

































































































Ad
More Related Content
What's hot (20)
Similar to How to build 1000 microservices with Kafka and thrive (20)






![[Big Data Spain] Apache Spark Streaming + Kafka 0.10: an Integration Story](https://cdn.slidesharecdn.com/ss_thumbnails/bigdataspainapachesparkstreamingkafka0-171117095800-thumbnail.jpg?width=560&fit=bounds)











Ad
More from Natan Silnitsky (20)




















Ad
Recently uploaded (20)




















How to build 1000 microservices with Kafka and thrive
- 1. [email protected] twitter @NSilnitsky linkedin/natansilnitsky github.com/natansil How to build 1000 microservices with Kafka and thrive Natan Silnitsky Backend Infra Developer, Wix.com
- 2. Wix Backend ~270 developers ~1300 micro-services >10M LoC (Scala ,Java, Node.js)
- 3. Wix Backend ~270 developers ~1300 micro-services >10M LoC (Scala ,Java, Node.js) 850M Kafka messages every day
- 4. Our inter-service communication Story Or How Wix moved to event driven architecture
- 5. till 2014 synchronous rpc-json + retries *special cases: activeMQ Embedded JMS broker for the JVM
- 6. Kafka SDK synchronous rpc-json + retries *special cases: activeMQ 2015 many production operations issues till 2014
- 7. A lot of boilerplate and missing features Kafka SDK 2015 synchronous rpc-json + retries *special cases: activeMQ till 2014 many production operations issues
- 8. Greyhound Make it simple and abstract Kafka SDK 2015 synchronous rpc-json + retries *special cases: activeMQ till 2014 many production operations issues A lot of boilerplate and missing features
- 9. Greyhound Kafka SDK 2015 synchronous rpc-json + retries *special cases: activeMQ till 2014 many production operations issues A lot of boilerplate and missing features 2018 Async request-reply * polyglot
- 10. Greyhound Kafka SDK Build 1,000 microservices and thrive * Easily change
- 11. Greyhound Kafka SDK Kafka works for us because of its structure
- 14. Topic TopicTopic Partition Partition Partition Partition Partition Partition Partition Partition Partition Kafka Producer Partition 0 1 2 3 4 5 append-only log
- 15. Topic TopicTopic Partition Partition Partition Partition Partition Partition Partition Partition Partition Partition 0 1 2 3 4 5 Kafka Consumers 6 7 8 9 1 0 1 1 1 2 1 3 1 4 1 5 1 6 1 7 1 8 1 9 2 0
- 17. Greyhound Producer Greyhound Consumer Kafka Consumer Kafka Producer Kafka Broker Why we wrapped Kafka
- 18. Greyhound wraps Kafka Less boilerplate …? - Setup boilerplate
- 19. KafkaProducer createProducer() { Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("acks", "all"); props.put("retries", 0); props.put("batch.size", 16384); props.put("linger.ms", 1); props.put("buffer.memory", 33554432); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); Producer<String, String> producer = new KafkaProducer<>(props); Return producer; } Setup with Kafka
- 20. KafkaProducer createProducer(GreyhoundBuilder greyhoundBuilder) { GreyhoundBufferedProducer unorderedProducer = greyhoundBuilder .bufferedProducerMaker() .unordered() .build(); } Setup with Greyhound * broker
- 21. KafkaConsumer createConsumer() { Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "test"); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.serializer", "com.foo.customserializer.UserSerializer"); KafkaConsumer<String, User> consumer = new KafkaConsumer<>(props); Return producer; } Setup with Kafka
- 22. GreyhoundConsumer createConsumer() { GreyhoundConsumer consumer = GreyhoundConsumer.aGreyhoundConsumerSpec(topic, handler); } Setup with Greyhound * Opinionated Types
- 23. Greyhound wraps Kafka Less boilerplate …? - Setup boilerplate - Consumer API boilerplate
- 24. static void runConsumer() throws InterruptedException { final Consumer<Long, SomeMessage> consumer = createConsumer(); while (true) { final ConsumerRecords<Long, SomeMessage> consumerRecords = consumer.poll(1000); consumerRecords.forEach(record -> { System.out.printf("Record value:%dn", record.value().messageValue); }); consumer.commitAsync(); } } Kafka Consumer API
- 25. static void runConsumer() throws InterruptedException { final Consumer<Long, SomeMessage> consumer = createConsumer(); while (true) { final ConsumerRecords<Long, SomeMessage> consumerRecords = consumer.poll(1000); consumerRecords.forEach(record -> { System.out.printf("Record value:%dn", record.value().messageValue); }); consumer.commitAsync(); } } Kafka Consumer API
- 26. static void runConsumer() throws InterruptedException { final Consumer<Long, SomeMessage> consumer = createConsumer(); while (true) { final ConsumerRecords<Long, SomeMessage> consumerRecords = consumer.poll(1000); consumerRecords.forEach(record -> { System.out.printf("Record value:%dn", record.value().messageValue); }); consumer.commitAsync(); } } Kafka Consumer API
- 27. static void runConsumer() throws InterruptedException { String topic = "some-topic"; MessageHandler<SomeMessage> handler = message -> System.out.printf("Record value:%dn", message.messageValue); GreyhoundConsumer consumer = GreyhoundConsumer.aGreyhoundConsumerSpec(topic, handler); } Greyhound Consumer API * No explicit commit
- 28. Greyhound wraps Kafka - Setup boilerplate - Consumer API boilerplate Extra features …?
- 29. The Kafka consumer is NOT thread-safe. All network I/O happens in the thread of the application making the call. It is the responsibility of the user to ensure that multi-threaded access is properly synchronized. Un-synchronized access will result in ConcurrentModificationException. https://kafka.apache.org/20/javadoc/index.html?org/apache/kafka/clients/consumer/KafkaConsumer.html
- 30. The Kafka consumer is NOT thread-safe. All network I/O happens in the thread of the application making the call. It is the responsibility of the user to ensure that multi-threaded access is properly synchronized. Un-synchronized access will result in ConcurrentModificationException. https://kafka.apache.org/20/javadoc/index.html?org/apache/kafka/clients/consumer/KafkaConsumer.html
- 31. Greyhound wraps Kafka So instead of a lot of consumers... - Setup boilerplate - Consumer API boilerplate + Parallel Consumption!
- 32. Kafka Broker Topic Greyhound Consumer Kafka Consumer WORKER THREAD POOL 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 (THREAD-SAFE) PARALLEL CONSUMPTION
- 33. static void runConsumer() { MessageHandler<SomeMessage> handler = ... GreyhoundConsumer consumer = GreyhoundConsumer.aGreyhoundConsumerSpec(topic, handler) .withGroup("some-group") .withMaxParallelism(10); } Greyhound Consumer
- 34. Greyhound wraps Kafka ...what about Error handling? - Setup boilerplate - Consumer API boilerplate + Thread-safe Parallel Consumption + Retries!
- 35. static void setupConsumer() { ConsumeRetryPolicy retryPolicy = ConsumeRetryPolicy.aRetryPolicy( Retries.fromBackoffs(Duration.ofSeconds(1), Duration.ofMinutes(10))); GreyhoundConsumer consumer = GreyhoundConsumer.aGreyhoundConsumerSpec(topic, handler) .withGroup("some-group") .withRetry(retryPolicy); } Greyhound Consumer
- 36. Kafka Broker site-created-topic 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 Greyhound Consumer Kafka Consumer FAILS TO READ
- 37. Kafka Broker site-created-topic 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 site-created-topic-retry-0 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 site-created-topic-retry-1 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 Inspired by Uber RETRY! Greyhound Consumer Kafka Consumer RETRY PRODUCER
- 38. Kafka Broker site-created-topic-retry-0 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 site-created-topic-retry-1 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 Kafka Broker site-created-topic 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 site-created-topic-retry-N 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 RETRY! Inspired by Uber
- 39. Retries same message on failure * Handle lag HANDLER BLOCKING POLICY Kafka Broker site-created-topic 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 Greyhound Consumer Kafka Consumer
- 41. Greyhound wraps Kafkaand when Kafka brokers are unavailable... - Setup boilerplate - Consumer API boilerplate + Thread-safe Parallel Consumption + Scheduled retries & blocking handler + Resilient Producer
- 43. Retry on failure Save to disk H2 Greyhound Resilient Producer Kafka Broker
- 44. H2H2H2 Retry on failure H2 Greyhound Resilient Producer Ordered block until message is produced Kafka Broker
- 45. H2H2H2 Retry on failure H2 Greyhound Resilient Producer Kafka Broker Unordered (better throughput and resiliency)
- 46. Greyhound wraps Kafka - Setup boilerplate - Consumer API boilerplate + Thread-safe Parallel Consumption + Scheduled retries & blocking handler + Resilient Producer + Context Propagation Super cool for us
- 50. Greyhound wraps Kafka - Setup boilerplate - Consumer API boilerplate + Thread-safe Parallel Consumption + Scheduled retries & blocking handler + Resilient Producer + Context propagation + Metrics publishing One last thing… for now
- 52. Kafka Consumer Kafka Producer Kafka Broker - Setup boilerplate - Consumer API boilerplate + Thread-safe Parallel Consumption + Scheduled retries & blocking handler + Resilient Producer + Context propagation + Metrics publishing
- 53. Greyhound takes care of the mechanics of distributed systems so YOU can focus on writing business logic.
- 55. Greyhound Consumer Greyhound Producer WIX CI + Greyhound new features / updates continuously updated
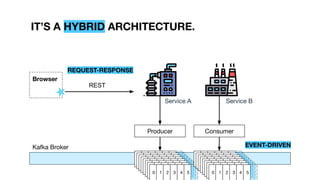
- 56. Kafka Broker ConsumerProducer Browser Service A Service B IT’S A HYBRID ARCHITECTURE. REQUEST-RESPONSE EVENT-DRIVEN 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 REST
- 57. Kafka Broker Producer Browser Pub/Sub REST use case #1 SITE CREATED!
- 58. Kafka Broker Consumer Producer Browser Pub/Sub REST use case #1 Consumer Consumer SITE CREATED!
- 59. Kafka Broker Consumer + Retries Job Scheduler Guarantee completion use case #2 Producer 1 32 RENEW SUBSCRIPTION!
- 60. Kafka Broker Long running async business process use case #3 Browser Web Sockets Service 1 Subscribe for notifications
- 61. Kafka Broker Consumer Long running async business process use case #3 Browser Producer REST 2 3 Web Sockets Service 4 1 Subscribe for notifications
- 62. Kafka Broker Consumer Long running async business process use case #3 Browser Producer REST 2 3 Web Sockets Service 4 6 Completion notification 5
- 63. Kafka Broker ConsumerProducer Service C THE COMPACT OPTION KVStore 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5
- 64. 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 DC A (Kafka Cluster A) THE CROSS-DC REPLICATION OPTION DC B (Kafka Cluster A)
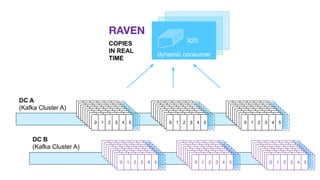
- 65. DC B (Kafka Cluster A) 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 DC A (Kafka Cluster A) 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 0 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 50 1 2 3 4 5 dynamic consumer COPIES IN REAL TIME X20 RAVEN
- 67. Wix has embraced Asynchronous, Event Driven design. ...and has all the required tools in place to support it.
- 68. Thank You [email protected] twitter @NSilnitsky linkedin/natansilnitsky github.com/natansil
- 70. Q&A [email protected] twitter @NSilnitsky linkedin/natansilnitsky github.com/natansil