HKOSCon18 - Chetan Khatri - Scaling TB's of Data with Apache Spark and Scala DSL at Production

This document summarizes a presentation about scaling terabytes of data with Apache Spark and Scala. The key points are: 1) The presenter discusses how to use Apache Spark and Scala to process large scale data in a distributed manner across clusters. Spark operations like RDDs, DataFrames and Datasets are covered. 2) A case study is presented about reengineering a data processing platform for a retail business to improve performance. Changes included parallelizing jobs, tuning Spark hyperparameters, and building a fast data architecture using Spark, Kafka and data lakes. 3) Performance was improved through techniques like dynamic resource allocation in YARN, reducing memory and cores per executor to better utilize cluster resources, and processing data

















![Why Dataset ?
● Strongly Typing
● Ability to use powerful lambda functions.
● Spark SQL’s optimized execution engine (catalyst, tungsten)
● Can be constructed from JVM objects & manipulated using Functional
transformations (map, filter, flatMap etc)
● A DataFrame is a Dataset organized into named columns
● DataFrame is simply a type alias of Dataset[Row]](https://image.slidesharecdn.com/hkoscon18-chetankhatri-180617050527/85/HKOSCon18-Chetan-Khatri-Scaling-TB-s-of-Data-with-Apache-Spark-and-Scala-DSL-at-Production-18-320.jpg)

![Unification of APIs in Apache Spark 2.0
DataFrame
Dataset
Untyped API
Typed API
Dataset
(2016)
DataFrame = Dataset [Row]
Alias
Dataset [T]](https://image.slidesharecdn.com/hkoscon18-chetankhatri-180617050527/85/HKOSCon18-Chetan-Khatri-Scaling-TB-s-of-Data-with-Apache-Spark-and-Scala-DSL-at-Production-20-320.jpg)




![Dataset API in Spark 2.x
val employeesDF = spark.read.json("employees.json")
// Convert data to domain objects.
case class Employee(name: String, age: Int)
val employeesDS: Dataset[Employee] = employeesDF.as[Employee]
val filterDS = employeesDS.filter(p => p.age > 3)
Type-safe: operate on domain
objects with compiled lambda
functions.](https://image.slidesharecdn.com/hkoscon18-chetankhatri-180617050527/85/HKOSCon18-Chetan-Khatri-Scaling-TB-s-of-Data-with-Apache-Spark-and-Scala-DSL-at-Production-25-320.jpg)






















































More Related Content
What's hot (20)
Similar to HKOSCon18 - Chetan Khatri - Scaling TB's of Data with Apache Spark and Scala DSL at Production (20)


















More from Chetan Khatri (20)




















Recently uploaded (20)




















HKOSCon18 - Chetan Khatri - Scaling TB's of Data with Apache Spark and Scala DSL at Production
- 1. Scaling TB’s of data with Apache Spark and Scala DSL at Production Chetan Khatri, India HKOSCon, 2018 @khatri_chetan Hong Kong Open Source Conference 2018 Charles K Kao Auditorium and Conference Hall 4-7, Hong Kong Science Park, Shatin. Hong Kong.
- 2.  Chetan Khatri Lead - Data Science, Accionlabs Inc. Open Source Contributor: Apache Spark, Apache HBase, Elixir Lang. Alumni - University of Kachchh. HKOSCon 2018, Hong Kong Science Park, Shatin. Hong Kong
- 3. WHO AM I ? Lead - Data Science, Technology Evangelist @ Accion labs India Pvt. Ltd. Committer @ Apache Spark, Apache HBase, Elixir Lang. Co-Authored University Curriculum @ University of Kachchh. Data Engineering @: Nazara Games, Eccella Corporation. M.Sc. - Computer Science from University of Kachchh.
- 4. Agenda ● Apache Spark and Scala ● Resilient Distributed Datasets (RDDs) ● DataFrames and Datasets ● Spark Operations ● Data Platform Components ● Re-engineering Data processing platform ● Rethink - Fast Data Architecture ● Parallelism & Concurrency at Spark
- 5. What is Apache Spark ? Apache Spark is a fast and general-purpose cluster computing system / Unified Engine for massive data processing. It provides high level API for Scala, Java, Python and R and optimized engine that supports general execution graphs. Structured Data / SQL - Spark SQL Graph Processing - GraphX Machine Learning - MLlib Streaming - Spark Streaming, Structured Streaming
- 6. What is Scala ? ● Scala is a modern multi-paradigm programming language designed to express common programming patterns in a concise, elegant, and type-safe way. ● Scala is object-oriented ● Scala is functional ● Strongly typed, Type Inference ● Higher Order Functions ● Lazy Computation
- 7. Data Structures in Apache Spark ? ● RDD ● DataFrame ● DataSet
- 8. What are RDDs ?
- 9. 1. Distributed Data Abstraction RDD RDD RDD RDD Logical Model Across Distributed Storage on Cluster HDFS, S3
- 10. 2. Resilient & Immutable RDD RDD RDD T T RDD -> T -> RDD -> T -> RDD T = Transformation
- 11. 3. Compile-time Type Safe / Strongly type inference Integer RDD String or Text RDD Double or Binary RDD
- 12. 4. Lazy evaluation RDD RDD RDD T T RDD RDD RDD T A RDD - T - RDD - T - RDD - T - RDD - A - RDD T = Transformation A = Action
- 14. Essential Spark Operations TRANSFORMATIONSACTIONS General Math / Statistical Set Theory / Relational Data Structure / I/O map gilter flatMap mapPartitions mapPartitionsWithIndex groupBy sortBy sample randomSplit union intersection subtract distinct cartesian zip keyBy zipWithIndex zipWithUniqueID zipPartitions coalesce repartition repartitionAndSortWithinPartitions pipe reduce collect aggregate fold first take forEach top treeAggregate treeReduce forEachPartition collectAsMap count takeSample max min sum histogram mean variance stdev sampleVariance countApprox countApproxDistinct takeOrdered saveAsTextFile saveAsSequenceFile saveAsObjectFile saveAsHadoopDataset saveAsHadoopFile saveAsNewAPIHadoopDataset saveAsNewAPIHadoopFile
- 15. When to use RDDs ? ● You care about control of dataset and knows how data looks like, you care about low level API. ● Don’t care about lot’s of lambda functions than DSL. ● Don’t care about Schema or Structure of Data. ● Don’t care about optimization, performance & inefficiencies! ● Very slow for non-JVM languages like Python, R. ● Don’t care about Inadvertent inefficiencies.
- 16. Inadvertent inefficiencies in RDDs parsedRDD.filter { case (project, sprint, numStories) => project == "finance" }. map { case (_, sprint, numStories) => (sprint, numStories) }. reduceByKey(_ + _). filter { case (sprint, _) => !isSpecialSprint(sprint) }. take(100).foreach { case (project, stories) => println(s"project: $stories") }
- 18. Why Dataset ? ● Strongly Typing ● Ability to use powerful lambda functions. ● Spark SQL’s optimized execution engine (catalyst, tungsten) ● Can be constructed from JVM objects & manipulated using Functional transformations (map, filter, flatMap etc) ● A DataFrame is a Dataset organized into named columns ● DataFrame is simply a type alias of Dataset[Row]
- 19. Structured APIs in Apache Spark SQL DataFrames Datasets Syntax Errors Runtime Compile Time Compile Time Analysis Errors Runtime Runtime Compile Time Analysis errors are caught before a job runs on cluster
- 20. Unification of APIs in Apache Spark 2.0 DataFrame Dataset Untyped API Typed API Dataset (2016) DataFrame = Dataset [Row] Alias Dataset [T]
- 21. DataFrame API Code // convert RDD -> DF with column names val parsedDF = parsedRDD.toDF("project", "sprint", "numStories") //filter, groupBy, sum, and then agg() parsedDF.filter($"project" === "finance"). groupBy($"sprint"). agg(sum($"numStories").as("count")). limit(100). show(100) project sprint numStories finance 3 20 finance 4 22
- 22. DataFrame -> SQL View -> SQL Query parsedDF.createOrReplaceTempView("audits") val results = spark.sql( """SELECT sprint, sum(numStories) AS count FROM audits WHERE project = 'finance' GROUP BY sprint LIMIT 100""") results.show(100) project sprint numStories finance 3 20 finance 4 22
- 23. Why Structure APIs ? // DataFrame data.groupBy("dept").avg("age") // SQL select dept, avg(age) from data group by 1 // RDD data.map { case (dept, age) => dept -> (age, 1) } .reduceByKey { case ((a1, c1), (a2, c2)) => (a1 + a2, c1 + c2) } .map { case (dept, (age, c)) => dept -> age / c }
- 24. Catalyst in Spark SQL AST DataFrame Datasets Unresolved Logical Plan Logical Plan Optimized Logical Plan Physical Plans CostModel Selected Physical Plan RDD
- 25. Dataset API in Spark 2.x val employeesDF = spark.read.json("employees.json") // Convert data to domain objects. case class Employee(name: String, age: Int) val employeesDS: Dataset[Employee] = employeesDF.as[Employee] val filterDS = employeesDS.filter(p => p.age > 3) Type-safe: operate on domain objects with compiled lambda functions.
- 26. Example: DataFrame Optimization employees.join(events, employees("id") === events("eid")) .filter(events("date") > "2015-01-01") events file employees table join filter Logical Plan scan (employees) filter Scan (events) join Physical Plan Optimized scan (events) Optimized scan (employees) join Physical Plan With Predicate Pushdown and Column Pruning
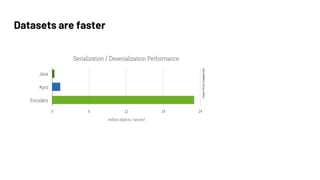
- 27. DataFrames are Faster than RDDs Source: Databricks
- 28. Datasets takes less Memory than RDDs Source: Databricks
- 30. Case Study
- 31. Components of your Data Platform Data Warehouse Fast Queries Transactional Reliability Data Lake Low Cost Massive Scale Streaming Message Bus (e.g. Kinesis, Apache Kafka) Low Latency
- 32. How to make them talk? DATA WAREHOUSE Fast Queries Transactional Reliability DATA LAKE Low Cost Massive Scale STREAMING MESSAGE BUS (e.g. Kinesis, Apache Kafka) Low Latency Complex, Slow, ETL Process
- 33. Changing the Game with a Re-engineering Data Processing Platform: Retail Business Challenges ● Weekly Data refresh, Daily Data refresh batch Spark / Hadoop job execution failures with unutilized Spark Cluster. ● Linear / sequential execution mode with broken data pipelines. ● Joining ~17 billion transactional records with skewed data nature. ● Data deduplication - outlet, item at retail. ● Scalability of massive data: ● ~4.6 Billion events on every weekly data refresh. ● Processing historical data: one time bulk load ~30 TB of data / ~17 billion transactional records. Business: explain the who, what, when, where, why and how of retailing.
- 34. Solution : Retail Business ● 5x performance improvements by re-engineering entire data lake to analytical engine pipeline’s. ● Proposed highly concurrent, elastic, non-blocking, asynchronous architecture to save customer’s ~22 hours runtime (~8 hours from 30 hours) for 4.6 Billion events. ● 10x performance improvements on historical load by under the hood algorithms optimization on 17 Billion events (Benchmarks ~1 hour execution time only) ● Master Data Management (MDM) - Deduplication and fuzzy logic matching on retails data(Item, Outlet) improved elastic performance.
- 36. Event Queuing Kafka Batch Transformations Reporting Tool (Dashboard) Processed DW - Ad hoc Analysis / 1st level aggregation Data Ingestion Pipeline RestfulAPI’s Summarized DB - KPI Reporting
- 37. Rethink - Fast Data Architectures UNIFIED fast data processing engine that provides: The SCALE of data lake The RELIABILITY & PERFORMANCE of data warehouse The LOW LATENCY of streaming
- 38. #1: Sequential job execution to parallel job execution Outlet Item Manufacturer Transactions
- 39. #1: Sequential job execution to parallel job execution (...) Outlets Items organization Transactions Files Outlets-by-file Transaction-by-day
- 40. #2: Spark / Hive Data processing: Hyper parameters tuning Dynamic resource allocation and Yarn external shuffle service has been enabled at YARN resource manager to allocate resources dynamically to other jobs on yarn. Overallocation of resources for small jobs: Those spark jobs were taking more resources but they were less DISK volume intensive, Hyper-parameters - executors, cores, memory on executor/ driver has been reduced to allow other pending jobs to execute and not to block entire cluster. i.e Job will run little slowly but utilize entire cluster with non-blocking approach for other jobs.
- 41. #2: Spark / Hive Data processing: Hyper parameters tuning: Example $SPARK_HOME/bin/spark-submit --class com.talk.chetan.SparkHistoricalJobSample --master yarn --deploy-mode cluster --driver-memory 6g --executors 12 --conf spark.shuffle.service.enabled=true --conf spark.dynamicAllocation.enabled=true executor-memory 30g --executor-cores 10 $SPARK_JAR_JOB_PATH For number tasks spark is executing on cluster Number of Parallel tasks = number of executors * cores Ex. number of executors = 8, cores = 8 := 64 Parallel tasks
- 42. #2: Spark / Hive Data processing: Hyper parameters tuning (...) Our optimization approaches: 1) Reduce memory / cores & increase executors: This can allow us to better utilize all the resources on the cluster without locking others out. 2) Reduce executors and use the same memory / cores: This will run slower for that run, but will allow others to use the cluster box in parallel.
- 43. #3: Physical Data Split up techniques for Analytical Engine (Hive) Physical data split up: Spark map-reduce transformations generates small-small files on larger dataset at some extents which led to increase Disk I/O, Memory I/O, File I/O, Bandwidth I/O etc. Also Downstream Hive Queries, Spark Jobs get impacts on performance and sometime it also fails with disk quota exceeded, container lost etc exceptions. In accordance with business logic and optimized new data model design, physical data split up techniques such as Partitioning, Re-partitioning, Coalesce applied on dimensions of data model with highly optimized, tuned other spark internals techniques to reduce N numbers of files generation. Which made drastic performance change at slice and dice on measures. spark.sql.files.maxRecordsPerFile
- 44. #4: Not everything is Streaming at Data Lake ! (~>) Frequent batch mode If you are going beyond few min’s, you should not be doing streaming at all, you should just kick-off batch jobs very frequently. If you run something long enough for example, streaming job runs for 4 months, eventually you can see all possible problems network partition, hardware failures, GC, spike & traffic on appcache etc. All kinds of things ! Kicking off batch job and immediately scale to right size it needs to be. It does it’s work & goes away.
- 45. #5: Historical Data Processing: Aggregation of data on ~17 Billion records file_errors Join transaction_by_file outlets_by_file items_by_file Hive External table with parquet partitioned Redshift transactions_error 1 Failed: * Disk quota exceeded * Executor lost failure * container killed by YARN on exceeding memory limits ~27 TB of total historical data Hive transactions_error (Managed table, parquet format with non-partitioned data) Success approach: * Enable YARN external shuffle service * Enable Dynamic Resource Allocation * Tune hyper-parameters to utilize cluster * Apply business transformation here * create temp view * insert to hive managed table 2 Failed
- 46. ~1 TB of Output Data Shuffle All executors at entire cluster are utilized
- 47. Spark on Kubernetes: Scheduler spark-submit --deploy-mode cluster --class org.apache.spark.examples.SparkPi --master k8s://https://35.225.152.61:443 --conf spark.executor.instances=2 --conf spark.app.name=spark-pi --conf spark.kubernetes.driver.docker.image=kubespark/spark-driver:v2.2.0-kubernetes-0.5.0 --conf spark.kubernetes.executor.docker.image=kubespark/spark-executor:v2.2.0-kubernetes-0.5.0 --conf spark.kubernetes.container.image=erkkel/eric:spark local:///opt/spark/examples/jars/spark-examples_2.11-2.2.0-k8s-0.5.0.jar
- 48. Enabler ?
- 49. Questions ?
- 50. Thank you for your Time! @khatri_chetan https://github.com/chetkhatri