmLen:138 DF ***AP*** Seq: 0x2E589B8 Ack: 0x642D47F9 Win: 0x4241 TcpLen: 20 [**] [1:1917:6] SCAN UPnP service discover attempt [**] [Classification: Detection of a Network Scan] [Priority: 3] 09/04-17:53:56.385573 168.150.177.164:1032 -> 239.255.255.250:1900 UDP TTL:1 TOS:0x0 ID:80 IpLen:20 DgmLen:161 Len: 133 [**] [1:1917:6] SCAN UPnP service discover attempt [**] [Classification: Detection of a Network Scan] [Priority: 3] 09/04-17:53:56.386910 168.150.177.164:1032 -> 239.255.255.250:1900 UDP TTL:1 TOS:0x0 ID:82 IpLen:20 DgmLen:161 Len: 133 [**] [1:1917:6] SCAN UPnP service discover attempt [**] [Classification: Detection of a Network Scan] [Priority: 3] 09/04-17:53:56.388244 168.150.177.164:1032 -> 239.255.255.250:1900 UDP TTL:1 TOS:0x0 ID:84 IpLen:20 DgmLen:161 Len: 133 [**] [1:1917:6] SCAN UPnP service discover attempt [**] [Classification: Detection of a Network Scan] [Priority: 3] 09/04-17:53:56.417045 168.150.177.164:45461 -> 168.150.177.1:1900 UDP TTL:1 TOS:0x0 ID:105 IpLen:20 DgmLen:161 Len: 133 [**] [1:1917:6] SCAN UPnP service discover attempt [**] [Classification: Detection of a Network Scan] [Priority: 3] 09/04-17:53:56.420759 168.150.177.164:45461 -> 168.150.177.1:1900 UDP TTL:1 TOS:0x0 ID:117 IpLen:20 DgmLen:160 Len: 132 [**] [1:1917:6] SCAN UPnP service discover attempt [**] [Classification: Detection of a Network Scan] [Priority: 3] 09/04-17:53:56.422095 168.150.177.164:45461 -> 168.150.177.1:1900 UDP TTL:1 TOS:0x0 ID:118 IpLen:20 DgmLen:161 Len: 133 [**] [1:2351:10] NETBIOS DCERPC ISystemActivator path overflow attempt little endian unicode [**] [Classification: Attempted Administrator Privilege Gain] [Priority: 1] 09/04-17:53:56.442445 198.8.16.1:10179 -> 168.150.177.164:135 TCP TTL:105 TOS:0x0 ID:49809 IpLen:20 DgmLen:1420 DF ***A**** Seq: 0xF9589BBF Ack: 0x82CCF5B7 Win: 0xFFFF TcpLen: 20 [Xref => http://www.microsoft.com/technet/security/bulletin/MS03-026.mspx][Xref => http://cgi.nessus.org/plugins/dump.php3?id=11808][Xref => http://cve.mitre.org/cgi-bin/cvename.cgi?name=2003-0352][Xref => http://www.securityfocus.com/bid/8205] 輸入資料
- 101. 輸出資料 Generate dot graph format
- 102. 系統分析 前處理 Map Reduce 運算 後續處理 網頁介面 輸入 資料 瀏覽 結果 報告
- 103. Alert Merge Example Key Values Host_1 Trojan Sip1,Sip2 80,443 4077,5002 tcp T1,T2,T3 Host_2 Trojan Sip1 443 5002 tcp T4 Host_3 D.D.O.S. Sip3,Sip4,Sip5 ,Sip6 53 6007,6008 tcp, udp T5 Destination IP Attack Signature Source IP Destination Port Source Port Packet Protocol Timestamp Host_1 Trojan Sip1 80 4077 tcp T1 Host_1 Trojan Sip2 80 4077 tcp T2 Host_1 Trojan Sip1 443 5002 tcp T3 Host_2 Trojan Sip1 443 5002 tcp T4 Host_3 D.D.O.S Sip3 53 6007 udp T5 Host_3 D.D.O.S Sip4 53 6008 tcp T5 Host_3 D.D.O.S Sip5 53 6007 udp T5 Host_3 D.D.O.S Sip6 53 6008 tcp T5
- 104. 程式流程圖 Source Regulation Integrate Alert Merge Extenstion Correlation Record Snort Logs Final Report
- 105. 結論 評估 系統分析 輸入輸出 系統元件 各元件參數與串流 實做 多次運算 前處理與後處理
- 106. QUESTIONS & THANKS