InfluxDB IOx Tech Talks: Intro to the InfluxDB IOx Read Buffer - A Read-Optimized In-Memory Query Execution Engine
1 like794 views

The document discusses updates and progress on InfluxDB IOx, a new columnar time series database, highlighting developments like a read buffer, management API, and future capabilities such as parquet persistence and replication. It emphasizes the importance of columnar data layout for analytical workloads and details various data organization and compression techniques in IOx. The presentation outlines the architecture, data models, and future enhancements aimed at improving performance and data handling for time-series use cases.











































![Which Dictionary Encoding?
“I need rows [2, 33, 55, 111, 3343]”
10,000,000 row column
Encoding Cardinality 10K
(materialise 1000 rows near end)
Cardinality 10M
(materialise 1 row near end)
Vec<String>
Dictionary μ
RLE μ](https://image.slidesharecdn.com/slides-210210182208/85/InfluxDB-IOx-Tech-Talks-Intro-to-the-InfluxDB-IOx-Read-Buffer-A-Read-Optimized-In-Memory-Query-Execution-Engine-44-320.jpg)

![Numerical Column Encodings
Supported Logical types: i64, u64, f64
{u8, i8,.., u64, i64}*
&[i64]: (48 B) [123, 198, 1, 33, 133, 224] ➠ &[u8]: (6 B) [..]
&[i64]: (48 B) [-18, 2, 0, 220, 2, 26] ➠ &[i16]: (12 B) [..]](https://image.slidesharecdn.com/slides-210210182208/85/InfluxDB-IOx-Tech-Talks-Intro-to-the-InfluxDB-IOx-Read-Buffer-A-Read-Optimized-In-Memory-Query-Execution-Engine-46-320.jpg)




















InfluxDB IOx Tech Talks: Intro to the InfluxDB IOx Read Buffer - A Read-Optimized In-Memory Query Execution Engine
- 1. Paul Dix InfluxData – CTO & co-founder [email protected] @pauldix InfluxDB IOx - a new columnar time series database (update)
- 2. Progress • New Team Members! • Read Buffer progress • Mutable Buffer & Read Buffer connections • Arrow Flight API • Replication, multiple IOx servers doc
- 3. API Decisions • Management API will be gRPC – CLI for common tasks • Write – InfluxDB 2.0 Line Protocol – JSON objects (events!) – Protobuf? • Query – HTTP (csv, json, display) – Arrow Flight – Postgres?
- 4. What’s Next? • Management API • Parquet Persistence to Object Store • Recovery from Object Store • Replication • Subscriptions • Official Builds & Documentation (now late March)
- 5. Edd Robinson Engineer @ InfluxData edd@influxdata.com @e-dard 🐙 @eddrobinson 🐦 An Intro to the InfluxDB IOx Read Buffer: a read-optimised in-memory execution engine
- 6. Me ● Software engineer at InfluxData. ● Worked on InfluxDB for ~4y: storage engine, write path, indexing. Working on IOx (and with Rust!) for just over a year.
- 7. What are we working towards? ● Unlimited Data: ○ Object Storage, compression ● Unlimited Cardinality: ○ Data organisation, no large indexes. ● 🚀 Analytical Queries: ○ in-memory, columnar data-layout, lots of fanciness
- 8. This talk is about... A sub-system in IOx called the Read Buffer, a new query execution engine. ● Work on data held in-memory and on-heap. No IO at read-time ● Data is immutable. ● Lots of wholesome column-store goodness: ○ 📊 ○ 🗜 ○ ⇶ ○ ❓ ○ ❓
- 9. Wider Goals We want to have excellent support for different time-series use-cases ● Events ● Observability trifecta (logging, tracing, metrics) ● Large analytical workloads
- 10. We already have a time-series database?
- 13. InfluxDB Sad 🐼 ~77 MB . 👎
- 15. ● ● ● mmap - ● IOx Bets
- 16. Why columnar is the way to go ● Analytical workloads usually only need projections of dataset. ● Increase flexibility in data organisation. ● Improve data relevance. ● Reduce footprint through compression. ● Mechanical sympathy - CPUs love arrays. Forrest Smith - blog
- 17. Why columnar is the way to go Memory Bandwidth: benchmark ● This example is synthetic (but indicative!) ● Data throughput from memory to CPU has an impact on performance. ● CPU cache is significantly faster than main memory
- 18. Why columnar is the way to go L1 Cache L2/L3 Cache Main Memory Memory Bandwidth: benchmark ● This example is synthetic (but indicative)! ● Data throughput from memory to CPU has an impact on performance. ● CPU cache is significantly faster than main memory If you want to make the most use of your memory bandwidth: ● process less data. ● process more relevant data. Columnar representations help with both of these
- 19. 🤿 Dive into the Read Buffer ● Data organisation; ● Data representation; ● Read execution (late materialisation); ● Early numbers! ● Future improvements.
- 20. ● WAL: replication and recovery ● Mutable Buffer: query written data ● Object Store: for durability ● Read Buffer: optised read-only view of written data. IOx Write Path
- 21. IOx Read Path Query Engine SQL Frontend Flux Frontend InfluxQL Frontend Mutable Buffer Read Buffer Object Storage Reader
- 22. IOx Read Path Query Engine SQL Frontend Flux Frontend … Frontend Mutable Buffer Read Buffer Object Storage Reader
- 23. Data Model Data organised by database
- 24. Data Model Databases are collections of partitions Partition Key
- 25. Chunk ID Data Model Partitions contain chunks
- 26. Table name Data Model Chunks contain Tables
- 27. Data Model Tables contain Row Groups Same Schema Filter entire tables
- 28. Data Model Row Groups contain columnar data Skip Row Group
- 29. Data Model (thanks @alamb) weather,location=us-east temperature=82,humidity=67 1465839830100400200 weather,location=us-midwest temperature=82,humidity=65 1465839830100400200 weather,location=us-west temperature=70,humidity=54 1465839830100400200 weather,location=us-east temperature=83,humidity=69 1465839830200400200 weather,location=us-midwest temperature=87,humidity=78 1465839830200400200 weather,location=us-west temperature=72,humidity=56 1465839830200400200 weather,location=us-east temperature=84,humidity=67 1465839830300400200 weather,location=us-midwest temperature=90,humidity=82 1465839830400400200 weather,location=us-west temperature=71,humidity=57 1465839830400400200 location "us-east" "us-midwest" "us-west" "us-east" "us-midwest" "us-west" "us-east" "us-midwest" "us-west" temperature 82 82 70 83 87 72 84 90 71 humidity 67 65 54 69 78 56 67 82 57 timestamp 2016-06-13T17:43:50.1004002Z 2016-06-13T17:43:50.1004002Z 2016-06-13T17:43:50.1004002Z 2016-06-13T17:43:50.2004002Z 2016-06-13T17:43:50.2004002Z 2016-06-13T17:43:50.2004002Z 2016-06-13T17:43:50.3004002Z 2016-06-13T17:43:50.3004002Z 2016-06-13T17:43:50.3004002Z Row Group in Table: weather
- 30. Supported Data Types Logical Data Types ● String (utf-8 valid strings) ● Float (double-precision float) (all of them 😉) ● Integer (signed integers) ● Unsigned (unsigned integers) ● Boolean ● Binary (arbitrary bytes) Semantic Column Types ● InfluxDB Tag ➟ String ● InfluxDB Field ➟ Most ● InfluxDB Timestamp ➟ I64 ● IOx Column ➟ Anything
- 31. Tailored for time-series: ● scans, grouped aggregates, windowed aggregates, schema exploration (tables, columns, values). ● Table/row group pruning. ● Predicate pushdown. ● Comparator operators with constant on tag columns (<, <=, >, >=, =, !=} ● Aggregates any column(s) Interesting Supported Features
- 32. Storing Data in the Read Buffer ➡
- 33. Columnar Compression Spectrum Lots ‘o Compression 💯 Smaller Footprint 👎 High processing cost No Compression 👎 Larger footprint 💯 ~Zero processing cost
- 34. Columnar Compression Spectrum Lots ‘o Compression Smaller Footprint High processing cost No Compression Larger footprint ~Zero processing cost Vec<T>
- 35. Choice can depend on data location
- 37. Read Buffer Compression Schemes Dictionary Encoding ● Good for high cardinality tag columns. ● Column order not factor in compression. ● Constant time access. 🚀 ● Key: Operate directly on compressed data. 🚀
- 38. Read Buffer Compression Schemes Filtering Dictionary Encoding WHERE “region” = ‘east’ x = 0 {0, 2, 7, 15} WHERE “region” > ‘north’ x > 1 {1, 3, 5, 8, 9, 10, 11, 12, 14}
- 39. “RLE” - Run-Length Encoding ● Incredible compression when lots of “runs”. ● Works best on heavily sorted columns. ● Not as consumable* ● Pre-computed bitsets 🚀 ● Can operate on compressed data. 🚀 Read Buffer Compression Schemes
- 40. Read Buffer Compression Schemes “RLE” - Run-Length Encoding WHERE “region” = ‘east’ x = 0 WHERE “region” > ‘north’ x > 1 {9, 10, 11, 12, 13, 14, 15}
- 41. Which Dictionary Encoding? WHERE “region” = ‘east’ ● 10M rows in column ● Cardinality 10,000 ● Single thread Billions rows/second processed
- 42. Which Dictionary Encoding? WHERE “region” = ‘east’ ● 10M rows in column. ● Cardinality 10,000. ● Single thread. ● SIMD intrinsics on Dictionary Encoding. ● RLE is on another level: “cheating”... Billions rows/second processed RLE 59ms 2.2ms 420ns 380MB ~40MB ~40MB
- 43. Which Dictionary Encoding? WHERE “span_id” = ‘123djk7GHs99wj’ ● 10 million rows in column. ● Cardinality 10 million. ● Single thread. ● SIMD intrinsics on Dictionary Encoding. Billions rows/second processed RLE 60ms 2.2ms 380MB ~420MB 580ns ~1GB
- 44. Which Dictionary Encoding? “I need rows [2, 33, 55, 111, 3343]” 10,000,000 row column Encoding Cardinality 10K (materialise 1000 rows near end) Cardinality 10M (materialise 1 row near end) Vec<String> Dictionary μ RLE μ
- 45. Which Dictionary Encoding? ● ● filtering ● materialisation
- 46. Numerical Column Encodings Supported Logical types: i64, u64, f64 {u8, i8,.., u64, i64}* &[i64]: (48 B) [123, 198, 1, 33, 133, 224] ➠ &[u8]: (6 B) [..] &[i64]: (48 B) [-18, 2, 0, 220, 2, 26] ➠ &[i16]: (12 B) [..]
- 48. Read Execution SELECT “host”, “counter”, “time” FROM “cpu” WHERE “env” = ‘prod’ AND “path” = ‘/write’ AND “counter” > 200 AND “time” >= x AND “time” < y; ● ● ● ●
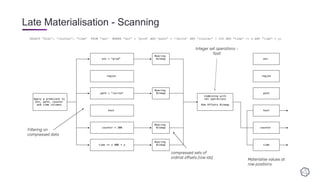
- 49. Late Materialisation - Scanning SELECT “host”, “counter”, “time” FROM “cpu” WHERE “env” = ‘prod’ AND “path” = ‘/write’ AND “counter” > 200 AND “time” >= x AND “time” < y;
- 50. Late Materialisation - Grouping SELECT SUM(“counter”) FROM “cpu” WHERE “path” = ‘/query’ AND “time” >= x AND “time” < y GROUP BY “region”; ♥
- 51. Let’s look at some initial numbers
- 52. ● ● span_id ● ● ● Synthetic High Cardinality Tracing use-case Column Name Cardinality Encoding
- 53. How much space do we need? ● ● ●
- 54. How much space do we need? ● ● ●
- 55. 1 M 1 ms 1.2 ms 10 M 1.1 ms 2.5 ms 60 M 1.3 ms 15.7 ms SELECT * FROM “traces” WHERE “trace_id” = ‘H7whivfl’; ● ● 🤔 ● 💪 ● “Needle in a Haystack”
- 56. SELECT SUM(duration) FROM “traces” GROUP BY “trace_id”; ● ● ● Aggregating over high-cardinality 1 M 30 s (~10 GB RAM) 45 ms (8 MB) 10 M 18 min (140 GB RAM) 498 ms (150 MB) 60 M D.N.F (OOM) 4.3 s (900MB)
- 57. SHOW TAG KEYS WHERE “cluster” = ‘cluster-2-2-3’ AND time >= x AND time < y ; Schema Exploration 1 M 15 ms 12 μs 10 M 150 ms 47 μs 60 M 1.6 s 120 μs
- 58. Future Work Lots more to do in Read Buffer land! ● Data-type support. ● More supported predicate, e.g., regex, LIKE, OR. ● More columnar encodings (e.g., time-series specific field encodings) ● Deletes support! (Proposal written up) ● Complete implementation of all physical operations. ● Performance - predicate caching, buffer pooling etc. ● Concurrent execution.
- 59. Thank You
- 60. Paul Dix InfluxData – CTO & co-founder [email protected] @pauldix InfluxDB IOx - a new columnar time series database (update)
- 61. Progress • New Team Members! • Read Buffer progress • Mutable Buffer & Read Buffer connections • Arrow Flight API • Replication, multiple IOx servers doc
- 62. API Decisions • Management API will be gRPC – CLI for common tasks • Write – InfluxDB 2.0 Line Protocol – JSON objects (events!) – Protobuf? • Query – HTTP (csv, json, display) – Arrow Flight – Postgres?
- 63. What’s Next? • Management API • Parquet Persistence to Object Store • Recovery from Object Store • Replication • Subscriptions • Official Builds & Documentation (now late March)
- 64. Paul Dix InfluxData – CTO & co-founder [email protected] @pauldix InfluxDB IOx - a new columnar time series database (update)
- 65. Progress • New Team Members! • Read Buffer progress • Mutable Buffer & Read Buffer connections • Arrow Flight API • Replication, multiple IOx servers doc
- 66. API Decisions • Management API will be gRPC – CLI for common tasks • Write – InfluxDB 2.0 Line Protocol – JSON objects (events!) – Protobuf? • Query – HTTP (csv, json, display) – Arrow Flight – Postgres?
- 67. What’s Next? • Management API • Parquet Persistence to Object Store • Recovery from Object Store • Replication • Subscriptions • Official Builds & Documentation (now late March)