Image Retrieval Overview (from Traditional Local Features to Recent Deep Learning Approaches)
Download as PPTX, PDF24 likes13,202 views

30分で画像検索の全てが分かるを目指して作成した(やっつけ)資料です。なお発表時間は足りなかった模様。











![RootSIFT [Arandjelovic+, CVPR’12]
4/16/2018 12
• Hellinger kernel works better than Euclidean distance
in comparing histograms such as SIFT
• Hellinger kernel (Bhattacharyya’s coefficient) for L1
normalized histograms x and y:
• Explicit feature map of x into x’ :
– L1 normalize x
– element-wise square root x to give x’
– then x’ is L2 normalized
• Computing Euclidean distance in the feature map
space is equivalent to Hellinger distance in the
original space:
RootSIFT
RootSIFT](https://image.slidesharecdn.com/imageretrievaloverview-180416040909/85/Image-Retrieval-Overview-from-Traditional-Local-Features-to-Recent-Deep-Learning-Approaches-13-320.jpg)

![Bag-of-Visual Words [Sivic+, ICCV’03]
4/16/2018 14
• Offline
– Collect a large number of training vectors
– Perform clustering algorithm (e.g., k-means)
– Centroids of clusters = visual words (VWs)
• Online:
– All features are assigned to their nearest visual words
– An image is represented by the frequency histogram of VWs
– (Dis)similarity is defined by the distance between histograms
Visual words (VW)
VW1
VWn
VW2
…
Visual words
-
-
・
・・
-
-
-
・・
・-
-
-
・・
・-
-
-
・
・・
-
-
-
・・
・
-
Frequency
}1|{ Nii vV](https://image.slidesharecdn.com/imageretrievaloverview-180416040909/85/Image-Retrieval-Overview-from-Traditional-Local-Features-to-Recent-Deep-Learning-Approaches-15-320.jpg)
![Bag-of-Visual Words [Sivic+, ICCV’03]
4/16/2018 1515
VW1
VW2
VWk
VWn
・
・
・
・
・
・
Indexing step
(quantization)
Search step
(quantization)
Match
Match
Matching can be performed in O(1)
with an inverted index
Query
image
Reference
images
Nearest VW](https://image.slidesharecdn.com/imageretrievaloverview-180416040909/85/Image-Retrieval-Overview-from-Traditional-Local-Features-to-Recent-Deep-Learning-Approaches-16-320.jpg)




![Weak Geometric Consistency [Jegou+, ECCV’08]
4/16/2018 20
• スケール比、角度差はconsistentなので
角度差、スケール比空間にハフ変換的に投票する
– 正解はスコアが下がらないが不正解ペアのスコアが大
きく下がる](https://image.slidesharecdn.com/imageretrievaloverview-180416040909/85/Image-Retrieval-Overview-from-Traditional-Local-Features-to-Recent-Deep-Learning-Approaches-21-320.jpg)


![Average Query Expansion [Chum+, ICCV’07]
4/16/2018 23
• Obtain top (m < 50) verified results of original query
• Construct new query using average of these results
Without geometric verification,
QE degrades accuracy!
Query image
Verified results
New query](https://image.slidesharecdn.com/imageretrievaloverview-180416040909/85/Image-Retrieval-Overview-from-Traditional-Local-Features-to-Recent-Deep-Learning-Approaches-24-320.jpg)
![Multiple Image Resolution Expansion [Chum+, ICCV’07]
4/16/2018 24
ROI
Query image
ROI
ROIROI
ROI
ROI
ROI
First verified results
ROI
ROI
ROI
ROI
ROI
ROI
• Calculate relative change in resolution
• Construct average query for each resolution
New query1 New query2 New query3](https://image.slidesharecdn.com/imageretrievaloverview-180416040909/85/Image-Retrieval-Overview-from-Traditional-Local-Features-to-Recent-Deep-Learning-Approaches-25-320.jpg)

![Discriminative Query Expansion [Arandjelovic+, CVPR’12]
4/16/2018 26
• Train a linear SVM classifier
– Use verified results as positive training data
– Use low ranked images as negative training data
– Rank images on their signed distance from the decision
boundary
– Reranking can be efficient with an inverted index!](https://image.slidesharecdn.com/imageretrievaloverview-180416040909/85/Image-Retrieval-Overview-from-Traditional-Local-Features-to-Recent-Deep-Learning-Approaches-27-320.jpg)










![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=560&fit=bounds)




![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=560&fit=bounds)

![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=560&fit=bounds)
![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=560&fit=bounds)

![[DL輪読会]Few-Shot Unsupervised Image-to-Image Translation](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminarfunit-190517005148-thumbnail.jpg?width=560&fit=bounds)


![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=560&fit=bounds)

![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=560&fit=bounds)

![[DL輪読会]Recent Advances in Autoencoder-Based Representation Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20190119dljournalclubweb-190401063633-thumbnail.jpg?width=560&fit=bounds)




![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=560&fit=bounds)

![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=560&fit=bounds)


Ad
More Related Content
What's hot (20)
Similar to Image Retrieval Overview (from Traditional Local Features to Recent Deep Learning Approaches) (14)









![[DL輪読会]Collective dynamics of repeated inference in variational autoencoder r...](https://cdn.slidesharecdn.com/ss_thumbnails/20201113dlcollectivedynamicsofrepeatedinferenceinvariationalautoencoderrapidlyfindclusterstructureve-201117021533-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=560&fit=bounds)

Ad
More from Yusuke Uchida (20)




















Ad
Image Retrieval Overview (from Traditional Local Features to Recent Deep Learning Approaches)
- 2. 特定物体認識 1 • 類似画像検索 • 一般物体認識 (クラス分類) • 特定物体認識 同じ物体(インスタンス)が写っている画像を検出 ResultQuery Query 空、雲 ResultQuery 大規模特定物体認識の最新動向 https://sites.google.com/site/yu4uchida/uchida_ieice2013.pdf
- 3. 大域特徴ベース vs 局所特徴ベース 2 • 大域特徴 (global feature) ベース – 画像から1つの特徴を抽出(e.g. カラーヒストグラム) – 類似画像検索ではうまくいくが 特定物体認識ではうまくいかない • 局所特徴 (local feature) ベース – 画像から多数の局所特徴を抽出(e.g. SIFT) – それらのマッチング結果により類似度を定義 – SIFT等の強力な特徴量により deep learningに最後まで抵抗(最近やられた模様)
- 4. 大域特徴ベース vs 局所特徴ベース 3 • 大域特徴で検索 • 局所特徴で検索 • 局所特徴をaggregateして大域特徴にして検索 – FV, VLAD
- 5. 局所特徴ベース特定物体認識 4 • Detection:局所特徴領域の検出 • Description:局所特徴領域の記述 • Indexing&Search:(近似)最近傍探索 • Post process – Geometric verification – Query expansion セットになることが多いが 本来は独立して選択できる
- 6. 局所特徴を用いた特定物体認識 4/16/2018 5 ①Extract local regions (patches) from images ②Describe the patches by d-dimensional vectors ③Make correspondences between similar patches ④Calculate similarity between the images Similarity: 3 Position (x, y) Orientation θ Scale σ Feature vector f (e.g., 128-dim SIFT) Local feature
- 7. 局所特徴領域の検出手法 6 • Blobタイプとコーナータイプ • 回転不変、スケール不変、アフィン不変 とタイプ分けされる • 基本的なアイディア= 畳み込みフィルタの応答の極大値により検出
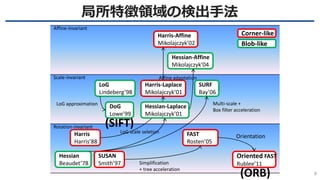
- 10. 局所特徴領域の検出手法 9 Hessian Beaudet’78 Harris Harris’88 LoG Lindeberg’98 DoG Lowe’99 SURF Bay’06 Harris-Laplace Mikolajczyk’01 Hessian-Affine Mikolajczyk’04 Harris-Affine Mikolajczyk’02 FAST Rosten’05 Affine-invariant Scale-invariant Rotation-invariant LoG scale seletion Affine adaptation Multi-scale + Box filter acceleration LoG approximation Hessian-Laplace Mikolajczyk’01 Oriented FAST Rublee’11 SUSAN Smith’97 Simplification + tree acceleration Orientation Corner-like Blob-like (SIFT) (ORB)
- 11. 局所特徴領域の記述手法 10 • 実数値タイプとバイナリタイプがある SIFT Lowe’99 SURF Bay’06 BRIEF Calonder’10 ORB Rublee’11 GLOH Mikolajczyk’05 FREAK Alahi’12 A-KAZE Alcantarilla’13 LDB Yang’12 LATCH Levi’16 BRISK Leutenegger’11 Real-valued Binary (0.56, 0.22, -0.10, …, 0.96) (1, 0, 0, …, 1) RootSIFT Arandjelovic’12
- 12. どれを使えば良いの? 11 • 精度重視 – SIFT or Hessian Affine detector + RootSIFT descriptor • 速度重視 – ORB detector + ORB descriptor • Local Feature Detectors, Descriptors, and Image Representations: A Survey https://arxiv.org/abs/1607.08368
- 13. RootSIFT [Arandjelovic+, CVPR’12] 4/16/2018 12 • Hellinger kernel works better than Euclidean distance in comparing histograms such as SIFT • Hellinger kernel (Bhattacharyya’s coefficient) for L1 normalized histograms x and y: • Explicit feature map of x into x’ : – L1 normalize x – element-wise square root x to give x’ – then x’ is L2 normalized • Computing Euclidean distance in the feature map space is equivalent to Hellinger distance in the original space: RootSIFT RootSIFT
- 14. Large-scale Object Recognition 4/16/2018 13 ・ ・ ・ Distance calculation Query image Reference images Explicit feature matching requires high computational cost and memory footprint Match Bag-of-visual words!
- 15. Bag-of-Visual Words [Sivic+, ICCV’03] 4/16/2018 14 • Offline – Collect a large number of training vectors – Perform clustering algorithm (e.g., k-means) – Centroids of clusters = visual words (VWs) • Online: – All features are assigned to their nearest visual words – An image is represented by the frequency histogram of VWs – (Dis)similarity is defined by the distance between histograms Visual words (VW) VW1 VWn VW2 … Visual words - - ・ ・・ - - - ・・ ・- - - ・・ ・- - - ・ ・・ - - - ・・ ・ - Frequency }1|{ Nii vV
- 16. Bag-of-Visual Words [Sivic+, ICCV’03] 4/16/2018 1515 VW1 VW2 VWk VWn ・ ・ ・ ・ ・ ・ Indexing step (quantization) Search step (quantization) Match Match Matching can be performed in O(1) with an inverted index Query image Reference images Nearest VW
- 17. 1 2 w N Inverted index Image ID 1 2 3 4 5 6 7 8 9 10 11 12 ... Image ID Accumulated scores VW ID Obtain image IDs Query image Reference image Image ID ...(x, y) σ θ (1) Feature detection (2) Feature description (3) Quantization (1) Feature detection (2) Feature description (3) Quantization (4) Voting ... ... ... ... Visual word v1 ... Visual word vw ... Visual word vN Visual words 1 4 5 7 10 16 19 Offline step Visual word v1 ... Visual word vw ... Visual word vN Visual words Get images with the top-K scores Results inlier outlier (5) Geometric verification 全体処理 Geometric verification
- 18. Geometric (Spatial) Verification 17 • マッチングした結果には誤検出が含まれる – 正解のマッチング(inlier)はある幾何的な変換モデルに対して 整合性が取れているはずなので、 モデルの推定とinlierの同定を同時に行う→RANSAC – inlierのみを用いて画像間の 類似度とすると精度が向上 outlier inlier
- 19. モデル; p’ = Mp 18 rotation scalingtranslation similarity trans. affine trans. perspective trans. 1DoF 2DoF 1DoF 4DoF 5DoF 6DoF 7DoF Fundamental Matrix
- 20. RANSAC 19 1. モデルパラメータを計算できる対応点をランダム サンプリング 2. モデルパラメータを算出 3. 全ての点対応で、上記のモデルパラメータと整合 する点対応をinlierとみなす 4. 上記を一定回数繰り返し、一番inlierが多かった モデルパラメータを採用
- 21. Weak Geometric Consistency [Jegou+, ECCV’08] 4/16/2018 20 • スケール比、角度差はconsistentなので 角度差、スケール比空間にハフ変換的に投票する – 正解はスコアが下がらないが不正解ペアのスコアが大 きく下がる
- 22. どのモデルを使えばよいの? 21 • とりあえず相似変換かアファイン変換 ←対象から離れていれば大体相似変換で近似可能 • スケールと角度がある特徴領域だと 1つの対応点から相似変換が求まる! →全ペアに対してモデル推定+inlier算出をする • その後、より自由度の大きいモデルをフィッティ ングしても良い J. Philbin et al., “Object retrieval with large vocabularies and fast spatial matching,” CVPR’17.
- 23. Query Expansion 22 • 最初の検索結果を元に、新たな検索クエリを人工 的に作成し、「芋づる式」に検索結果を改善する ことを狙う クエリ 検索結果 拡張クエリ 新たな検索結果
- 24. Average Query Expansion [Chum+, ICCV’07] 4/16/2018 23 • Obtain top (m < 50) verified results of original query • Construct new query using average of these results Without geometric verification, QE degrades accuracy! Query image Verified results New query
- 25. Multiple Image Resolution Expansion [Chum+, ICCV’07] 4/16/2018 24 ROI Query image ROI ROIROI ROI ROI ROI First verified results ROI ROI ROI ROI ROI ROI • Calculate relative change in resolution • Construct average query for each resolution New query1 New query2 New query3
- 26. Query Expansion Results 4/16/2018 25 • ori = original query • qeb = query expansion baseline • trc = transitive closure expansion • avg = average query expansion • rec = recursive average query expansion • sca = multiple image resolution expansion
- 27. Discriminative Query Expansion [Arandjelovic+, CVPR’12] 4/16/2018 26 • Train a linear SVM classifier – Use verified results as positive training data – Use low ranked images as negative training data – Rank images on their signed distance from the decision boundary – Reranking can be efficient with an inverted index!
- 28. Aggregation Methods 27 • 局所特徴は1画像から1000前後抽出される • 画像が多いとインデックスが肥大化 • 特に画像認識では1つのベクトルとして扱いたい – Fisher Vector (FV) – VLAD • 精度を求める場合は使わない
- 29. 最近傍探索 (Nearest Neighbor Search, NNS) 28 • 距離空間 M における点の集合 S とクエリ点 q∈M が 与えられた際に S の中で q に最も近い点を探す – k近傍 / range search • ユークリッド空間での最近傍探索を扱うことがほとんど • kd-tree, SR-tree等のindexingにより高速化 (高次元(数十?)で次元の呪いにかかる) + + + ++ + + + + + + + o q Input + + + ++ + + + + + + + o q Output S
- 30. 近似最近傍探索 29 • エラーを許す代わりに高速化、エラー率とトレードオフ – 速度、精度、メモリ使用量がトレードオフになる • 木構造+priority search – kd-tree, randomized kd-trees, hierarchical kd-tree – メモリを気にしなければ無難で良い • Locality Sensitive Hashing (LSH) 系 – ***LSHがいっぱい。個人的には嫌い • 直積量子化系 – サーベイ → https://www.jstage.jst.go.jp/article/mta/6/1/6_2/_article/-char/ja/ – データを圧縮し、圧縮したまま検索 • バイナリ圧縮系 – いっぱいある https://www.slideshare.net/ren4yu/k-means-hashing-up (Heさんだよ) – バイナリ符号にするのでpopcnt命令で距離計算できる (がそのままだとlinear search)
- 32. CNN系 (global feature) 31 • CNN Features off-the-shelf: an Astounding Baseline for Recognition https://arxiv.org/abs/1403.6382 – クラス分類用のCNN (OverFeat) のFCをそのまま使っても結構良い • Neural Codes for Image Retrieval https://arxiv.org/pdf/1404.1777.pdf – 最終層前のFCを使ったほうが良いとか、検索対象のドメインで finetuneしたほうが良いとか • CNN Image Retrieval Learns from BoW: Unsupervised Fine- Tuning with Hard Examples https://arxiv.org/abs/1604.02426 – Siamese Networkで学習 • Global featureでもかなり良い(vs. FV/VLAD) • 基本的に回転・スケール不変ではないことに注意
- 33. CNN系 (local feature) 32 • LIFT: Learned Invariant Feature Transform https://arxiv.org/abs/1603.09114 – 検出、角度推定、記述をend-to-endで学習 – 遅いし検索では精度出ていない • Large-Scale Image Retrieval with Attentive Deep Local Features https://arxiv.org/abs/1612.06321 – FCN+アテンション(マルチスケールでやる)で局所特徴を定義 – 良さげ https://github.com/tensorflow/models/tree/master/researc h/delf – 回転不変性は担保されない
- 34. DELF 33
- 35. Comparative Study 34 • Revisiting Oxford and Paris: Large-Scale Image Retrieval Benchmarking https://arxiv.org/abs/1803.11285 – Local, global, CNN/非CNNが網羅的に比較されている (が、著者らのチームにバイアスがかかっているかも) Local Global 非CNN CNN
- 36. ベストプラクティス① 35 • Global → https://arxiv.org/abs/1711.02512 – 性能の良いベースネットワークを利用(ResNet以上) し、finetune(Siamere?)する – generalized mean-pooling (Lp, p=3) を利用 – 複数スケール (region) を利用 – RegionレベルでDiffusionベースのquery expansion https://arxiv.org/abs/1611.05113
- 37. ベストプラクティス② 36 • Local → https://hal.inria.fr/hal-01131898/document – 特徴量としてはDELFを利用 – Indexing, matching, scoringがややこしい(ASMK – Geometric verificationは必須 – Query expansionもやる
Editor's Notes
- #12: Arandjelovic