Informix partitioning interval_rolling_window_table
Download as PPT, PDF4 likes2,571 views

This document provides an overview of interval partitioning and rolling window table partitioning in IBM Informix. It discusses: - Partitioning 101, including the benefits of partitioning like capacity, parallelism, and time cyclic data management. - Interval partitioning, which fragments data based on an interval value (e.g. monthly) and allows Informix to automatically create new fragments without downtime when data exceeds the initial fragments. - Rolling window table partitioning, which allows time-series data to be stored for a defined period then automatically detached to reduce storage requirements and improve query performance over time.















![STATLEVEL property
STATLEVEL defines the granularity or level of statistics created for the
table.
Can be set using CREATE or ALTER TABLE.
STATLEVEL [TABLE | FRAGMENT | AUTO] are the allowed values for
STATLEVEL.
TABLE – entire table dataset is read and table level statistics are
stored in sysdistrib catalog.
FRAGMENT – dataset of each fragment is read an fragment level
statistics are stored in new sysfragdist catalog. This option is only
allowed for fragmented tables.
AUTO – System determines when update statistics is run if TABLE or
FRAGMENT level statistics should be created.](https://image.slidesharecdn.com/informixpartitioningintervalrollingwindowtable-130425023447-phpapp01/85/Informix-partitioning-interval_rolling_window_table-17-320.jpg)
![UPDATE STATISTICS extensions
• UPDATE STATISTICS [AUTO | FORCE];
• UPDATE STATISTICS HIGH FOR TABLE [AUTO |
FORCE];
• UPDATE STATISTICS MEDIUM FOR TABLE tab1
SAMPLING SIZE 0.8 RESOLUTION 1.0 [AUTO |
FORCE ];
• Mode specified in UPDATE STATISTICS statement
overrides the AUTO_STAT_MODE session setting.
Session setting overrides the ONCONFIG's
AUTO_STAT_MODE parameter.](https://image.slidesharecdn.com/informixpartitioningintervalrollingwindowtable-130425023447-phpapp01/85/Informix-partitioning-interval_rolling_window_table-18-320.jpg)




















![40
Syntax
• Start with Interval fragmentation
• Augument the following:
FRAGMENT BY
RANGE (<column list>)
INTERVAL (<value>)
[ [ROLLING(<integer value> FRAGMENTS)]
[LIMIT TO <integer value> <SIZEUNIT>]
[DETACH|DISCARD]]
[[ANY|INTERVAL FIRST|INTERVAL ONLY]]
STORE IN (<dbspace list> |
<function_to_return_dbspacename()>) ;
SIZEUNIT:[K | KB | KiB | M | MB | MiB | G | GB | GiB | T | TB | TiB ]](https://image.slidesharecdn.com/informixpartitioningintervalrollingwindowtable-130425023447-phpapp01/85/Informix-partitioning-interval_rolling_window_table-40-320.jpg)
![41
• ALTER FRAGMENT... MODIFY INTERVAL
augmented as such
[ROLLING(<integer value> FRAGMENTS)] [LIMIT TO
<integer value> <SIZEUNIT>] [DETACH|DISCARD]
• ALTER FRAGMENT … MODIFY DROP ALL ROLLING removes
the rolling window policy altogether
• ALTER FRAGMENT … MODIFY INTERVAL DISABLE disables
rolling window policies without dropping them
• ALTER FRAGMENT … MODIFY INTERVAL ENABLE
reinstates the current rolling window policy, if any
is defined](https://image.slidesharecdn.com/informixpartitioningintervalrollingwindowtable-130425023447-phpapp01/85/Informix-partitioning-interval_rolling_window_table-41-320.jpg)










Informix partitioning interval_rolling_window_table
- 1. Deep dive into interval partitioning & rolling window table in IBM Informix Keshava Murthy IBM Informix Development
- 2. • Partitioning 101 • Interval partitioning • Rolling window table partitioning
- 3. Partitioning 101 What? Ability to partition a table or index into multiple physical partitions. Applications have a single schema or table. Underneath, table or index is organized by multiple partitions; Query processing and tools understand this and combine the partitions to provide a single view of the table. E.g. UNION (ALL) of States making UNITED STATES of AMERICA. Why? Capacity, parallelism, query performance (parallelism, partition elimination), time cyclic data management, faster statistics collection, multi- temperature data storage How? -CREATE TABLE with PARTITION (FRAGMENT) BY clause -ALTER TABLE INIT -CREATE INDEX on a partitioned table -CREATE INDEX explicitly with PARTITION clause Query Processing and more: -Scans all the fragments to complete the scan - Parallelization - Partition elimination during scan and join - Parallelized Index builds
- 4. DBSPACE CHUNK CHUNK CHUNK Extent Extent Extent CHUNK Pages Pages Pages Partition Extent
- 5. Customer_table Partition idx_cust_id Customer_table Partition Paritition Storesales_table Idx_store_id Partition Partition Tables, Indices and Partitions
- 6. CREATE TABLE customer_p (id int, lname varchar(32)) FRAGMENT BY ROUND ROBIN PARTITION part1 IN dbs1, PARTITION part2 IN dbs1, PARTITION part3 IN dbs2; CREATE TABLE customer_p (id int, state varchar (32)) FRAGMENT BY EXPRESSION PARTITION part1 (state = "CA") in dbs1, PARTITION part2 (state = "KS") in dbs1, PARTITION part3 (state = "OR") in dbs1, PARTITION part4 (state = "NV") in dbs1; CREATE TABLE customer (id int, state char (2), zipcode decimal(5,0)) FRAGMENT BY EXPRESSION PARTITION partca93 (state = 'CA' and zipcode <= 93000) in dbs1, PARTITION partcagt93 (state = 'CA' and zipcode > 93000) in dbs2, PARTITION partks (state = 'KS') in dbs3, PARTITION partor (state = 'OR') in dbs1, PARTITION part4 (state = 'NV') in dbs1;
- 7. • Multi-threaded Dynamic Scalable Architecture (DSA) – Scalability and Performance – Optimal usage of hardware and OS resources • DSS Parameters to optimize memory – DSS queries – Efficient hash joins • Parallel Data Query for parallel operations – Light scans, extensive – calculations, sorts, multiple joins – Ideal for DSS queries and batch operations • Data Compression • Time cyclic data mgmt – Fragment elimination, fragment attach and detach – Data/index distribution schemas – Improve large data volume manageability – Increase performance by maximizing I/O throughput • Configurable Page Size – On disk and in memory – Additional performance gains • Large Chunks support – Allows IDS instances to handle large volumes • Quick Sequential Scans – Essential for table scans common to DSS environments 17 Top IDS features utilized for building warehouse Source:
- 8. • Multi-threaded Dynamic Scalable Architecture (DSA) – Scalability and Performance – Optimal usage of hardware and OS resources • DSS Parameters to optimize memory – DSS queries – Efficient hash joins • Parallel Data Query for parallel operations – Light scans, extensive – calculations, sorts, multiple joins – Ideal for DSS queries and batch operations • Data Compression • Time cyclic data mgmt – Fragment elimination, fragment attach and detach – Data/index distribution schemas – Improve large data volume manageability – Increase performance by maximizing I/O throughput • Configurable Page Size – On disk and in memory – Additional performance gains • Large Chunks support – Allows IDS instances to handle large volumes • Quick Sequential Scans – Essential for table scans common to DSS environments 17 Top IDS features utilized for building warehouse Source: Fragmentation Features
- 9. List fragmentation CREATE TABLE customer (id SERIAL, fname CHAR(32), lname CHAR(32), state CHAR(2), phone CHAR(12)) FRAGMENT BY LIST (state) PARTITION p0 VALUES ("KS", "IL", "IN") IN dbs0, PARTITION p1 VALUES ("CA", "OR", "NV") IN dbs1, PARTITION p2 VALUES ("NY", "MN") IN dbs2, PARTITION p3 VALUES (NULL) IN dbs3, PARTITION p4 REMAINDER IN dbs3;
- 10. Open Loops with Partitioning – As of 11.50 1. UPDATES STATISTICS on a large fragmented table takes a long time 2. Need to explicitly create new partitions for new range of data 3. Need database & application down time to manage the application
- 12. • Statistics collection by partition –Distinct histograms for each partition –All the histograms are combined –Each data partition has UDI counter –Subsequently, only recollect modified partitions & update the global histogram • Smarter Statistics – Only recollect if 10% of th data has changed – Automatic statistics during attach, detach Smarter UPDATE STATISTICS
- 13. UPDATE STATISTICS during ATTACH, DETACH • Automatically kick-off update statistics refresh in the background – need to enable fragment level statistics • tasks eliminated by interval fragmentation –Running of update statistics manually after ALTER operations –Time taken to collect statistics is reduced as well.
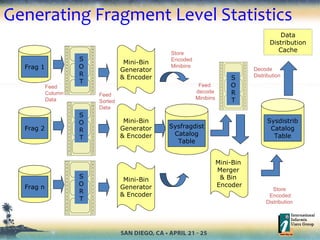
- 14. Fragment Level Statistics (FLS) • Generate and store column distribution at fragment level • Fragment level stats are combined to form column distribution • System monitors UDI (Update/Delete/Insert) activities on each fragment • Stats are refreshed only for frequently updated fragments • Fragment level distribution is used to re-calculate column distribution • No need to re-generate stats across entire table
- 15. Generating Table Level Statistics • Distribution created for entire column dataset from all fragments. • Stored in sysdistrib with (tabid,colno) combination. • Dbschema utility can decodes and display encoded distribution. • Optimizer uses in-memory distribution representation for query optimization. Data Distribution Cache Data Distribution CacheFeed Sorted Data Feed Column Data Store Encoded Distribution Decode Distribution Bin Generator & Encoder S O R T Sysdistrib Catalog table Frag 1 Frag 2 Frag n
- 16. Generating Fragment Level Statistics Data Distribution Cache Data Distribution Cache Feed Sorted Data Feed Column Data Store Encoded Minibins Decode Distribution Mini-Bin Generator & Encoder S O R T Sysfragdist Catalog Table Frag 1 Frag 2 Frag n S O R T S O R T Mini-Bin Generator & Encoder Mini-Bin Generator & Encoder Mini-Bin Merger & Bin Encoder Sysdistrib Catalog Table S O R T Feed decode Minibins Store Encoded Distribution
- 17. STATLEVEL property STATLEVEL defines the granularity or level of statistics created for the table. Can be set using CREATE or ALTER TABLE. STATLEVEL [TABLE | FRAGMENT | AUTO] are the allowed values for STATLEVEL. TABLE – entire table dataset is read and table level statistics are stored in sysdistrib catalog. FRAGMENT – dataset of each fragment is read an fragment level statistics are stored in new sysfragdist catalog. This option is only allowed for fragmented tables. AUTO – System determines when update statistics is run if TABLE or FRAGMENT level statistics should be created.
- 18. UPDATE STATISTICS extensions • UPDATE STATISTICS [AUTO | FORCE]; • UPDATE STATISTICS HIGH FOR TABLE [AUTO | FORCE]; • UPDATE STATISTICS MEDIUM FOR TABLE tab1 SAMPLING SIZE 0.8 RESOLUTION 1.0 [AUTO | FORCE ]; • Mode specified in UPDATE STATISTICS statement overrides the AUTO_STAT_MODE session setting. Session setting overrides the ONCONFIG's AUTO_STAT_MODE parameter.
- 19. UPDATE STATISTICS extensions • New metadata columns - nupdates, ndeletes and ninserts – in sysdistrib and sysfragdist store the corresponding counter values from partition page at the time of statistics generation. These columns will be used by consecutive update statistics run for evaluating if statistics are stale or reusable. • Statistics evaluation is done at fragment level for tables with fragment level statistics and at table level for the rest. • Statistics created by MEDIUM or HIGH mode (column distributions) is evaluated. • The LOW statistics is saved at the fragment level as well and is aggregated to collect global statistics
- 20. Alter Fragment Attach/Detach • Automatic background refreshing of column statistics after executing ALTER FRAGMENT ATTACH/DETACH on a table with fragmented statistics. • Refreshing of statistics begins after the ALTER has been committed. • For ATTACH operation, fragmented statistics of the new fragment is built and table level statistics is rebuilt from all fragmented statistics. Any existing fragments with out of date column statistics will be rebuilt at this time too. • For DETACH operation, table level statistics of the resulting tables are rebuilt from the fragmented statistics. • The background task that refreshes statistics is “refreshstats” and will print errors in online.log if any are encountered.
- 21. Design for Time Cyclic data mgmt create table mytrans( custid integer, proc_date date, store_loc char(12) …. ) fragment by expression ...... (proc_date < DATE ('01/01/2009' ) ) in fe_auth_log20081231, (MONTH(proc_date) = 1 ) in frag2009Jan , (MONTH(proc_date) = 2 ) in frag2009Feb,…. (MONTH(proc_date) = 10 and proc_date < DATE ('10/26/2009' ) ) in frag2009Oct , (proc_date = DATE ('10/26/2009' ) ) in frag20091026 , (proc_date = DATE ('10/27/2009' ) ) in frag20091027, (proc_date = DATE ('10/28/2009' ) ) in frag20091027 , (proc_date = DATE ('10/29/2009' ) ) in frag20091027 , (proc_date = DATE ('10/30/2009' ) ) in frag20091027 , (proc_date = DATE ('10/31/2009' ) ) in frag20091027 , (proc_date = DATE ('11/01/2009' ) ) in frag20091027 , ;
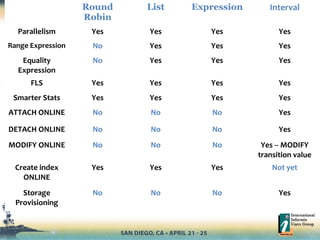
- 22. Round Robin List Expression Interval Parallelism Yes Yes Yes Yes Range Expression No Yes Yes Yes Equality Expression No Yes Yes Yes FLS Yes Yes Yes Yes Smarter Stats Yes Yes Yes Yes ATTACH ONLINE No No No Yes DETACH ONLINE No No No Yes MODIFY ONLINE No No No Yes -- MODIFY transition value Create index ONLINE Yes Yes Yes Not yet Storage Provisioning No No No Yes
- 23. Type of filter (WHERE clause) Nonoverlapping Single fragment key Overlapping on a single column key Nonoverlapping Multiple column key Range expression Can eliminate Cannot eliminate Cannot eliminate Equality expression Can eliminate Can eliminate Can eliminate Fragment elimination
- 24. New fragmentation Strategies in Informix v11.70 • List Fragmentation –Similar to expression based fragmentation –Syntax compatibility • Interval Fragmentation –Like expression, but policy based –Improves availability of the system
- 25. Time Cyclic Data management • Time-cyclic data management (roll-on, roll-off) • Attach the new fragment • Detach the fragment no longer needed • Update the statistics (low, medium/high) to keep everything up to date. field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field JanJan FebFeb MarMar AprApr May 09May 09 Dec 08Dec 08 enables storing data over time
- 26. field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field field JanJan FebFeb MarMar AprApr May 09May 09 Dec 08Dec 08 • ATTACH, DETACH and rest of ALTERs require exclusive access – Planned Downtime • These can be scripted, but still need to lock out the users – Informix 11.50.xC6 has DDL_FORCE_EXEC to lock out the users • Expression strategy gives you flexibility, but elimination can be tricky. Time Cyclic Data management
- 27. Fragment by Expression create table orders ( order_num int, order_date date, customer_num integer not null, ship_instruct char(40), backlog char(1), po_num char(10), ship_date date, ship_weight decimal(8,2), ship_charge money(6), paid_date date ) partition by expression partition prv_partition (order_date < date(’01-01-2010’)) in mydbs, partition jan_partition (order_date >= date(’01-01-2010’) and order_date < date(’02-01-2010’) in mydbs, partition feb_partition (order_date >= date(’02-01-2010’) and order_date < date(’03-01-2010’) in mydbs, partition mar_partition (order_date >= date(’03-01-2010’) and order_date < date(’04-01-2010’) in mydbs, partition apr_partition (order_date >= date(’04-01-2010’) and order_date < date(’05-01-2010’) in mydbs, …
- 28. Fragment by Interval Interval Value Initial Partition Partition Key dbspaces create table orders ( order_num int, order_date date, customer_num integer not null, ship_instruct char(40), backlog char(1), po_num char(10), ship_date date, ship_weight decimal(8,2), ship_charge money(6), paid_date date ) partition by range(order_date) interval(1 units month) store in (dbs1, dbs2) partition prv_partition values < date(’01-01-2010’) in dbs3;
- 29. Interval Fragmentation • Fragments data based on an interval value – E.g. fragment for every month or every million customer records • Tables have an initial set of fragments defined by a range expression • When a row is inserted that does not fit in the initial range fragments, IDS will automatically create fragment to hold the row (no DBA intervention) • No X-lock is required for fragment addition • All the benefits of fragment by expression
- 30. ONLINE attach, detach • ATTACH – Load the data into a staging table, create the indices exactly as you have in your target table. – Then simply attach the table as a fragment into another table. • DETACH – Identify the partition you want to detach – Simply detach the partition with ONLINE keyword to avoid attemps to get exclusive access
- 31. Attach Example ALTER FRAGMENT ONLINE ON TABLE “sales”.orders ATTACH december_orders_table as PARTITION december_partition values < 01-01-2011;
- 32. Attach Example
- 33. Attaching online
- 34. December_orders_table Table to attach orders query1 query2 Issue ALTER ATTACH ONLINE query1 query2 Query1 and Query2 continue and won’t access the new partition Attach Modify the dictionary entry to indicate online attach is in progress. Other sessions can read the list but cannot modify. query1 query2 query3 New queries will work on the table and won’t consider the table fragment for the queries. ONLINE ATTACH operation is complete. Table is fully available for queries query3 query4 Get exclusive access to the partion list (in the dictionary) .The dictionary entry gets modified and new dictionary entries for new queries from here on New queries will work on the table and will consider the new table fragment . Attaching online
- 35. ONLINE operations • ATTACH a fragment • DETACH a fragment • MODIFY transition value • Automatic ADDing of new fragments on insert or update • tasks eliminated by interval fragmentation – Scheduling downtime to get exclusive access for ADD, ATTACH, DETACH – Defining proper expressions to ensure fragment elimination – Running of update statistics manually after ALTER operations – Time taken to collect statistics is reduced as well.
- 37. 37 Agenda • Reasons for feature • Syntax • Examples • Limitations
- 38. 38 Reasons for feature - Enterprise • Enterprise customers and customer applications have a policy –Keep 13 months of sales data –Every month, purge/compress/move this data • Customers write scripts to implement this policy • All these require database & system down time. • Scripts have to be tested, maintained. • Why not support the policy itself in the database?
- 39. 39 Reasons for feature - Embedded • Embedded applications have a need to manage limited amount of space automatically • OEM's have written thousands of lines of SPL to limit the amount of space taken by tables • Offering the ability to control table space usage declaratively simplifies applications • Why not embed the policy itself into the table?
- 40. 40 Syntax • Start with Interval fragmentation • Augument the following: FRAGMENT BY RANGE (<column list>) INTERVAL (<value>) [ [ROLLING(<integer value> FRAGMENTS)] [LIMIT TO <integer value> <SIZEUNIT>] [DETACH|DISCARD]] [[ANY|INTERVAL FIRST|INTERVAL ONLY]] STORE IN (<dbspace list> | <function_to_return_dbspacename()>) ; SIZEUNIT:[K | KB | KiB | M | MB | MiB | G | GB | GiB | T | TB | TiB ]
- 41. 41 • ALTER FRAGMENT... MODIFY INTERVAL augmented as such [ROLLING(<integer value> FRAGMENTS)] [LIMIT TO <integer value> <SIZEUNIT>] [DETACH|DISCARD] • ALTER FRAGMENT … MODIFY DROP ALL ROLLING removes the rolling window policy altogether • ALTER FRAGMENT … MODIFY INTERVAL DISABLE disables rolling window policies without dropping them • ALTER FRAGMENT … MODIFY INTERVAL ENABLE reinstates the current rolling window policy, if any is defined
- 42. 42 ROLLING clause • Used to specify the number of active interval fragments • When interval fragments exceed the set value (that is when a new one is created), the interval fragment holding the lowest set of values will be detached
- 43. 43 LIMIT clause • Specifies the maximum size of the table • When limit exceeded, fragments holding the lowest value will be detached until space used is below limit • The comparison is done against the overall size (data and indices pages allocated) of the table • Both interval and initial range fragments could be detached depending on the action specified
- 44. 44 DETACH | DISCARD clause • Decides the fate of victim fragments • DISCARD will eliminate the fragment for good • DETACH will preserve the data by detaching the fragment in a new table • Applications can detect detached fragments and archive their contents into different tables, databases, aggregate it, etc • The actual detach / discard is done through the DBscheduler
- 45. 45 ANY | INTERVAL FIRST | INTERVAL ONLY • The LIMIT TO clause has three modes of operation – ANY – any fragment will be detached starting from the lowest – INTERVAL FIRST – interval fragments will be detached starting from the lowest, if table still exceeds LIMIT, range fragments will be detached from the lowest: intended as an emergency action – INTERVAL ONLY – range fragments preserved even if table still exceeds LIMIT • Default is INTERVAL FIRST • Range fragments will be detached but preserved empty
- 46. 46 STORE clause • The STORE clause has been extended to be able to take a function which returns the dbspace name where the next fragment is to be created. • The function takes four arguments: table owner, table name, value being inserted, retry flag • If creating fragment fails first time round, function will be invoked again with retry flag set • On new failure, DML being executed will fail • The statement will fail if the UDR cannot be determined
- 47. 47 Examples create table orders (order_num serial(1001), order_date date, customer_num integer not null, ship_instruct char(40), backlog char(1), po_num char(10), ship_date date, ship_weight decimal(8,2), ship_charge money(6), paid_date date ) partition by range(order_date) interval(1 units month) ROLLING (12 FRAGMENTS) LIMIT TO 20 GB DETACH store in (mydbname()) partition prv_partition values < date(’01-01-2010’) in mydbs;
- 48. 48 Examples #2 • Sample UDR to determine dbspace CREATE FUNCTION mydbname(owner char(255), table CHAR(255), value DATETIME YEAR TO SECOND, retry INTEGER) RETURNING CHAR(255) IF (retry > 0) THEN RETURN NULL; -- if it does not work the first time, -- do not try again END IF; IF (MONTH(value) < 7) THEN RETURN "dbs1"; ELSE RETURN "dbs2"; END IF; END FUNCTION
- 49. 49 UDRs and DBScheduler • Detaching or dropping fragments can be done manually, executing function syspurge() from the database from which the fragments should be dropped detached • It will be done automatically every day through the 'purge_tables' Dbscheduler system task. • Task is enabled by default • By default, when does purge_tables task scheduled?
- 50. 50 Limitations • Due to primary key constraint violations, the feature will not be applicable to tables with a primary key having referential constraints to it (primary key with no references is fine). • Only indices following the same fragmentation strategy as the table are allowed (to allow real time fragment detach). • This means indices have to be created with no storage option, and no ALTER FRAGMENT MODIFY, ALTER FRAGMENT INIT is allowed on the indices.
- 51. Deep dive into interval and rolling window table partitioning in IBM Informix Keshava Murthy IBM [email protected]