How Microsoft Built and Scaled Cosmos
2 likes2,632 views

Cosmos is a large-scale data processing system used by thousands at Microsoft to process exabytes of data across clusters of over 50,000 servers. It provides a SQL-like language and allows teams to easily share and join data. This drives huge scalability requirements. The Apollo scheduler was developed to maximize cluster utilization while minimizing latency for heterogeneous workloads at cloud scale. Later, JetScope was created to support lower latency interactive queries through intermediate result streaming and gang scheduling while maintaining fault tolerance.









![organization reports to surface [..] release risks and telemetry information
telemetry information using map/reduce COSMOS
WSD organization is responsible for delivering security and non-
security fixes to Windows OSes to billions of customers, every
month on patch Tuesday](https://image.slidesharecdn.com/talkcosmoscopy-2-160118231019/85/How-Microsoft-Built-and-Scaled-Cosmos-10-320.jpg)





























How Microsoft Built and Scaled Cosmos
- 1. How Microsoft built and scaled Cosmos
- 2. Cosmos — Cosmos is a large Scale Data processing system — In use by thousands of internal users at Microsoft — Distributed filesystem contains exabytes of data — High-level SQL-like language to run jobs processing up to petabytes at a time
- 3. Outline — What made Cosmos successful — Language — Data sharing — Technical Challenges — Scalability challenges and architecture — Supporting lower latency workload — Conclusion
- 4. Language: Scope — SQL-Like language — Support structured data and unstructured data — Easy to use and learn Q = SSTREAM “queries.ss”; U = SSTREAM “users.ss”; J= SELECT *, Math.Round(Q.latency) AS l FROM Q,U WHERE Q.uid==U.uid; OUTPUT J TO “output.txt” “SCOPE: Parallel Databases Meet MapReduce” Jingren Zhou, Nicolas Bruno, Ming-chuan Wu, Paul Larson, Ronnie Chaiken, Darren Shakib, The VLDB Journal, 2012
- 5. Scope — C# extensibility — Supports user defined objects input = EXTRACT user, session, blob FROM "log_%n.txt?n=1...10" USING DefaultTextExtractor; SELECT user, session, new RequestInfo(blob) AS request FROM input WHERE request.Browser.IsChrome() “SCOPE: Parallel Databases Meet MapReduce” Jingren Zhou, Nicolas Bruno, Ming-chuan Wu, Paul Larson, Ronnie Chaiken, Darren Shakib, The VLDB Journal, 2012
- 6. Scope Distributed Execution — Queries are parsed into a logical operator tree — The optimizer transforms the query into a physical operator graph, which is then compiled into binaries — The physical operator graph and binaries are handed to a scheduler for execution “Apollo: Scalable and Coordinated Scheduling for Cloud-Scale Computing” Eric Boutin, Jaliya Ekanayake, Wei Lin, Bing Shi, Jingren Zhou, Zhengping Qian, Ming Wu, and Lidong Zhou, in Proc. of the 2014 OSDI Conference (OSDI'14)
- 8. Data Sharing — Users share data by reference — Teams put their data in Cosmos because that is where the data they want to join against is — Skype, Windows, Xbox, Bing, Ads, Office, and more http://research.microsoft.com/en-us/events/fs2011/helland_cosmos_big_data_and_big_challenges.pdf https://azure.microsoft.com/en-us/blog/behind-the-scenes-of-azure-data-lake-bringing-microsoft-s-big-data-experience-to- hadoop/ “Apollo: Scalable and Coordinated Scheduling for Cloud-Scale Computing” Eric Boutin, Jaliya Ekanayake, Wei Lin, Bing Shi, Jingren Zhou, Zhengping Qian, Ming Wu, and Lidong Zhou, in Proc. of the 2014 OSDI Conference (OSDI'14)
- 9. Network Effect • Teams put their data in Cosmos because that is where the data they want to join against is http://research.microsoft.com/en-us/events/fs2011/helland_cosmos_big_data_and_big_challenges.pdf JETS operates a high-scale, modern data pipeline for Office Telemetry data from clients and services are combined into both custom (app domain specific) and common System Health data sets in Cosmos.
- 10. organization reports to surface [..] release risks and telemetry information telemetry information using map/reduce COSMOS WSD organization is responsible for delivering security and non- security fixes to Windows OSes to billions of customers, every month on patch Tuesday
- 11. Are you interested in building the BI platform for Bing Ads? Experience with working on C#, C++, or Java, Cosmos, is highly desirable.
- 12. Are you excited about delivering the next generation personal assistant, Cortana, to millions of people using Windows worldwide? Experience with“Big Data” technologies like Cosmos
- 13. Data Sharing — Users share data by reference — Teams put their data in Cosmos because that is where the data they want to join against is — Skype, Windows, Xbox, Bing, Ads, Office, and more — This drives huge scalability requirements — Cluster size exceed 50,000 servers http://research.microsoft.com/en-us/events/fs2011/helland_cosmos_big_data_and_big_challenges.pdf https://azure.microsoft.com/en-us/blog/behind-the-scenes-of-azure-data-lake-bringing-microsoft-s-big-data-experience-to- hadoop/ “Apollo: Scalable and Coordinated Scheduling for Cloud-Scale Computing” Eric Boutin, Jaliya Ekanayake, Wei Lin, Bing Shi, Jingren Zhou, Zhengping Qian, Ming Wu, and Lidong Zhou, in Proc. of the 2014 OSDI Conference (OSDI'14)
- 14. Outline — What made Cosmos successful — Language — Data sharing — Technical Challenges — Scalability challenges and architecture — Supporting lower latency workload — Conclusion
- 15. Plan Optimizations — At large scale, query plan manipulations are required to improve efficiency of sort, aggregation and broadcast
- 16. Aggregation
- 17. Broadcast Joins
- 18. Parallel Sort
- 19. Scaling the Execution: Apollo (OSDI’14) — A large number of users share execution resources for data locality — How to minimize latency while maximizing cluster utilization? — Challenges: — Scale — Heterogeneous workload — Maximizing utilization “Apollo: Scalable and Coordinated Scheduling for Cloud-Scale Computing” Eric Boutin, Jaliya Ekanayake, Wei Lin, Bing Shi, Jingren Zhou, Zhengping Qian, Ming Wu, and Lidong Zhou, in Proc. of the 2014 OSDI Conference (OSDI'14)
- 21. Dynamic Workload How to effectively use resources while maintaining performance guarantees with a dynamic workload?
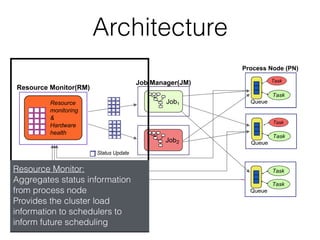
- 22. Architecture — For scalability, the architecture adopts a fully decentralized control plane — Each job has its own scheduler instance — Each scheduler is making independent decisions informed by global information
- 23. Architecture • Scheduler: There is one scheduler per job for scalability The scheduler makes local decision and directly dispatch tasks to process nodes
- 24. Architecture Process Nodes: Execute tasks on behalf of job managers Provides local resource isolation Send status update aggregated by a resource monitor
- 25. Architecture Resource Monitor: Aggregates status information from process node Provides the cluster load information to schedulers to inform future scheduling
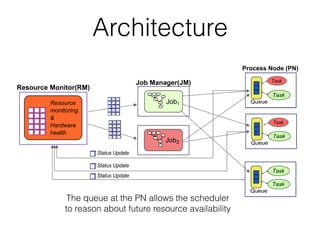
- 26. Architecture The queue at the PN allows the scheduler to reason about future resource availability
- 27. Representing Load — How to concisely represent load? — Represents the expected wait time to acquire resources — Integrated into a scheduler cost model
- 29. Optimizing for various factors — To make optimal scheduling decisions, multiple factors have to be considered at the same time — Input location — Network topology — Wait time — Initialization time — Machine health, probability of failure
- 30. Scheduler Performance Ideal scheduler (Capacity Constraint) Ideal Scheduler (Infinite Capacity) Baseline Apollo The Cosmos scheduler performs within 5% of the ideal trace driven scheduler
- 31. Utilization Cosmos maintains a median utilization above 80% on weekdays while supporting latency-sensitive workloads
- 32. More in the paper — Scheduler cost model — Opportunistic scheduling — Stable matching “Apollo: Scalable and Coordinated Scheduling for Cloud-Scale Computing” Eric Boutin, Jaliya Ekanayake, Wei Lin, Bing Shi, Jingren Zhou, Zhengping Qian, Ming Wu, and Lidong Zhou, in Proc. of the 2014 OSDI Conference (OSDI'14)
- 33. Outline — What made Cosmos successful — Language — Data sharing — Technical Challenges — Scalability challenges and architecture — Supporting lower latency workload — Conclusion
- 34. Supporting lower latency workloads — As the customer base increased, the workload diversified — Users request the ability to get interactive latencies, on the same data — While Apollo can scale to jobs processing petabytes of data, it has undesirable overhead for smaller jobs
- 35. Supporting lower latency workloads — How to provide interactive latencies at cloud scale? — How to provide fault tolerance in an interactive context?
- 36. JetScope (VLDB ’15) — Provide interactive capabilities on Cosmos & Scope — Paradigm shift in the execution model: — Stream intermediate results — Gang scheduling
- 37. Intermediate Results Streaming — JetScope avoids materializing intermediates to disk — Tasks writes to a local service, StreamNet, which manages communications — Challenges: — Deadlock on ordered merge when using finite communication buffers — Too many connections
- 38. Gang Scheduling — To achieve minimal latency, JetScope starts all tasks at the same time (gang scheduling) — Execution overlap in tasks allows an increase in parallelism — Challenge: Scheduler deadlock — Two schedulers incrementally acquire resources — Resources run out, neither jobs can execute — Solution: Admission control
- 39. —Chance of failure increases with number of servers touched —A job could fail repeatedly and never complete —We need a fault tolerance mechanism that doesn’t impact performance —Details are in the paper 39 Fault Tolerance
- 40. How does JetScope scale? Latency(seconds) 0 13 25 38 50 Q1 Q4 Q6 Q12 Q15 10TB with 200 servers 1TB with 20 servers Similar latency after 10x scale increase 40
- 41. Conclusion —Cosmos is a large scale distributed data processing system —Store exabytes of data on many clusters, that can contain over 50,000 servers —Provides both batch processing and interactive processing —Has a fully decentralized control plane for scalability —Operates a high utilization to maintain low query cost 41