Hadoop World 2011: Hadoop and Performance - Todd Lipcon & Yanpei Chen, Cloudera
90 likes12,681 views

The document discusses performance measurements and improvements in Hadoop's MapReduce and HDFS, highlighting critical metrics such as latency, throughput, and efficiency. It details various optimizations made to enhance CPU efficiency, input/output operations, and job scheduling, resulting in significant performance boosts. The overall message emphasizes Hadoop's advancements in speed and efficiency, with benchmarks indicating improvements in random read performance and reduced CPU usage, making Hadoop faster than ever.













































Hadoop World 2011: Hadoop and Performance - Todd Lipcon & Yanpei Chen, Cloudera
- 1. Hadoop and Performance Todd Lipcon – Cloudera [email protected] Yanpei Chen – UC Berkeley [email protected] Copyright 2011 Cloudera Inc. All rights reserved
- 2. Measures of performance • MapReduce/HDFS • Per-job latency (measure job with a stop watch) • Cluster throughput (measure slot seconds) • Single-job latency and cluster throughput may be at odds! (eg speculative execution) • Efficiency (CPU-seconds used, bytes spilled, bytes shuffled) • HBase • Average, 99th percentile latency • Write/read throughput • In-cache vs out-of-cache Copyright 2011 Cloudera Inc. All rights reserved 2
- 3. How do we make our favorite elephant handle like a Ferrari? Photo credit: Telethon Italia, http://www.flickr.com/photos/telethonitalia/6171706697/ Copyright 2011 Cloudera Inc. All rights reserved 3
- 4. Performance from Hadoop developer’s POV • What do we measure? • Overhead = effort spent doing work you don’t care about • CPU overhead, lock contention: • CPU-seconds per HDFS GB written/read • Microseconds of latency to read 64K from OS cache via HDFS • Number of concurrent reads per second from many threads • Scheduler/framework overhead • No-op MR jobs (sleep –mt 1 –rt 1 –m 5000 –r 1) • Disk utilization • iostat: avg sectors/req, %util, MB/sec R/W Copyright 2011 Cloudera Inc. All rights reserved 4
- 5. Hadoop Performance myths • Java is slow? • Most of Hadoop is IO or network bound, not CPU • In the few CPU hot spots, we can use JNI or sun.misc.Unsafe • Java doesn’t give you enough low-level system access? • JNI allows us to call any syscall that C can! • We can integrate tight assembly code too! • Hadoop’s IO path has too many layers • We trust that the 60+ developers of ext4, XFS, and the Linux IO scheduler know more about low-level IO than we do! • Every system has a file layout and IO scheduler; those that do their own usually do it for portability (some RDBMS) Copyright 2011 Cloudera Inc. All rights reserved 5
- 6. Lies, damn lies, and statistics benchmarks Copyright 2011 Cloudera Inc. All rights reserved 6
- 7. HDFS/MR Improvements: IO/Caching • MapReduce is designed to do primarily sequential IO • Linux IO scheduler read-ahead heuristics are weak • HDFS 0.20 does many seeks even for sequential access • Many datasets are significantly larger than memory capacity; caching them is a waste of memory • Doing MR jobs on large input sets evicts useful data from memory (dentries, inodes, HBase HFiles) • Linux employs lazy page writeback of written data in case it is re-written (which HDFS never does!) • If dirty pages take up more than dirty_ratio of memory, forces blocking of all writes! (IO stalls even on underutilized drives) Copyright 2011 Cloudera Inc. All rights reserved 7
- 8. HDFS/MR Improvements: IO/Caching Solutions • Linux provides three useful syscalls: • posix_fadvise(POSIX_FADV_WILLNEED): hint to start reading in a given range of a file (e.g. forced readahead) • posix_fadvise(POSIX_FADV_DONTNEED): hint to drop a range of file from cache (e.g. after we’ve read it) • sync_file_range(SYNC_FILE_RANGE_WRITE): enqueue dirty pages for immediate (but asynchronous) writeback • Explicit readahead short-circuits bad Linux heuristics, causes larger IOs to device. Marked async in kernel to allow better reordering. • Dropping unnecessary data from cache leaves more room for more important data. • Explicit writeback avoids blocking behavior when too many pages are dirty. Copyright 2011 Cloudera Inc. All rights reserved 8
- 9. HDFS/MR Improvements: IO/Caching Results • ~20% improvement on terasort wall-clock • Disk utilization much higher • CPU utilization graph much smoother Before After Copyright 2011 Cloudera Inc. All rights reserved 9
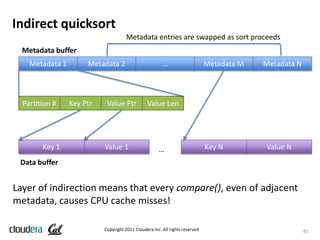
- 10. MR CPU Improvements: Sort • CPU inefficiency: • Many CPU cycles in WritableComparator.compareBytes • Naïve looping over parallel byte arrays: slow! • Optimization: Use sun.misc.Unsafe for ~4x reduction in CPU usage of this function! (compare 64 bits at a time) • CPU cache usage: • “Indirect QuickSort” is used for the sort algorithm in MR • Sort operates on an array of pointers to data, but bad cache- locality properties • Optimization: include 4-byte key prefix with pointer, avoiding memory indirection for most comparisons Copyright 2011 Cloudera Inc. All rights reserved 10
- 11. Benchmark results CDH3u2 vs optimized build with cache-conscious sort and IO scheduling advice. 1TB sort, 10 nodes, 24G RAM, 6 disks (lower is better) 1 0.9 0.8 Relative time 0.7 0.6 0.5 CDH3u2 0.4 Optimized 0.3 0.2 0.1 30m 24m 31h 21h 19h 15h 0 Wall-clock Map slot-hours Reduce slot-hours Copyright 2011 Cloudera Inc. All rights reserved 11
- 12. MR Improvements: Scheduler • 0.20.2: • TaskTrackers heartbeat once every 3 seconds, even on a small cluster • Each heartbeat assigns exactly 1 task to a TT • If tasks run for less than 3*slotCount seconds, TT will be underutilized (tasks finish faster than assigned) • Trunk/0.20.205/CDH3: • Assign multiple tasks per heartbeat • Heartbeat rate dropped to 0.3 seconds on small clusters (adaptive for larger) • “Out-of-band heartbeats” on any task completion Copyright 2011 Cloudera Inc. All rights reserved 12
- 13. MR Improvements: Scheduler results 30.3 24 0.20.2 12 Current 3.3 Minimum job latency (s) Tasks scheduled/sec (lower is better) (higher is better) 10 node cluster, 10 map slots per machine. hadoop jar examples.jar sleep –mt 1 –rt 1 –m 5000 –r 1 Copyright 2011 Cloudera Inc. All rights reserved 13
- 14. HDFS CPU Improvements: Checksumming • HDFS checksums every piece of data in/out • Significant CPU overhead • Measure by putting ~1G in HDFS, cat file in a loop • 0.20.2: ~30-50% of CPU time is CRC32 computation! • Optimizations: • Switch to “bulk” API: verify/compute 64KB at a time instead of 512 bytes (better instruction cache locality, amortize JNI overhead) • Switch to CRC32C polynomial, SSE4.2, highly tuned assembly (~8 bytes per cycle with instruction level parallelism!) Copyright 2011 Cloudera Inc. All rights reserved 14
- 15. Checksum improvements (lower is better) 1360us 100% 90% 80% 70% 60% 760us 50% CDH3u0 40% Optimized 30% 20% 10% 0% Random-read latency Random-read CPU Sequential-read CPU usage usage Post-optimization: only 16% overhead vs un-checksummed access Maintain ~800MB/sec from a single thread reading OS cache Copyright 2011 Cloudera Inc. All rights reserved 15
- 16. HDFS Random access • 0.20.2: • Each individual read operation reconnects to DataNode • Much TCP Handshake overhead, thread creation, etc • 0.23: • Clients cache open sockets to each datanode (like HTTP Keepalive) • HBase-like access patterns use a finite small number of sockets • Rewritten BlockReader to eliminate a data copy • Eliminated lock contention in DataNode’s FSDataset class Copyright 2011 Cloudera Inc. All rights reserved 16
- 17. Random-read micro benchmark (higher is better) 700 600 Speed (MB/sec) 500 400 300 200 100 106 253 299 247 488 635 187 477 633 0 4 threads, 1 file 16 threads, 1 file 8 threads, 2 files 0.20.2 Trunk (no native) Trunk (native) TestParallelRead benchmark, modified to 100% random read proportion. Quad core Core i7 [email protected] Copyright 2011 Cloudera Inc. All rights reserved 17
- 18. Random-read macro benchmark (HBase YCSB) Copyright 2011 Cloudera Inc. All rights reserved 18
- 19. MR2 Improvements: Shuffle • Trunk/MR2 features many shuffle improvements: • No more io.sort.record.percent (important but obscure tunable): now auto-tuned • Reducers now fetch several map outputs on one TCP connection instead of reconnecting (better fetch throughput) • MR2: shuffle server rewritten with Netty, zero-copy sendfile support (less CPU usage on TaskTracker, fewer timeouts) • 30% improvement in shuffle throughput Copyright 2011 Cloudera Inc. All rights reserved 19
- 20. Summary • Hadoop is now faster than ever… • 2-3x random read performance boost vs 0.20.2 • Significantly less CPU usage for a given workload • Up to 2x faster wall-clock time for shuffle-intensive jobs • …and getting faster every day! Copyright 2011 Cloudera Inc. All rights reserved 20
- 21. Upstream JIRAs • Random read keepalive: HDFS-941 • Faster Checksums: HDFS-2080 • fadvise/sync_file_range: HADOOP-7714 • Faster compareBytes: HADOOP-7761 • MR sort cache locality: MAPREDUCE-3235 • Rewritten map-side shuffle: MAPREDUCE-64 • Rewritten reduce side shuffle: MAPREDUCE-318 • Others still in progress: • http://tiny.cloudera.com/perf-jiras Copyright 2011 Cloudera Inc. All rights reserved 21
- 22. Coming to a Hadoop near you! • Some of these improvements will be in CDH3u3: • (~25% faster terasort, ~2x faster HBase random read) • 10-node terasort, 6x7200RPM, 24G RAM: 24.5 minutes • Almost all of these improvements will be in Apache Hadoop 0.23.1 • Many improvements come from upstream Linux itself! • ext4 vs ext3 (less fragmentation, faster unlink()) • per-block-device writeback (Linux 2.6.32) Copyright 2011 Cloudera Inc. All rights reserved 22
- 23. Next: Advances in MapReduce performance measurement Copyright 2011 Cloudera Inc. All rights reserved Slide 23
- 24. State of the art in MapReduce performance • Essential but insufficient benchmarks Gridmix2 Hive BM Hibench PigMix Gridmix3 Copyright 2011 Cloudera Inc. All rights reserved Slide 24
- 25. State of the art in MapReduce performance • Essential but insufficient benchmarks Gridmix2 Hive BM Hibench PigMix Gridmix3 Data sizes Intensity variations Job types Cluster independent Synthetic workloads Copyright 2011 Cloudera Inc. All rights reserved Slide 25
- 26. State of the art in MapReduce performance • Essential but insufficient benchmarks Representative? Gridmix2 Hive BM Hibench PigMix Gridmix3 Data sizes Intensity variations Job types Cluster independent Synthetic workloads Replay? Copyright 2011 Cloudera Inc. All rights reserved Slide 26
- 27. State of the art in MapReduce performance • Essential but insufficient benchmarks Representative? Gridmix2 Hive BM Hibench PigMix Gridmix3 Data sizes √ Intensity variations √ Job types √ Cluster independent √ √ √ √ Synthetic workloads Replay? Copyright 2011 Cloudera Inc. All rights reserved Slide 27
- 28. Need to measure what production MapReduce systems REALLY do From generic large elephant to realistic elephant herd (benchmarks) (workloads) Copyright 2011 Cloudera Inc. All rights reserved Slide 28
- 29. Need to advance the state of the art • Develop scientific knowledge - Workload description, synthesis, replay • Apply to system engineering - Design, measurement, QA, certification, design Copyright 2011 Cloudera Inc. All rights reserved Slide 29
- 30. First comparison of production MapReduce • Facebook trace (FB) - 6 months in 2009, approx. 6000 jobs per day • Cloudera customer trace (CC-b) - 1 week in 2011, approx. 3000 jobs per day • Not in this talk – Traces from 4 other customers - E-commerce, media/telecomm, retail Copyright 2011 Cloudera Inc. All rights reserved Slide 30
- 31. Three dimensions to compare Representative? Data sizes Intensity variations Job types Cluster independent Synthetic workloads Copyright 2011 Cloudera Inc. All rights reserved Slide 31
- 32. Different job sizes CDF CDF CDF 1 1 1 0.8 0.8 0.8 CC-b 0.6 0.6 0.6 0.4 0.4 0.4 FB 0.2 0.2 0.2 0 0 0 1E+0E+3E+6GB TB 0 1 1 1E+9 KB MB 1E+12 1E+0E+3E+6GB TB 0 KB 1 1E+9 1 MB 0 KB MB 1 1E+12 1 1 GB TB 1E+12 1E+0E+3E+6E+9 Input size Shuffle size Output size Copyright 2011 Cloudera Inc. All rights reserved Slide 32
- 33. Different workload time variation FB CC-b 1000 300 Number 200 of jobs 500 100 0 0 Input + 2.E+13 4.E+13 shuffle + output 1.E+13 2.E+13 data size 0.E+00 0.E+00 6.E+06 6.E+07 Map + 4.E+07 reduce 3.E+06 2.E+07 task times 0.E+00 0.E+00 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 Days since a Sunday Days since a Tuesday Copyright 2011 Cloudera Inc. All rights reserved Slide 33
- 34. Different job types – identify by kmeans Map time Red. time Input Shuffle Output Duration (task sec) (task sec) Copyright 2011 Cloudera Inc. All rights reserved Slide 34
- 35. Different job types – identify by kmeans % of Map time Red. time Input Shuffle Output Duration jobs (task sec) (task sec) 95.8 21 KB 0 871 KB 32 s 20 0 3.3 381 KB 0 1.9 GB 21 min 6097 0 0.2 10 KB 0 4.2 GB 1 hr 50 min 26,321 0 0.1 405 KB 0 447 GB 1 hr 10 min 66,657 0 0.02 446 KB 0 1.1 TB 5 hrs 5 min 125,662 0 0.05 230 KB 8.8 GB 491 MB 15 min 104,338 66,760 0.03 1.9 TB 502 MB 2.6 GB 30 min 348, 942 76,738 0.01 418 GB 2.5 TB 45 GB 1 hr 25 min 1,076,089 974,395 0.07 255 GB 788 GB 1.6 GB 35 min 384, 562 338,050 0.002 7.6 TB 51 GB 104 KB 55 min 4,843,452 853,911 Copyright 2011 Cloudera Inc. All rights reserved Slide 35
- 36. Different job types – identify by kmeans % of Map time Red. time Input Shuffle Output Duration Description jobs (task sec) (task sec) 95.8 21 KB 0 871 KB 32 s 20 0 Small jobs 3.3 381 KB 0 1.9 GB 21 min 6097 0 Load data, fast 0.2 10 KB 0 4.2 GB 1 hr 50 min 26,321 0 Load data, slow 0.1 405 KB 0 447 GB 1 hr 10 min 66,657 0 Load data, large 0.02 446 KB 0 1.1 TB 5 hrs 5 min 125,662 0 Load data, huge 0.05 230 KB 8.8 GB 491 MB 15 min 104,338 66,760 Aggregate, fast Aggregate and 0.03 1.9 TB 502 MB 2.6 GB 30 min 348, 942 76,738 expand Expand and 0.01 418 GB 2.5 TB 45 GB 1 hr 25 min 1,076,089 974,395 aggregate 0.07 255 GB 788 GB 1.6 GB 35 min 384, 562 338,050 Data transform 0.002 7.6 TB 51 GB 104 KB 55 min 4,843,452 853,911 Data summary Copyright 2011 Cloudera Inc. All rights reserved Slide 36
- 37. Different job types – summary FB CC-b % of jobs Description % of jobs Description 95.8 Small jobs 88.9 Small job 3.3 Load data, fast 7.7 Data transform “small” 0.2 Load data, slow 2.8 Data transform “med” 0.1 Load data, large Data transform “large”, 0.5 0.02 Load data, huge map heavy 0.05 Aggregate, fast 0.1 Aggregate 0.03 Aggregate and expand 0.01 Expand and aggregate 0.07 Data transform 0.002 Data summary Copyright 2011 Cloudera Inc. All rights reserved Slide 37
- 38. Measure performance by replaying workload • Major advance over artificial benchmarks - “Performance is X for workload A, Y for workload B.” • Challenges: - Turn long trace (6 months) into short workload (1 day) - Do so while keeping the workload representative Copyright 2011 Cloudera Inc. All rights reserved Slide 38
- 39. Replay concatenated trace samples • Problem: Need short and representative workloads • Solution: concatenate continuous window trace samples E.g. Day long workload = Concat(24 x continuous hourly samples) or = Concat(6 x continuous 4-hourly samples) • Strength: Reproduce all statistics within a sample window • Limits: Introduces (controllable) sampling error Copyright 2011 Cloudera Inc. All rights reserved Slide 39
- 40. Verify that we get representative workloads CDFs for synthetic workloads CDF CDF CDF 1 1 1 0.8 0.8 0.8 0.6 0.6 0.6 0.4 0.4 0.4 0.2 0.2 0.2 0 CDF for 0 0 whole race 0 KB MB GB TB 0 KB MB GB TB 0 KB MB GB TB 1E+0 1E+3 1E+6 1E+91E+12 1E+0 1E+3 1E+6 1E+91E+12 1E+0 1E+3 1E+6 1E+91E+12 Output size – 4hr samples Output size – 1hr samples Output size – 15min samples Copyright 2011 Cloudera Inc. All rights reserved Slide 40
- 41. Case study: Compare FIFO vs. fair scheduler Replay on System 1 Fixed workload, Performance Fixed metrics, comparison Fixed env. Replay on System 2 Workload = Facebook-like synthetic workload, 24 x 1hr samples Metrics = average job latency Environment = 200-machines EC2 cluster, m1.large instances System 1 = FIFO scheduler System 2 = Fair scheduler Copyright 2011 Cloudera Inc. All rights reserved Slide 41
- 42. Choice of scheduler depends on workload! 100000 Fair scheduler Better Completion time (s) FIFO scheduler 1000 10 4800 4820 4840 4860 4880 4900 Job index (out of 6000+ total jobs in a day) 1000 Fair scheduler Completion time(s) FIFO scheduler Better 100 10 100 120 140 160 180 200 Job index (out of 6000+ total jobs in a day) Copyright 2011 Cloudera Inc. All rights reserved Slide 42
- 43. Takeaways • Need to consider workload-level performance! • Data sizes, arrival patterns, job types • Understanding performance is a community effort! • Not everyone is like Google/Yahoo/Facebook • Different features and metrics relevant to each use case • Check out our evolving MapReduce workload repository • www.eecs.berkeley.edu/~ychen2/SWIM.html Thanks!!! Copyright 2011 Cloudera Inc. All rights reserved Slide 43
- 44. Backup slides Copyright 2011 Cloudera Inc. All rights reserved Slide 44
- 45. Indirect quicksort Metadata entries are swapped as sort proceeds Metadata buffer Metadata 1 Metadata 2 … Metadata M Metadata N Partition # Key Ptr Value Ptr Value Len Key 1 Value 1 … Key N Value N Data buffer Layer of indirection means that every compare(), even of adjacent metadata, causes CPU cache misses! Copyright 2011 Cloudera Inc. All rights reserved 45
- 46. Indirect quicksort with “comparison proxies” Metadata buffer Metadata 1 Metadata 2 … Metadata M Metadata N Partition # Key prefix Key Ptr Value Ptr Value Len Copy first 4 bytes of key into metadata Key 1 Value 1 … Data buffer Many comparisons avoid the indirect memory lookup into the data buffer: 1.6x improvement in total map side CPU usage for terasort! Copyright 2011 Cloudera Inc. All rights reserved 46