Integer quantization for deep learning inference: principles and empirical evaluation
3 likes752 views

The document summarizes a presentation on integer quantization for deep learning inference. It discusses quantization fundamentals such as uniform quantization, affine and scale quantization, and tensor quantization granularity. It also covers post-training quantization, techniques to recover accuracy like partial quantization and quantization-aware training, and recommends a workflow for quantization.




![Related Work
• Uniform [7,59] quantization enables the use of integer or fixed-
point math pipelines, allowing computation to be performed in the
quantized domain.
• Non-uniform[13,60,34,2] quantization requires dequantization, e.g.
a codebook lookup, before doing computation in higher precision,
limiting its benefits to model compression and bandwidth reduction.
• This paper focuses on leveraging quantization to accelerate
computation, so we will restrict our focus to uniform quantization
schemes.
• In this paper, we present an evaluation of int8 quantization on all of
the major network architectures with both PTQ and QAT.
Neural Acceleration Study #3](https://image.slidesharecdn.com/integerquantizationfordeeplearninginferenceprinciplesandempinciplesandempiricalevaluation-201007135938/85/Integer-quantization-for-deep-learning-inference-principles-and-empirical-evaluation-5-320.jpg)


![Quantization Fundamentals: Scale Quantization
(Symmetric)
Neural Acceleration Study #3
• integer range [−127, 127]](https://image.slidesharecdn.com/integerquantizationfordeeplearninginferenceprinciplesandempinciplesandempiricalevaluation-201007135938/85/Integer-quantization-for-deep-learning-inference-principles-and-empirical-evaluation-8-320.jpg)


![Quantization Fundamentals: Tensor Quantization
Granularity
Neural Acceleration Study #3
• For activations, only per-tensor quantization is practical for
performance reasons.
• The number of rows depends on batch instances.
• Row count can vary at inference time.
• It prevents the per-row scaling factor from being computation
offline.
• (which would not be meaningful for different instances in a mini-
batch), whereas determining them online imposes a compute
overhead and in some cases results in poor accuracy (Dynamic
Quantization discussion in [58]).](https://image.slidesharecdn.com/integerquantizationfordeeplearninginferenceprinciplesandempinciplesandempiricalevaluation-201007135938/85/Integer-quantization-for-deep-learning-inference-principles-and-empirical-evaluation-11-320.jpg)
![Quantization Fundamentals: Tensor Quantization
Granularity
Neural Acceleration Study #3
• The corresponding granularity to per-column in convolutions is
per-kernel, or equivalently per-output-channel since each
kernel produces a separate output channel [27, 29].
• This is commonly referred to as “per-channel” weight
quantization in literature and we follow that convention [21,
25, 26, 38, 46]. We examine the granularity impact on accuracy
in Section 4.1.](https://image.slidesharecdn.com/integerquantizationfordeeplearninginferenceprinciplesandempinciplesandempiricalevaluation-201007135938/85/Integer-quantization-for-deep-learning-inference-principles-and-empirical-evaluation-12-320.jpg)


![Quantization Fundamentals: Calibration
Neural Acceleration Study #3
• Max: Use the maximum absolute value seen during calibration [52].
• Entropy: Use KL divergence to minimize information loss between the original floating-point
values and values that could be represented by the quantized format. This is the default method
used by TensorRT [36].
• Percentile: Set the range to a percentile of the distribution of absolute values seen during
calibration [33]. For example, 99% calibration would clip 1% of the largest magnitude values.
• Clipping the distribution trades off a large clipping error on a few outlier values for smaller
rounding errors on a majority of the values.](https://image.slidesharecdn.com/integerquantizationfordeeplearninginferenceprinciplesandempinciplesandempiricalevaluation-201007135938/85/Integer-quantization-for-deep-learning-inference-principles-and-empirical-evaluation-15-320.jpg)






![Techniques to Recover Accuracy: Quantization Aware
Training
Neural Acceleration Study #3
• Intuition for QAT
• the model has converged to a “narrow” minimum, since a small change in the weight leads to a large change in loss. By
training with quantization, we may potentially avoid these narrow minima by computing gradients with respect to the
quantized weights, as shown in Figure 6b. In doing so, narrow minima will result in larger gradients, potentially allowing
the model to explore the loss landscape for “wide” [22] or “flat” [16, 30] minima, where quantization points have lower
loss, and thus higher accuracy.](https://image.slidesharecdn.com/integerquantizationfordeeplearninginferenceprinciplesandempinciplesandempiricalevaluation-201007135938/85/Integer-quantization-for-deep-learning-inference-principles-and-empirical-evaluation-22-320.jpg)


![Techniques to Recover Accuracy: Learning Quantization
Parameters
Neural Acceleration Study #3
• Apply the same fine-tuning schedule as before.
• but allow the ranges of each quantized activation tensor to be learned along with the weights, as opposed to keeping
them fixed throughout fine-tuning.
• Use PACT[1]
• Fixed best: best accuracy with PTQ as described in Table 5.
• Use max calibration for activation quantization
• Learning the range results in higher accuracy than keeping it fixed for most networks.
• In best calibration cases, learning the ranges generate very similar results.
• Not to offer extra benefit for int8 over QAT if activation ranges are already carefully calibrated.
• PACT could yield better results with longer fine-tuning or a separate process.
[1] Pact: Parameterized clipping activation for quantized neural networks, ICLR18](https://image.slidesharecdn.com/integerquantizationfordeeplearninginferenceprinciplesandempinciplesandempiricalevaluation-201007135938/85/Integer-quantization-for-deep-learning-inference-principles-and-empirical-evaluation-25-320.jpg)
![Techniques to Recover Accuracy: Learning Quantization
Parameters
Neural Acceleration Study #3
• Complex fine-tuning procedure
[1] Pact: Parameterized clipping activation for quantized neural networks, ICLR18](https://image.slidesharecdn.com/integerquantizationfordeeplearninginferenceprinciplesandempinciplesandempiricalevaluation-201007135938/85/Integer-quantization-for-deep-learning-inference-principles-and-empirical-evaluation-26-320.jpg)
































More Related Content
What's hot (20)
Similar to Integer quantization for deep learning inference: principles and empirical evaluation (20)


















More from jemin lee (7)







Recently uploaded (20)








![Passive House Canada Conference 2025 Presentation [Final]_v4.ppt](https://cdn.slidesharecdn.com/ss_thumbnails/phcc2025presentationfinalv4-250512155835-5098a2a9-thumbnail.jpg?width=560&fit=bounds)











Integer quantization for deep learning inference: principles and empirical evaluation
- 1. INTEGER QUANTIZATION FOR DEEP LEARNING INFERENCE: PRINCIPLES AND EMPIRICAL EVALUATION NVIDIA, Georgia Tech. Arxiv 2020 Presenter: Jemin Lee https://leejaymin.github.io/index.html 7 Oct. 2020 Neural Acceleration Study Season #3
- 2. Contents • Introduction and Background • Quantization Fundamentals • Post-Training Quantization • Techniques to Recover Accuracy • Recommended Workflow • Conclusion Neural Acceleration Study #2
- 3. Introduction • Low-precision formats offer several performance benefits • First, many processors provide higher throughput math pipelines the low-bit formats, which can speed up math-intensive operations, such as convolutions and matrix multiplications. • Second, smaller word sizes reduce memory bandwidth pressure, improving performance for bandwidth-limited computations. • Third, smaller word sizes lead to lower memory size requirements, which can improve cache utilization as well as other aspects of memory-system operation. Neural Acceleration Study #3
- 4. Introduction • Review the mathematical fundamentals underlying various integer quantization choices (Section 3) as well as techniques for recovering accuracy lost due to quantization (Section 5). Section 6 combines this information into a recommended workflow. Neural Acceleration Study #3
- 5. Related Work • Uniform [7,59] quantization enables the use of integer or fixed- point math pipelines, allowing computation to be performed in the quantized domain. • Non-uniform[13,60,34,2] quantization requires dequantization, e.g. a codebook lookup, before doing computation in higher precision, limiting its benefits to model compression and bandwidth reduction. • This paper focuses on leveraging quantization to accelerate computation, so we will restrict our focus to uniform quantization schemes. • In this paper, we present an evaluation of int8 quantization on all of the major network architectures with both PTQ and QAT. Neural Acceleration Study #3
- 6. Quantization Fundamentals • Uniform quantization steps • 1) Choose the range of the real numbers to be quantized, clamping the values outside this range. • 2) Map the real values to integers representable by the bit-width of the quantized representation (round each mapped real value to the closest integer value). • Quantize: convert a real number to a quantized integer representation (e.g. from fp32 to int8). • Dequantize: convert a number from quantized integer representation to a real number (e.g. from int32 to fp16). Neural Acceleration Study #3
- 7. Quantization Fundamentals: Affine Quantization (Asymmetric) Neural Acceleration Study #3 • 𝒇 𝒙 = 𝒔 % 𝒙 + 𝒛 • S is scale factor and z is zero-point • Int8 • S= 𝟐𝟓𝟓 𝜷$𝜶 , z=-round(𝜷 " 𝒔)-128
- 8. Quantization Fundamentals: Scale Quantization (Symmetric) Neural Acceleration Study #3 • integer range [−127, 127]
- 9. Quantization Fundamentals: Tensor Quantization Granularity Neural Acceleration Study #3 • At the coarsest, per-tensor granularity, the same quantization parameters are shared by all elements in the tensor. • The finest granularity would have individual quantization parameters per element. • tensor - per row or per column for 2D matrices, • per channel for 3D (image-like) tensors.
- 10. Quantization Fundamentals: Tensor Quantization Granularity Neural Acceleration Study #3 • Integer matrix multiplication • per-row or per-tensor for activations • per-column or per-tensor for weights • The equation is as below:
- 11. Quantization Fundamentals: Tensor Quantization Granularity Neural Acceleration Study #3 • For activations, only per-tensor quantization is practical for performance reasons. • The number of rows depends on batch instances. • Row count can vary at inference time. • It prevents the per-row scaling factor from being computation offline. • (which would not be meaningful for different instances in a mini- batch), whereas determining them online imposes a compute overhead and in some cases results in poor accuracy (Dynamic Quantization discussion in [58]).
- 12. Quantization Fundamentals: Tensor Quantization Granularity Neural Acceleration Study #3 • The corresponding granularity to per-column in convolutions is per-kernel, or equivalently per-output-channel since each kernel produces a separate output channel [27, 29]. • This is commonly referred to as “per-channel” weight quantization in literature and we follow that convention [21, 25, 26, 38, 46]. We examine the granularity impact on accuracy in Section 4.1.
- 13. Quantization Fundamentals: Computational Cost of Affine Quantization Neural Acceleration Study #3 • Breakdown three terms: • the integer dot product, just as in scale quantization (Equation 10). • only integer weights and zero-points can be computed offline, only adding an element-wise addition at inference time. • If the layer has a bias then this term can be folded in without increasing inference cost. • involves the quantized input matrix Xq, and thus cannot be computed offline. • overhead, reducing or even eliminating the throughput advantage that integer math pipelines have over reduced precision floating-point. • extra computation is incurred only if affine quantization is used for the weight matrix. • Scale quantization for weights. • Affine quantization could be used for activations
- 15. Quantization Fundamentals: Calibration Neural Acceleration Study #3 • Max: Use the maximum absolute value seen during calibration [52]. • Entropy: Use KL divergence to minimize information loss between the original floating-point values and values that could be represented by the quantized format. This is the default method used by TensorRT [36]. • Percentile: Set the range to a percentile of the distribution of absolute values seen during calibration [33]. For example, 99% calibration would clip 1% of the largest magnitude values. • Clipping the distribution trades off a large clipping error on a few outlier values for smaller rounding errors on a majority of the values.
- 16. Post Training Quantization Neural Acceleration Study #3 • Quantization parameters are calibrated offline by processing the trained model weights and activations generated by running inference on a sample dataset, no further training is involved.
- 17. Post Training Quantization Neural Acceleration Study #3 • refer to the relative accuracy change, computed by (accint8 − accfp32)/accfp32
- 18. Post Training Quantization: Weight Quantization Neural Acceleration Study #3 • Int8 weights: max calibration • However, as BN parameters are learned per channel, their folding can result in significantly different weight value distributions across channels. • Table 4 reports per-channel (per-column for linear layers) granularity and indicates that max calibration is sufficient to maintain accuracy when quantizing weights to int8. The rest of the experiments in this paper use per-channel max calibration for weights.
- 19. Post Training Quantization: Activation Quantization Neural Acceleration Study #3 • For most of the networks, there is at least one activation calibration method that achieves acceptable accuracy, • except for MobileNets, EfficientNets, Transformer and BERT where the accuracy drop is larger than 1%. • no single calibration is best for all networks.
- 20. Techniques to Recover Accuracy Neural Acceleration Study #3 • Partial quantization: leaves the most sensitive layers unquantized • One also has an option to train networks with quantization • there are also approaches that jointly learn the model weights and quantization parameters.
- 21. Techniques to Recover Accuracy: Partial Quantization Neural Acceleration Study #3 • Partial quantization: leaves the most sensitive layers unquantized
- 22. Techniques to Recover Accuracy: Quantization Aware Training Neural Acceleration Study #3 • Intuition for QAT • the model has converged to a “narrow” minimum, since a small change in the weight leads to a large change in loss. By training with quantization, we may potentially avoid these narrow minima by computing gradients with respect to the quantized weights, as shown in Figure 6b. In doing so, narrow minima will result in larger gradients, potentially allowing the model to explore the loss landscape for “wide” [22] or “flat” [16, 30] minima, where quantization points have lower loss, and thus higher accuracy.
- 23. Techniques to Recover Accuracy: Quantization Aware Training Neural Acceleration Study #3 • Fake Quantization • FakeQuant(x) = DQ(Q(x)) = INT8(s*x) / s • Problem: The quantization function is non-differentiable • Solution: Straight Through Estimation (STE)
- 24. Techniques to Recover Accuracy: Quantization Aware Training Neural Acceleration Study #3 • Result
- 25. Techniques to Recover Accuracy: Learning Quantization Parameters Neural Acceleration Study #3 • Apply the same fine-tuning schedule as before. • but allow the ranges of each quantized activation tensor to be learned along with the weights, as opposed to keeping them fixed throughout fine-tuning. • Use PACT[1] • Fixed best: best accuracy with PTQ as described in Table 5. • Use max calibration for activation quantization • Learning the range results in higher accuracy than keeping it fixed for most networks. • In best calibration cases, learning the ranges generate very similar results. • Not to offer extra benefit for int8 over QAT if activation ranges are already carefully calibrated. • PACT could yield better results with longer fine-tuning or a separate process. [1] Pact: Parameterized clipping activation for quantized neural networks, ICLR18
- 26. Techniques to Recover Accuracy: Learning Quantization Parameters Neural Acceleration Study #3 • Complex fine-tuning procedure [1] Pact: Parameterized clipping activation for quantized neural networks, ICLR18
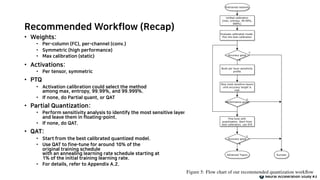
- 27. Recommended Workflow (Recap) • Weights: • Per-column (FC), per-channel (conv.) • Symmetric (high performance) • Max calibration (static) • Activations: • Per tensor, symmetric • PTQ • Activation calibration could select the method among max, entropy, 99.99%, and 99.999%. • If none, do Partial quant, or QAT • Partial Quantization: • Perform sensitivity analysis to identify the most sensitive layers and leave them in floating-point. • If none, do QAT. • QAT: • Start from the best calibrated quantized model. • Use QAT to fine-tune for around 10% of the original training schedule with an annealing learning rate schedule starting at 1% of the initial training learning rate. • For details, refer to Appendix A.2. Neural Acceleration Study #3
- 28. Conclusion • Review the mathematical background for integer quantization of neural networks, as well as some performance-related reasons for choosing quantization parameters. • Empirically evaluate various choices for int8 quantization of a variety of models, leading to a quantization workflow proposal. • MobileNets and BERT are challengeable for quantization. • Workflow composes post-training quantization, partial quantization, and quantization-aware fine-tuning techniques. • Some more complex techniques, such as ADMM and distillation, were not required for int8 quantization of these models. • However, these techniques should be evaluated when quantizing to even lower-bit integer representations, which we leave to future work. Neural Acceleration Study #3
- 29. Thank you Neural Acceleration Study #2