Indic threads pune12-accelerating computation in html 5
Download as PPTX, PDF1 like1,212 views

The 7th Annual IndicThreads Pune Conference was held on 14-15 December 2012. http://pune12.indicthreads.com/






![Example of adding two vectors
Serial version
For(i=1 to n)
c[i]= a[i]+b[i];
Using OpenCL
_kernel add(a,b,c)
{
int i =get_global_id(); //get thread id
c[i]=a[i]+b[i];
}](https://image.slidesharecdn.com/indicthreads-pune12-acceleratingcomputationinhtml5-121217123118-phpapp02/85/Indic-threads-pune12-accelerating-computation-in-html-5-8-320.jpg)


![OpenCL-Execution Model
_kernel add(a,b,c)
1. Kernel {
2. Work-items int i =get_global_id();//get thread/workitem id
c[i]=a[i]+b[i];
3. Work group }
4. ND-range
5. Program
6. Memory
objects
7. Command
queues](https://image.slidesharecdn.com/indicthreads-pune12-acceleratingcomputationinhtml5-121217123118-phpapp02/85/Indic-threads-pune12-accelerating-computation-in-html-5-11-320.jpg)









![Coding with WebCL
platforms = WebCL.getPlatformIDs();
context = WebCL.createContextFromType([WebCL.CL_CONTEXT_PLATFORM,
platforms[0]], WebCL.CL_DEVICE_TYPE_CPU);
devices = context .getContextInfo(WebCL.CL_CONTEXT_DEVICES);
program = context .createProgramWithSource(kernelSrc);
kernelfunction1 = program.createKernel(“function1");
buffparam = context.createBuffer(WebCL.CL_MEM_READ_WRITE, bufSize);
cmdQueue = context.createCommandQueue(devices[0], 0);
cmdQueue.enqueueWriteBuffer(buffparam , true, 0, bufSize, parameter, []);
kernelfunction1.setKernelArg(0, buffparam , WebCL.types.float2);
cmdQueue.enqueueNDRangeKernel(kernelfunction1 , 1, [], totalWorkitems,
totalWorkgroups, []);
cmdQueue.finish ();
cmdQueue.enqueueReadBuffer(‘xyz’, true, 0, bufSize, ‘xyzParam’, []);](https://image.slidesharecdn.com/indicthreads-pune12-acceleratingcomputationinhtml5-121217123118-phpapp02/85/Indic-threads-pune12-accelerating-computation-in-html-5-22-320.jpg)


































Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to Indic threads pune12-accelerating computation in html 5 (20)




















Ad
More from IndicThreads (20)




















Indic threads pune12-accelerating computation in html 5
- 1. Accelerating computation in html 5 Ashish Shah SAS R&D INDIA
- 2. Outline • Multicore Computing • Problem statement • Demo • Introduction to OpenCL and WebCL • Conclusion • References
- 4. Problem statement Layout algorithm for node-linked graphs Layout Algorithm
- 5. DEMO Demo 1 – Serial version Demo 2 - Parallel version with multi-core CPU Demo 3 - Parallel version with many-core GPU
- 6. Performance analysis Time in ms Number of particles
- 7. Introduction to OpenCL • Open Compute Language, C- like language. • Framework for writing parallel algorithms • Heterogeneous platforms • Developed by Apple • Is an open standard and controlled by Khronos group
- 8. Example of adding two vectors Serial version For(i=1 to n) c[i]= a[i]+b[i]; Using OpenCL _kernel add(a,b,c) { int i =get_global_id(); //get thread id c[i]=a[i]+b[i]; }
- 9. OpenCL Architecture 1. Platform model 2. Execution model 3. Memory model 4. Programming model
- 10. OpenCL -Platform • Device • Host Host Intel CPU GPU 2 Compute Device 1 (GPU 1) Compute unite (Cores)
- 11. OpenCL-Execution Model _kernel add(a,b,c) 1. Kernel { 2. Work-items int i =get_global_id();//get thread/workitem id c[i]=a[i]+b[i]; 3. Work group } 4. ND-range 5. Program 6. Memory objects 7. Command queues
- 12. Memory Model in OpenCL Compute Device Private register Private register Private register Compute unit 0 Compute unit 1 Compute unit 2 Local memory/cache Local memory/cache Local memory/cache Global constant memory-DRAM Global Memory -DRAM
- 13. Programming model 1. Data parallel-single function on multiple data 2. Task parallel-Multiple functions on single data
- 14. OpenCL Stack Java,c,.net, HTML,.java, WebCL Applications .NET,c,c++ kernals OpenCL-Api Compiler String data context Memory Api’s OpenCL Framework OpenCL Runtime Command queues, buffer objects, kernel Device driver execution OpenCL Device (GPU/CPU hardware)
- 15. Essential Development Tasks C-code with restrictions Initialize Initiate Execute Read back Parallelize Code Kernel OpenCL kernels and kernel data to host environment data
- 16. Essential Development Tasks • Query compute device • Create context • Compile kernels Initialize Initiate Execute Read back Parallelize Code Kernel OpenCL kernels and kernel data to host environment data
- 17. Essential Development Tasks • Create memory objects • Map data structures to OpenCL supported data structures. • Initialize kernel parameters Initialize Initiate Execute Read back Parallelize Code Kernel OpenCL kernels and kernel data to host environment data
- 18. Essential Development Tasks • Specify number of threads to execute task • Trigger the execution of kernel- sync or async Initialize Initiate Execute Read back Parallelize Code Kernel OpenCL kernels and kernel data to host environment data
- 19. Essential Development Tasks • Map to application datastructure Initialize Initiate Execute Read back Parallelize Code Kernel OpenCL kernels and kernel data to host environment data
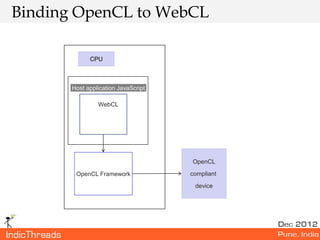
- 20. Introduction to WebCL • Java Script bindings for OpenCL • First announced in March 2011 by Khronos • API definition underway • Prototype plugin is available only for Firefox browser
- 21. Binding OpenCL to WebCL CPU Host application JavaScript WebCL OpenCL OpenCL Framework compliant device
- 22. Coding with WebCL platforms = WebCL.getPlatformIDs(); context = WebCL.createContextFromType([WebCL.CL_CONTEXT_PLATFORM, platforms[0]], WebCL.CL_DEVICE_TYPE_CPU); devices = context .getContextInfo(WebCL.CL_CONTEXT_DEVICES); program = context .createProgramWithSource(kernelSrc); kernelfunction1 = program.createKernel(“function1"); buffparam = context.createBuffer(WebCL.CL_MEM_READ_WRITE, bufSize); cmdQueue = context.createCommandQueue(devices[0], 0); cmdQueue.enqueueWriteBuffer(buffparam , true, 0, bufSize, parameter, []); kernelfunction1.setKernelArg(0, buffparam , WebCL.types.float2); cmdQueue.enqueueNDRangeKernel(kernelfunction1 , 1, [], totalWorkitems, totalWorkgroups, []); cmdQueue.finish (); cmdQueue.enqueueReadBuffer(‘xyz’, true, 0, bufSize, ‘xyzParam’, []);
- 23. Applications of OpenCL • Database mining • Neural networks • Physics based simulation,mechanics • Image processing • Speech processing • Weather forecasting and climate research • Bioinformatics
- 24. Conclusion • Significant performance gains in using OpenCL for computations in client-side environments like HTML5 • Algorithms need to be ‘parallelizable’ • Further optimizations can be achieved by exploiting memory model
- 25. Software/Hardware used in demo application Hardware Intel(R) Core(TM)2 Quad core CPU Q8400 @ 2.66GHz Nvidia 160m Quadro 8 cores @ 580 MHz Software OpenCL runtime for CPU http://software.intel.com/en-us/articles/vcsource- tools-opencl-sdk/ OpenCL runtime for GPU http://www.nvidia.com/object/quadro_nvs_notebook. html WebCL plugin for Firefox http://webcl.nokiaresearch.com/
- 26. References http://www.macresearch.org/opencl http://en.wikipedia.org/wiki/GPGPU http://www.khronos.org/webcl/
Editor's Notes
- #3: Html applications use multicores
- #4: What are multicores?Compare Cpu and GpuAdvantages of using GPUHow is it possible to do so.Moors lawSimple questions
- #5: -Explain network diagram-how to render-performance issue-solve it using parallel computation opencl technologyUse different color force directed.Real time use ,giving imp to diagram than textReplace Force directed algorithm with simple lay out algo.
- #6: Fontext for demoPause and explain details,with variation in speech
- #8: Brief OpenCl intro.Dreaft and open specification.Parallel only!!!Thread amnagement,synch is simple
- #10: Why this models?How architecture helps in improving performance
- #11: HierarcyHosta calls
- #12: What to do with execution model.Acces threads,Create memory,execute program,CommandsWorkgrou-cores corrospondence
- #18: Explain mapping data structures
- #22: More details on WebCL
- #27: variation in speechConclusion… and question