How Caching Improves Efficiency and Result Completeness for Querying Linked Data
0 likes599 views

That's the slides with which I presented my paper at the Linked Data on the Web workshop (LDOW) at WWW 2011, Hyderabad, India.

![Can we query the Web of Data
as of it were a single,
giant database?
SELECT DISTINCT ?i ?label
WHERE {
?prof rdf:type <http://res ... data/dbprofs#DBProfessor> ;
foaf:topic_interest ?i .
}
OPTIONAL {
}
?i rdfs:label ?label
FILTER( LANG(?label)="en" || LANG(?label)="")
ORDER BY ?label
?
Our approach: Link Traversal Based Query Execution
[ISWC'09]
Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 2](https://image.slidesharecdn.com/slidesldow2011caching-110328223711-phpapp02/85/How-Caching-Improves-Efficiency-and-Result-Completeness-for-Querying-Linked-Data-2-320.jpg)



































![Contributions
● Theoretical foundation (extension of the original definition)
● Reachability by a Dseed-initialized execution of a BGP query b
● Dseed-dependent solution for a BGP query b
● Reachability R(B) for a serial execution of B = b1 , … , bn
➔ Each solution for bcur is also R(B)-dependent solution for bcur
● Conceptual analysis of the impact of data caching
● Performance factor: p( bcur , B ) = c( bcur , [ ] ) – c( bcur , B )
● Serendipity factor: s( bcur , B ) = b( bcur , B ) – b( bcur , [ ] )
● Empirical verification of the potential impact
● Out of scope: Caching strategies (replacement, invalidation)
Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 40](https://image.slidesharecdn.com/slidesldow2011caching-110328223711-phpapp02/85/How-Caching-Improves-Efficiency-and-Result-Completeness-for-Querying-Linked-Data-40-320.jpg)








![Experiment – Single Query
Experiment Avg.1 number of Average1 Avg.1 query
Query Results Hit Rate Execution Time
(std.dev.) (std.dev.) (std.dev.)
4.983 0.576 30.036 s
no reuse
(11.658) (0.182) (46.708)
5.070 0.996 1.943 s
upper bound
(11.813) (0.017) (11.375)
1
Averaged over all 115 queries
● In the ideal case for Bupper= [ bcur , bcur ] :
● pupper( bcur , Bupper ) = c( bcur , [ ] ) – c( bcur , Bupper ) = c( bcur , [ ] )
● supper( bcur , Bupper ) = b( bcur , Bupper ) – b( bcur , [ ] ) = 0
Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 50](https://image.slidesharecdn.com/slidesldow2011caching-110328223711-phpapp02/85/How-Caching-Improves-Efficiency-and-Result-Completeness-for-Querying-Linked-Data-50-320.jpg)




![Experiment – Complete Sequence
Bgiven order= [ q1 , … , q38 ]
no reuse upper 0 given0,4 0,6 0,8
0,2 1 0 5 10 15 20 25 30 0 20 40 60 80
bound order s( q , Bgiven order ) = b( q39 , Bgiven order ) – b( q39 , [ ] )
39
ContactInfoPhillipe =9–1
(Query No. 36)
=8
UnsetPropsPhillipe
(Query No. 37)
2ndDegree1Phillipe
(Query No. 38)
2ndDegree2Phillipe
(Query No. 39)
IncomingPhillipe
(Query No. 40)
0 0,2 0,4 0,6 0,8 1 0 5 10 15 20 25 30 0 20 40 60 80
hit rate number of query results query execution time
(in seconds)
Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 56](https://image.slidesharecdn.com/slidesldow2011caching-110328223711-phpapp02/85/How-Caching-Improves-Efficiency-and-Result-Completeness-for-Querying-Linked-Data-56-320.jpg)
![Experiment – Complete Sequence
Bgiven order= [ q1 , … , q38 ]
no reuse upper 0 given0,4 0,6 0,8
0,2 1 0 5 10 15 20 25 30 0 20 40 60 80
p'( q , B
bound order given order
39
) = c'( q39 , [ ] ) – c'( q39 , Bgiven order )
ContactInfoPhillipe = 31.48 s – 68.64 s
(Query No. 36)
= – 37.16 s
UnsetPropsPhillipe
(Query No. 37)
2ndDegree1Phillipe
(Query No. 38)
2ndDegree2Phillipe
(Query No. 39)
IncomingPhillipe
(Query No. 40)
0 0,2 0,4 0,6 0,8 1 0 5 10 15 20 25 30 0 20 40 60 80
hit rate number of query results query execution time
(in seconds)
Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 57](https://image.slidesharecdn.com/slidesldow2011caching-110328223711-phpapp02/85/How-Caching-Improves-Efficiency-and-Result-Completeness-for-Querying-Linked-Data-57-320.jpg)

































More Related Content
What's hot (17)
Similar to How Caching Improves Efficiency and Result Completeness for Querying Linked Data (20)















More from Olaf Hartig (20)




















Recently uploaded (20)




















How Caching Improves Efficiency and Result Completeness for Querying Linked Data
- 1. How Caching Improves Efficiency and Result Completeness for Querying Linked Data Olaf Hartig http://olafhartig.de/foaf.rdf#olaf Database and Information Systems Research Group Humboldt-Universität zu Berlin
- 2. Can we query the Web of Data as of it were a single, giant database? SELECT DISTINCT ?i ?label WHERE { ?prof rdf:type <http://res ... data/dbprofs#DBProfessor> ; foaf:topic_interest ?i . } OPTIONAL { } ?i rdfs:label ?label FILTER( LANG(?label)="en" || LANG(?label)="") ORDER BY ?label ? Our approach: Link Traversal Based Query Execution [ISWC'09] Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 2
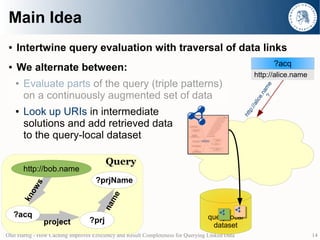
- 3. Main Idea ● Intertwine query evaluation with traversal of data links ● We alternate between: ● Evaluate parts of the query (triple patterns) on a continuously augmented set of data ● Look up URIs in intermediate solutions and add retrieved data to the query-local dataset query-local dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 3
- 4. Main Idea ● Intertwine query evaluation with traversal of data links ● We alternate between: ● Evaluate parts of the query (triple patterns) on a continuously augmented set of data ● Look up URIs in intermediate solutions and add retrieved data to the query-local dataset Query http://bob.name ?prjName s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 4
- 5. Main Idea ● Intertwine query evaluation with traversal of data links ● We alternate between: htt p:/ ? ● Evaluate parts of the query (triple patterns) /bo on a continuously augmented set of data b.n am Look up URIs in intermediate e ● solutions and add retrieved data to the query-local dataset Query http://bob.name ?prjName s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 5
- 6. Main Idea ● Intertwine query evaluation with traversal of data links ● We alternate between: htt p:/ ? ● Evaluate parts of the query (triple patterns) /bo on a continuously augmented set of data b.n am Look up URIs in intermediate e ● solutions and add retrieved data to the query-local dataset Query http://bob.name ?prjName s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 6
- 7. Main Idea ● Intertwine query evaluation with traversal of data links ● We alternate between: htt p:/ ? ● Evaluate parts of the query (triple patterns) /bo on a continuously augmented set of data b.n am Look up URIs in intermediate e ● solutions and add retrieved data to the query-local dataset Query http://bob.name ?prjName s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 7
- 8. Main Idea ● Intertwine query evaluation with traversal of data links ● We alternate between: htt p:/ ? ● Evaluate parts of the query (triple patterns) /bo on a continuously augmented set of data b.n am Look up URIs in intermediate e ● solutions and add retrieved data “Descriptor object” to the query-local dataset Query http://bob.name ?prjName s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 8
- 9. Main Idea ● Intertwine query evaluation with traversal of data links ● We alternate between: ● Evaluate parts of the query (triple patterns) on a continuously augmented set of data ● Look up URIs in intermediate solutions and add retrieved data to the query-local dataset Query http://bob.name ?prjName s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 9
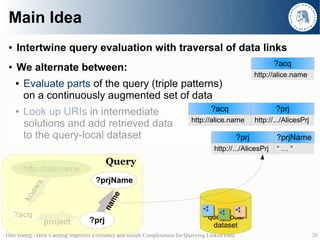
- 10. Main Idea ● Intertwine query evaluation with traversal of data links ● We alternate between: ● Evaluate parts of the query (triple patterns) on a continuously augmented set of data ● Look up URIs in intermediate solutions and add retrieved data to the query-local dataset http://bob.name Query kno ws http://bob.name http://alice.name ?prjName s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 10
- 11. Main Idea ● Intertwine query evaluation with traversal of data links ?acq ● We alternate between: http://alice.name ● Evaluate parts of the query (triple patterns) on a continuously augmented set of data ● Look up URIs in intermediate solutions and add retrieved data to the query-local dataset http://bob.name Query kno ws http://bob.name http://alice.name ?prjName s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 11
- 12. Main Idea ● Intertwine query evaluation with traversal of data links ?acq ● We alternate between: http://alice.name ● Evaluate parts of the query (triple patterns) ? me on a continuously augmented set of data a e.n a lic :// ● Look up URIs in intermediate p htt solutions and add retrieved data to the query-local dataset Query http://bob.name ?prjName s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 12
- 13. Main Idea ● Intertwine query evaluation with traversal of data links ?acq ● We alternate between: http://alice.name ● Evaluate parts of the query (triple patterns) ? me on a continuously augmented set of data a e.n a lic :// ● Look up URIs in intermediate p htt solutions and add retrieved data to the query-local dataset Query http://bob.name ?prjName s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 13
- 14. Main Idea ● Intertwine query evaluation with traversal of data links ?acq ● We alternate between: http://alice.name ● Evaluate parts of the query (triple patterns) ? me on a continuously augmented set of data a e.n a lic :// ● Look up URIs in intermediate p htt solutions and add retrieved data to the query-local dataset Query http://bob.name ?prjName s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 14
- 15. Main Idea ● Intertwine query evaluation with traversal of data links ?acq ● We alternate between: http://alice.name ● Evaluate parts of the query (triple patterns) on a continuously augmented set of data ● Look up URIs in intermediate solutions and add retrieved data to the query-local dataset Query http://bob.name ?prjName s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 15
- 16. Main Idea ● Intertwine query evaluation with traversal of data links ?acq ● We alternate between: http://alice.name ● Evaluate parts of the query (triple patterns) on a continuously augmented set of data ● Look up URIs in intermediate solutions and add retrieved data to the query-local dataset Query http://bob.name ?prjName s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 16
- 17. Main Idea ● Intertwine query evaluation with traversal of data links ?acq ● We alternate between: http://alice.name ● Evaluate parts of the query (triple patterns) on a continuously augmented set of data ● Look up URIs in intermediate solutions and add retrieved data to the query-local dataset http://alice.name Query pr o http://bob.name jec t ?prjName http://.../AlicesPrj s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 17
- 18. Main Idea ● Intertwine query evaluation with traversal of data links ?acq ● We alternate between: http://alice.name ● Evaluate parts of the query (triple patterns) on a continuously augmented set of data ● Look up URIs in intermediate ?acq ?prj http://alice.name http://.../AlicesPrj solutions and add retrieved data to the query-local dataset http://alice.name Query pr o http://bob.name jec t ?prjName http://.../AlicesPrj s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 18
- 19. Main Idea ● Intertwine query evaluation with traversal of data links ?acq ● We alternate between: http://alice.name ● Evaluate parts of the query (triple patterns) on a continuously augmented set of data ● Look up URIs in intermediate ?acq ?prj http://alice.name http://.../AlicesPrj solutions and add retrieved data to the query-local dataset Query http://bob.name ?prjName s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 19
- 20. Main Idea ● Intertwine query evaluation with traversal of data links ?acq ● We alternate between: http://alice.name ● Evaluate parts of the query (triple patterns) on a continuously augmented set of data ● Look up URIs in intermediate ?acq ?prj http://alice.name http://.../AlicesPrj solutions and add retrieved data to the query-local dataset ?prj ?prjName http://.../AlicesPrj “…“ Query http://bob.name ?prjName s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 20
- 21. Main Idea ● Intertwine query evaluation with traversal of data links ?acq ● We alternate between: http://alice.name ● Evaluate parts of the query (triple patterns) on a continuously augmented set of data ● Look up URIs in intermediate ?acq ?prj http://alice.name http://.../AlicesPrj solutions and add retrieved data to the query-local dataset ?prj ?prjName http://.../AlicesPrj “…“ Query ?acq ?prj ?prjName http://bob.name ?prjName http://alice.name http://.../AlicesPrj “…“ s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 21
- 22. Characteristics ● Link traversal based query execution: ● Evaluation on a continuously augmented dataset ● Discovery of potentially relevant data during execution ● Discovery driven by intermediate solutions ● Main advantage: ● No need to know all data sources in advance ● Limitations: ● Query has to contain a URI as a starting point ● Ignores data that is not reachable* by the query execution * formal definition in the paper Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 22
- 23. The Issue Query ?acq interest ?i s ow label kn http://bob.name ?iLabel query-local dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 23
- 24. The Issue Query ?acq interest ?i s ow label kn http://bob.name ?iLabel htt query-local p: //b ob dataset ? .nam e Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 24
- 25. The Issue Query ?acq interest http://bob.name ?i kno s ow w s label kn http://alice.name http://bob.name ?iLabel query-local dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 25
- 26. The Issue Query ?acq interest http://bob.name ?i kno s ow w s label kn http://alice.name http://bob.name ?iLabel query-local dataset ?acq ?i ?iLabel Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 26
- 27. The Issue Query ?acq interest ?i s ow label kn http://bob.name ?iLabel query-local dataset Query http://bob.name ?prjName s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 27
- 28. Reusing the Query-Local Dataset Query ?acq interest ?i s ow label kn http://bob.name ?iLabel query-local dataset Query http://bob.name ?prjName s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 28
- 29. Reusing the Query-Local Dataset Query ?acq interest ?i s ow label kn http://bob.name ?iLabel http://alice.name o ws Query kn http://bob.name http://bob.name ?prjName s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 29
- 30. Reusing the Query-Local Dataset Query ?acq interest ?i ?acq s ow http://alice.name label kn http://bob.name ?iLabel http://alice.name o ws Query kn http://bob.name http://bob.name ?prjName s ow me kn na ?acq query-local project ?prj dataset Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 30
- 31. Hypothesis Re-using the query-local dataset (a.k.a. data caching) may benefit query performance + result completeness Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 31
- 32. Contributions ● Systematic analysis of the impact of data caching ● Theoretical foundation* ● Conceptual analysis* ● Empirical evaluation of the potential impact * see paper ● Out of scope: Caching strategies (replacement, invalidation) Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 32
- 33. Experiment – Scenario ● Information about the distributed social network of FOAF profiles ● 5 types of queries ● Experiment Setup: ● 23 persons ● Sequential use ➔ 115 queries Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 33
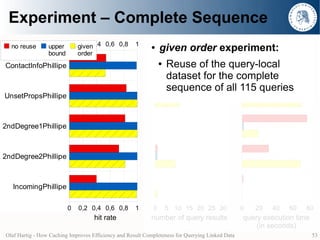
- 34. Experiment – Complete Sequence no reuse given 0 0,2 0,4 0,6 0,8 1 ● no reuse experiment: order ContactInfoPhillipe ● No data caching (Query No. 36) ● given order experiment UnsetPropsPhillipe ● Reuse of the query-local (Query No. 37) dataset for the complete sequence of all 115 queries 2ndDegree1Phillipe (Query No. 38) 2ndDegree2Phillipe (Query No. 39) ● Hit rate: IncomingPhillipe look-ups answered from cache (Query No. 40) all look-up requests 0 0,2 0,4 0,6 0,8 1 hit rate Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 34
- 35. Experiment – Complete Sequence no reuse given 0 0,2 0,4 0,6 0,8 1 ● no reuse experiment: order ContactInfoPhillipe ● No data caching (Query No. 36) ● given order experiment UnsetPropsPhillipe ● Reuse of the query-local (Query No. 37) dataset for the complete sequence of all 115 queries 2ndDegree1Phillipe (Query No. 38) 2ndDegree2Phillipe (Query No. 39) ● Hit rate: IncomingPhillipe look-ups answered from cache (Query No. 40) all look-up requests 0 0,2 0,4 0,6 0,8 1 hit rate Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 35
- 36. Experiment – Complete Sequence no reuse given 0 0,2 0,4 0,6 0,8 1 0 5 10 15 20 25 30 0 20 40 60 80 order ContactInfoPhillipe (Query No. 36) UnsetPropsPhillipe (Query No. 37) 2ndDegree1Phillipe (Query No. 38) 2ndDegree2Phillipe (Query No. 39) IncomingPhillipe (Query No. 40) 0 0,2 0,4 0,6 0,8 1 0 5 10 15 20 25 30 0 20 40 60 80 hit rate number of query results query execution time (in seconds) Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 36
- 37. Experiment – Complete Sequence no reuse given 0 0,2 0,4 0,6 0,8 1 0 5 10 15 20 25 30 0 20 40 60 80 order ContactInfoPhillipe (Query No. 36) UnsetPropsPhillipe (Query No. 37) 2ndDegree1Phillipe (Query No. 38) 2ndDegree2Phillipe (Query No. 39) IncomingPhillipe (Query No. 40) 0 0,2 0,4 0,6 0,8 1 0 5 10 15 20 25 30 0 20 40 60 80 hit rate number of query results query execution time (in seconds) Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 37
- 38. Summary ● Contributions: ● Theoretical foundation ● Conceptual analysis ● Empirical evaluation ● Main findings: ● Additional results possible (for semantically similar queries) ● Impact on performance may be positive but also negative ● Future work: ● Analysis of caching strategies in our context ● Main issue: invalidation Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 38
- 39. Backup Slides Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 39
- 40. Contributions ● Theoretical foundation (extension of the original definition) ● Reachability by a Dseed-initialized execution of a BGP query b ● Dseed-dependent solution for a BGP query b ● Reachability R(B) for a serial execution of B = b1 , … , bn ➔ Each solution for bcur is also R(B)-dependent solution for bcur ● Conceptual analysis of the impact of data caching ● Performance factor: p( bcur , B ) = c( bcur , [ ] ) – c( bcur , B ) ● Serendipity factor: s( bcur , B ) = b( bcur , B ) – b( bcur , [ ] ) ● Empirical verification of the potential impact ● Out of scope: Caching strategies (replacement, invalidation) Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 40
- 41. Query Template Contact SELECT * WHERE { <PERSON> foaf:knows ?p . OPTIONAL { ?p foaf:name ?name } OPTIONAL { ?p foaf:firstName ?firstName } OPTIONAL { ?p foaf:givenName ?givenName } OPTIONAL { ?p foaf:givenname ?givenname } OPTIONAL { ?p foaf:familyName ?familyName } OPTIONAL { ?p foaf:family_name ?family_name } OPTIONAL { ?p foaf:lastName ?lastName } OPTIONAL { ?p foaf:surname ?surname } OPTIONAL { ?p foaf:birthday ?birthday } OPTIONAL { ?p foaf:img ?img } OPTIONAL { ?p foaf:phone ?phone } OPTIONAL { ?p foaf:aimChatID ?aimChatID } OPTIONAL { ?p foaf:icqChatID ?icqChatID } OPTIONAL { ?p foaf:jabberID ?jabberID } OPTIONAL { ?p foaf:msnChatID ?msnChatID } OPTIONAL { ?p foaf:skypeID ?skypeID } OPTIONAL { ?p foaf:yahooChatID ?yahooChatID } } Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 41
- 42. Query Template UnsetProps SELECT DISTINCT ?result ?resultLabel WHERE { ?result rdfs:isDefinedBy <http://xmlns.com/foaf/0.1/> . ?result rdfs:domain foaf:Person . OPTIONAL { <PERSON> ?result ?var0 } FILTER ( !bound(?var0) ) <PERSON> foaf:knows ?var2 . ?var2 ?result ?var3 . ?result rdfs:label ?resultLabel . ?result vs:term_status ?var1 . } ORDER BY ?var1 Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 42
- 43. Query Template Incoming SELECT DISTINCT ?result WHERE { ?result foaf:knows <PERSON> . OPTIONAL { ?result foaf:knows ?var1 . FILTER ( <PERSON> = ?var1 ) <PERSON> foaf:knows ?result . } FILTER ( !bound(?var1) ) } Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 43
- 44. Query Template 2ndDegree1 SELECT DISTINCT ?result WHERE { <PERSON> foaf:knows ?p1 . <PERSON> foaf:knows ?p2 . FILTER ( ?p1 != ?p2 ) ?p1 foaf:knows ?result . FILTER ( <PERSON> != ?result ) ?p2 foaf:knows ?result . OPTIONAL { <PERSON> ?knows ?result . FILTER ( ?knows = foaf:knows ) } FILTER ( !bound(?knows) ) } Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 44
- 45. Query Template 2ndDegree2 SELECT DISTINCT ?result WHERE { <PERSON> foaf:knows ?p1 . <PERSON> foaf:knows ?p2 . FILTER ( ?p1 != ?p2 ) ?result foaf:knows ?p1 . FILTER ( <PERSON> != ?result ) ?result foaf:knows ?p2 . OPTIONAL { <PERSON> ?knows ?result . FILTER ( ?knows = foaf:knows ) } FILTER ( !bound(?knows) ) } Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 45
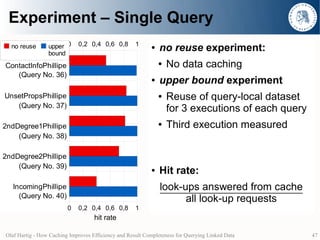
- 46. Experiment – Single Query no reuse upper 0 0,2 0,4 0,6 0,8 1 ● no reuse experiment: bound ContactInfoPhillipe ● No data caching (Query No. 36) ● upper bound experiment UnsetPropsPhillipe ● Reuse of query-local dataset (Query No. 37) for 3 executions of each query 2ndDegree1Phillipe ● Third execution measured (Query No. 38) 2ndDegree2Phillipe (Query No. 39) ● Hit rate: IncomingPhillipe look-ups answered from cache (Query No. 40) all look-up requests 0 0,2 0,4 0,6 0,8 1 hit rate Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 46
- 47. Experiment – Single Query no reuse upper 0 0,2 0,4 0,6 0,8 1 ● no reuse experiment: bound ContactInfoPhillipe ● No data caching (Query No. 36) ● upper bound experiment UnsetPropsPhillipe ● Reuse of query-local dataset (Query No. 37) for 3 executions of each query 2ndDegree1Phillipe ● Third execution measured (Query No. 38) 2ndDegree2Phillipe (Query No. 39) ● Hit rate: IncomingPhillipe look-ups answered from cache (Query No. 40) all look-up requests 0 0,2 0,4 0,6 0,8 1 hit rate Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 47
- 48. Experiment – Single Query no reuse upper 0 0,2 0,4 0,6 0,8 1 0 5 10 15 20 25 30 0 20 40 60 80 bound ContactInfoPhillipe (Query No. 36) UnsetPropsPhillipe (Query No. 37) 2ndDegree1Phillipe (Query No. 38) 2ndDegree2Phillipe (Query No. 39) IncomingPhillipe (Query No. 40) 0 0,2 0,4 0,6 0,8 1 0 5 10 15 20 25 30 0 20 40 60 80 hit rate number of query results query execution time (in seconds) Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 48
- 49. Experiment – Single Query no reuse upper 0 0,2 0,4 0,6 0,8 1 0 5 10 15 20 25 30 0 20 40 60 80 bound ContactInfoPhillipe (Query No. 36) UnsetPropsPhillipe (Query No. 37) 2ndDegree1Phillipe (Query No. 38) 2ndDegree2Phillipe (Query No. 39) IncomingPhillipe (Query No. 40) 0 0,2 0,4 0,6 0,8 1 0 5 10 15 20 25 30 0 20 40 60 80 hit rate number of query results query execution time (in seconds) Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 49
- 50. Experiment – Single Query Experiment Avg.1 number of Average1 Avg.1 query Query Results Hit Rate Execution Time (std.dev.) (std.dev.) (std.dev.) 4.983 0.576 30.036 s no reuse (11.658) (0.182) (46.708) 5.070 0.996 1.943 s upper bound (11.813) (0.017) (11.375) 1 Averaged over all 115 queries ● In the ideal case for Bupper= [ bcur , bcur ] : ● pupper( bcur , Bupper ) = c( bcur , [ ] ) – c( bcur , Bupper ) = c( bcur , [ ] ) ● supper( bcur , Bupper ) = b( bcur , Bupper ) – b( bcur , [ ] ) = 0 Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 50
- 51. Experiment – Single Query Experiment Avg.1 number of Average1 Avg.1 query Query Results Hit Rate Execution Time (std.dev.) (std.dev.) (std.dev.) 4.983 0.576 30.036 s no reuse (11.658) (0.182) (46.708) 5.070 0.996 1.943 s upper bound (11.813) (0.017) (11.375) 1 Averaged over all 115 queries ● Summary (measurement errors aside): ● Same number of query results ● Significant improvements in query performance Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 51
- 52. Experiment – Complete Sequence no reuse upper 0 given0,4 0,6 0,8 0,2 1 ● 0 given15 20 25 experiment: 5 10 order 30 0 20 40 60 80 bound order ContactInfoPhillipe ● Reuse of the query-local (Query No. 36) dataset for the complete sequence of all 115 queries UnsetPropsPhillipe (Query No. 37) 2ndDegree1Phillipe (Query No. 38) 2ndDegree2Phillipe (Query No. 39) IncomingPhillipe (Query No. 40) 0 0,2 0,4 0,6 0,8 1 0 5 10 15 20 25 30 0 20 40 60 80 hit rate number of query results query execution time (in seconds) Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 52
- 53. Experiment – Complete Sequence no reuse upper 0 given0,4 0,6 0,8 0,2 1 ● 0 given15 20 25 experiment: 5 10 order 30 0 20 40 60 80 bound order ContactInfoPhillipe ● Reuse of the query-local (Query No. 36) dataset for the complete sequence of all 115 queries UnsetPropsPhillipe (Query No. 37) 2ndDegree1Phillipe (Query No. 38) 2ndDegree2Phillipe (Query No. 39) IncomingPhillipe (Query No. 40) 0 0,2 0,4 0,6 0,8 1 0 5 10 15 20 25 30 0 20 40 60 80 hit rate number of query results query execution time (in seconds) Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 53
- 54. Experiment – Complete Sequence no reuse upper 0 given0,4 0,6 0,8 0,2 1 0 5 10 15 20 25 30 0 20 40 60 80 bound order ContactInfoPhillipe (Query No. 36) UnsetPropsPhillipe (Query No. 37) 2ndDegree1Phillipe (Query No. 38) 2ndDegree2Phillipe (Query No. 39) IncomingPhillipe (Query No. 40) 0 0,2 0,4 0,6 0,8 1 0 5 10 15 20 25 30 0 20 40 60 80 hit rate number of query results query execution time (in seconds) Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 54
- 55. Experiment – Complete Sequence no reuse upper 0 given0,4 0,6 0,8 0,2 1 0 5 10 15 20 25 30 0 20 40 60 80 bound order ContactInfoPhillipe (Query No. 36) UnsetPropsPhillipe (Query No. 37) 2ndDegree1Phillipe (Query No. 38) 2ndDegree2Phillipe (Query No. 39) IncomingPhillipe (Query No. 40) 0 0,2 0,4 0,6 0,8 1 0 5 10 15 20 25 30 0 20 40 60 80 hit rate number of query results query execution time (in seconds) Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 55
- 56. Experiment – Complete Sequence Bgiven order= [ q1 , … , q38 ] no reuse upper 0 given0,4 0,6 0,8 0,2 1 0 5 10 15 20 25 30 0 20 40 60 80 bound order s( q , Bgiven order ) = b( q39 , Bgiven order ) – b( q39 , [ ] ) 39 ContactInfoPhillipe =9–1 (Query No. 36) =8 UnsetPropsPhillipe (Query No. 37) 2ndDegree1Phillipe (Query No. 38) 2ndDegree2Phillipe (Query No. 39) IncomingPhillipe (Query No. 40) 0 0,2 0,4 0,6 0,8 1 0 5 10 15 20 25 30 0 20 40 60 80 hit rate number of query results query execution time (in seconds) Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 56
- 57. Experiment – Complete Sequence Bgiven order= [ q1 , … , q38 ] no reuse upper 0 given0,4 0,6 0,8 0,2 1 0 5 10 15 20 25 30 0 20 40 60 80 p'( q , B bound order given order 39 ) = c'( q39 , [ ] ) – c'( q39 , Bgiven order ) ContactInfoPhillipe = 31.48 s – 68.64 s (Query No. 36) = – 37.16 s UnsetPropsPhillipe (Query No. 37) 2ndDegree1Phillipe (Query No. 38) 2ndDegree2Phillipe (Query No. 39) IncomingPhillipe (Query No. 40) 0 0,2 0,4 0,6 0,8 1 0 5 10 15 20 25 30 0 20 40 60 80 hit rate number of query results query execution time (in seconds) Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 57
- 58. Experiment – Complete Sequence Experiment Avg.1 number of Average1 Avg.1 query Query Results Hit Rate Execution Time (std.dev.) (std.dev.) (std.dev.) 4.983 0.576 30.036 s no reuse (11.658) (0.182) (46.708) 5.070 0.996 1.943 s upper bound (11.813) (0.017) (11.375) 6.878 0.932 39.845 s given order (12.158) (0.139) (145.898) 1 Averaged over all 115 queries ● Summary: ● Data cache may provide for additional query results ● Impact on performance may be positive but also negative Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 58
- 59. Experiment – Complete Sequence Experiment Avg.1 number of Average1 Avg.1 query Query Results Hit Rate Execution Time (std.dev.) (std.dev.) (std.dev.) 4.983 0.576 30.036 s no reuse (11.658) (0.182) (46.708) 5.070 0.996 1.943 s upper bound (11.813) (0.017) (11.375) 6.878 0.932 39.845 s given order (12.158) (0.139) (145.898) 6.652 0.954 36.994 s random orders (11.966) (0.036) (118.700) ● Executing the query sequence in a random order results in measurements similar to the given order. Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 59
- 60. These slides have been created by Olaf Hartig http://olafhartig.de This work is licensed under a Creative Commons Attribution-Share Alike 3.0 License (http://creativecommons.org/licenses/by-sa/3.0/) Olaf Hartig - How Caching Improves Efficiency and Result Completeness for Querying Linked Data 60