Integrate Solr with real-time stream processing applications
14 likes•8,719 views

The document discusses integrating Apache Storm with Apache Solr for real-time stream processing applications. It provides an example of building a Storm topology that listens to click events from a URL shortener, counts the frequency of pages in a time window, ranks the top sites, and persists the results to Solr for visualization. The key points covered are using Spring to simplify building Storm topologies, integrating with Solr for indexing and search, and unit testing streaming data providers.




































Integrate Solr with real-time stream processing applications
- 2. INTEGRATE SOLR WITH REAL-TIME STREAM PROCESSING APPLICATIONS Timothy Potter @thelabdude linkedin.com/thelabdude
- 3. whoami independent consultant search / big data projects soon to be joining engineering team @LucidWorks co-author Solr In Action previously big data architect Dachis Group
- 4. my storm story re-designed a complex batch-oriented indexing pipeline based on Hadoop (Oozie, Pig, Hive, Sqoop) to real-time storm topology
- 5. agenda walk through how to develop a storm topology common integration points with Solr (near real-time indexing, percolator, real-time get)
- 6. example listen to click events from 1.usa.gov URL shortener (bit.ly) to determine trending US government sites stream of click events: http://developer.usa.gov/1usagov http://www.smartgrid.gov -> http://1.usa.gov/ayu0Ru
- 7. beyond word count tackle real challenges you’ll encounter when developing a storm topology and what about ... unit testing, dependency injection, measure runtime behavior of your components, separation of concerns, reducing boilerplate, hiding complexity ...
- 8. storm open source distributed computation system scalability, fault-tolerance, guaranteed message processing (optional)
- 9. storm primitives • • • • • tuple: ordered list of values stream: unbounded sequence of tuples spout: emit a stream of tuples (source) bolt: performs some operation on each tuple topology: dag of spouts and tuples
- 10. solution requirements • • • • • receive click events from 1.usa.gov stream count frequency of pages in a time window rank top N sites per time window extract title, body text, image for each link persist rankings and metadata for visualization
- 11. trending snapshot (sept 12, 2013)
- 13. embed.ly API bolt spout field grouping bit.ly hash global grouping EnrichLink Bolt 1.usa.gov Spout field grouping bit.ly hash provided by in the storm-starter project Solr Indexing Bolt field grouping obj Rolling Count Bolt Intermediate Rankings Bolt Total Rankings Bolt stream data store Solr grouping global grouping Persist Rankings Bolt Metrics DB
- 14. stream grouping • • • • shuffle: random distribution of tuples to all instances of a bolt field(s): group tuples by one or more fields in common global: reduce down to one all: replicate stream to all instances of a bolt source: https://github.com/nathanmarz/storm/wiki/Concepts
- 15. useful storm concepts bolts can receive input from many spouts tuples in a stream can be grouped together streams can be split and joined bolts can inject new tuples into the stream components can be distributed across a cluster at a configurable parallelism level • optionally, storm keeps track of each tuple emitted by a spout (ack or fail) • • • • •
- 16. tools • • • • • Spring framework – dependency injection, configuration, unit testing, mature, etc. Groovy – keeps your code tidy and elegant Mockito – ignore stuff your test doesn’t care about Netty – fast & powerful NIO networking library Coda Hale metrics – get visibility into how your bolts and spouts are performing (at a very low-level)
- 17. spout easy! just produce a stream of tuples ... and ... avoid blocking when waiting for more data, ease off throttle if topology is not processing fast enough, deal with failed tuples, choose if it should use message Ids for each tuple emitted, data model / schema, etc ...
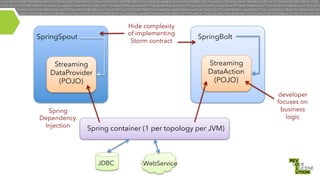
- 18. Hide complexity of implementing Storm contract SpringSpout Streaming DataAction (POJO) Streaming DataProvider (POJO) Spring Dependency Injection SpringBolt developer focuses on business logic Spring container (1 per topology per JVM) JDBC WebService
- 19. streaming data provider class OneUsaGovStreamingDataProvider implements StreamingDataProvider, MessageHandler { Spring Dependency Injection MessageStream messageStream ... void open(Map stormConf) { messageStream.receive(this) } non-blocking call to get the boolean next(NamedValues nv) { next message from 1.usa.gov String msg = queue.poll() if (msg) { OneUsaGovRequest req = objectMapper.readValue(msg, OneUsaGovRequest) if (req != null && req.globalBitlyHash != null) { nv.set(OneUsaGovTopology.GLOBAL_BITLY_HASH, req.globalBitlyHash) nv.set(OneUsaGovTopology.JSON_PAYLOAD, req) return true use Jackson JSON parser } to create an object from the } raw incoming data return false } void handleMessage(String msg) { queue.offer(msg) }
- 20. jackson json to java @JsonIgnoreProperties(ignoreUnknown = true) class OneUsaGovRequest implements Serializable { @JsonProperty("a") String userAgent; @JsonProperty("c") Spring converts json to java object for you: String countryCode; <bean id="restTemplate" @JsonProperty("nk") class="org.springframework.web.client.RestTemplate"> int knownUser; <property name="messageConverters"> <list> @JsonProperty("g") <bean id="messageConverter” String globalBitlyHash; class="...json.MappingJackson2HttpMessageConverter"> </bean> @JsonProperty("h") </list> String encodingUserBitlyHash; </property> </bean> @JsonProperty("l") String encodingUserLogin; ... }
- 21. spout data provider spring-managed bean <bean id="oneUsaGovStreamingDataProvider" class="com.bigdatajumpstart.storm.OneUsaGovStreamingDataProvider"> <property name="messageStream"> <bean class="com.bigdatajumpstart.netty.HttpClient"> <constructor-‐arg index="0" value="${streamUrl}"/> </bean> </property> </bean> Note: when building the StormTopology to submit to Storm, you do: builder.setSpout("1.usa.gov-‐spout", new SpringSpout("oneUsaGovStreamingDataProvider", spoutFields), 1)
- 22. spout data provider unit test class OneUsaGovStreamingDataProviderTest extends StreamingDataProviderTestBase { @Test void testDataProvider() { String jsonStr = '''{ "a": "user-‐agent", "c": "US", "nk": 0, "tz": "America/Los_Angeles", "gr": "OR", "g": "2BktiW", "h": "12Me4B2", "l": "usairforce", "al": "en-‐us", "hh": "1.usa.gov", "r": "http://example.com/foo", ... }''' OneUsaGovStreamingDataProvider dataProvider = new OneUsaGovStreamingDataProvider() dataProvider.setMessageStream(mock(MessageStream)) dataProvider.open(stormConf) // Config setup in base class dataProvider.handleMessage(jsonStr) NamedValues record = new NamedValues(OneUsaGovTopology.spoutFields) assertTrue dataProvider.next(record) ... } } mock json to simulate data from 1.usa.gov feed use Mockito to satisfy dependencies not needed for this test asserts to verify data provider works correctly
- 23. rolling count bolt • • • • counts frequency of links in a sliding time window emits topN in current window every M seconds uses tick tuple trick provided by Storm to emit every M seconds (configurable) provided with the storm-starter project http://www.michael-noll.com/blog/2013/01/18/implementing-real-time-trending-topics-in-storm/
- 24. enrich link metadata bolt • • • • • calls out to embed.ly API caches results locally in the bolt instance relies on field grouping (incoming tuples) outputs data to be indexed in Solr benefits from parallelism to enrich more links concurrently (watch those rate limits)
- 25. embed.ly service class EmbedlyService { @Autowired RestTemplate restTemplate integrate coda hale metrics String apiKey private Timer apiTimer = MetricsSupport.timer(EmbedlyService, "apiCall") Embedly getLinkMetadata(String link) { String urlEncoded = URLEncoder.encode(link,"UTF-‐8") URI uri = new URI("https://api.embed.ly/1/oembed?key=${apiKey}&url=${urlEncoded}") Embedly embedly = null MetricsSupport.withTimer(apiTimer, { embedly = restTemplate.getForObject(uri, Embedly) }) return embedly simple closure to time our } requests to the Web service
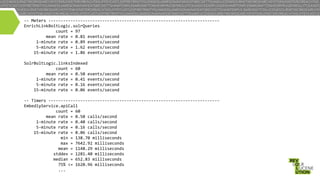
- 26. metrics • • • • capture runtime behavior of the components in your topology Coda Hale metrics - http://metrics.codahale.com/ output metrics every N minutes report metrics to JMX, ganglia, graphite, etc
- 27. -‐-‐ Meters -‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐ EnrichLinkBoltLogic.solrQueries count = 97 mean rate = 0.81 events/second 1-‐minute rate = 0.89 events/second 5-‐minute rate = 1.62 events/second 15-‐minute rate = 1.86 events/second SolrBoltLogic.linksIndexed count = 60 mean rate = 0.50 events/second 1-‐minute rate = 0.41 events/second 5-‐minute rate = 0.16 events/second 15-‐minute rate = 0.06 events/second -‐-‐ Timers -‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐ EmbedlyService.apiCall count = 60 mean rate = 0.50 calls/second 1-‐minute rate = 0.40 calls/second 5-‐minute rate = 0.16 calls/second 15-‐minute rate = 0.06 calls/second min = 138.70 milliseconds max = 7642.92 milliseconds mean = 1148.29 milliseconds stddev = 1281.40 milliseconds median = 652.83 milliseconds 75% <= 1620.96 milliseconds ...
- 28. storm cluster concepts • • • • • • nimbus: master node (~job tracker in Hadoop) zookeeper: cluster management / coordination supervisor: one per node in the cluster to manage worker processes worker: one or more per supervisor (JVM process) executor: thread in worker task: work performed by a spout or bolt
- 29. Topology JAR Nimbus Node 1 Zookeeper Supervisor (1 per node) Each component (spout or bolt) is distributed across a cluster of workers based on a configurable parallelism Worker 1 (port 6701) executor (thread) JVM process ... N workers ... M nodes
- 30. @Override StormTopology build(StreamingApp app) throws Exception { parallelism hint to the framework ... (can be rebalanced) TopologyBuilder builder = new TopologyBuilder() builder.setSpout("1.usa.gov-‐spout", new SpringSpout("oneUsaGovStreamingDataProvider", spoutFields), 1) builder.setBolt("enrich-‐link-‐bolt", new SpringBolt("enrichLinkAction", enrichedLinkFields), 3) .fieldsGrouping("1.usa.gov-‐spout", globalBitlyHashGrouping) ...
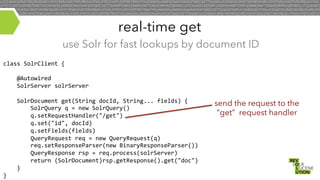
- 31. solr integration points • • • real-time get near real-time indexing (NRT) percolate (match incoming docs to pre-existing queries)
- 32. real-time get use Solr for fast lookups by document ID class SolrClient { @Autowired SolrServer solrServer SolrDocument get(String docId, String... fields) { SolrQuery q = new SolrQuery() q.setRequestHandler("/get") q.set("id", docId) q.setFields(fields) QueryRequest req = new QueryRequest(q) req.setResponseParser(new BinaryResponseParser()) QueryResponse rsp = req.process(solrServer) return (SolrDocument)rsp.getResponse().get("doc") } } send the request to the “get” request handler
- 33. near real-time indexing • If possible, use CloudSolrServer to route documents directly to the correct shard leaders (SOLR-4816) • Use <openSearcher>false</openSearcher> for auto “hard” commits • Use auto soft commits as needed • Use parallelism of Storm bolt to distribute indexing work to N nodes http://searchhub.org/2013/08/23/understanding-transaction-logs-softcommit-and-commit-in-sorlcloud/
- 34. percolate • match incoming documents to pre-configured queries (inverted search) – example: Is this tweet related to campaign Y for brand X? • use storm’s distributed computation support to evaluate M pre-configured queries per doc
- 35. two possible approaches • Lucene-only solution using MemoryIndex – See presentation by Charlie Hull and Alan Woodward • EmbeddedSolrServer – Full solrconfig.xml / schema.xml – RAMDirectory – Relies on Storm to scale up documents / second – Easy solution for up to a few thousand queries
- 36. PercolatorBolt 1 Embedded SolrServer Twi"er Spout random stream grouping ... Pre-‐configured queries stored in a database Could be 100’s of these PercolatorBolt N Embedded SolrServer ZeroMQ pub/sub to push query changes to percolator
- 37. tick tuples • send a special kind of tuple to a bolt every N seconds if (TupleHelpers.isTickTuple(input)) { // do special work } used in percolator to delete accumulated documents every minute or so ...
- 38. references • Storm Wiki • https://github.com/nathanmarz/storm/wiki/Documentation • Overview: Krishna Gade • http://www.slideshare.net/KrishnaGade2/storm-at-twitter • Trending Topics: Michael Knoll • http://www.michael-noll.com/blog/2013/01/18/implementing-real-timetrending-topics-in-storm/ • Understanding Parallelism: Michael Knoll • http://www.michael-noll.com/blog/2012/10/16/understanding-theparallelism-of-a-storm-topology/
- 39. Q&A get the code: https://github.com/thelabdude/lsrdublin Manning coupon codes for conference related books: h"p://deals.manningpublica8ons.com/Revolu8onsEU2013.html