Install and Configure Ubuntu for Hadoop Installation for beginners
1 like334 views
Covered each and every step to configure Ubuntu. Used vmware workstation 10. Note: I am beginner so I might have used technical word wrong. But it is working perfectly fine.
1 of 62
Downloaded 23 times





























































Ad
Recommended
Hadoop single cluster installation
Hadoop single cluster installationMinh Tran The objective of this slide is to install Hadoop in standalone mode and in a single cluster pseudo mode
Running hadoop on ubuntu linux
Running hadoop on ubuntu linuxTRCK The document discusses Hadoop and HDFS. It provides an overview of HDFS architecture and how it is designed to be highly fault tolerant and provide high throughput access to large datasets. It also discusses setting up single node and multi-node Hadoop clusters on Ubuntu Linux, including configuration, formatting, starting and stopping the clusters, and running MapReduce jobs.
Single node hadoop cluster installation 
Single node hadoop cluster installation Mahantesh Angadi This document provides instructions for installing a single-node Hadoop cluster on Ubuntu. It outlines downloading and configuring Java, installing Hadoop, configuring SSH access to localhost, editing Hadoop configuration files, and formatting the HDFS filesystem via the namenode. Key steps include adding a dedicated Hadoop user, generating SSH keys, setting properties in core-site.xml, hdfs-site.xml and mapred-site.xml, and running 'hadoop namenode -format' to initialize the filesystem.
Hadoop Installation
Hadoop Installationmrinalsingh385 To know more, Register for Online Hadoop Training at WizIQ.
Click here : http://www.wiziq.com/course/21308-hadoop-big-data-training
A complete guide to Hadoop Installation that will help you when ever you face problems while installing Hadoop !!
An example Hadoop Install
An example Hadoop InstallMike Frampton A practical example of how Hadoop can be installed
and a cluster created using low cost hardware.
Hadoop installation
Hadoop installationAnkit Desai Hadoop Installation, Steps to install hadoop, Hadoop VMare Install, Hadoop single node cluster, Hadoop Multinode Cluster setup steps
Hadoop single node setup
Hadoop single node setupMohammad_Tariq This document provides instructions for setting up Hadoop in single node mode on Ubuntu. It describes adding a Hadoop user, installing Java and SSH, downloading and extracting Hadoop, configuring environment variables and Hadoop configuration files, and formatting the NameNode.
Hadoop 2.2.0 Multi-node cluster Installation on Ubuntu 
Hadoop 2.2.0 Multi-node cluster Installation on Ubuntu 康志強 大人 This document provides instructions for installing Hadoop 2.2.0 on a 3 node cluster of Ubuntu virtual machines. It describes setting up hostnames and SSH access between nodes, installing Java and Hadoop, and configuring Hadoop for a multi-node setup with one node as the name node and secondary name node, and the other two nodes as data nodes and node managers. Finally it explains starting up the HDFS and YARN services and verifying the cluster setup.
Run wordcount job (hadoop)
Run wordcount job (hadoop)valeri kopaleishvili The document provides step-by-step instructions for installing a single-node Hadoop cluster on Ubuntu Linux using VMware. It details downloading and configuring required software like Java, SSH, and Hadoop. Configuration files are edited to set properties for core Hadoop functions and enable HDFS. Finally, sample data is copied to HDFS and a word count MapReduce job is run to test the installation.
Set up Hadoop Cluster on Amazon EC2
Set up Hadoop Cluster on Amazon EC2IMC Institute 1. The document describes how to set up a Hadoop cluster on Amazon EC2, including creating a VPC, launching EC2 instances for a master node and slave nodes, and configuring the instances to install and run Hadoop services.
2. Key steps include creating a VPC, security group and EC2 instances for the master and slaves, installing Java and Hadoop on the master, cloning the master image for the slaves, and configuring files to set the master and slave nodes and start Hadoop services.
3. The setup is tested by verifying Hadoop processes are running on all nodes and accessing the HDFS WebUI.
Dev ops
Dev opsTom Hall This document provides an overview of various Linux system administration concepts and tools, including:
- Explaining that everything is a file in Linux and describing some special files like /dev/null.
- Summarizing how to use utilities like top, iostat, vmstat, and free to monitor system performance.
- Describing how to use find, locate, xargs to search for files and sed/awk to manipulate text.
- Explaining how processes can still have open file handles even if the files are deleted and how lsof can identify these situations.
- Summarizing how to use cron, logrotate, and Upstart to automate tasks and manage processes and services
Hadoop on ec2
Hadoop on ec2Mark Kerzner The document discusses configuring and running a Hadoop cluster on Amazon EC2 instances using the Cloudera distribution. It provides steps for launching EC2 instances, editing configuration files, starting Hadoop services, and verifying the HDFS and MapReduce functionality. It also demonstrates how to start and stop an HBase cluster on the same EC2 nodes.
Hadoop 3.1.1 single node
Hadoop 3.1.1 single node康志強 大人 This document provides instructions for installing Hadoop 3.1.1 in a single-node configuration on Ubuntu. It includes steps for setting up the installation environment, configuring Java and Hadoop, and starting the Hadoop daemons. Key steps are installing Java 8, downloading and extracting Hadoop, configuring core-site.xml, hdfs-site.xml and other files, formatting HDFS, and starting HDFS and YARN processes. References for more information are also provided.
Ansible ex407 and EX 294
Ansible ex407 and EX 294IkiArif1 The document provides requirements and sample exam questions for the Red Hat Certified Engineer (RHCE) EX294 exam. It outlines 18 exam questions to test Ansible skills. Key requirements include setting up 5 virtual machines, one as the Ansible control node and 4 managed nodes. The questions cover tasks like Ansible installation, ad-hoc commands, playbooks, roles, vaults and more. Detailed solutions are provided for each question/task.
Light my-fuse
Light my-fuseWorkhorse Computing FUSE allows processes to mount their own private filesystems without requiring root privileges. Some examples of FUSE filesystems include encrypted volumes using encfs and remote filesystems mounted over SSH using sshfs. These filesystems can be mounted automatically and only be visible to the mounting process, providing security and privacy for personal data even from the root user.
Automated infrastructure is on the menu
Automated infrastructure is on the menujtimberman This document summarizes an OSCON 2010 presentation by Joshua Timberman and Aaron Peterson of Opscode about Chef, an open-source automation platform for configuring and managing servers. The presentation covers Chef 101, getting started with Chef, and cooking with Chef. It discusses key concepts like Chef clients, the Chef server, nodes, roles, recipes, resources, attributes, and data bags. The goal is to provide an introduction to Chef and how it can be used to automate infrastructure.
HADOOP 실제 구성 사례, Multi-Node 구성
HADOOP 실제 구성 사례, Multi-Node 구성Young Pyo The document describes the steps to set up a Hadoop cluster with one master node and three slave nodes. It includes installing Java and Hadoop, configuring environment variables and Hadoop files, generating SSH keys, formatting the namenode, starting services, and running a sample word count job. Additional sections cover adding and removing nodes and performing health checks on the cluster.
How to create a secured multi tenancy for clustered ML with JupyterHub
How to create a secured multi tenancy for clustered ML with JupyterHubTiago Simões With this presentation you should be able to create a kerberos secured architecture for a framework of an interactive data analysis and machine learning by using a Jupyter/JupyterHub powered by IPython Clusters that enables the machine learning processing clustering local and/or remote nodes, all of this with a non-root user and as a service.
How to go the extra mile on monitoring
How to go the extra mile on monitoringTiago Simões This document provides instructions for monitoring additional metrics from clusters and applications using Grafana, Prometheus, JMX, and PushGateway. It includes steps to export JMX metrics from Kafka and NiFi, setup and use PushGateway to collect and expose custom metrics, and create Grafana dashboards to visualize the metrics.
Install odoo v8 the easiest way on ubuntu debian
Install odoo v8 the easiest way on ubuntu debianFrancisco Servera Install odoo the easiest way on ubuntu or debian. A very useful guide for those who want odoo instaled in a virtual machine in production environement
DevOps(3) : Ansible - (MOSG)
DevOps(3) : Ansible - (MOSG)Soshi Nemoto Ansible is an IT automation tool that can provision and configure servers. It works by defining playbooks that contain tasks to be run on target servers. Playbooks use YAML format and modules to automate configuration changes. Vagrant and Ansible can be integrated so that Ansible playbooks are run as part of the Vagrant provisioning process to automate server setup. The document provides an introduction and examples of using Ansible playbooks with Vagrant virtual machines to install and configure the Apache HTTP server.
Lamp configuration u buntu 10.04
Lamp configuration u buntu 10.04mikehie This document provides step-by-step instructions for configuring a LAMP stack on an Ubuntu 10.04 server including: installing Apache, MySQL, PHP; enabling modules; installing Drush and Drush Make; setting up Virtualmin for virtual hosting; and configuring security such as firewall rules and remote database access. It also includes links to additional resources for Drupal, Ubuntu, and LAMP configuration.
Sun raysetup
Sun raysetupPortal Oliveira This document provides step-by-step instructions for installing a SunRay Server 4.1 and setting up a SunRay G1 Thin Client with Debian Linux. It details installing and configuring the necessary software on the server machine, including the SunRay server software, Java runtime environment, DHCP server, and more. Instructions are also provided for configuring the thin client and networking to allow it to connect to the SunRay server.
Vagrant, Ansible, and OpenStack on your laptop
Vagrant, Ansible, and OpenStack on your laptopLorin Hochstein The document discusses using Ansible and Vagrant together to easily test and deploy OpenStack. Ansible allows writing idempotent infrastructure scripts, while Vagrant allows testing them by booting reproducible virtual machines. The document provides an example of using Ansible plays to install NTP and using Vagrant to define VMs for an OpenStack controller and compute node.
Installation of Subversion on Ubuntu,...
Installation of Subversion on Ubuntu,...wensheng wei The document provides instructions for installing Subversion on Ubuntu with Apache, SSL, and BasicAuth to allow hosting SVN repositories on a web server, including installing necessary packages, configuring Apache with a SSL certificate and virtual host, creating repositories under /var/svn, setting up authentication using htpasswd, and enabling WebDAV and SVN support in Apache.
Build your own private openstack cloud
Build your own private openstack cloudNUTC, imac This document provides instructions for configuring OpenStack Nova compute on a controller and compute server. It discusses:
1. Configuring the MySQL database, RabbitMQ, and Keystone service credentials for Nova on the controller.
2. Installing and configuring the Nova packages, including API, scheduler, and conductor services on the controller and nova-compute on the compute server.
3. Configuring Nova to use the MySQL database, RabbitMQ for messaging, and Glance for images.
4. Starting the Nova services and cleaning the SQLite database file.
使用 CLI 管理 OpenStack 平台
使用 CLI 管理 OpenStack 平台NUTC, imac The document discusses using the OpenStack command line interface (CLI) to manage an OpenStack platform. It provides examples of commands for various OpenStack services like Keystone, Glance, Neutron, Nova, Cinder, Swift, Heat, and Ceilometer. The commands can be used to create, delete, modify, query and display resources and include examples like keystone user create, neutron network create, nova boot instance, and ceilometer meter list.
Triangle OpenStack meetup 09 2013
Triangle OpenStack meetup 09 2013Dan Radez The document provides instructions for deploying Red Hat OpenStack on Red Hat Enterprise Linux using PackStack. It describes starting two virtual machines for the RDO control and compute nodes. It then discusses using PackStack to install OpenStack on the nodes in an interactive or automated way. Finally, it outlines exploring the OpenStack dashboard and services like Keystone, Glance, Nova, Cinder, and Swift after installation.
Setup and run hadoop distrubution file system example 2.2
Setup and run hadoop distrubution file system example 2.2Mounir Benhalla The document provides instructions for setting up Hadoop 2.2.0 on Ubuntu. It describes installing Java and OpenSSH, creating Hadoop user and groups, setting up SSH keys for passwordless login, configuring Hadoop environment variables, formatting the namenode, starting Hadoop services, and running a sample Pi estimation MapReduce job to test the installation.
Pig, Making Hadoop Easy
Pig, Making Hadoop EasyNick Dimiduk This document introduces Pig, an open source platform for analyzing large datasets that sits on top of Hadoop. It provides an example of using Pig Latin to find the top 5 most visited websites by users aged 18-25 from user and website data. Key points covered include who uses Pig, how it works, performance advantages over MapReduce, and upcoming new features. The document encourages learning more about Pig through online documentation and tutorials.
Ad
More Related Content
What's hot (20)
Run wordcount job (hadoop)
Run wordcount job (hadoop)valeri kopaleishvili The document provides step-by-step instructions for installing a single-node Hadoop cluster on Ubuntu Linux using VMware. It details downloading and configuring required software like Java, SSH, and Hadoop. Configuration files are edited to set properties for core Hadoop functions and enable HDFS. Finally, sample data is copied to HDFS and a word count MapReduce job is run to test the installation.
Set up Hadoop Cluster on Amazon EC2
Set up Hadoop Cluster on Amazon EC2IMC Institute 1. The document describes how to set up a Hadoop cluster on Amazon EC2, including creating a VPC, launching EC2 instances for a master node and slave nodes, and configuring the instances to install and run Hadoop services.
2. Key steps include creating a VPC, security group and EC2 instances for the master and slaves, installing Java and Hadoop on the master, cloning the master image for the slaves, and configuring files to set the master and slave nodes and start Hadoop services.
3. The setup is tested by verifying Hadoop processes are running on all nodes and accessing the HDFS WebUI.
Dev ops
Dev opsTom Hall This document provides an overview of various Linux system administration concepts and tools, including:
- Explaining that everything is a file in Linux and describing some special files like /dev/null.
- Summarizing how to use utilities like top, iostat, vmstat, and free to monitor system performance.
- Describing how to use find, locate, xargs to search for files and sed/awk to manipulate text.
- Explaining how processes can still have open file handles even if the files are deleted and how lsof can identify these situations.
- Summarizing how to use cron, logrotate, and Upstart to automate tasks and manage processes and services
Hadoop on ec2
Hadoop on ec2Mark Kerzner The document discusses configuring and running a Hadoop cluster on Amazon EC2 instances using the Cloudera distribution. It provides steps for launching EC2 instances, editing configuration files, starting Hadoop services, and verifying the HDFS and MapReduce functionality. It also demonstrates how to start and stop an HBase cluster on the same EC2 nodes.
Hadoop 3.1.1 single node
Hadoop 3.1.1 single node康志強 大人 This document provides instructions for installing Hadoop 3.1.1 in a single-node configuration on Ubuntu. It includes steps for setting up the installation environment, configuring Java and Hadoop, and starting the Hadoop daemons. Key steps are installing Java 8, downloading and extracting Hadoop, configuring core-site.xml, hdfs-site.xml and other files, formatting HDFS, and starting HDFS and YARN processes. References for more information are also provided.
Ansible ex407 and EX 294
Ansible ex407 and EX 294IkiArif1 The document provides requirements and sample exam questions for the Red Hat Certified Engineer (RHCE) EX294 exam. It outlines 18 exam questions to test Ansible skills. Key requirements include setting up 5 virtual machines, one as the Ansible control node and 4 managed nodes. The questions cover tasks like Ansible installation, ad-hoc commands, playbooks, roles, vaults and more. Detailed solutions are provided for each question/task.
Light my-fuse
Light my-fuseWorkhorse Computing FUSE allows processes to mount their own private filesystems without requiring root privileges. Some examples of FUSE filesystems include encrypted volumes using encfs and remote filesystems mounted over SSH using sshfs. These filesystems can be mounted automatically and only be visible to the mounting process, providing security and privacy for personal data even from the root user.
Automated infrastructure is on the menu
Automated infrastructure is on the menujtimberman This document summarizes an OSCON 2010 presentation by Joshua Timberman and Aaron Peterson of Opscode about Chef, an open-source automation platform for configuring and managing servers. The presentation covers Chef 101, getting started with Chef, and cooking with Chef. It discusses key concepts like Chef clients, the Chef server, nodes, roles, recipes, resources, attributes, and data bags. The goal is to provide an introduction to Chef and how it can be used to automate infrastructure.
HADOOP 실제 구성 사례, Multi-Node 구성
HADOOP 실제 구성 사례, Multi-Node 구성Young Pyo The document describes the steps to set up a Hadoop cluster with one master node and three slave nodes. It includes installing Java and Hadoop, configuring environment variables and Hadoop files, generating SSH keys, formatting the namenode, starting services, and running a sample word count job. Additional sections cover adding and removing nodes and performing health checks on the cluster.
How to create a secured multi tenancy for clustered ML with JupyterHub
How to create a secured multi tenancy for clustered ML with JupyterHubTiago Simões With this presentation you should be able to create a kerberos secured architecture for a framework of an interactive data analysis and machine learning by using a Jupyter/JupyterHub powered by IPython Clusters that enables the machine learning processing clustering local and/or remote nodes, all of this with a non-root user and as a service.
How to go the extra mile on monitoring
How to go the extra mile on monitoringTiago Simões This document provides instructions for monitoring additional metrics from clusters and applications using Grafana, Prometheus, JMX, and PushGateway. It includes steps to export JMX metrics from Kafka and NiFi, setup and use PushGateway to collect and expose custom metrics, and create Grafana dashboards to visualize the metrics.
Install odoo v8 the easiest way on ubuntu debian
Install odoo v8 the easiest way on ubuntu debianFrancisco Servera Install odoo the easiest way on ubuntu or debian. A very useful guide for those who want odoo instaled in a virtual machine in production environement
DevOps(3) : Ansible - (MOSG)
DevOps(3) : Ansible - (MOSG)Soshi Nemoto Ansible is an IT automation tool that can provision and configure servers. It works by defining playbooks that contain tasks to be run on target servers. Playbooks use YAML format and modules to automate configuration changes. Vagrant and Ansible can be integrated so that Ansible playbooks are run as part of the Vagrant provisioning process to automate server setup. The document provides an introduction and examples of using Ansible playbooks with Vagrant virtual machines to install and configure the Apache HTTP server.
Lamp configuration u buntu 10.04
Lamp configuration u buntu 10.04mikehie This document provides step-by-step instructions for configuring a LAMP stack on an Ubuntu 10.04 server including: installing Apache, MySQL, PHP; enabling modules; installing Drush and Drush Make; setting up Virtualmin for virtual hosting; and configuring security such as firewall rules and remote database access. It also includes links to additional resources for Drupal, Ubuntu, and LAMP configuration.
Sun raysetup
Sun raysetupPortal Oliveira This document provides step-by-step instructions for installing a SunRay Server 4.1 and setting up a SunRay G1 Thin Client with Debian Linux. It details installing and configuring the necessary software on the server machine, including the SunRay server software, Java runtime environment, DHCP server, and more. Instructions are also provided for configuring the thin client and networking to allow it to connect to the SunRay server.
Vagrant, Ansible, and OpenStack on your laptop
Vagrant, Ansible, and OpenStack on your laptopLorin Hochstein The document discusses using Ansible and Vagrant together to easily test and deploy OpenStack. Ansible allows writing idempotent infrastructure scripts, while Vagrant allows testing them by booting reproducible virtual machines. The document provides an example of using Ansible plays to install NTP and using Vagrant to define VMs for an OpenStack controller and compute node.
Installation of Subversion on Ubuntu,...
Installation of Subversion on Ubuntu,...wensheng wei The document provides instructions for installing Subversion on Ubuntu with Apache, SSL, and BasicAuth to allow hosting SVN repositories on a web server, including installing necessary packages, configuring Apache with a SSL certificate and virtual host, creating repositories under /var/svn, setting up authentication using htpasswd, and enabling WebDAV and SVN support in Apache.
Build your own private openstack cloud
Build your own private openstack cloudNUTC, imac This document provides instructions for configuring OpenStack Nova compute on a controller and compute server. It discusses:
1. Configuring the MySQL database, RabbitMQ, and Keystone service credentials for Nova on the controller.
2. Installing and configuring the Nova packages, including API, scheduler, and conductor services on the controller and nova-compute on the compute server.
3. Configuring Nova to use the MySQL database, RabbitMQ for messaging, and Glance for images.
4. Starting the Nova services and cleaning the SQLite database file.
使用 CLI 管理 OpenStack 平台
使用 CLI 管理 OpenStack 平台NUTC, imac The document discusses using the OpenStack command line interface (CLI) to manage an OpenStack platform. It provides examples of commands for various OpenStack services like Keystone, Glance, Neutron, Nova, Cinder, Swift, Heat, and Ceilometer. The commands can be used to create, delete, modify, query and display resources and include examples like keystone user create, neutron network create, nova boot instance, and ceilometer meter list.
Triangle OpenStack meetup 09 2013
Triangle OpenStack meetup 09 2013Dan Radez The document provides instructions for deploying Red Hat OpenStack on Red Hat Enterprise Linux using PackStack. It describes starting two virtual machines for the RDO control and compute nodes. It then discusses using PackStack to install OpenStack on the nodes in an interactive or automated way. Finally, it outlines exploring the OpenStack dashboard and services like Keystone, Glance, Nova, Cinder, and Swift after installation.
Viewers also liked (10)
Setup and run hadoop distrubution file system example 2.2
Setup and run hadoop distrubution file system example 2.2Mounir Benhalla The document provides instructions for setting up Hadoop 2.2.0 on Ubuntu. It describes installing Java and OpenSSH, creating Hadoop user and groups, setting up SSH keys for passwordless login, configuring Hadoop environment variables, formatting the namenode, starting Hadoop services, and running a sample Pi estimation MapReduce job to test the installation.
Pig, Making Hadoop Easy
Pig, Making Hadoop EasyNick Dimiduk This document introduces Pig, an open source platform for analyzing large datasets that sits on top of Hadoop. It provides an example of using Pig Latin to find the top 5 most visited websites by users aged 18-25 from user and website data. Key points covered include who uses Pig, how it works, performance advantages over MapReduce, and upcoming new features. The document encourages learning more about Pig through online documentation and tutorials.
Practical Problem Solving with Apache Hadoop & Pig
Practical Problem Solving with Apache Hadoop & PigMilind Bhandarkar The document discusses a presentation about practical problem solving with Hadoop and Pig. It provides an agenda that covers introductions to Hadoop and Pig, including the Hadoop distributed file system, MapReduce, performance tuning, and examples. It discusses how Hadoop is used at Yahoo, including statistics on usage. It also provides examples of how Hadoop has been used for applications like log processing, search indexing, and machine learning.
HIVE:
Data Warehousing & Analytics on Hadoop
HIVE:
Data Warehousing & Analytics on HadoopZheng Shao Hive is a data warehousing system built on Hadoop that allows users to query data using SQL. It addresses issues with using Hadoop for analytics like programmability and metadata. Hive uses a metastore to manage metadata and supports structured data types, SQL queries, and custom MapReduce scripts. At Facebook, Hive is used for analytics tasks like summarization, ad hoc analysis, and data mining on over 180TB of data processed daily across a Hadoop cluster.
Hadoop for beginners free course ppt
Hadoop for beginners free course pptNjain85 This is a power point presentation on Hadoop and Big Data. This covers the essential knowledge one should have when stepping into the world of Big Data.
This course is available on hadoop-skills.com for free!
This course builds a basic fundamental understanding of Big Data problems and Hadoop as a solution. This course takes you through:
• This course builds Understanding of Big Data problems with easy to understand examples and illustrations.
• History and advent of Hadoop right from when Hadoop wasn’t even named Hadoop and was called Nutch
• What is Hadoop Magic which makes it so unique and powerful.
• Understanding the difference between Data science and data engineering, which is one of the big confusions in selecting a carrier or understanding a job role.
• And most importantly, demystifying Hadoop vendors like Cloudera, MapR and Hortonworks by understanding about them.
This course is available for free on hadoop-skills.com
Big Data & Hadoop Tutorial
Big Data & Hadoop TutorialEdureka! Big Data and Hadoop training course is designed to provide knowledge and skills to become a successful Hadoop Developer. In-depth knowledge of concepts such as Hadoop Distributed File System, Setting up the Hadoop Cluster, Map-Reduce,PIG, HIVE, HBase, Zookeeper, SQOOP etc. will be covered in the course.
Big data ppt
Big data pptIDBI Bank Ltd. Big data is large amounts of unstructured data that require new techniques and tools to analyze. Key drivers of big data growth are increased storage capacity, processing power, and data availability. Big data analytics can uncover hidden patterns to provide competitive advantages and better business decisions. Applications include healthcare, homeland security, finance, manufacturing, and retail. The global big data market is expected to grow significantly, with India's market projected to reach $1 billion by 2015. This growth will increase demand for data scientists and analysts to support big data solutions and technologies like Hadoop and NoSQL databases.
Big data and Hadoop
Big data and HadoopRahul Agarwal This document provides an overview of big data and Hadoop. It discusses why Hadoop is useful for extremely large datasets that are difficult to manage in relational databases. It then summarizes what Hadoop is, including its core components like HDFS, MapReduce, HBase, Pig, Hive, Chukwa, and ZooKeeper. The document also outlines Hadoop's design principles and provides examples of how some of its components like MapReduce and Hive work.
What is Big Data?
What is Big Data?Bernard Marr This presentation, by big data guru Bernard Marr, outlines in simple terms what Big Data is and how it is used today. It covers the 5 V's of Big Data as well as a number of high value use cases.
Big Data Analytics with Hadoop
Big Data Analytics with HadoopPhilippe Julio Hadoop, flexible and available architecture for large scale computation and data processing on a network of commodity hardware.
Ad
Similar to Install and Configure Ubuntu for Hadoop Installation for beginners (20)
Installing Lamp Stack on Ubuntu Instance
Installing Lamp Stack on Ubuntu Instancekamarul kawnayeen This document provides instructions for installing the LAMP stack on an Ubuntu instance in AWS EC2 to deploy a Play Framework application. It describes configuring the security group to allow HTTP, HTTPS, SSH and port 9000 traffic. It then explains how to install and configure Apache web server, PHP 5, MySQL database and PHPMyAdmin. Key steps include enabling the Apache rewrite module, testing PHP installation, configuring the MySQL server, linking PHPMyAdmin at the /var/www/html directory and checking that the LAMP stack is fully installed and functional.
Lamp Server With Drupal Installation
Lamp Server With Drupal Installationfranbow This document provides instructions for installing a LAMP server with Drupal on it. It describes installing CentOS as the base Linux server, then using yum to add Apache, MySQL, PHP, and additional packages to create a full LAMP stack. It details configuring DHCP and FTP services. It also explains downloading and extracting Drupal, creating a MySQL database for it, and navigating through the Drupal installation process via a web browser. The key steps are: 1) installing a base Linux server; 2) using yum to add Apache, MySQL, PHP to create a LAMP server; 3) downloading and extracting Drupal; 4) creating a MySQL database; and 5) navigating through the Drupal installation
VMware ESXi 6.0 Installation Process
VMware ESXi 6.0 Installation ProcessNetProtocol Xpert The document provides step-by-step instructions for installing VMware ESXi 6.0 on a server. It first lists the minimum hardware requirements including supported server hardware, CPUs, RAM, network adapters and storage. It then outlines the interactive installation process using a CD/DVD including selecting options, providing passwords, configuring networking and applying changes. Once complete, the vSphere client can be used to manage the new ESXi host.
Virtualization.pdf
Virtualization.pdfमयंक वर्मा 🇮🇳 Installation of VMWare Workstation,Creation of VM image of base operating system,Installation of QEMU on Ubuntu 12.10,KVM on Ubuntu 12.10 and managing a VM on it,KVM and guest operating system on CentOS 6.3,Installing Guest OS in KVM using Command Line,Installation of VMware ESX Server,
xampp_server
xampp_servertutorialsruby This document provides instructions for installing XAMPP server on Fedora Core 5 Linux. It describes downloading and installing VMware Server to create a virtual machine for Fedora Core 5. It then outlines installing Fedora Core 5 in the virtual machine, including partitioning disks and setting the root password. Additional steps include installing a minimal desktop environment, downloading a package from FreshRPMs to enable additional repositories, and preparing to install XAMPP server for local web development and testing. The goal is to have a fully functional and secure test web server environment using XAMPP on Fedora Core 5 in a virtual machine.
xampp_server
xampp_servertutorialsruby This document provides instructions for installing XAMPP server on Fedora Core 5 Linux. It discusses downloading and installing VMware Server to create a virtual machine for Fedora Core 5. It then walks through installing Fedora Core 5 in the virtual machine, including partitioning disks and setting the root password. It describes customizing the installation to minimize installed components by removing desktop environments and unnecessary servers. Finally, it discusses downloading and installing the FreshRPM package to enable easier installation of additional packages.
Intoduction to VirtualBox English
Intoduction to VirtualBox EnglishKichiemon Adachi VirtualBox allows users to install multiple guest operating systems on a single machine. The document outlines the steps to install VirtualBox and then install Ubuntu 13.04 as a guest OS. It describes downloading and installing VirtualBox, creating a virtual machine, configuring settings like memory and storage, and then walking through the Ubuntu installation process by selecting options and components. The summary provides a high-level overview of the key steps involved in setting up Ubuntu as a virtual machine on VirtualBox.
Building your own Desktop Cloud Environment
Building your own Desktop Cloud EnvironmentJnaapti As developers we have seen these problems:
Our development environments accumulate lots of applications and libraries over a period of months.
We are usually in the habit of installing everything in one machine.
We fear that we may screw up our development environment and that means unproductive man-hours.
We forget that a multi-machine deployment is different from a single machine deployment.
How about virtualization in the desktop?
In this demo, I will take you through the steps to create a multi-VM development environment.
This demo will make use of QEMU, KVM and Virt Manager and show you how you can create a VM image, and then start servers with a set of commands, deploy your app, test everything and tear down the environment once you are happy - all this in the cosy comforts of your laptop or desktop.
The Jnaapti development environment is based on this setup.
Getting started with robonova in ubuntu
Getting started with robonova in ubuntuSandeep Saini This document provides instructions for setting up a virtual machine (VM) with Ubuntu to compile code for a Robonova robot. It describes installing VMware Player to run the Ubuntu VM virtual machine image file. It also explains how to connect a USB drive with example code to the VM, compile and run a sample "Hello World" program, and transfer the executable to the Robonova robot using minicom serial communication to run on the robot.
Debian
DebianYUDDYAL HAMDANIL The document provides instructions for configuring routing, networking interfaces, firewall rules, and installing various server software on a Linux system including FTP, Apache web server, NTP, Squid proxy, ISC DHCP server, and Bind DNS server. It includes commands to edit configuration files, start and restart services, and test functionality from client systems by accessing the new services over the network.
VPN Server using Raspberry Pi
VPN Server using Raspberry PiInternational Islamic University Chittagong, Bangladesh This document summarizes a presentation on setting up a VPN server using a Raspberry Pi. It describes the Raspberry Pi hardware specifications and applications. It then explains what a VPN is and why they are used. The main steps to install and set up the OpenVPN software on the Raspberry Pi are outlined, including installing the software, generating encryption keys, configuring ports and IP addresses. Finally, it describes how to set up the first OpenVPN user and connect to the VPN from another device.
installation of hadoop on ubuntu.pptx
installation of hadoop on ubuntu.pptxvishal choudhary This document provides instructions for installing Hadoop on Ubuntu, including downloading and configuring required packages and files. Key steps include installing Java, OpenSSH, and Hadoop; configuring configuration files like core-site.xml and hdfs-site.xml to specify directories and settings; formatting the namenode; and starting daemons through scripts to launch the Hadoop filesystem, resource manager, and other services.
Install dev stack
Install dev stackBasim Aly (JNCIP-SP, JNCIP-ENT) If you're new to openstack and you want get some hands on it then you have to install the Devstack. a bundled version for all openstack services and components in one software.
Connect to blumix vm with vnc
Connect to blumix vm with vncJoseph Chang Do you want to connect to your Bluemix VM with Graphic User Interface? In this slide, I will show you how to use VNC Viewer to connect to your Ubuntu VM on Bluemix.
Oracle vm
Oracle vmRavi Kumar Lanke Oracle VM allows users to install virtual machines on physical servers. It requires installing Oracle VM Server on a physical computer along with Oracle VM Manager which is used to manage multiple VM Servers. The document provides step-by-step instructions for installing Oracle VM Server which formats disks and installs a Linux-based management operating system. It then describes installing Oracle VM Manager which is a web-based application used to centrally manage multiple VM Servers. Minimum hardware requirements are also outlined for both Oracle VM Server and Oracle VM Manager installations.
1 installing ubuntu1404-lts_on_virtualbox
1 installing ubuntu1404-lts_on_virtualboxKichiemon Adachi This document provides instructions for installing Ubuntu 14.04 in Oracle VirtualBox. It describes downloading and installing VirtualBox on the host operating system, creating a virtual machine, configuring settings like memory and network adapter, mounting the Ubuntu 14.04 ISO, installing the guest operating system, and installing Guest Additions to enable features like shared clipboard. The process involves 7 steps: 1) installing VirtualBox on the host, 2) creating a virtual machine, 3) configuring settings for the guest, 4) mounting the ISO, 5) installing Ubuntu, 6) installing Guest Additions, and 7) shutting down the virtual machine.
Oracle Enterprise Manager Cloud Control 13c13.3 Installation On Oracle Linux-7
Oracle Enterprise Manager Cloud Control 13c13.3 Installation On Oracle Linux-7Arun Sharma Oracle Enterprise Manager Cloud Control 13c release 3 installation on Oracle Linux 7. The process of installing OEM 13c is same on Oracle Linux 6!
Full article link is here: https://www.support.dbagenesis.com/post/oracle-enterprise-manager-cloud-control-13-3-installation-on-oracle-linux
INSTALLION OF BI
INSTALLION OF BIArjun deshwal This document provides instructions for installing data integration and BI server software on an Ubuntu system. It describes downloading and configuring MySQL, Java, data integration, the MySQL connector, Hadoop, and finally running Spoon and the BI server. Key steps include installing Ubuntu 12.04 or higher, MySQL, Java, extracting and configuring data integration and the Hadoop shim, downloading the MySQL connector, and running Spoon and the BI server.
Virtualization and Socket Programing
Virtualization and Socket ProgramingMidhun S I am going to show How to install VirtualBox, Install Guest OS, and Run socket programming in the Virtual Machines.
02 free bsd installation
02 free bsd installationAbdelaziz Ali The document provides instructions for installing FreeBSD and Gnome on PCs. It outlines important instructions to follow exactly, including using specific keyboard keys. It then details the steps for installing FreeBSD, configuring FreeBSD, and installing Gnome. The steps include inserting the FreeBSD DVD, selecting installation options, adding configuration settings, installing packages, and creating a new user for logging into the Gnome desktop environment.
Ad
Recently uploaded (20)
Build Your Own Copilot & Agents For Devs
Build Your Own Copilot & Agents For DevsBrian McKeiver May 2nd, 2025 talk at StirTrek 2025 Conference.
Complete Guide to Advanced Logistics Management Software in Riyadh.pdf
Complete Guide to Advanced Logistics Management Software in Riyadh.pdfSoftware Company Explore the benefits and features of advanced logistics management software for businesses in Riyadh. This guide delves into the latest technologies, from real-time tracking and route optimization to warehouse management and inventory control, helping businesses streamline their logistics operations and reduce costs. Learn how implementing the right software solution can enhance efficiency, improve customer satisfaction, and provide a competitive edge in the growing logistics sector of Riyadh.
Quantum Computing Quick Research Guide by Arthur Morgan
Quantum Computing Quick Research Guide by Arthur MorganArthur Morgan This is a Quick Research Guide (QRG).
QRGs include the following:
- A brief, high-level overview of the QRG topic.
- A milestone timeline for the QRG topic.
- Links to various free online resource materials to provide a deeper dive into the QRG topic.
- Conclusion and a recommendation for at least two books available in the SJPL system on the QRG topic.
QRGs planned for the series:
- Artificial Intelligence QRG
- Quantum Computing QRG
- Big Data Analytics QRG
- Spacecraft Guidance, Navigation & Control QRG (coming 2026)
- UK Home Computing & The Birth of ARM QRG (coming 2027)
Any questions or comments?
- Please contact Arthur Morgan at [email protected].
100% human made.
Technology Trends in 2025: AI and Big Data Analytics
Technology Trends in 2025: AI and Big Data AnalyticsInData Labs At InData Labs, we have been keeping an ear to the ground, looking out for AI-enabled digital transformation trends coming our way in 2025. Our report will provide a look into the technology landscape of the future, including:
-Artificial Intelligence Market Overview
-Strategies for AI Adoption in 2025
-Anticipated drivers of AI adoption and transformative technologies
-Benefits of AI and Big data for your business
-Tips on how to prepare your business for innovation
-AI and data privacy: Strategies for securing data privacy in AI models, etc.
Download your free copy nowand implement the key findings to improve your business.
Splunk Security Update | Public Sector Summit Germany 2025
Splunk Security Update | Public Sector Summit Germany 2025Splunk Splunk Security Update
Sprecher: Marcel Tanuatmadja
AI and Data Privacy in 2025: Global Trends
AI and Data Privacy in 2025: Global TrendsInData Labs In this infographic, we explore how businesses can implement effective governance frameworks to address AI data privacy. Understanding it is crucial for developing effective strategies that ensure compliance, safeguard customer trust, and leverage AI responsibly. Equip yourself with insights that can drive informed decision-making and position your organization for success in the future of data privacy.
This infographic contains:
-AI and data privacy: Key findings
-Statistics on AI data privacy in the today’s world
-Tips on how to overcome data privacy challenges
-Benefits of AI data security investments.
Keep up-to-date on how AI is reshaping privacy standards and what this entails for both individuals and organizations.
DevOpsDays Atlanta 2025 - Building 10x Development Organizations.pptx
DevOpsDays Atlanta 2025 - Building 10x Development Organizations.pptxJustin Reock Building 10x Organizations with Modern Productivity Metrics
10x developers may be a myth, but 10x organizations are very real, as proven by the influential study performed in the 1980s, ‘The Coding War Games.’
Right now, here in early 2025, we seem to be experiencing YAPP (Yet Another Productivity Philosophy), and that philosophy is converging on developer experience. It seems that with every new method we invent for the delivery of products, whether physical or virtual, we reinvent productivity philosophies to go alongside them.
But which of these approaches actually work? DORA? SPACE? DevEx? What should we invest in and create urgency behind today, so that we don’t find ourselves having the same discussion again in a decade?
What is Model Context Protocol(MCP) - The new technology for communication bw...
What is Model Context Protocol(MCP) - The new technology for communication bw...Vishnu Singh Chundawat The MCP (Model Context Protocol) is a framework designed to manage context and interaction within complex systems. This SlideShare presentation will provide a detailed overview of the MCP Model, its applications, and how it plays a crucial role in improving communication and decision-making in distributed systems. We will explore the key concepts behind the protocol, including the importance of context, data management, and how this model enhances system adaptability and responsiveness. Ideal for software developers, system architects, and IT professionals, this presentation will offer valuable insights into how the MCP Model can streamline workflows, improve efficiency, and create more intuitive systems for a wide range of use cases.
Special Meetup Edition - TDX Bengaluru Meetup #52.pptx
Special Meetup Edition - TDX Bengaluru Meetup #52.pptxshyamraj55 We’re bringing the TDX energy to our community with 2 power-packed sessions:
🛠️ Workshop: MuleSoft for Agentforce
Explore the new version of our hands-on workshop featuring the latest Topic Center and API Catalog updates.
📄 Talk: Power Up Document Processing
Dive into smart automation with MuleSoft IDP, NLP, and Einstein AI for intelligent document workflows.
Heap, Types of Heap, Insertion and Deletion
Heap, Types of Heap, Insertion and DeletionJaydeep Kale This pdf will explain what is heap, its type, insertion and deletion in heap and Heap sort
Noah Loul Shares 5 Steps to Implement AI Agents for Maximum Business Efficien...
Noah Loul Shares 5 Steps to Implement AI Agents for Maximum Business Efficien...Noah Loul Artificial intelligence is changing how businesses operate. Companies are using AI agents to automate tasks, reduce time spent on repetitive work, and focus more on high-value activities. Noah Loul, an AI strategist and entrepreneur, has helped dozens of companies streamline their operations using smart automation. He believes AI agents aren't just tools—they're workers that take on repeatable tasks so your human team can focus on what matters. If you want to reduce time waste and increase output, AI agents are the next move.
Enhancing ICU Intelligence: How Our Functional Testing Enabled a Healthcare I...
Enhancing ICU Intelligence: How Our Functional Testing Enabled a Healthcare I...Impelsys Inc. Impelsys provided a robust testing solution, leveraging a risk-based and requirement-mapped approach to validate ICU Connect and CritiXpert. A well-defined test suite was developed to assess data communication, clinical data collection, transformation, and visualization across integrated devices.

Procurement Insights Cost To Value Guide.pptx
Procurement Insights Cost To Value Guide.pptxJon Hansen Procurement Insights integrated Historic Procurement Industry Archives, serves as a powerful complement — not a competitor — to other procurement industry firms. It fills critical gaps in depth, agility, and contextual insight that most traditional analyst and association models overlook.
Learn more about this value- driven proprietary service offering here.
Andrew Marnell: Transforming Business Strategy Through Data-Driven Insights
Andrew Marnell: Transforming Business Strategy Through Data-Driven InsightsAndrew Marnell With expertise in data architecture, performance tracking, and revenue forecasting, Andrew Marnell plays a vital role in aligning business strategies with data insights. Andrew Marnell’s ability to lead cross-functional teams ensures businesses achieve sustainable growth and operational excellence.
How analogue intelligence complements AI
How analogue intelligence complements AIPaul Rowe
Artificial Intelligence is providing benefits in many areas of work within the heritage sector, from image analysis, to ideas generation, and new research tools. However, it is more critical than ever for people, with analogue intelligence, to ensure the integrity and ethical use of AI. Including real people can improve the use of AI by identifying potential biases, cross-checking results, refining workflows, and providing contextual relevance to AI-driven results.
News about the impact of AI often paints a rosy picture. In practice, there are many potential pitfalls. This presentation discusses these issues and looks at the role of analogue intelligence and analogue interfaces in providing the best results to our audiences. How do we deal with factually incorrect results? How do we get content generated that better reflects the diversity of our communities? What roles are there for physical, in-person experiences in the digital world?
Mobile App Development Company in Saudi Arabia
Mobile App Development Company in Saudi ArabiaSteve Jonas EmizenTech is a globally recognized software development company, proudly serving businesses since 2013. With over 11+ years of industry experience and a team of 200+ skilled professionals, we have successfully delivered 1200+ projects across various sectors. As a leading Mobile App Development Company In Saudi Arabia we offer end-to-end solutions for iOS, Android, and cross-platform applications. Our apps are known for their user-friendly interfaces, scalability, high performance, and strong security features. We tailor each mobile application to meet the unique needs of different industries, ensuring a seamless user experience. EmizenTech is committed to turning your vision into a powerful digital product that drives growth, innovation, and long-term success in the competitive mobile landscape of Saudi Arabia.
Rusty Waters: Elevating Lakehouses Beyond Spark
Rusty Waters: Elevating Lakehouses Beyond Sparkcarlyakerly1 Spark is a powerhouse for large datasets, but when it comes to smaller data workloads, its overhead can sometimes slow things down. What if you could achieve high performance and efficiency without the need for Spark?
At S&P Global Commodity Insights, having a complete view of global energy and commodities markets enables customers to make data-driven decisions with confidence and create long-term, sustainable value. 🌍
Explore delta-rs + CDC and how these open-source innovations power lightweight, high-performance data applications beyond Spark! 🚀
AI Changes Everything – Talk at Cardiff Metropolitan University, 29th April 2...
AI Changes Everything – Talk at Cardiff Metropolitan University, 29th April 2...Alan Dix Talk at the final event of Data Fusion Dynamics: A Collaborative UK-Saudi Initiative in Cybersecurity and Artificial Intelligence funded by the British Council UK-Saudi Challenge Fund 2024, Cardiff Metropolitan University, 29th April 2025
https://alandix.com/academic/talks/CMet2025-AI-Changes-Everything/
Is AI just another technology, or does it fundamentally change the way we live and think?
Every technology has a direct impact with micro-ethical consequences, some good, some bad. However more profound are the ways in which some technologies reshape the very fabric of society with macro-ethical impacts. The invention of the stirrup revolutionised mounted combat, but as a side effect gave rise to the feudal system, which still shapes politics today. The internal combustion engine offers personal freedom and creates pollution, but has also transformed the nature of urban planning and international trade. When we look at AI the micro-ethical issues, such as bias, are most obvious, but the macro-ethical challenges may be greater.
At a micro-ethical level AI has the potential to deepen social, ethnic and gender bias, issues I have warned about since the early 1990s! It is also being used increasingly on the battlefield. However, it also offers amazing opportunities in health and educations, as the recent Nobel prizes for the developers of AlphaFold illustrate. More radically, the need to encode ethics acts as a mirror to surface essential ethical problems and conflicts.
At the macro-ethical level, by the early 2000s digital technology had already begun to undermine sovereignty (e.g. gambling), market economics (through network effects and emergent monopolies), and the very meaning of money. Modern AI is the child of big data, big computation and ultimately big business, intensifying the inherent tendency of digital technology to concentrate power. AI is already unravelling the fundamentals of the social, political and economic world around us, but this is a world that needs radical reimagining to overcome the global environmental and human challenges that confront us. Our challenge is whether to let the threads fall as they may, or to use them to weave a better future.
Generative Artificial Intelligence (GenAI) in Business
Generative Artificial Intelligence (GenAI) in BusinessDr. Tathagat Varma My talk for the Indian School of Business (ISB) Emerging Leaders Program Cohort 9. In this talk, I discussed key issues around adoption of GenAI in business - benefits, opportunities and limitations. I also discussed how my research on Theory of Cognitive Chasms helps address some of these issues
What is Model Context Protocol(MCP) - The new technology for communication bw...
What is Model Context Protocol(MCP) - The new technology for communication bw...Vishnu Singh Chundawat
Install and Configure Ubuntu for Hadoop Installation for beginners
- 1. INSTALL AND CONFIGURE UBUNTU FOR HADOOP INSTALLATION Shilpa Hemaraj
- 2. Install vmware workstation I am using vmware Workstation 10.
- 3. Create Virtual Machine Select typical recommended option
- 4. SELECT “I WILL INSTALL THE OPERATING SYSTEM LATER”
- 5. SELECT OPERATING SYSTEM “LINUX”
- 6. HIT “NEXT”
- 7. SELECT “STORE VIRTUAL DISK AS A SINGLE FILE”
- 8. WE ARE ALMOST NEAR!!! HIT “FINISH”
- 9. ITS TIME TO INSTALL UBUNTU IN VM (VIRTUAL MACHINE) SELECT ON CD/DVD
- 10. SELECT “USE ISO IMAGE FILE” SELECT THE PATH WHERE “UBUNTU-14.04.3-SERVER-AMD64.ISO” IS SAVED
- 11. AFTER GIVING PATH ,HIT “OK”
- 12. POWER ON THE VM
- 14. SELECT ENGLISH
- 16. HIT ON “NO”
- 17. SELECT LANGUAGE
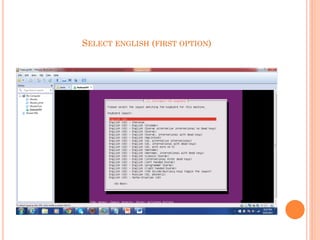
- 18. SELECT ENGLISH (FIRST OPTION)
- 19. WAIT TILL IT LOADS ADDITIONAL COMPONENTS
- 20. NOW WE NEED TO CONFIGURE THE NETWORK GIVE HOSTNAME
- 21. GIVE USERNAME (I AM SELECTING HADOOP)
- 22. GIVE USERNAME SAME AS WE HAVE GIVEN BEFORE (HADOOP)
- 23. GIVE SIMPLE PASSWORD (I GAVE ADMIN12345)
- 24. GIVE SAME PASSWORD(ADMIN12345) REMEMBER USERNAME AND PASSWORD. WE NEED IT FOR FUTURE USE.
- 25. WE DON’T NEED TO ENCRYPT HOME DIRECTORY. NO NO!!!
- 26. WAIT!!
- 27. SELECT “YES”
- 28. PARTITIONING METHOD: WE ARE SELECTING “GUIDED-USE ENTIRE DISK”
- 29. HIT IT
- 30. OH!! “YES”
- 31. WAIT!!
- 32. DON’T GIVE ANYTHING SELECT “CONTINUE”
- 33. HMMMM…….
- 34. HELL NO!! “NO AUTOMATIC UPDATES”
- 35. DON’T FORGET TO SELECT “OPENSSH SERVER”
- 37. “YES”
- 38. “CONTINUE”
- 39. OOOFFFFF…
- 40. GIVE LOGIN CREDENTIAL (SAME AS WHAT WE HAVE GIVEN BEFORE) (LOGIN:HADOOP PASSWORD:ADMIN12345)
- 41. HURRAY!!
- 42. NOW ITS TIME TO UPDATE COMMAND: SUDO APT-GET UPDATE
- 43. WAIT TILL IT UPDATES
- 44. INSTALL OPENSSH SERVER COMMAND: SUDO APT-GET INSTALL OPENSSH-SERVER (INCASE MISSED DURING INSTALLATION)
- 45. SELECT “Y”
- 46. HMMM….
- 47. NOW WE NEED TO INSTALL JAVA COMMAND: SUDO APT-GET INSTALL OPENJDK-7-JDK
- 48. SELECT “Y”
- 49. WE SUCCESSFULLY INSTALL JAVA
- 50. WE CAN CHECK JAVA VERSION INSTALLED JUST TO MAKE SURE. COMMAND:
- 51. COMMAND: IFCONFIG IT IS VERY DIFFICULT TO WORK IN VMWARE SO WE WILL USE PUTTY TO WRITE COMMANDS. IT IS MORE USER FRIENDLY. GIVE SAME IP ADDRESS IN PUTTY. SELECT “YES” FOR NEXT POPUP. GIVE SAME USERNAME AND PASSWORD. ©MBHGroups.com
- 52. TO INSTALL HADOOP , WE NEED TO COPY HADOOP INSTALLATION FILE TO OUR LINUX. WE WILL USE WINSCP TO COPY FILE FROM WINDOWS MACHINE TO LINUX. HOST NAME – GIVE IP ADDRESS AND USERNAME AND PASSWORD IS SAME AS WHAT WE ARE GIVING SELECT “YES” FOR POPUP
- 53. COPY HADOOP TAR FILE TO LINUX MACHINE
- 54. FROM NOW ON I WILL BE USING PUTTY FOR ANY LINUX COMMAND. NOW I CAN SEE MY TAR FILE.
- 55. EXTRACT TAR FILE. COMMAND: TAR –XVZF HADOOP-1.2.1.TAR.GZ
- 56. COPY FOLDER TO /USR/LOCAL/HADOOP COMMAND: SUDO CP –R HADOOP-1.2.1 /USR/LOCAL/HADOOP
- 57. TIME TO EDIT BASH COMMAND: SUDO VI /HOME/HADOOP/.BASHRC ADD 2 LINES AT THE END. TO EDIT FILE “ALT+I” OR “INSERT”
- 58. EXPORT HADOOP_PREFIX=/USR/LOCAL/HADOOP EXPORT PATH=$PATH:$HADOOP_PREFIX/BIN UPDATE THE BASH SETTINGS COMMAND:EXEC BASH
- 59. WE NEED TO INFORM HADOOP ABOUT WHERE JAVA IS. EDIT HADOOP-ENV.SH FILE COMMAND: SUDO VI /USR/LOCAL/HADOOP/CONF/HADOOP-ENV.SH
- 60. UNCOMMENT THE JAVA_HOME EXPORT JAVA_HOME=/USR/LIB/JVM/JAVA-1.7.0-OPENJDK- AMD64
- 61. WE CAN CHECK HADOOP INSTALLATION. GIVE COMMAND:”HADOOP” AND IF YOU GET OUTPUT LIKE THIS THEN INSTALLATION IS GOOD
- 62. HURRAY