Hive, Impala, and Spark, Oh My: SQL-on-Hadoop in Cloudera 5.5
74 likes23,222 views

The document discusses SQL-on-Hadoop technologies within Cloudera 5.5, highlighting the evolution from MapReduce to tools like Apache Hive, Impala, and Spark. It covers the strengths and use cases of these technologies, their performance benchmarks, and the importance of choosing the right SQL engine for specific requirements. Additionally, it emphasizes the benefits of open-source standards to avoid vendor lock-in and enhance ecosystem compatibility.





















Hive, Impala, and Spark, Oh My: SQL-on-Hadoop in Cloudera 5.5
- 1. 1© Cloudera, Inc. All rights reserved. Hive, Impala, and Spark, Oh My: SQL-on-Hadoop in Cloudera 5.5 Justin Erickson | Director of Product Management | Cloudera
- 2. 2© Cloudera, Inc. All rights reserved. Agenda • History of SQL-on-Hadoop technologies • Picking the right tool for the job • What’s new with Cloudera 5.5 • Real-world use cases • Future of SQL-on-Hadoop
- 3. 3© Cloudera, Inc. All rights reserved. MapReduce: The Early Years The original processing engine for Hadoop • Process any type of data in any format • Scale infinitely for multiple, large jobs • Pioneer of bringing compute to data But… • Difficult to program • Slow processing • Limited expressivity PROCESS STORE BATCH MapReduce FILESYSTEM HDFS
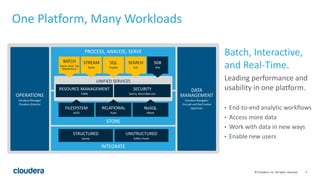
- 4. 4© Cloudera, Inc. All rights reserved. One Platform, Many Workloads Batch, Interactive, and Real-Time. Leading performance and usability in one platform. • End-to-end analytic workflows • Access more data • Work with data in new ways • Enable new users OPERATIONS Cloudera Manager Cloudera Director DATA MANAGEMENT Cloudera Navigator Encrypt and KeyTrustee Optimizer STRUCTURED Sqoop UNSTRUCTURED Kafka, Flume PROCESS, ANALYZE, SERVE UNIFIED SERVICES RESOURCE MANAGEMENT YARN SECURITY Sentry, RecordService FILESYSTEM HDFS RELATIONAL Kudu NoSQL HBase STORE INTEGRATE BATCH Spark, Hive, Pig MapReduce STREAM Spark SQL Impala SEARCH Solr SDK Kite
- 5. 5© Cloudera, Inc. All rights reserved. The Need for SQL for Batch Processing Apache Hive • Eases development on MapReduce with familiar SQL • Built for long-running ETL, data preparation, and batch processing • Shared data structures across Hadoop tools STRUCTURED Sqoop UNSTRUCTURED Kafka, Flume PROCESS, ANALYZE, SERVE UNIFIED SERVICES RESOURCE MANAGEMENT YARN SECURITY Sentry, RecordService FILESYSTEM HDFS RELATIONAL Kudu NoSQL HBase STORE INTEGRATE BATCH Spark, Hive, Pig MapReduce STREAM Spark SQL Impala SEARCH Solr SDK Kite
- 6. 6© Cloudera, Inc. All rights reserved. The Need for Interactive SQL for BI Apache Impala (incubating) • Low latency for interactive performance • Built for multi-user workloads • Compatible with SQL and leading BI partner tools STRUCTURED Sqoop UNSTRUCTURED Kafka, Flume PROCESS, ANALYZE, SERVE UNIFIED SERVICES RESOURCE MANAGEMENT YARN SECURITY Sentry, RecordService FILESYSTEM HDFS RELATIONAL Kudu NoSQL HBase STORE INTEGRATE BATCH Spark, Hive, Pig MapReduce STREAM Spark SQL Impala SEARCH Solr SDK Kite
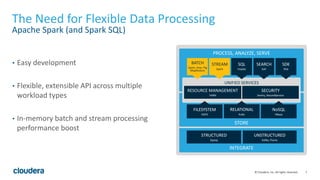
- 7. 7© Cloudera, Inc. All rights reserved. The Need for Flexible Data Processing Apache Spark (and Spark SQL) • Easy development • Flexible, extensible API across multiple workload types • In-memory batch and stream processing performance boost STRUCTURED Sqoop UNSTRUCTURED Kafka, Flume PROCESS, ANALYZE, SERVE UNIFIED SERVICES RESOURCE MANAGEMENT YARN SECURITY Sentry, RecordService FILESYSTEM HDFS RELATIONAL Kudu NoSQL HBase STORE INTEGRATE BATCH Spark, Hive, Pig MapReduce STREAM Spark SQL Impala SEARCH Solr SDK Kite
- 8. 8© Cloudera, Inc. All rights reserved. Focus on Open Source Standards Open source does not guarantee a future-proof investment Long-Term Architecture Only open standards get continuing, long-term investment from across the ecosystem. Avoidance of Lock-in Open standards have multi-vendor support, giving customers choices and preventing lock-in. Ecosystem Compatibility Open standards attract more third- party connectors/certifications due to broad adoption.
- 9. 9© Cloudera, Inc. All rights reserved. Choosing the Right SQL Engine Know Your Audience, Know Your Use Case Batch Processing BI and SQL Analytics Procedural Development SQLOR Impala
- 10. 10© Cloudera, Inc. All rights reserved. SQL-on-Hadoop in Cloudera 5.5 Apache Hive Apache Impala (incubating) Apache Spark SQL Audience ETL Developers Business Analysts Data Engineers & Data Scientists Strengths • Built for very long-running ETL, data preparation, or batch processing • Supports custom file formats • Handles massive ETL sorts with joins • Scales to high-concurrency • Supports high-performance interactive SQL • Compatible with BI tools & skills • Hadoop integration & usability • Easily embed SQL into Java, Scala, or Python applications • Simple language for common operations • Seamlessly mix SQL and Spark code within a single application New Features • Hive in the cloud (S3) • Hive-on-Spark beta • Governance & Lineage • Nested data types • Column-level security • Integration with Kudu (beta) • Support for Spark SQL & DataFrames • Hive integration • Automatic performance optimizations
- 11. 11© Cloudera, Inc. All rights reserved. SQL-on-Hadoop Benchmark Impala, Spark SQL, Hive-on-Tez Versions: • Impala 2.3 • Hive 2.0 on Tez 0.5.2 (aka “Stinger”) • Spark SQL 1.5 with Tungsten • Benchmark Details • Based on industry standards (TPC) • Repeatable • Methodical testing with multiple runs on same hardware • Help competing software do well • Run on optimal file formats for each • Tune query engines appropriately
- 12. 12© Cloudera, Inc. All rights reserved. Impala Multi-User Performance Over 7x Faster 0 50 100 150 200 250 Time(inSeconds) SingleUser,4 10Users,12.8 SingleUser,32 10Users,97 SingleUser,59 10Users,210 7.2x 7.6x 13.4x 16.4x Single User vs 10 User Response Time/Impala Times Faster (Lower Bars = Better) Impala Spark SQL (with Tungsten) Hive-on-Tez
- 13. 13© Cloudera, Inc. All rights reserved. Impala Enables Nearly 7x Throughput 2045 302 136.0 0 500 1000 1500 2000 2500 QueriesperHour Query Throughput/Impala Throughput Times Faster (Higher Bars = Better) 6.8x 15x Impala Hive-on-TezSpark SQL (with Tungsten)
- 14. 14© Cloudera, Inc. All rights reserved. Performance Benchmark Takeaways • Impala unlocks BI usage directly on Hadoop • Meets BI low-latency and multi-user requirements • Advantage expands for single-user vs just 10 users • Hive is designed (and still great) for batch processing • Most Impala customers use Hive for data preparation • Hive is the most commonly used ETL framework • Spark SQL enables easier Spark application development • Enables mixed procedural Spark (Java/Scala) and SQL job development • Mid-term trends will further favor Impala’s design approach for latency and concurrency • More data sets move to memory (HDFS caching, in-memory joins, Intel joint roadmap) • CPU efficiency will increase in importance • Native code enables easy optimizations for CPU instruction sets • Intel joint roadmap support these opportunities
- 15. 15© Cloudera, Inc. All rights reserved. Use Cases
- 16. 16© Cloudera, Inc. All rights reserved. PROBLEM SOLUTION Needed to efficiently collect, process, and analyze data from growing hospital network • EDW couldn’t meet scale and unstructured data demands • Processing too slow for actionable decisions • Limited, time consuming supply chain matching Integrated 1000s of hospital systems through unified enterprise data hub • Ingest and process 45% more spend data • Faster analytics on $41B through end-user healthcare spend dashboard • Unprecedented matching of 98% of supply chain data • Better TCO through unification and licensing costs for new opportunities
- 17. 17© Cloudera, Inc. All rights reserved. PROBLEM SOLUTION Clients had limited insights to thousands of marketing campaigns across channels • Clients want real-time campaign updates with 3-sec SLA • Existing system couldn’t meet scaling or data type demands • Limited self-service BI Built next-generation digital marketing platform for 360-degree customer view • Improved query performance from minutes to seconds to meet SLAs • Enhanced modeling with combined online and offline data • Real-time optimizations through interactive, self-service access
- 18. 18© Cloudera, Inc. All rights reserved. PROBLEM SOLUTION Couldn’t support data integration across 20+ brands • Existing systems couldn’t scale for data consolidation • Siloed access based on workload • No real-time data ingestion or access Brought all data directly to the business to lower costs and open up new use cases fast • Reduced TCO by 50% by consolidating over 1PB of data, adding 200M rows daily • Enabled real-time vs hourly updates on ad performance • Optimized inventory management through data matching and consolidation
- 19. 19© Cloudera, Inc. All rights reserved. Impala Roadmap 2H 2015 1H 2016 2016 • SQL Support & Usability • Nested structures • Kudu updates (beta) • Management & Security • Record reader service (beta) • Finer-grained security (Sentry) • Integration • Isilon support • Python interface (Ibis) • Performance & Scale • Improved predictability under concurrency • Performance & Scale • Continued scalability and concurrency • Initial perf/scale improvements • Management & Security • Improved admission control • Resource utilization and showback • SQL Support & Usability • Dynamic partitioning • Improved timestamp compatibility • Performance & Scale • >20x performance • Multi-threaded joins/aggregations • Continued scale work • Management & Security • Improved YARN integration • Automated metadata • Integration • S3 support • SQL Support & Usability • Nested types with Avro • Date type • Added SQL extensions
- 20. 20© Cloudera, Inc. All rights reserved. Download Cloudera 5.5 cloudera.com/downloads
- 21. 21© Cloudera, Inc. All rights reserved. Try It With Cloudera Live cloudera.com/live Featuring tutorials on:
- 22. 22© Cloudera, Inc. All rights reserved. Cloudera Enterprise Making Hadoop Fast, Easy, and Secure A new kind of data platform: • One place for unlimited data • Unified, multi-framework data access Cloudera makes it: • Fast for business • Easy to manage • Secure without compromise OPERATIONS DATA MANAGEMENT STRUCTURED UNSTRUCTURED PROCESS, ANALYZE, SERVE UNIFIED SERVICES RESOURCE MANAGEMENT SECURITY FILESYSTEM RELATIONAL NoSQL STORE INTEGRATE BATCH STREAM SQL SEARCH SDK
- 23. 23© Cloudera, Inc. All rights reserved. Thank You!
Editor's Notes
- #4: The original scalable, general, processing engine of Hadoop ecosystem - Useful across diverse problem domains - Fueled initial ecosystem explosion
- #5: What’s really significant about this architecture is how it unifies diverse access to common data. In traditional approaches, you’d have separate systems to collect, store, process, explore, model, and serve data. Different teams would use different systems for each workload, and users whose roles span multiple systems would have to use several of them to achieve their objectives. With Cloudera’s enterprise data hub: You can perform end-to-end data workflows in a single system, dramatically lowering time to value. Each workload can access unlimited data, thanks to the underlying data platform, enhancing the value of each workload. Power users can now access their data in new ways: SQL, search, machine learning, programming, etc. At the same time, new users are enabled by these diverse workloads to interact with data. Cloudera Enterprise provides comprehensive support for batch, interactive, and real-time workloads: Batch Data integration with Apache Sqoop Data processing with MapReduce, Apache Hive, Apache Pig Memory-centric processing with Apache Spark Interactive Analytic SQL with Impala Search with Apache Solr Machine Learning with Apache Spark Real-Time Data integration with Apache Kafka, Apache Flume Stream processing with Apache Spark Data serving with Apache HBase Shared resource management ensures that each workload is handled appropriately and abides by IT policy. What’s more, 3rd party tools, such as SAS or Informatica can run as native workloads inside Cloudera’s enterprise data hub.
- #10: Our goal is to provide the best tools for a particular job * Hive is the best for batch, and of course we want to make that experience better. * Impala is purpose built for interactive BI on Hadoop. Latency, concurrency, vendor ecosystem, and partner certification. * Spark SQL in the future will enable Spark developers to inline SQL as steps within their Spark application
- #17: Link to account record in SFDC (valid for Cloudera employees only): https://na6.salesforce.com/0018000000zmcRQ?srPos=0&srKp=001 Premier’s enterprise data hub improves healthcare efficiency, analyzing $41 billion in spend. Background: Premier is an alliance whose mission is to improve the health of communities. By collecting, integrating, and analyzing clinical, financial, and operational data from the 3,000 U.S. hospitals and 110,000 other healthcare providers in its alliance, Premier’s database is one of the deepest and most comprehensive in the industry. The company has insight into $41 billion in purchases, and one out of every three health system discharges nationwide. Challenge: Premier must find the most efficient way to collect, cleanse, and load data from thousands of different data sets into its solution, which provides a six to nine month rolling window of history to healthcare providers. Providers use this information for clinical quality and cost analysis, and to guide their medical supply chain management decisions. In Premier’s incumbent environment, the multi-step process to ingest and make data available for analysis had grown complex, expensive, time-consuming, and wouldn’t scale. As the number of members in Premier’s alliance continued to grow, both the types and volumes of data collected started to balloon, leading to two primary data management challenges for Premier: data ingestion and supply chain data matching. Solution: In December 2013, Premier deployed a multi-tenant enterprise data hub (EDH) on Cloudera in production, supporting four use cases: First, clinical data integration: Premier ingests clinical data into the EDH, and through Impala, makes it available to healthcare practitioners for analysis and visualization via business intelligence tools including IBM Cognos, MicroStrategy, and Tableau. With the MapReduce data processing framework, Premier can automatically eliminate data that hasn’t changed from incoming data sets -- it can just process the subset of data that is new or different. The second use case is data transformation, processing and cleansing: Premier is migrating key ETL processes from traditional tools to Cloudera to simplify the big data environment, streamline data processing, and reduce costs. Cloudera processes all incoming data and then feeds two operational data stores in addition to Premier’s IBM Netezza data warehouse appliance. The third use case is supply chain data matching: Using MapReduce, Cloudera Search, and Cloudera Impala, Premier can index data in batch, process incoming data sets and match them against the existing index. The results are then made available for querying through Hive and Impala. The fourth use case is interactive, analytical member spend application: Premier combined clinical, financial, and operational data into its centralized EDH to empower an interactive application that analyzes the $41 billion in spend across all of its member organizations. Results: Premier’s EDH reduces the total amount of data that needs to be processed with each data set provided by hospitals, and total processing time has been significantly reduced -- meaning Premier can deliver new, fresh, and comprehensive data and analytics to healthcare providers faster than before. And because Hadoop can handle both structured and unstructured data, healthcare providers don’t need to manually enter data that isn’t captured electronically, such as information about images or handwritten nurses’ notes. Raw data in all formats and from numerous sources can be quickly loaded into the system. Eliminating manual data entry also reduces data duplication and keying errors that would otherwise result. With Premier’s new solution for supply chain data matching, Premier can match 98% of datasets, which was unprecedented. And its member spend application leveraging Cloudera Search for predictive analytics has increased spend categorization across all members from 49.8% to 72%. This enables members to perform market share calculations, spend trending, and identify savings opportunities. Internal teams are also finding other interesting use cases to take advantage of the processing speed, efficiencies, and analytic flexibility offered by the EDH. For example, Premier is starting to compare product masters with supplies. This use case is similar to the supply chain data matching operation. Premier will be able to, for example, compare cardiologists to see which ones are performing better, and identify whether specific products lead to higher quality results. Analysts can then drill down to evaluate those products, when they’re being purchased, and at what price, and under what contract. Because Premier’s system has visibility into thousands of healthcare providers’ systems and operations, Premier can ultimately make data driven recommendations to help healthcare providers secure better products at a lower cost.
- #23: In response, many organizations have turned to a new architecture – an enterprise data hub – to complement and extend existing investments. An enterprise data hub can store unlimited data, cost-effectively and reliably, for as long as you need, and lets users access that data in a variety of ways. Data can be collected, stored, processed, explored, modeled, and served in one unified platform. It’s connected to the systems you already rely on. Cloudera’s enterprise data hub, powered by Apache Hadoop, the popular open source distributed data platform, is differentiated in several crucial areas. We provide: Leading query performance. The enterprise management and governance that you require of all of your mission-critical infrastructure. Comprehensive, transparent, compliance-ready security at the core. An open source platform that is also built of open standards – projects that are supported by multiple vendors to ensure sustainability, portability, and compatibility. Our platform runs in your choice of environment, whether on-premises or in the cloud. === Cheat Sheet version: Our enterprise data hub is: One place for unlimited data Accessible to anyone Connected to the systems you already depend on Secure, governed, managed & compliant Built on open source and open standards Deployed however you want Coupled with the support and enablement you need to succeed. Important Note: Our EDH emphasizes “unified analytics” over “unified data”: It’s not practical or probable that customers will actually unify all their data. Much of it lives in the cloud or on storage (e.g. Isilon), in remote datacenters, is of uncertain value vs. cost of moving it to a hub, or security mandates preclude collocation. We enable customers to gather unlimited data, while bringing diverse processing and analytics to that data.