How to migrate from any CMS (thru the front-door)
2 likes1,370 views

The document outlines an Adobe developer event focused on migrating content management systems (CMS) to AEM, led by Chris Rockwell from the University of Michigan. It discusses the challenges of database migrations, the use of frontend tools for automation, and provides detailed information on using programming tools like Cucumber and Capybara for testing migrations. It concludes with a demonstration of techniques for successfully migrating content from legacy systems and resources for further reference.







![Example Code - Step Definition
Given /^the profile page (.*)$/ do | url |!
visit url !
end!
!
Given /^profiles should migrate into these dept categories:$/ do |table|!
@peopleDeptCat = table.raw!
@peopleHash = Hash[@peopleDeptCat.map {|key, value, v2| [key, [value, v2]]}]!
!
@phone = find("#phone", :visible => false).value!
@imageURI = find(".peopleImg")[:src]!
@education = find("#education").all('li').collect(&:text) !
!
curlAuthenticate(@profilePath)!
buildJsonContent!
postContent(@peoplePath, @categoryHash) # create category page!
postContent(@categoryPath, @profileHash) # create profile!
….!
@c.close!
end!
!
The
Capybara
gem
provides
convenient
ways
to…
• Drive
Selenium,
visit
url
• Get
content
from
the
page,
find(".peopleImg")[:src]
A
Data
Table
is
passed
in
from
Cucumber
lisOng
email,
department
and
category.
This
extra
informaOon
is
used
to
create
the
new
paths
for
the
migrated
pages.](https://image.slidesharecdn.com/u-mmigration-150811165155-lva1-app6892/85/How-to-migrate-from-any-CMS-thru-the-front-door-10-320.jpg)




How to migrate from any CMS (thru the front-door)
- 1. CIRCUIT – An Adobe Developer Event Presented by ICF Interactive How to migrate any CMS through the front door
- 2. Agenda • About @rockwell105 – Recent Experiences in Content Migration • A process for any CMS • Frontend Tools • Example Code – Cucumber / Step-Definition using Capybara – LSA Department Profile Pages • Demonstration • Summary / Questions – Resources & References
- 3. About Me Chris Rockwell – University of Michigan, LSA • College of Literature, Science and the Arts, Web Services – Technical Lead on AEM project – Neither software consultant nor database expert • API User; Java, Ruby and Frontend – Recent Experience • Database Migration from OpenText • R2Integrated did a great job in migrating our SQL database to AEM – Java classes calling SQL Stored Procedures and creating the content in the JCR – We also used frontend techniques, which I want to talk about today
- 4. Querying the Database Why database migra/ons can be difficult -‐ Requires skills in both systems -‐ Source CMS and target AEM -‐ Source DB table names are like … -‐ vgnAsAtmyContentChannel? -‐ vgnAsAtmyContentObjRef? -‐ Rela/onships between the tables were unclear -‐ In our case, no foreign keys -‐ Legacy system customiza/ons may not be well understood or documented What about the Legacy system API? Or Screen Scraping?
- 5. Migrate ANY CMS HTML CSS JS WordPress AEM OpenText Joomla Drupal MediaWiki Magnolia AssumpOon: Every Web CMS that places content in HTML templates, which provide a consistent HTML Document structure. Template Mapping Old system to New system Group URL’s by template group For each group idenOfy extra informa/on needed to migrate properly
- 6. Data / Screen Scaping hGps://en.wikipedia.org/wiki/Data_scraping “Data scraping is generally considered an ad hoc, inelegant technique, o2en used only as a "last resort" when no other mechanism for data interchange is available. Aside from the higher programming and processing overhead, output displays intended for human consump>on o2en change structure frequently.” For us, some content was much easier (and more fun) to automate a browser and get the content from the frontend. Why it this easier? -‐ Content is consolidated on the page -‐ No reverse engineering of messy legacy systems -‐ Knowledge of the DOM can be used to get content using CSS selectors -‐ Consistent HTML template structure provided by the legacy system -‐ UAT fails if the migraOng URL does not meet assumpOons
- 7. Data / Screen Scaping Other reasons to do this -‐ Going aYer business with no access to the database (POC) -‐ Can be done quickly without knowledge about the legacy system -‐ Can be done in phases (migrates based URL’s listed) -‐ Works against live websites (not stale database snapshots)
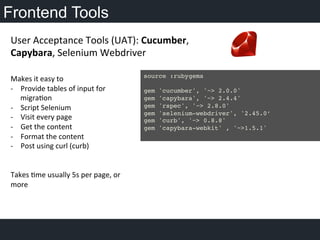
- 8. Frontend Tools Makes it easy to -‐ Provide tables of input for migraOon -‐ Script Selenium -‐ Visit every page -‐ Get the content -‐ Format the content -‐ Post using curl (curb) Takes Ome usually 5s per page, or more User Acceptance Tools (UAT): Cucumber, Capybara, Selenium Webdriver source :rubygems! ! gem 'cucumber', '~> 2.0.0'! gem 'capybara', '~> 2.4.4'! gem 'rspec', '~> 2.8.0'! gem 'selenium-webdriver', '2.45.0’! gem 'curb', '~> 0.8.8'! gem 'capybara-webkit' , '~>1.5.1'! !
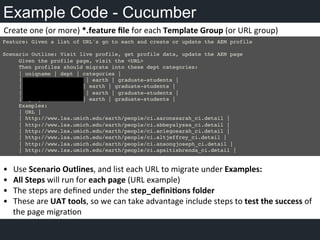
- 9. Example Code - Cucumber Feature: Given a list of URL's go to each and create or update the AEM profile! ! Scenario Outline: Visit live profile, get profile data, update the AEM page ! !Given the profile page, visit the <URL> ! !Then profiles should migrate into these dept categories:! !| uniqname | dept | categories | !! !| [email protected] | earth | graduate-students | ! !| [email protected] | earth | graduate-students | ! !| [email protected] | earth | graduate-students | ! !| [email protected] | earth | graduate-students |! !Examples:! !| URL | ! !| http://www.lsa.umich.edu/earth/people/ci.aaronssarah_ci.detail |! !| http://www.lsa.umich.edu/earth/people/ci.abbeyalyssa_ci.detail |! !| http://www.lsa.umich.edu/earth/people/ci.aciegosarah_ci.detail |! !| http://www.lsa.umich.edu/earth/people/ci.altjeffrey_ci.detail |! !| http://www.lsa.umich.edu/earth/people/ci.ansongjoseph_ci.detail |! !| http://www.lsa.umich.edu/earth/people/ci.apsitisbrenda_ci.detail | ! • Use Scenario Outlines, and list each URL to migrate under Examples: • All Steps will run for each page (URL example) • The steps are defined under the step_defini/ons folder • These are UAT tools, so we can take advantage include steps to test the success of the page migraOon Create one (or more) *.feature file for each Template Group (or URL group)
- 10. Example Code - Step Definition Given /^the profile page (.*)$/ do | url |! visit url ! end! ! Given /^profiles should migrate into these dept categories:$/ do |table|! @peopleDeptCat = table.raw! @peopleHash = Hash[@peopleDeptCat.map {|key, value, v2| [key, [value, v2]]}]! ! @phone = find("#phone", :visible => false).value! @imageURI = find(".peopleImg")[:src]! @education = find("#education").all('li').collect(&:text) ! ! curlAuthenticate(@profilePath)! buildJsonContent! postContent(@peoplePath, @categoryHash) # create category page! postContent(@categoryPath, @profileHash) # create profile! ….! @c.close! end! ! The Capybara gem provides convenient ways to… • Drive Selenium, visit url • Get content from the page, find(".peopleImg")[:src] A Data Table is passed in from Cucumber lisOng email, department and category. This extra informaOon is used to create the new paths for the migrated pages.
- 11. Example Code- Sling Post Servlet def buildJsonContent! @profileHash = {! "jcr:primaryType"=> "cq:Page",! @uniqueName =>{! "jcr:primaryType"=> "cq:Page", ! "jcr:content"=> {! "jcr:primaryType"=> "cq:PageContent",! ! "officeLocation"=> "#{@officeLocation}",! "jcr:title"=> "#{@firstName} #{@lastName}",! "website1"=> "#{@url}",! "website2"=> "#{@url2}",! "lastName"=> "#{@lastName}",! "cq:template"=> "/apps/sweet-aem-project/templates/department_person_profile",! "officeHours"=> "#{@officeHours}",! "fileName"=> "#{@cvFileName.match(/w*.w{3,4}$/) if [email protected]?}", #! "education"=> @education || "",! "about"=> "#{@about}",! "phone"=> "#{@phone.gsub(/<br>/,', ') if [email protected]?}",! "title"=> "#{@title.gsub(/<br>/,'; ') if [email protected]?}", ! "firstName"=> "#{@firstName}",! "uniqueName"=> "#{@uniqueName}",! "hideInNav"=> "true",! "sling:resourceType"=> "sweet-aem-project/components/pages/department_person_profile",! "cq:designPath"=> "/etc/designs/sweet-aem-project",! "profileImage"=> {! "jcr:primaryType"=> "nt:unstructured",! "sling:resourceType"=> "foundation/components/image",! "imageRotate"=> "0",! },! }! }! } ! Step Defini/on Overview Visit the page, Get the content. Build nested hash(es), which convert nicely to JSON Use *.infinity.json on example content. Use this as a starOng point for the nested hash. def postContent(jcrPath, contentHash)! @c.url = jcrPath! @c.on_success {|easy| puts "ON SUCCESS #{easy.response_code}"}! @c.on_failure {|easy| fail easy.to_s}! @c.http_post("#{jcrPath}", ! Curl::PostField.content(':operation', 'import'),! Curl::PostField.content(':contentType', 'json'),! Curl::PostField.content(':replaceProperties', 'true'),! Curl::PostField.content(':content', contentHash.to_json))! puts "FINISHED: HTTP #{@c.response_code}"! end ! Step Defini/on Overview (cont.) Post JSON to the desired path using :opera/on import The JSON contains a structure needed for the page in AEM containing properOes needed; jcr:primaryType, cq:template, sling:resourceType content hash example
- 12. Legacy System AEM System OperaOon Import SlingPostServlet Wrap-up Demo Questions
- 13. • Several options for Content Migration – Scraping webpages is one option to consider – :operation import is great • Ways to speed up frontend migration – Scale migration across machines using Selenium Grid to launch parallel operations – Use a headless browser Questions Wrap-up Demo
- 14. Resources / References Sling docs haps://sling.apache.org/documentaOon/bundles/manipulaOng-‐content-‐the-‐slingpostservlet-‐ servlets-‐post.html#imporOng-‐content-‐structures U-‐M Demo Project haps://bitbucket.org/cmrockwell/cukescrape Ruby Gems hap://bundler.io/ haps://github.com/jnicklas/capybara haps://github.com/cucumber/cucumber haps://github.com/taf2/curb Selenium Webdriver hap://www.seleniumhq.org/projects/webdriver/ hap://www.seleniumhq.org/docs/07_selenium_grid.jsp Wrap-up Questions Demo