Hypergraph for consensus optimization
2 likes499 views

Describes efficient way to implement graph-parallel computing by partitioning graph edges among computing nodes. From IEEE BigData 2013.















































More Related Content
What's hot (9)
Similar to Hypergraph for consensus optimization (20)







Recently uploaded (20)




















Hypergraph for consensus optimization
- 1. Vertex programming for bipartite graphs H Miao, X Liu, B Huang, and L Getoor (2013), “A hypergraph- partitioned vertex programming approach for large-scale consensus optimization.” IEEE BigData 2013. Presented by Hershel Safer in Machine Learning :: Reading Group Meetupin Machine Learning :: Reading Group Meetup on 13/11/13 Vertex programming for bipartite graphs – Hershel Safer Page 113 November 2013
- 2. Outline The setting The problem A solution An application and improvement Vertex programming for bipartite graphs – Hershel Safer Page 213 November 2013
- 3. The MapReduce model for processing Big Data The data-parallel paradigm • Map: Many computers process subproblems in parallel • Reduce: Master computer combines subproblem solutions into overall solution Appropriate for embarrassingly parallel problems with independent subproblemsindependent subproblems Does not support computational dependencies between subproblems Does not naturally support iteration Vertex programming for bipartite graphs – Hershel Safer Page 313 November 2013
- 4. Graph-parallel computation for machine learning (ML) Many ML algorithms are iterative, have dependencies Many ML algorithms are expressed naturally on graphs • Vertices represent subproblems • Edges represent computational dependencies GraphLab and Pregel express iterative algorithms with sparse dependencies for implementation on multiple computersdependencies for implementation on multiple computers • Algorithm designer defines computation at each vertex and information exchange on each edge, for each iteration • Package handles mapping of vertices to computers, details of inter-computer communication, and scheduling • Package guarantees data consistency (various models possible) and correctness as compared to serial execution Vertex programming for bipartite graphs – Hershel Safer Page 413 November 2013
- 5. Outline The setting The problem A solution An application and improvement Vertex programming for bipartite graphs – Hershel Safer Page 513 November 2013
- 6. The graph-parallel computing model Sparse graph G = (V, E) Vertex program Q(v), executed in parallel on each vertex v Q(v) can interact with Q(u) for each neighboring vertex u (i.e., (u,v) is an edge of E) Interaction (communication) is via messages or shared state • Vertex information is available to all neighbors• Vertex information is available to all neighbors • Edge information is available to the two adjacent vertices Vertex programming for bipartite graphs – Hershel Safer Page 613 November 2013
- 7. Phases of a vertex program Q: GAS model For each vertex v, iterate these steps (in parallel for all vertices): • Gather: Collect information from neighboring vertices and edges • Apply: Do the local computation and update the local data • Scatter: Update the data on the adjacent edges Vertex programming for bipartite graphs – Hershel Safer Page 713 November 2013
- 8. Implementing efficient graph-parallel computing Use a balanced p-way edge cut to partition vertices more-or-less evenly among the computers to take advantage of parallelism. Communication between vertices u and v is cheap if they are on the same computer, expensive otherwise Gonzalez 2012 the same computer, expensive otherwise If edge (u,v) spans computers, a ghost copy of u is kept on v’s computer and vice versa. Changes to u and v are synchronized across the computer network to all ghost copies. So: Partition vertices so that most neighbors are on the same computer. This is easiest if most vertices have small degree (neighborhood). Vertex programming for bipartite graphs – Hershel Safer Page 813 November 2013
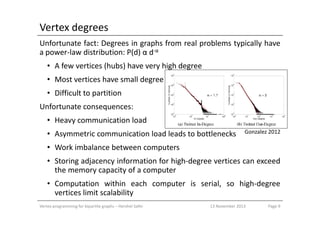
- 9. Vertex degrees Unfortunate fact: Degrees in graphs from real problems typically have a power-law distribution: P(d) α d-α • A few vertices (hubs) have very high degree • Most vertices have small degree • Difficult to partition Unfortunate consequences: • Heavy communication load • Asymmetric communication load leads to bottlenecks • Work imbalance between computers • Storing adjacency information for high-degree vertices can exceed the memory capacity of a computer • Computation within each computer is serial, so high-degree vertices limit scalability Vertex programming for bipartite graphs – Hershel Safer Page 913 November 2013 Gonzalez 2012
- 10. Outline The setting The problem A solution An application and improvement Vertex programming for bipartite graphs – Hershel Safer Page 1013 November 2013
- 11. Breaking the bottleneck: Edge partitioning via vertex cut Instead of partitioning the vertices, use a balanced p-way vertex cut to partition the edges more-or-less evenly among the computers. Vertices, rather than edges, span computers. A vertex with many edges may be replicated on multiple computers. One copy is the master; the Gonzalez 2012 may be replicated on multiple computers. One copy is the master; the rest are mirrors, containing read-only copies of vertex data. Changes to vertices are synchronized across the network. PowerGraph vertex cut formalism: Vertex programming for bipartite graphs – Hershel Safer Page 1113 November 2013 Gonzalez 2012
- 12. Properties of edge partitioning via vertex cut The objective minimizes the average number of replicas, and hence the total storage and network-communication cost. The vertex cut addresses the major issues of the edge cut: work balance, network communication, and communication bottlenecks are improved even in the presence of high-degree vertices. PowerGraph paper describes several way to implement partitioning, including random and greedy assignments Vertex programming for bipartite graphs – Hershel Safer Page 1213 November 2013
- 13. Outline The setting The problem A solution An application and improvement Vertex programming for bipartite graphs – Hershel Safer Page 1313 November 2013
- 14. Consensus optimization and ADMM Consensus optimization decomposes a complex problem into a collection of simpler problems using local variables, and constraining local copies of the variables to be equal to a global consensus variable. Alternating Direction Method of Multipliers (ADMM) is an optimization Miao 2013 Alternating Direction Method of Multipliers (ADMM) is an optimization method that iterates two phases. Although not new, it has gained recent popularity because it can be used for distributed solution of large-scale optimization problems. Vertex programming for bipartite graphs – Hershel Safer Page 1413 November 2013
- 15. Consensus optimization using ADMM ADMM is useful for consensus optimization when the dual problem can be decomposed into simple, independent subproblems. Solve them in parallel in one phase, combine subproblem solutions in the second phase, and iterate. Miao 2013 The graph for solving consensus optimization problems has two kinds of vertices and a bipartite structure. • Subproblem: Calculating x and λ • Consensus: Calculating consensus variables X After a subproblem vertex finishes computing, it transmits results to relevant consensus vertices, & vice versa. This leads to emergent two- phase behavior. Vertex programming for bipartite graphs – Hershel Safer Page 1513 November 2013 Miao 2013
- 16. PowerGraph edge partitioning is not good for ADMM Greedy edge partitioning does not work well for bipartite graphs, such as those used for consensus optimization with ADMM • Consensus vertices tend to have much higher degree than subproblem vertices. As a result, subproblem vertices tend to get replicated by the PowerGraph vertex-cut methods. • Subproblem vertices perform much heavier computations that do consensus vertices, so replicating the former is not desirable. Solution: Split only consensus vertices, not subproblem vertices Vertex programming for bipartite graphs – Hershel Safer Page 1613 November 2013
- 17. A hypergraph formulation for vertex cut Main contribution of this paper: Splitting the consensus vertices with a constraint for balanced edge placement corresponds to Solving a hyperdge cut problem with a similar constraint in the hypergraph H(VS, EC), where VS is the set of subproblem vertices and EC is a set of hyperedges, where hyperedge ej ε EC is the set of allEC is a set of hyperedges, where hyperedge ej ε EC is the set of all subproblems related to consensus variable j. Solve using available hypergraph analysis packages They report substantial improvements in replication factor and running time compared to PowerGraph strategies for edge partitions Vertex programming for bipartite graphs – Hershel Safer Page 1713 November 2013
- 18. References Hypergraph-partitioned vertex programming • H. Miao et al., IEEE BigData 2013 • H. Miao et al., Univ. Maryland tech report, 2013 ADMM • J. Eckstein, RUTCOR research report, 2012 • S. Boyd, Foundations & Trends in Machine Learning, 3 (2010), p. 1• S. Boyd, Foundations & Trends in Machine Learning, 3 (2010), p. 1 GraphLab • Y. Low, Uncertainty in Artificial Intelligence 2010 • Y. Low, VLDB 5:8 (2012) • J. Gonzalez, USENIX OSDI 2012 Vertex programming for bipartite graphs – Hershel Safer Page 1813 November 2013