Hadoop Operations Powered By ... Hadoop (Hadoop Summit 2014 Amsterdam)
96 likes26,899 views

Adam Kawa, a data engineer at Spotify, discusses the intricacies of Hadoop operations, specifically focusing on data analysis and infrastructure utilized by Spotify. The document covers numerous technical challenges, optimizations, and lessons learned from analyzing data metrics, enhancing performance in Hadoop, and addressing capacity planning. Various strategies are presented for improving data utilization and retention policies based on user behavior and operational metrics.




































































































Hadoop Operations Powered By ... Hadoop (Hadoop Summit 2014 Amsterdam)
- 1. Adam Kawa Data Engineer @ Spotify Hadoop Operations Powered By … Hadoop
- 2. 1. How many times has Coldplay been streamed this month? 2. How many times was “Get Lucky” streamed during first 24h? 3. Who was the most popular artist in NYC last week? Labels, Advertisers, Partners
- 3. 1. What song to recommend Jay-Z when he wakes up? 2. Is Adam Kawa bored with Coldplay today? 3. How to get Arun to subscribe to Spotify Premium? Data Scientists
- 5. (Big) Data At Spotify ■ Data generated by +24M monthly active users and for users! - 2.2 TB of compressed data from users per day - 64 TB of data generated in Hadoop each day (triplicated)
- 6. Data Infrastructure At Spotify ■ Apache Hadoop YARN ■ Many other systems including - Kafka, Cassandra, Storm, Luigi in production - Giraph, Tez, Spark in the evaluation mode
- 7. ■ Probably the largest commercial Hadoop cluster in Europe! - 694 heterogeneous nodes - 14.25 PB of data consumed - ~12.000 jobs each day Apache Hadoop
- 8. March 2013 Tricky questions were asked!
- 9. 1. How many servers do you need to buy to survive one year? 2. What will you do to use them efficiently? 3. If we agree, don’t come back to us this year! OK? Finance Department
- 10. ■ One of Data Engineers responsible for answering these questions! Adam Kawa
- 11. ■ Examples of how to analyze various metrics, logs and files - generated by Hadoop - using Hadoop - to understand Hadoop - to avoid guesstimates! The Topic Of This Talk
- 12. ■ This knowledge can be useful to - measure how fast HDFS is growing - define an empirical retention policy - measure the performance of jobs - optimize the scheduler - and more What To Use It For
- 13. 1. Analyzing HDFS 2. Analyzing MapReduce and YARN Agenda
- 14. HDFS Garbage Collection On The NameNode
- 15. “ We don’t have any full GC pauses on the NN. Our GC stops the NN for less than 100 msec, on average! :) ” Adam Kawa @ Hadoop User Mailing List December 16th, 2013
- 16. “ Today, between 12:05 and 13:00 we had 5 full GC pauses on the NN. They stopped the NN for 34min47sec in total! :( ” Adam Kawa @ Spotify office, Stockholm January 13th, 2014
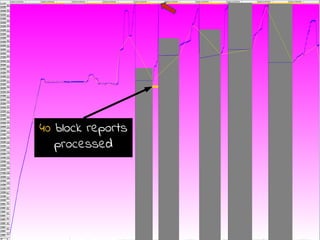
- 17. What happened between 12:05 and 13:00?
- 18. The NameNode was receiving the block reports from all the DataNodes Quick Answer!
- 19. 1. We started the NN when the DNs were running Detailed Answer
- 20. 1. We started the NN when the DNs were running 2. 502 DNs immediately registered to the NN ■ Within 1.2 sec (based on logs from the DNs) Detailed Answer
- 21. 1. We started the NN when the DNs were running 2. 502 DNs immediately registered to the NN ■ Within 1.2 sec (based on logs from the DNs) 3. 502 DNs started sending the block reports ■ dfs.blockreport.initialDelay = 30 minutes ■ 17 block reports per minute (on average) ■ +831K blocks in each block report (on average) Detailed Answer
- 22. 1. We started the NN when the DNs were running 2. 502 DNs immediately registered to the NN ■ Within 1.2 sec (based on logs from the DNs) 3. 502 DNs started sending the block reports ■ dfs.blockreport.initialDelay = 30 minutes ■ 17 block reports per minute (on average) ■ +831K blocks in each block report (on average) 4. This generated a high memory pressure on the NN ■ The NN ran into Full GC !!! Detailed Answer
- 23. Hadoop told us everything!
- 24. ■ Enable GC logging for the NameNode ■ Visualize e.g. GCViewer ■ Analyze memory usage patterns, GC pauses, misconfiguration Collecting The GC Stats
- 25. Time
- 26. This blue line shows the heap used by the NN
- 27. Loading FsImage
- 32. 5min 39sec of Full GC
- 34. Next Full GC
- 35. Next Full GC !!!
- 36. CMS collector starts at 98.5% of heap… We fixed that !
- 37. What happened in HDFS between mid-December 2013 and mid-January 2014?
- 39. ■ A persistent checkpoint of HDFS metadata ■ It contains information about files + directories ■ A binary file HDFS FsImage File
- 40. ■ Converts the content of FsImage to text formats - e.g. a tab-separated file or XML ■ Output is easily analyzed by any tools - e.g. Pig, Hive HDFS Offline Image Viewer
- 41. 50% of the data created during last 3 months
- 44. 1. NO data added that day 2. Many more files added after
- 45. The migration to YARN
- 47. Where did the small files come from?
- 48. ■ An interactive visualization of data in HDFS Twitter's HDFS-DU /app-logs avg. file size = 253 KB no. of dirs = 595K no. of files = 60.6M
- 49. ■ Statistics broken down by user/group name ■ Candidates for duplicate datasets ■ Inefficient MapReduce jobs - Small files - Skewed files More Uses Of FsImage File
- 50. ■ You can analyze FsImage to learn how fast HDFS grows ■ You can combine it with “external” datasets - number of daily/monthly active users - total size of logs generated by users - number of queries / day run by data analysts Advanced HDFS Capacity Planning
- 51. ■ You can also use ''trend button'' in Ganglia Simplified HDFS Capacity Planning If we do NOTHING, we might fill the cluster in September ...
- 52. What will we do to survive longer than September?
- 53. HDFS Retention
- 54. Question How many days after creation, a dataset is not accessed anymore? Retention Policy
- 55. Question How many days after creation, a dataset is not accessed anymore? Possible Solution ■ You can use modification_time and access_time from FsImage Empirical Retention Policy
- 56. ■ Logs and core datasets are accessed even many years after creation ■ Many reports are not accessed even a hour after creation ■ Most intermediate datasets needed less than a week ■ 10% of data has not been accessed for a year Our Retention Facts
- 58. ■ Some files/directories will be accessed more often than others e.g.: - fresh logs, core datasets, dictionary files Idea ■ To process it faster, increase its replication factor while it’s “hot” ■ To save disk space, decrease its replication factor when it becomes “cold” Hot Dataset
- 59. How to find them?
- 60. ■ Logs all filesystem access requests sent to the NN ■ Easy to parse and aggregate - a tab-separated line for each request HDFS Audit Log 2014-01-18 15:16:12,023 INFO FSNamesystem.audit: allowed=true ugi=kawaa (auth:SIMPLE) ip=/10.254.28.4 cmd=open src=/metadata/artist/2013-11-27/part-00061.avro dst=null perm=null
- 61. ■ JAR files stored in HDFS and used by Pig scripts ■ A dictionary file with metadata about log messages ■ Core datasets: playlists, users, top tracks Our Hot Datasets
- 63. ■ There are jobs that we schedule regularly - e.g. top lists for each country Idea ■ Before submitting it next time, use statistics from the previous executions of a job - To learn about its historical performance - To tweak its configuration settings Recurring MapReduce Jobs
- 64. We implemented ■ A pre-execution hook that automatically sets - Maximum size of an input split - Number of Reduce tasks ■ More settings can be tweaked - Memory - Combiner Jobs Autotuning
- 65. ■ Here, the goal is that a task runs approx. 10 min, on average - Inspired by LinkedIn at Hadoop Summit 2013 - Helpful in extreme cases (short/long running tasks) A Small PoC ;)
- 66. Another Example - Job Optimized Over Time
- 67. Even perfect manual settings may become outdated when an input dataset grows!
- 69. ■ Extracts the statistics from historical MapReduce jobs - Supports MRv1 and YARN ■ Stores them as Avro files - Enables easy analysis using e.g. Pig and Hive ■ Similar projects - Replephant, hRaven Zlatanitor = Zlatan + Monitor Zlatanitor
- 70. Low Medium High
- 71. A Slow Node - 40% lower throughput than the average Low Medium High
- 72. NIC negotiated 100MbE instead of 1GbE Low Medium High
- 73. According to Facebook ■ ”Small percentage of machines are responsible for large percentage of failures” - Worse performance - More alerts - More manual intervention Repeat Offenders
- 74. Adding nodes to the cluster increases performance. Sometimes, removing (crappy) nodes does too !
- 75. Fixing slow and failing tasks as well !
- 77. ■ YARN - can be moved to HDFS - They are stored as TFiles … :( - Small and many of them! Location Of Application Logs
- 78. ■ Frequent exceptions and bugs - Just looking at the last line of stderr shows a lot! ■ Possible optimizations - Memory and size of map input buffer What Might Be Checked a) AttributeError: 'int' object has no attribute 'iteritems' b) ValueError: invalid literal for int() with base 10: 'spotify' c) ValueError: Expecting , delimiter: line 1 column 3257 (char 3257) d) ImportError: No module named db_statistics
- 80. ■ We specified capacities and elasticity based on a combination of - “some” data - intuition - desire to shape future usage (!) Our Initial Capacities
- 81. ■ Basic information available on the Scheduler Web UI ■ Take print-screens! - Otherwise, you will lose the history of what you saw :( Overutilization And Underutilization
- 82. ■ Capacity Scheduler exposes these metrics via JMX ■ Ganglia does NOT display the metrics related to utilization of queues (by default) Visualizing Utilization Of Queue
- 83. ■ It collects JMX metrics from Java processes ■ It can send metrics to multiple destinations - Graphite, cacti/rrdtool, Ganglia - tab-separated text file - STDOUT - and more Jmxtrans
- 84. ■ Our Production queue often borrows resources - Usually from the Queue3 and Queue4 queues Overutilization And Underutilization
- 86. The Best Time For The Downtime?
- 87. Three Crowns
- 88. Three Crowns = Sweden
- 89. BONUS Some Cool Stuff From The Community
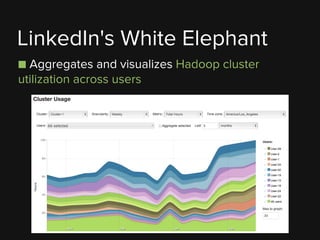
- 90. ■ Aggregates and visualizes Hadoop cluster utilization across users LinkedIn's White Elephant
- 91. ■ Collects run-time statistics from MR jobs - Stores them in HBase ■ Does not provide built-in visualization layer - The picture below comes from Twitter's blog Twitter's hRaven
- 92. That’s all!
- 93. ■ Analyzing Hadoop is also a “business” problem - Save money - Iterate faster - Avoid downtimes Summary
- 94. Thank you!
- 95. ■ To my awesome colleagues for great technical review: Piotr Krewski, Josh Baer, Rafal Wojdyla, Anna Dackiewicz, Magnus Runesson, Gustav Landén, Guido Urdaneta, Uldis Barbans More Thanks
- 97. Check out spotify.com/jobs or @Spotifyjobs for more information [email protected] Check out my blog: HakunaMapData.com Want to join the band?
- 98. Backup
- 99. ■ Tricky question! ■ Use production jobs that represent your workload ■ Use a metric that is independent from size of data that you process ■ Optimize one setting at the time Benchmarking
- 100. Benchmarking
- 101. Benchmarking