





































![VS-Quant
Per-vector scaled quantization for low-precision inference
Modified vector MAC unit for VS-Quant
Fine-grained scale factors per vector
[Dai et al., MLSYS 2021]
Works with either post-training quantization or quantization-aware retraining!](https://image.slidesharecdn.com/hardwarefordeeplearning-250330111237-5be5f59f/85/Hardware-for-Deep-Learning-AI-ML-CNN-pdf-39-320.jpg)









![PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
Global
Controller
Global Buffer
MAGNet System
DRAM
Processing Element (PE)
X
Wb Ab
X
Wb Ab
X
Wb Ab
VectorSize
Weight
Collector
Accumulation
Collector
+
+
+
+
+
Vector MAC unit
[Venkatesan et al., ICCAD 2019]
Magnet
Configurable using synthesizable SystemC, HW generated using HLS tools](https://image.slidesharecdn.com/hardwarefordeeplearning-250330111237-5be5f59f/85/Hardware-for-Deep-Learning-AI-ML-CNN-pdf-51-320.jpg)
![Energy-efficient DL Inference accelerator
Transformers, VS-Quant INT4, TSMC 5nm
• Efficient architecture
• Used MAGNet [Venkatesan et al., ICCAD 2019] to design a low-
precision DL inference accelerator for Transformers
• Multi-level dataflow to improve data reuse and energy efficiency
• Low-precision data format: VS-Quant INT4
• Hardware-software techniques to tolerate quantization error
• Enable low cost multiply-accumulate (MAC) operations
• Reduce storage and data movement
• Special function units
• TSMC 5nm
• 1024 4-bit MACs/cycle (512 8-bit)
• 0.153 mm2 chip
• Voltage range: 0.46V – 1.05V
• Frequency range: 152 MHz – 1760 MHz
• 95.6 TOPS/W with 50%-dense 4-bit input matrices
with VSQ enabled at 0.46V
• 0.8% energy overhead from VSQ support with 50%-
dense inputs at 0.67V
[Keller, Venkatesan, et al., “A 95.6-TOPS/W Deep Learning Inference Accelerator with Per-Vector Scaled 4-bit Quantization in 5nm”, JSSC 2023]](https://image.slidesharecdn.com/hardwarefordeeplearning-250330111237-5be5f59f/85/Hardware-for-Deep-Learning-AI-ML-CNN-pdf-52-320.jpg)



































Ad
More Related Content
Similar to Hardware for Deep Learning AI ML CNN.pdf (20)
More from AhmedSaeed115917 (7)





Ad
Recently uploaded (20)




















Ad
Hardware for Deep Learning AI ML CNN.pdf
- 1. Deep Learning Hardware: Past, Present, and Future CRA Snowbird Conference July 23, 2024 Bill Dally Chief Scientist and SVP of Research, NVIDIA Corporation Adjunct Professor of CS and EE, Stanford
- 2. Model Training Trained Model Fine Tuning Specialized Model Data Special Data Inference Query Answer Human Feedback 1012 Tokens 109 Images Application dependent $10M-50M GPU Time $100K-1M GPU Time 1K-1M Annotated Queries <1s GPU Time 100M-2T Parameters ~$3 x 10-4 per Word © 1K-1M Coding Medical Advice Education Writing Creative ChipDesign Retrieval Data Vendors Hardware Vendors CSPs End-Service Providers
- 3. Motivation
- 4. Deep Learning was Enabled by Hardware
- 5. VGG-19 Seq2Seq Resnet InceptionV3 Xception ResNeXt ELMo Wav2Vec 2.0 MoCo ResNet50 BERT Large GPT-1 Transformer XLNet Microsoft T-NLG GPT-2 1.5B Megatron-NLG GPT3-175B MT NLG 530B Chinchilla BLOOM PaLM GPT-MoE-1.8T DenseNet201 AlexNet 100 10,000 1,000,000 100,000,000 10,000,000,000 2012 2014 2016 2018 2020 2022 2024 Training Compute (p Before Transformers =3x/ yr Transformers = 16x / yr 107 in 10 years!
- 6. Some History
- 7. K20X 3.94 M40 6.84 P100 21.20 Q8000 261.00 A100 1248.00 0.00 500.00 1000.00 1500.00 2000.00 2500.00 4000.00 3500.00 3000.00 4500.00 4/1/12 8/14/13 12/27/14 5/10/16 9/22/17 2/4/19 6/18/20 10/31/21 3/15/23 Int 8 TOPS Single-Chip Inference Performance - 1000X in 10 years FP32 FMA FP16 HDP4 FP16 HMMA INT8 IMMA Sparsity H100 4000.00 V100 125.00 B200 20,000
- 8. Gains from • Number Representation • FP32, FP16, Int8, FP4 • (TF32, BF16) • ~16x, 32x • Complex Instructions • DP4, HMMA, IMMA • ~12.5x • Process • 28nm, 16nm, 7nm, 5nm, 4nm • ~2.5x, 3x • Sparsity ~2x • Die Size 2x • Model efficiency has also improved – overall gain > 1000x K20X 3.94 M40 6.84 P100 21.20 V100 125.00 Q8000 261.00 4000.00 0.00 500.00 1000.00 1500.00 2000.00 2500.00 3000.00 3500.00 4000.00 4500.00 4/1/12 8/14/13 12/27/14 5/10/16 9/22/17 2/4/19 6/18/20 10/31/21 3/15/23 Int 8 TOPS Single-Chip Inference Performance - 1000X in 10 years Scalar FP32 FP16 DP4A HMMA Tensor Cores A100 Structured Sparsity 1248.00 IMMA Int8 Tensor Cores H100 FP8 Transforme r Eng B200 20,000
- 9. Specialized Instructions Amortize Overhead Operation Energy** Overhead* HFMA 1.5pJ 2000% HDP4A 6.0pJ 500% HMMA 110pJ 22% IMMA 160pJ 16% *Overhead is instruction fetch, decode, and operand fetch – 30pJ **Energy numbers from 45nm process
- 10. 1 PFLOPS (TF32) 1 / 2 PLFLOPS (FP16 or BF16) (dense/sparse) 2 / 4 PLFOPS (FP8 or Int8) (dense/sparse) 3.4TB/s (HBM3) 94GB 18 NVLINK ports 400Gb/s each 900GB/s total 700W Transformer Engine Dynamic Programming Instructions 9 TOPS/W (Int8/FP8) Hopper H100 4PF Sparse FP8, 900GB/s, 700W
- 11. Blackwell B200 The Two Largest Dies Possible—Unified as One GPU 10 PetaFLOPS FP8 | 20 PetaFLOPS FP4 192GB HBM3e | 8 TB/sec HBM Bandwidth | 1.8TB/s NVLink 2 reticle-limited dies operate as One Unified CUDA GPU NV-HBI 10TB/s High Bandwidth Interface Full performance. No compromises 4X Training | 30X Inference | 25X Energy Efficiency & TCO Fast Memory 192GB HBM3e
- 12. 3D Parallelism It takes 20 GPUs to hold one copy of GPT4 model parameters Tensor Parallel Pipeline Parallel
- 13. GB200 NVL72 Delivers New Unit of Compute 36 GRACE CPUs 72 BLACKWELL GPUs Fully Connected NVLink Switch Rack GB200 NVL72 Training 720 PFLOPs Inference 1.4 EFLOPs NVL Model Size 27T params Multi-Node All-to-All 130 TB/s Multi-Node All-Reduce 260 TB/s
- 14. Scale-up – NVLink and NVSwitch – to 256 GPUs Scale- out – IB to 10,000s of GPUs Collectives Double Effective Network Bandwidth (AllReduce)
- 15. 100 10,000 1,000,000 100,000,000 10,000,000,000 2012 2014 2016 2018 2020 2022 2024 Training Compute (petaFLOPs) PASCAL KEPLER VOLTA HOPPER System Scaling NVLINK HGX HBM SATURN V 0.6PF SELENE 2.8 EF EOS 43 EF TF32 AMPERE TENSOR CORE TRANSFORMER ENGINE 70,000x in 5 years
- 16. Software
- 18. 2.4-2.9x From Software Improvements
- 21. Future Directions Number representation • Log numbers • Vector scaling (VS-Quant) • Optimal Clipping • Much cheaper math • Smaller numbers Sparsity • Activations • Lower density (vs 2:4 in A100/H100) Better tiling • Lower memory energy Circuits • Memory • Communication • 3D memory Process • Capacitance scaling Input Buffer Accumulation Buffer Datapath + MAC Weight Buffer Accumulation Collector Data Movement 6% 8% 16% 15% 8% 47%
- 23. S M 1 7 S E M 1 5 10 S E 1 7 X 8 int8 fp16 log8 sym8 spike analog Weight Buffer Activation Buffer Storage Transport Multiply Accumulate Operation •Attributes: • Cost • Operation energy • Movement energy • Accuracy • Dynamic range • Precision (error)
- 24. S M 1 7 S E M 1 5 10 S 1 4 X 8 int8 fp16 log8 sym8 spike analog EI EF 3 Dynamic Range
- 25. Symbol Representation (Codebook) Han et al. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding, arXiv 2015 clustering
- 29. •Dynamic Range 105 •WC Accuracy 4% •Vs Int8 – DR 102 •WC Accuracy 33% •Vs FP8 (E4M3) – DR 105 •WC Accuracy 6% Log4.3 S EI 1 4 3 EF
- 30. 1 3 5 7 9 11 13 15 1 3 5 7 9 Actual Value 11 13 15 Closest Represenatble Value 4-bit Integer Representation (Int4) 1 3 5 7 9 11 13 15 1 3 5 7 9 Actual Value 11 13 15 Closest Represenatble Value 4-bit Log Representation (L2.2) Max Error 9% Max Error 33%
- 31. 1 3 5 7 9 11 13 15 1 3 5 7 9 Actual Value 11 13 15 Closest Represenatble Value 4-bit Log Representation (L2.2) 1 3 5 7 9 11 13 15 1 3 5 7 9 Actual Value 11 13 15 Closest Representable value FP2.2 Max Error 9% Max Error 13%
- 32. • Log Numbers • Multiplies are cheap – just an add • Adds are hard – convert to integer, add, convert back • Fractional part of log is a lookup • Integer part of log is a shift • Can factor the lookup outside the summation • Only convert back after summation (and NLF) S EI 1 4 3 EF
- 33. S EI 1 4 3 EF Patent Application US2021/0056446A1 EI EF S
- 34. Optimum Clipping
- 35. Whatever number representation you use Pick the range optimally
- 36. clip clip large q. noise low density data
- 38. Vector Scaling
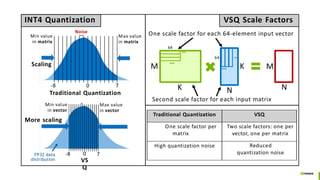
- 39. VS-Quant Per-vector scaled quantization for low-precision inference Modified vector MAC unit for VS-Quant Fine-grained scale factors per vector [Dai et al., MLSYS 2021] Works with either post-training quantization or quantization-aware retraining!
- 40. Traditional Quantization VSQ One scale factor per matrix Two scale factors: one per vector, one per matrix High quantization noise Reduced quantization noise Noise Scaling Max value in matrix Min value in matrix -8 0 7 Traditional Quantization -8 7 Min value in vector More scaling Max value in vector 0 VS Q INT4 Quantization FP32 data distribution VSQ Scale Factors M K K N M N 64 64 … … … … One scale factor for each 64-element input vector Second scale factor for each input matrix
- 41. Sparsity
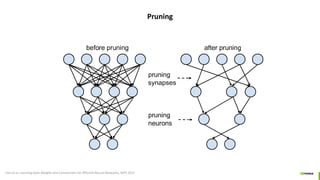
- 42. Pruning Han et al. Learning both Weights and Connections for Efficient Neural Networks, NIPS 2015
- 43. Structured Sparsity Mishra, Asit, et al. "Accelerating sparse deep neural networks." arXiv preprint arXiv:2104.08378 (2021) NVIDIA A100 Tensor Core GPU Architecture whitepaper
- 44. Accelerators
- 45. EIE (2016) Eyeriss (2016) SCNN (2017) Simba (2018)
- 46. Accelerators Employ: • Special Data Types and Operations •Do in 1 cycle what normally takes 10s or 100s – 10-1000x efficiency gain • Massive Parallelism – >1,000x, not 16x – with Locality • This gives performance, not efficiency • Optimized Memory • High bandwidth (and low energy) for specific data structures and operations • Reduced or Amortized Overhead • 10,000x efficiency gain for simple operations • Algorithm-Architecture Co-Design
- 47. Fast Accelerators since 1985 • Mossim Simulation Engine: Dally, W.J. and Bryant, R.E., 1985. A hardware architecture for switch-level simulation. IEEE Trans. CAD, 4(3), pp.239-250. • MARS Accelerator: Agrawal, P . and Dally, W.J., 1990. A hardware logic simulation system. IEEE Trans. CAD, 9(1), pp.19-29. • Reconfigurable Arithmetic Processor: Fiske, S. and Dally, W.J., 1988. The reconfigurable arithmetic processor . ISCA 1988. • Imagine: Kapasi, U.J., Rixner, S., Dally, W.J., Khailany, B., Ahn, J.H., Mattson, P . and Owens, J.D., 2003. Programmable stream processors. Computer, 36(8), pp.54-62. • ELM: Dally, W.J., Balfour, J., Black-Shaffer, D., Chen, J., Harting, R.C., Parikh, V., Park, J. and Sheffield, D., 2008. Efficient embedded computing. Computer, 41(7). • EIE: Han, S., Liu, X., Mao, H., Pu, J., Pedram, A., Horowitz, M.A. and Dally, W.J., 2016, June. EIE: efficient inference engine on compressed deep neural network, ISCA 2016 • SCNN:Parashar, A., Rhu, M., Mukkara, A., Puglielli, A., Venkatesan, R., Khailany, B., Emer, J., Keckler, S.W. and Dally, W.J., 2017, June. Scnn: An accelerator for compressed-sparse convolutional neural networks, ISCA 2017 • Darwin: Turakhia, Bejerano, and Dally, “Darwin: A Genomics Co-processor provides up to 15,000× acceleration on long read assembly”, ASPLOS 2018. • SATiN: Zhuo, Rucker, Wang, and Dally, “Hardware for Boolean Satisfiability Inference,”
- 48. Eliminating Instruction Overhead OOO CPU Instruction – 250pJ (99.99% overhead, ARM A-15) Area is proportional to energy – all 28nm 16b Int Add, 32fJ Evangelos Vasilakis. 2015. An Instruction Level Energy Characterization of Arm Processors. Foundation of Research and Technology Hellas, Inst. of Computer Science, Tech. Rep. FORTH-ICS/TR- 450 (2015)
- 49. Operation: Energy (pJ) 8b Add 0.03 16b Add 0.05 32b Add 0.1 16b FP Add 0.4 32b FP Add 0.9 8b Mult 0.2 32b Mult 3.1 16b FP Mult 1.1 32b FP Mult 3.7 32b SRAM Read (8KB) 5 32b DRAM Read 640 Area (m2) 36 67 137 1360 4184 282 3495 1640 7700 N/A N/A Cost of Operations 1 10 100 1000 Energy numbers are from Mark Horowitz “Computing’s Energy Problem (and what we can do about it)”, ISSCC 2014 Area numbers are from synthesized result using Design Compiler under TSMC 45nm tech node. FP units used DesignWare Library. Relative Energy Cost Relative Area Cost 10000 1 10 100 1000
- 50. The Importance of Staying Local LPDDR DRAM GB On-Chip SRAM MB Local SRAM KB 640pJ/word 50pJ/word 5pJ/word
- 51. PE R PE R PE R PE R PE R PE R PE R PE R PE R Global Controller Global Buffer MAGNet System DRAM Processing Element (PE) X Wb Ab X Wb Ab X Wb Ab VectorSize Weight Collector Accumulation Collector + + + + + Vector MAC unit [Venkatesan et al., ICCAD 2019] Magnet Configurable using synthesizable SystemC, HW generated using HLS tools
- 52. Energy-efficient DL Inference accelerator Transformers, VS-Quant INT4, TSMC 5nm • Efficient architecture • Used MAGNet [Venkatesan et al., ICCAD 2019] to design a low- precision DL inference accelerator for Transformers • Multi-level dataflow to improve data reuse and energy efficiency • Low-precision data format: VS-Quant INT4 • Hardware-software techniques to tolerate quantization error • Enable low cost multiply-accumulate (MAC) operations • Reduce storage and data movement • Special function units • TSMC 5nm • 1024 4-bit MACs/cycle (512 8-bit) • 0.153 mm2 chip • Voltage range: 0.46V – 1.05V • Frequency range: 152 MHz – 1760 MHz • 95.6 TOPS/W with 50%-dense 4-bit input matrices with VSQ enabled at 0.46V • 0.8% energy overhead from VSQ support with 50%- dense inputs at 0.67V [Keller, Venkatesan, et al., “A 95.6-TOPS/W Deep Learning Inference Accelerator with Per-Vector Scaled 4-bit Quantization in 5nm”, JSSC 2023]
- 53. Program Mapping Directives Mapper & Runtime GPU Data & Task Placement Synthesis Custom Compute Blocks (Instructions or Clients) (someday as ‘chiplets’) SMs Configurable Memory Efficient NoC
- 54. Conclusion
- 55. Conclusion • Deep Learning was enabled by hardware and its progress is limited by hardware • 1000x in last 10 years • Number representation, complex ops, sparsity • Logarithmic numbers • Lowest worst-case error for a given number of bits • Can ‘factor out’ hard parts of an add • Optimum clipping • Minimize MSE by trading quantization noise for clipping noise • VS-Quant • Separate scale factor for each small vector – 16 to 64 scalars • Accelerators – Testbeds for GPU ‘cores’ • Test chip validates concepts and measures efficiency • 95.6 TOPS/W on BERT with negligible accuracy loss 3.94 6.84 21.20 125.00 261.00 1248.00 0.00 200.00 400.00 600.00 800.00 1000.00 1200.00 1400.00 4/1/12 8/14/13 12/27/14 5/10/16 9/22/17 2/4/19 6/18/20 10/31/21 Int 8 TOPS Single-Chip Inference Performance - 317X in 8 years S EI EF −𝛼 +𝛼 clip clip