













































![OWL2 Property chain example
Digital Enterprise Research Institute www.deri.ie
ex:uncle rdf:type owl:ObjectProperty .
ex:parent rdf:type owl:ObjectProperty .
ex:brother rdf:type owl:ObjectProperty .
[] rdfs:subPropertyOf ex:uncle;!!
owl:propertyChain (!
ex:parent!!
ex:brother!!
).
:alice ex:parent :bob .
:bob ex:brother :joe .
=
:alice ex:uncle :joe .
29 of XYZ](https://image.slidesharecdn.com/drupalrdfasemtech20100625-100626161426-phpapp02/85/How-to-Build-Linked-Data-Sites-with-Drupal-7-and-RDFa-48-320.jpg)







































































![90%+%/$*+-$/-'7:'.!8')'!+2,%';
!#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4*
! .8$/0!!6#3
1T$#43!.8$/0E4!/*/!'2!5.=/
:8*#B/*'6/00%
U#!5.=!3T$3*'43!3V8'3
! .8$/0!!6#2*'W8*3!B#8034
N#3!5.=!A#B/*4!X5.=HYNZQ!2*'$034Q!*8*03[
=03T'W03!V83%'2(!X]:5^Z[
1T$#*!/2!7B$#*](https://image.slidesharecdn.com/drupalrdfasemtech20100625-100626161426-phpapp02/85/How-to-Build-Linked-Data-Sites-with-Drupal-7-and-RDFa-125-320.jpg)







![A*)*:$-'7:'.!8')'!+2,%';
!#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4*
! =_:=Q!7_Q!`_Q!.!a#8*!#A!*)3!W#Tb
! :00!8434!)/;3!/2!#20'23!'32*'*%G!
c3W7.G!d57!A#!/2!'2';'8/0
e843HRfB3!!!!!Jg!!A#/AG]34#2
e=_:=hZ!/8*)32*'6/*'#2](https://image.slidesharecdn.com/drupalrdfasemtech20100625-100626161426-phpapp02/85/How-to-Build-Linked-Data-Sites-with-Drupal-7-and-RDFa-134-320.jpg)



![!+2,%'%)5'60*'C*D'%$'%+#*
!#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4*
! .8$/0!J!$'#233!N
! ]0/*A#B!#A!6)#'63!A#!B/2%!843!6/434
! 72A083263!*)3!*324
! L,,9,,,!.8$/0!4'*34!XSl[
! N#3!5.=!/*/!#2!*)3!c3W](https://image.slidesharecdn.com/drupalrdfasemtech20100625-100626161426-phpapp02/85/How-to-Build-Linked-Data-Sites-with-Drupal-7-and-RDFa-138-320.jpg)
![/E)73*5#*@*)$-
!#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4*
97*%#2*-'%$'!(.1'%)5'F1!'1):7+@%$/-
60-'37+E'0%-'D**)':2)5*5'D='$0*':773)#'#+%)$-
!6'3263!=#82/*'#2!730/2!823!O/2*!U#9!=7H,DH1H7SRD,
!=]H7ji+,,9K9K!j51]](https://image.slidesharecdn.com/drupalrdfasemtech20100625-100626161426-phpapp02/85/How-to-Build-Linked-Data-Sites-with-Drupal-7-and-RDFa-139-320.jpg)































Ad
More Related Content
What's hot (20)
Similar to How to Build Linked Data Sites with Drupal 7 and RDFa (20)


















Ad
More from scorlosquet (19)



















Ad
Recently uploaded (20)




















How to Build Linked Data Sites with Drupal 7 and RDFa
- 1. !"#"$%&'()$*+,+"-*'.*-*%+/0'1)-$"$2$* 33345*+"4"* =#>!*#!?8'0<!@'2A3<!./*/!B'*34! >'*)!.&8$/0!C!/2<!5.D/ B*E$)/23!"#&0#4F83*G!@'2!"0/&AG!:03H/2<&3!I/44/2*G!:H30!I#003&34 B3JK36)!+,L, B/2!D&/26'46# M823!+N*)G!+,L, ! !"#$%&'()*!+,,-!.'('*/0!12*3&$&'43!5343/&6)!724*'*8*39!:00!&'()*4!&343&;3<9
- 2. % ! ()
- 3. 72$8+%'82$)* !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* ! 72*#86*'#2!*#!B3J/2*'6!/2!843O80!;#6/P80/'34!QLGN!)R ! S3**'2(!4*/*3!'*)!.8$/0!CT!'24*/00/*'#2!/2! 6#2O'(8/*'#2!QLGN!)R U43!6/43 =/24V#2!.3J# ! 5.D!'2!.8$/0!C!QW)R :6)'*36*83 .3O/80*!5.D!J/$$'2(4
- 4. !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* 72*#86*'#2!*#!*)3!=3/2*'6!?3@ ! !#$%'()*!+,,-!.'('*/0!12*3$'43!5343/6)!724*'*8*39!:00!'()*4!343;39 )/$*3
- 5. Semantic Web benefits Digital Enterprise Research Institute www.deri.ie ! Programs and sites can my-site.net company.com your-site.org exchange information ! Search engines can display more relevant information in results ! Data mashers can + combine data from different datasets to find new and astounding things 1
- 6. Key (confusing) terms Digital Enterprise Research Institute www.deri.ie Machine Understandable Linked Data SPARQL RDF Giant Federated Dataset Global Graph 2
- 7. Machine Understandable Digital Enterprise Research Institute www.deri.ie linclark.jpg is a picture The Semantic Web helps of a person named machines understand what Lin Clark the information on a Web page is... 3
- 8. RDF Digital Enterprise Research Institute www.deri.ie R esource Description F ramework 4
- 9. RDF Digital Enterprise Research Institute www.deri.ie Everything is a resource A resource is a named thing A resource is a uniquely named thing Namespace xmlns:lin=”http://lin-clark.com/page.html# CURIE URI this http://lin-clark.com/page.html#this lin:this 5
- 10. RDF Digital Enterprise Research Institute www.deri.ie A resource can be a document foaf:Document dblp:this 6
- 11. RDF Digital Enterprise Research Institute www.deri.ie A resource can be a company foaf:Organization deri:this 7
- 12. RDF Digital Enterprise Research Institute www.deri.ie A resource can even be a person foaf:Person lin:me 8
- 13. RDF Digital Enterprise Research Institute www.deri.ie You can describe properties of that person... foaf:name Lin Clark foaf:mbox [email protected] foaf:birthday 07-01 lin:me 9
- 14. RDF Digital Enterprise Research Institute www.deri.ie and describe how that person is related to other resources foaf:made swrc:employs lin:me dblp:this deri:this 10
- 15. Federated Dataset Digital Enterprise Research Institute www.deri.ie Because we are using http URIs, these resources don’t need to be in the same database foaf:made swrc:employs lin:me dblp:this deri:this 11
- 16. Federated Dataset Digital Enterprise Research Institute www.deri.ie the resources can be distributed across the Web in a federated datagraph 12
- 17. Giant Global Graph Digital Enterprise Research Institute www.deri.ie And when all resources are described this way, the Web becomes one giant database... 13
- 18. SPARQL Digital Enterprise Research Institute www.deri.ie Find and retrieve information from the graph using SPARQL 14
- 19. The Semantic Web Digital Enterprise Research Institute www.deri.ie Machine Understandable Linked Data SPARQL RDF Giant Federated Dataset Global Graph 15
- 20. Digital Enterprise Research Institute www.deri.ie The Semantic Web ! Copyright 2009 Digital Enterprise Research Institute. All rights reserved.
- 21. The Web - Initial Proposal (1989) Digital Enterprise Research Institute www.deri.ie http://www.w3.org/History/1989/proposal.html 2 of XYZ
- 22. The Web - Circa 2010 Digital Enterprise Research Institute www.deri.ie ?? ?? ?? 3 of XYZ
- 23. The Web – 1994 Vision Digital Enterprise Research Institute www.deri.ie To a computer, the Web is a flat, boring world, devoid of meaning. This is a pity, as in fact documents on the Web describe real objects and imaginary concepts, and give particular relationships between them. For example, a document might describe a person. The title document to a house describes a house and also the ownership relation with a person. Adding semantics to the Web involves two things: allowing documents which have information in machine- readable forms, and allowing links to be created with relationship values. Only when we have this extra level of semantics will we be able to use computer power to help us exploit the information to a greater extent than our own reading. Tim Berners-Lee, 1st World Wide Web Conference, Geneva, May 1994 4 of XYZ
- 24. The Web – 1994 Vision Digital Enterprise Research Institute www.deri.ie http://www.slideshare.net/danbri/when-presentation-849447 5 of XYZ
- 25. The Semantic Web Digital Enterprise Research Institute www.deri.ie ! Bridging the gap from a Web of Documents to a Web of Data With typed objects and typed relationships: The Web as a giant decentralized database ! Adding machine-readable meta-data to existing content So that information can be parsed, queried, reused ! Defining shared semantics for this meta-data For interoperability between applications and for advanced purposes, such as reasoning ! Enabling machine-readable knowledge at Web scale, making information more easy to find and process 6 of XYZ
- 26. Digital Enterprise Research Institute www.deri.ie
- 27. A Bit of History Digital Enterprise Research Institute www.deri.ie ! Memex 1945 ! - Vannevar Bush A memex is “a device in which an individual stores all his books, records, and communications.” ! Augmenting Human Intellect 1960 - Douglas Engelbart “By ‘augmenting human intellect’ we mean increasing the capability of a man to approach a complex problem situation, to gain comprehension to suit his particular needs, and to derive solutions to problems.” 8 of XYZ
- 28. More recently Digital Enterprise Research Institute www.deri.ie ! SHOE http://www.cs.umd.edu/projects/plus/SHOE/ “SHOE is a small extension to HTML which allows web page authors to annotate their web documents with machine- readable knowledge. SHOE makes real intelligent agent software on the web possible.“ 9 of XYZ
- 29. The Semantic Web, right now Digital Enterprise Research Institute www.deri.ie ! Standardisation work in W3C http://w3.org ! Semantic Web activity http://www.w3.org/2001/sw/ ! Incubator Groups, Working Groups, Interest Groups SPARQL - http://www.w3.org/2009/sparql/wiki/Main_Page RDB2RDF – http://www.w3.org/2005/Incubator/rdb2rdf RIF - http://www.w3.org/2005/rules/ HCLS - http://www.w3.org/2001/sw/hcls/ … 10 of XYZ
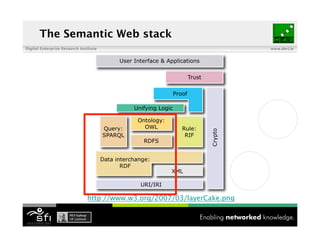
- 30. The Semantic Web stack Digital Enterprise Research Institute www.deri.ie http://www.w3.org/2007/03/layerCake.png 11 of XYZ
- 31. The Semantic Web stack Digital Enterprise Research Institute www.deri.ie http://www.w3.org/2007/03/layerCake.png 12 of XYZ
- 32. Digital Enterprise Research Institute www.deri.ie URIs, RDF(S) and OWL ! Copyright 2009 Digital Enterprise Research Institute. All rights reserved.
- 33. URIs Digital Enterprise Research Institute www.deri.ie ! A Uniform Resource Identifier (URI) is a compact sequence of characters that identifies an abstract or physical resource as of RFC3986 ! URIs are used to identify everything in a unique and non-ambiguous way Not only pages (as on the current Web), but any resource (people, documents, books, interests …) A URI for a person is different from a URI for a document about the person, because a person is not a document ! ! Example http://apassant.net/alex - myself http://apassant.net - my homepage 14
- 34. Resource Description Framework Digital Enterprise Research Institute www.deri.ie ! URI represent resources But how define things about these resources ? E.g. “Drupal is a CMS”, “DERI is in Galway” ! RDF – Resource Description Framework RDF abstract syntax, a data model: a directed, labeled graph based on URIs RDF is not XML ! RDF/XML is only one of the multiple way to serialize RDF data (N3, RDFa …) ! RDF is based on triples subject predicate object . Subjects and predicates are URIs Objects can be either URIs or litterals 15
- 35. RDF by example Digital Enterprise Research Institute www.deri.ie @prefix dct: http://purl.org/dc/terms/ . ! http://semtech2010.semanticuniverse.com/talk/2889#id! dct:title “How to build Linked Data sites with Drupal7 and RDFa” ; ! dct:author http://apassant.net/alex ;! dct:subject http://dbpedia.org/resource/Drupal .! How to build Linked Data sites with dct:title http://semtech2010.semanticuniverse.com/talk/2889#id Drupal7 and RDFa dct:author dct:subject http://apassant.net/alex http://dbpedia.org/resource/Drupal 16
- 36. RDFa Digital Enterprise Research Institute www.deri.ie ! A way of embedding RDF in (X)HTML documents: One page for both humans and machines Don’t need to repeat yourself Introducing new XHTML attributes http://www.w3.org/TR/xhtml-rdfa-primer/ ! Current work is ongoing on RDFa 1.1: For profiles, etc.
- 37. RDFa by example Digital Enterprise Research Institute www.deri.ie
- 38. RDFa by example Digital Enterprise Research Institute www.deri.ie
- 39. RDFa and prefixes Digital Enterprise Research Institute www.deri.ie ! http://sdow2009.semanticweb.org Header contains prefixes and links to the GRDDL transformation
- 40. Extracting other serialisations Digital Enterprise Research Institute www.deri.ie ! http://sdow2009.semanticweb.org Webpage can be translated to native RDF/XML using an RDFa distiller - http://www.w3.org/2007/08/pyRdfa/
- 41. Ontologies Digital Enterprise Research Institute www.deri.ie ! RDF provides a way to write assertions But what about their semantics E.g. how can one know that http://xmlns.com/foaf/0.1/knows identifies an acquaintance relationship ? ! Ontologies provide common semantics for resources on the Semantic Web “An ontology is a specification of a conceptualization.” ! Developing ontologies for the Semantic Web Main languages are RDFS (RDF Schema) and OWL (Web Ontology Language) Growing expressivity levels 22 of XYZ
- 42. Ontologies Digital Enterprise Research Institute www.deri.ie ! Classes and properties :Person a rdfs:Class . :father a rdfs:Property . :father rdfs:domain :Person . :father rdfs:range :Person . 23 of XYZ
- 43. Metadata and ontologies Digital Enterprise Research Institute www.deri.ie
- 44. RDFS Digital Enterprise Research Institute www.deri.ie ! RDFS defines classes, properties and subsumption relations between classes and properties ex:Person rdfs:subClassOf ex:humanLiving . ex:worksWith rdfs:subPropertyOf ex:knows . ! Such relationships are used to infer new statements :alex rdf:type ex:Person . :Alex ex:worksWith :Axel . Is enough to say that Alex is a humanLiving and knows Axel 25 of XYZ
- 45. RDFS by example Digital Enterprise Research Institute www.deri.ie 26 of XYZ
- 46. OWL Digital Enterprise Research Institute www.deri.ie ! OWL goes further than RDFS by introducing new axioms Disjunction (e.g. person / document) Transitivity (e.g. ancestor) Symmetry (e.g. sibling) Cardinality constraints (e.g. ancestor 1) ! OWL2 introduces a lot of useful features, especially for reasoning Property Chains (parent + brother - uncle) 27 of XYZ
- 47. OWL by example Digital Enterprise Research Institute www.deri.ie 28 of XYZ
- 48. OWL2 Property chain example Digital Enterprise Research Institute www.deri.ie ex:uncle rdf:type owl:ObjectProperty . ex:parent rdf:type owl:ObjectProperty . ex:brother rdf:type owl:ObjectProperty . [] rdfs:subPropertyOf ex:uncle;!! owl:propertyChain (! ex:parent!! ex:brother!! ). :alice ex:parent :bob . :bob ex:brother :joe . = :alice ex:uncle :joe . 29 of XYZ
- 49. Digital Enterprise Research Institute www.deri.ie Linked Data ! Copyright 2009 Digital Enterprise Research Institute. All rights reserved.
- 50. Linked Data Digital Enterprise Research Institute www.deri.ie ! Building a “Web of Data” to enhance the current Web ! Exposing, sharing and connecting data about things via dereferenceable URIs ! The Linking Open Data (LOD) project: http://linkeddata.org/ Translating existing datasets into RDF and linking them together, for example DBpedia (Wikipedia) and GeoNames, Freebase, BBC programmes, etc. Governement data also available as Linked Data
- 51. The Linked Data principles Digital Enterprise Research Institute www.deri.ie ! http://www.w3.org/DesignIssues/LinkedData.html ! Use URIs as names for things ! Use HTTP URIs so that people can look up those names ! When someone looks up a URI, provide useful information, using the standards (RDF, SPARQL) ! Include links to other URIs. so that they can discover more things ! E.g. http://dbpedia.org/resource/SPARQL 32
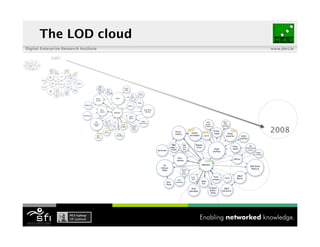
- 52. The LOD cloud Digital Enterprise Research Institute www.deri.ie 2007 2008
- 53. The LOD cloud Digital Enterprise Research Institute www.deri.ie 2008 2009
- 54. Digital Enterprise Research Institute www.deri.ie image from richard.cyganiak.de/2007/10/lod/lod-datasets_2009-07-14.png
- 55. Digital Enterprise Research Institute www.deri.ie Some Ontologies used in Drupal7 ! Copyright 2009 Digital Enterprise Research Institute. All rights reserved.
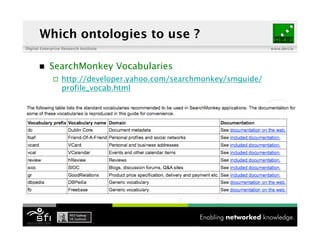
- 56. Which ontologies to use ? Digital Enterprise Research Institute www.deri.ie ! SearchMonkey Vocabularies http://developer.yahoo.com/searchmonkey/smguide/ profile_vocab.html 37
- 57. Which ontologies to use ? Digital Enterprise Research Institute www.deri.ie ! How to Publish Linked Data on the Web http://www4.wiwiss.fu-berlin.de/bizer/pub/ LinkedDataTutorial/ 38
- 58. Extending ontologies ? Digital Enterprise Research Institute www.deri.ie ! What if existing ontologies are not enough for your needs ? Create a new ontology … or extend an existing one ! ! Ontologies can be extended in a decentralized way E.g. Anyone can create a subproperty of foaf:knows, “metInSemtech”, in his own ontology and publish it online ! Open.vocab.org A collaborative platform to manage ontologies http://open.vocab.org 39
- 59. Drupal7 Digital Enterprise Research Institute www.deri.ie ! The following models are used in Drupal7 ! RSS Content module http://web.resource.org/rss/1.0/modules/content/ ! DublinCore http://dublincore.org/ ! FOAF http://foaf-project.org ! SIOC and its Types module http://sioc-project.org ! SKOS http://www.w3.org/2004/02/skos/
- 60. RSS Content Digital Enterprise Research Institute www.deri.ie
- 61. DublinCore Digital Enterprise Research Institute www.deri.ie ! DublinCore DCMI Metadata Terms http://purl.org/dc/terms/ ! Some properties dc:title dc:subject dc:created dc:date dc:modified
- 62. DublinCore by example Digital Enterprise Research Institute www.deri.ie
- 63. FOAF – Friend Of A Friend Digital Enterprise Research Institute www.deri.ie
- 64. FOAF – Friend Of A Friend Digital Enterprise Research Institute www.deri.ie ! An ontology for describing people and the relationships that exist between them: http://foaf-project.org/ Identity, personal profiles and social networks Can be integrated with other SW vocabularies ! FOAF on the Web: LiveJournal, MyOpera, identi.ca, MyBlogLog, hi5, Fotothing, Videntity, FriendFeed, Ecademy, Typepad
- 65. FOAF (Friend-of-a-Friend) Digital Enterprise Research Institute www.deri.ie
- 66. FOAF (Friend-of-a-Friend) Digital Enterprise Research Institute www.deri.ie
- 67. FOAF at a glance Digital Enterprise Research Institute www.deri.ie
- 68. FOAF from Flickr Digital Enterprise Research Institute www.deri.ie
- 69. FOAF from Twitter Digital Enterprise Research Institute www.deri.ie
- 70. Distributed identity with FOAF Digital Enterprise Research Institute www.deri.ie
- 71. Interlinking identities and networks Digital Enterprise Research Institute www.deri.ie
- 72. FOAF+SSL: Secured authentication Digital Enterprise Research Institute www.deri.ie
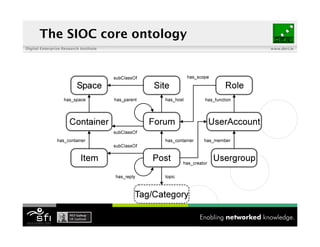
- 73. SIOC Digital Enterprise Research Institute www.deri.ie ! Semantically-Interlinked Online Communities http://sioc-project.org/ ! Addressing interoperability issues on the (Social) Web To fully describe content / structure of social websites and to create new connections between online discussion posts and items, forums and containers Various domains: Web 2.0, enterprise information integration, HCLS, e-government Widely deployed (SearchMonkey, Talis, etc.)
- 74. Digital Enterprise Research Institute www.deri.ie
- 75. The SIOC core ontology Digital Enterprise Research Institute www.deri.ie
- 76. SIOC by example Digital Enterprise Research Institute www.deri.ie
- 77. SIOC Types Digital Enterprise Research Institute www.deri.ie ! Additional information is required for finer-grained representation of Web 2.0 content Differentiating a blog post from a wiki page or from a microblogging status update ! SIOC Types http://rdfs.org/sioc/types ! Use-case in HCLS http://www.w3.org/TR/hcls-sioc/
- 78. SIOC Types Digital Enterprise Research Institute www.deri.ie
- 79. SIOC Types Digital Enterprise Research Institute www.deri.ie
- 80. SIOC Types by example Digital Enterprise Research Institute www.deri.ie
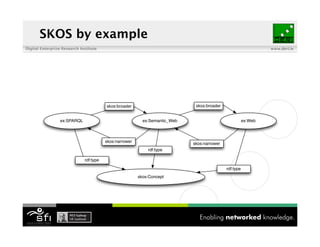
- 81. SKOS Digital Enterprise Research Institute www.deri.ie ! SKOS - Simple Knowledge Organization System http://www.w3.org/TR/2009/REC-skos- reference-20090818/ ! Thesaurus, subject headings and classifications skos:Concept skos:semanticRelation – skos:related, skos:narrower, skos:broader – A different semantics than in RDFS/OWL hierarchies ! Used by: NY Times, Library of Congress, DBpedia, etc.
- 82. SKOS by example Digital Enterprise Research Institute www.deri.ie ex:SPARQL ex:Semantic_Web ex:Web rdf:type rdf:type rdf:type skos:Concept
- 83. SKOS by example Digital Enterprise Research Institute www.deri.ie skos:broader skos:broader ex:SPARQL ex:Semantic_Web ex:Web rdf:type rdf:type rdf:type skos:Concept
- 84. SKOS by example Digital Enterprise Research Institute www.deri.ie skos:broader skos:broader ex:SPARQL ex:Semantic_Web ex:Web skos:narrower skos:narrower rdf:type rdf:type rdf:type skos:Concept
- 85. SKOS by example Digital Enterprise Research Institute www.deri.ie skos:semanticRelation skos:broader skos:broader ex:SPARQL ex:Semantic_Web ex:Web skos:narrower skos:narrower rdf:type rdf:type rdf:type skos:Concept
- 86. SKOS by example Digital Enterprise Research Institute www.deri.ie
- 87. SKOS by example Digital Enterprise Research Institute www.deri.ie
- 88. SKOS by example Digital Enterprise Research Institute www.deri.ie
- 89. SKOS by example Digital Enterprise Research Institute www.deri.ie
- 90. Digital Enterprise Research Institute www.deri.ie Querying RDF data with SPARQL ! Copyright 2009 Digital Enterprise Research Institute. All rights reserved.
- 91. SPARQL Digital Enterprise Research Institute www.deri.ie ! RDF(S)/OWL useful to produce data A need to query it ! SPARQL SPARQL Protocol and RDF Query Language The “SQL” of the Semantic Web ! FAQ http://www.thefigtrees.net/lee/sw/sparql-faq ! SPARQL Query Recommendation / tutorial http://www.w3.org/TR/rdf-sparql-query/ ! Currently under standardization for SPARQL1.1 http://www.w3.org/2009/sparql/wiki/Main_Page
- 92. How it works ? Digital Enterprise Research Institute www.deri.ie ! Graph Pattern Matching Identifying if a requested graph matches the underlying RDF data ! Four different operators SELECT, DESCRIBE, CONSTRUCT, ASK Combined with query patterns and optional features (union, filters …) ! A Protocol To query RDF data using SPARQL endpoints via HTTP ! Most of endpoints are associated with an RDF store A place that stores RDF data and provides open access to it – e.g. http://dbpedia.org/sparql
- 93. Example of SELECT queries Digital Enterprise Research Institute www.deri.ie “select persons older than 30” SELECT ?X WHERE { ?X a foaf:Person. ?X ex:age ?Y. FILTER (?Y 30) } 74
- 94. Querying DBpedia Digital Enterprise Research Institute www.deri.ie ! People Born in Galway Simple triple pattern http://dbpedia.org/ontology/birthplace ! Answer SELECT ?who! WHERE {! ?who ! http://dbpedia.org/ontology/birthplace :Galway .! }!
- 95. Querying DBpedia Digital Enterprise Research Institute www.deri.ie ! Japanese name of Galway ! Using the FILTER by LANG clause FILTER(lang(?x) = ja) ! Answer SELECT ?name! WHERE {! :Galway rdfs:label ?name .! FILTER (lang(?name) = ja) .! }!
- 96. Querying DBpedia Digital Enterprise Research Institute www.deri.ie ! Irish cities at the east of Galway!
- 97. Querying DBpedia Digital Enterprise Research Institute www.deri.ie ! FILTER by type and comparison of coordinates ! Answer PREFIX yago: http://dbpedia.org/class/yago/! SELECT DISTINCT ?place ?long WHERE {! :Galway dbpedia2:westCoord ?glong .! ?place rdf:type! yago:CitiesInTheRepublicOfIreland ;! dbpedia2:westCoord ?long .! FILTER (?long ?glong) ! }!
- 98. !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* =)%!.8$/0 ! !#$%'()*!+,,-!.'('*/0!12*3$'43!5343/6)!724*'*8*39!:00!'()*4!343;39 )/$*3
- 99. What is Drupal? Digital Enterprise Research Institute www.deri.ie 2
- 100. What IS Drupal? Digital Enterprise Research Institute www.deri.ie Content Management System CMS Content Management Framework CMF 3
- 101. What IS Drupal? Digital Enterprise Research Institute www.deri.ie CMS A package that a non-developer (or non-Web developer) can download and install quickly and easily to create a complex website Runs on many servers, particularly Apache and MySQL which are used by many hosting providers With Drupal 7, setup should take less than 10 minutes A collection of modules that can be plugged into the main package to bring advanced functionality to the site At last count in Spring of 2009, there were 4400 modules on Drupal.org Common quote: “There’s a module for that” 4
- 102. What IS Drupal? Digital Enterprise Research Institute www.deri.ie CMF Gets Web developers up and running with functionality quickly, but allows for a very high level of customization A number of APIs for things such as form creation and processing Hook system allows external modules to act when something happens in the main body of code All templates can be overridden at a granular level Allows Web developers to package up any custom functionality or configuration and distribute it widely to developers and non-developers alike Modules Themes Installation Profiles and Features 5
- 103. What does RDF in Drupal mean? Digital Enterprise Research Institute www.deri.ie CMS Out of the box, content structures are mapped to RDF Contributed modules offer advanced functionality without having to code anything CMF RDF Mapping API in Drupal core package A collection of RDF functions in a contributed API 15
- 104. Why Drupal? Digital Enterprise Research Institute www.deri.ie Similarities • Both have structured data • Data is structured in a similar way— instances of types with properties and relationships 1
- 105. Why Drupal? Digital Enterprise Research Institute www.deri.ie Differences • Drupal’s structure stays hidden in the database, RDF structure is exposed on the page • Drupal’s field names are unique to the site and not explicitly defined, RDF terms are universally dereferencable and explicitly defined 2
- 106. Default RDF mappings in core Digital Enterprise Research Institute www.deri.ie • Node titles • Submission information • Comment count and comment relationships • Users, names and homepages • Taxonomy terms • Featured images ... And you can define your own mappings for your content types or alter mappings for existing ones 5
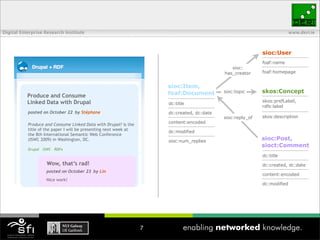
- 107. Digital Enterprise Research Institute www.deri.ie sioc:User foaf:name sioc: has_creator foaf:homepage sioc:Item, foaf:Document sioc:topic skos:Concept Produce and Consume Linked Data with Drupal skos:prefLabel, dc:title rdfs:label posted on October 22 by Stéphane dc:created, dc:date sioc:reply_of skos:description content:encoded Produce and Consume Linked Data with Drupal! is the title of the paper I will be presenting next week at dc:modified the 8th International Semantic Web Conference (ISWC 2009) in Washington, DC. sioc:num_replies sioc:Post, sioct:Comment Drupal ISWC RDFa dc:title Wow, that’s rad! dc:created, dc:date posted on October 23 by Lin content:encoded Nice work! dc:modified 7
- 108. Digital Enterprise Research Institute www.deri.ie posted on span property=dc:date dc:created content=2009-10-22T08:03:26-05:00 Produce and Consume datatype=xsd:dateTime Linked Data with Drupal October 22 posted on October 22 by Stéphane /span by Produce and Consume Linked Data with Drupal! is the span rel=sioc:has_creator title of the paper I will be presenting next week at span about=/user/6 the 8th International Semantic Web Conference (ISWC 2009) in Washington, DC. typeof=sioc:User property=foaf:name Drupal ISWC RDFa stephane /span Wow, that’s rad! /span posted on October 23 by Lin Nice work! 8
- 109. Digital Enterprise Research Institute www.deri.ie RDF Mapping User Interface User interface for site administrators to define new mappings or alter existing mappings. 10
- 110. Digital Enterprise Research Institute www.deri.ie RDF SPARQL Endpoint A RDF store that makes your site information available for SPARQL queries. 11
- 111. Digital Enterprise Research Institute www.deri.ie RDF Proxy A way of connecting nodes to RDF sources across the Web and automatically syncing your site’s information with the external source. 12
- 112. Digital Enterprise Research Institute www.deri.ie E-Commerce Module Item for sale gr:Offering gr:hasPriceSpecification gr:hasWarrantyScope gr:hasWarrantyPromise 14
- 113. !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* =3**'2(!4*/*3!'*)!.8$/0!? @! A43!6/43 ! !#$%'()*!+,,-!.'('*/0!12*3$'43!5343/6)!724*'*8*39!:00!'()*4!343;39 )/$*3
- 114. .2)))#'*6%7,*8'9+#%):%$;) !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4*
- 115. .2)))#'*6%7,*8'9+#%):%$;) !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4*
- 116. .2)))#'*6%7,*8'9+#%):%$;) !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* ! !#$%'$()%*+(,*-./(*0(1*2.3$/4 5 67(,%$/*8$($*9):*3.-/;$()%*+,;,+*=/,*2?@AB 5 @,*-.(()%*9)*C$;,-))
- 117. .2)))#'*6%7,* !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4*
- 118. !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* =3**'2(!4*/*3!'*)!.8$/0!? @! A/24@#2!3B# ! !#$%'()*!+,,-!.'('*/0!12*3$'43!5343/6)!724*'*8*39!:00!'()*4!343;39 )/$*3
- 119. Site Configuration Digital Enterprise Research Institute www.deri.ie • Edit your site information admin/config/system/site-information • Create a front page node/add admin/config/system/site-information • Change your site design and logo admin/appearance • Install modules admin/modules • Configure Wysiwyg editor admin/config/content/wysiwyg 1
- 120. Site Configuration Digital Enterprise Research Institute www.deri.ie • Create Content Types Add Fields admin/structure/types • Manage menus admin/structure/menu/manage/main-menu Review and find out more at: youtube.com/linwclark 2
- 121. !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* 5.=!'2!.8$/0! )/$*3 ! !#$%'()*!+,,-!.'('*/0!12*3$'43!5343/6)!724*'*8*39!:00!'()*4!343;39
- 122. 673%+5-'.!8')'!+2,%'/7+* !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* ?@'3#!A#B!*)3!A8*83? .8$/0#2!C#4*#2!+,,D .'34E!F3%2#*3 )**$GHH;'3#9(##(0396#BH;'3#$0/%I#6'JDKD+LL+-MDKK,DM,
- 123. 673%+5-'.!8')'!+2,%'/7+* !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* #3!4$'2* N/%!+,,- .157!O/0P/%Q!730/2 )**$GHH8$/09#(H2#3HKKRD+K
- 124. 673%+5-'.!8')'!+2,%'/7+* !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* )**$GHH*P'**396#BH'34H4*/*84HK--RSSKRK
- 125. 90%+%/$*+-$/-'7:'.!8')'!+2,%'; !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* ! .8$/0!!6#3 1T$#43!.8$/0E4!/*/!'2!5.=/ :8*#B/*'6/00% U#!5.=!3T$3*'43!3V8'3 ! .8$/0!!6#2*'W8*3!B#8034 N#3!5.=!A#B/*4!X5.=HYNZQ!2*'$034Q!*8*03[ =03T'W03!V83%'2(!X]:5^Z[ 1T$#*!/2!7B$#*
- 126. +/0$*/$2+* !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* ! *86*83!/*/G!'24*/2634!#A! *%$34!P'*)!$#$3*'34!/2! 30/*'#24)'$4 ! #2*32*!*%$3!J!5.=!60/44 ! ='30!J!5.=!$#$3*% ! U#3!J!5.=!34#863 )**$GHHPPP9A0'6F96#BH$)#*#4H#6B/2H++SMLMD+S,
- 127. 97)$*)$'$=,*-'%)5'8*5- !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4*
- 128. 97)$*)$'$=,*-'%)5'8*5- !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4*
- 129. 75* !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4*
- 130. .!8'%)5'.!8% !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* ! !#$%'$()*+,*-,( ! ..#/$0%$12-3$456(/$78)-( ! 922:;/$1*22=/$*?'223
- 131. .!8'%)5'.!8% !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* ! 922,7;*)52+( ! @$A$B-?+)$5+?-*($5+$)-*C? ! 1*22$2'(-D($*$EFA$5+?-*($5+$)$ #;5?3G)-28:G7*)
- 132. !+2,%';'5*:%2$'.!8'?/0*@% !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4*
- 133. !+2,%';'%)5'.!8 !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4*
- 134. A*)*:$-'7:'.!8')'!+2,%'; !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* ! =_:=Q!7_Q!`_Q!.!a#8*!#A!*)3!W#Tb ! :00!8434!)/;3!/2!#20'23!'32*'*%G! c3W7.G!d57!A#!/2!'2';'8/0 e843HRfB3!!!!!Jg!!A#/AG]34#2 e=_:=hZ!/8*)32*'6/*'#2
- 135. B73'@%/0)*-'-**'!+2,%',%#*- !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* ! dW'V8'*%!5.=/ ! '2'63!i!j)3!3B/2*'6!c3W!'23T )**$GHH8W'V8'*%iA/9(##(036#396#BH4;2H*82FH8W'V8'*%i0#/39k4 )**$GHH4'2'6396#BH
- 136. H2%$6*?5+($($I-8B*;$B*:( !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* ! dW'V8'*%!5.=/ ! '2'63!i!j)3!3B/2*'6!c3W!'23T
- 137. H2%$6*?5+($($I-8B*;$B*:( !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* .;2:$B2()$*($*$:-*B ! dW'V8'*%!5.=/ ! '2'63!i!j)3!3B/2*'6!c3W!'23T
- 138. !+2,%'%)5'60*'C*D'%$'%+#* !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* ! .8$/0!J!$'#233!N ! ]0/*A#B!#A!6)#'63!A#!B/2%!843!6/434 ! 72A083263!*)3!*324 ! L,,9,,,!.8$/0!4'*34!XSl[ ! N#3!5.=!/*/!#2!*)3!c3W
- 139. /E)73*5#*@*)$- !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* 97*%#2*-'%$'!(.1'%)5'F1!'1):7+@%$/- 60-'37+E'0%-'D**)':2)5*5'D='$0*':773)#'#+%)$- !6'3263!=#82/*'#2!730/2!823!O/2*!U#9!=7H,DH1H7SRD, !=]H7ji+,,9K9K!j51]
- 140. !#$%'()$*+,+-*'.*-*%+/0'1)-$$2$* 33345*+4* 60%)E-G H2*-$7)-I 0$$,JKK-*@%)$/L5+2,%4/7@K