Interactive Realtime Dashboards on Data Streams using Kafka, Druid and Superset
Download as PPTX, PDF23 likes3,649 views

The document discusses building real-time dashboards on data streams. It describes using Apache Kafka to ingest streaming data from Wikipedia edits. The data is enriched using Kafka Streams and stored in Apache Druid for powering interactive visualizations in Superset. Key components are Kafka for the event flow, Kafka Streams for processing, Druid for the data store, and Superset for visualization.



![© Hortonworks Inc. 2011 – 2016. All Rights Reserved
Step by Step Breakdown
Consume Events
Enrich / Transform
(Add Geolocation
from IP Address)
Store Events
Visualize Events
Sample Event : [[Eoghan Harris]] https://en.wikipedia.org/w/index.php?diff=792474242&oldid=787592607 * 7.114.169.238 * (+167) Added fact](https://image.slidesharecdn.com/fifthelephantfinal-170728065349/85/Interactive-Realtime-Dashboards-on-Data-Streams-using-Kafka-Druid-and-Superset-4-320.jpg)















![© Hortonworks Inc. 2011 – 2016. All Rights Reserved21
Dictionary Encoding
Create and store Ids for each value
e.g. page column
Values - Justin Bieber, Ke$ha, Selena Gomes
Encoding - Justin Bieber : 0, Ke$ha: 1, Selena Gomes: 2
Column Data - [0 0 0 1 1 2]
city column - [0 0 0 1 1 1]
timestamp page language city country … added deleted
2011-01-01T00:01:35Z Justin Bieber en SF USA 10 65
2011-01-01T00:03:63Z Justin Bieber en SF USA 15 62
2011-01-01T00:04:51Z Justin Bieber en SF USA 32 45
2011-01-01T00:05:35Z Ke$ha en Calgary CA 17 87
2011-01-01T00:06:41Z Ke$ha en Calgary CA 43 99
2011-01-02T00:08:35Z Selena Gomes en Calgary CA 12 53](https://image.slidesharecdn.com/fifthelephantfinal-170728065349/85/Interactive-Realtime-Dashboards-on-Data-Streams-using-Kafka-Druid-and-Superset-21-320.jpg)
![© Hortonworks Inc. 2011 – 2016. All Rights Reserved22
Bitmap Indices
Store Bitmap Indices for each value
Justin Bieber -> [0, 1, 2] -> [1 1 1 0 0 0]
Ke$ha -> [3, 4] -> [0 0 0 1 1 0]
Selena Gomes -> [5] -> [0 0 0 0 0 1]
Queries
Justin Bieber or Ke$ha -> [1 1 1 0 0 0] OR [0 0 0 1 1 0] -> [1 1 1 1 1 0]
language = en and country = CA -> [1 1 1 1 1 1] AND [0 0 0 1 1 1] -> [0 0 0 1 1 1]
Indexes compressed with Concise or Roaring encoding
timestamp page language city country … added deleted
2011-01-01T00:01:35Z Justin Bieber en SF USA 10 65
2011-01-01T00:03:63Z Justin Bieber en SF USA 15 62
2011-01-01T00:04:51Z Justin Bieber en SF USA 32 45
2011-01-01T00:01:35Z Ke$ha en Calgary CA 17 87
2011-01-01T00:01:35Z Ke$ha en Calgary CA 43 99
2011-01-01T00:01:35Z Selena Gomes en Calgary CA 12 53](https://image.slidesharecdn.com/fifthelephantfinal-170728065349/85/Interactive-Realtime-Dashboards-on-Data-Streams-using-Kafka-Druid-and-Superset-22-320.jpg)














Interactive Realtime Dashboards on Data Streams using Kafka, Druid and Superset
- 1. Interactive Realtime Dashboards on Data Streams Nishant Bangarwa Hortonworks Druid Committer, PMC June 2017
- 2. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Sample Data Stream : Wikipedia Edits
- 3. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Demo: Wikipedia Real-Time Dashboard (Accelerated 30x)
- 4. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Step by Step Breakdown Consume Events Enrich / Transform (Add Geolocation from IP Address) Store Events Visualize Events Sample Event : [[Eoghan Harris]] https://en.wikipedia.org/w/index.php?diff=792474242&oldid=787592607 * 7.114.169.238 * (+167) Added fact
- 5. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Required Components Event Flow Event Processing Data Store Visualization Layer
- 6. © Hortonworks Inc. 2011 – 2016. All Rights Reserved6 Event Flow
- 7. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Event Flow : Requirements Event Producers Queue Event Consumers Low latency High Throughput Failure Handling Message delivery guarantees – Message Ordering Atleast Once, Exactly once, Atmost Once Scalability Fault tolerant
- 8. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Apache Kafka
- 9. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Apache Kafka Low Latency High Throughput Message Delivery guarantees At-least once Exactly Once (Fully introduced in apache kafka v0.11.0 June 2017) Reliable design to Handle Failures Message Acks between producers and brokers Data Replication on brokers Consumers can Read from any desired offset Handle multiple producers/consumers Scalable
- 10. © Hortonworks Inc. 2011 – 2016. All Rights Reserved10 Event Processing
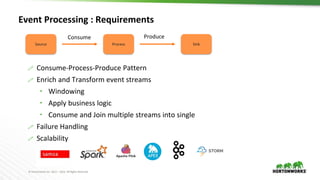
- 11. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Event Processing : Requirements Consume-Process-Produce Pattern Enrich and Transform event streams Windowing Apply business logic Consume and Join multiple streams into single Failure Handling Scalability Source Process Sink Consume Produce
- 12. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Kafka Streams Rich Lightweight Stream processing library Event-at-a-time Stateful processing : windowing, joining, aggregation operators Local state using RocksDb Backed by changelog in kafka Highly scalable, distributed, fault tolerant Compared to a standard Kafka consumer: Higher level: faster to build a sophisticated app Less control for very fine-grained consumption
- 13. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Kafka Streams : Wikipedia Data Enrichment
- 14. © Hortonworks Inc. 2011 – 2016. All Rights Reserved14 Data Store
- 15. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Data Store : Requirements Processed Events Data Store Queries Ability to ingest Streaming data Power Interactive dashboards Sub-Second Query Response time Ad-hoc arbitrary slicing and dicing of data Data Freshness Summarized/aggregated data is queried Scalability High Availability
- 16. © Hortonworks Inc. 2011 – 2016. All Rights Reserved16 Druid Column-oriented distributed datastore Sub-Second query times Realtime streaming ingestion Arbitrary slicing and dicing of data Automatic Data Summarization Approximate algorithms (hyperLogLog, theta) Scalable to petabytes of data Highly available
- 17. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Suitable Use Cases Powering Interactive user facing applications Arbitrary slicing and dicing of large datasets User behavior analysis measuring distinct counts retention analysis funnel analysis A/B testing Exploratory analytics/root cause analysis Not interested in dumping entire dataset
- 18. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Druid: Segments Data in Druid is stored in Segment Files. Partitioned by time Ideally, segment files are each smaller than 1GB. If files are large, smaller time partitions are needed. Time Segment 1: Monday Segment 2: Tuesday Segment 3: Wednesday Segment 4: Thursday Segment 5_2: Friday Segment 5_1: Friday
- 19. © Hortonworks Inc. 2011 – 2016. All Rights Reserved19 Example Wikipedia Edit Dataset timestamp page language city country … added deleted 2011-01-01T00:01:35Z Justin Bieber en SF USA 10 65 2011-01-01T00:03:63Z Justin Bieber en SF USA 15 62 2011-01-01T00:04:51Z Justin Bieber en SF USA 32 45 2011-01-01T00:05:35Z Ke$ha en Calgary CA 17 87 2011-01-01T00:06:41Z Ke$ha en Calgary CA 43 99 2011-01-02T00:08:35Z Selena Gomes en Calgary CA 12 53 Timestamp Dimensions Metrics
- 20. © Hortonworks Inc. 2011 – 2016. All Rights Reserved20 Data Rollup timestamp page language city country … added deleted 2011-01-01T00:01:35Z Justin Bieber en SF USA 10 65 2011-01-01T00:03:63Z Justin Bieber en SF USA 15 62 2011-01-01T00:04:51Z Justin Bieber en SF USA 32 45 2011-01-01T00:05:35Z Ke$ha en Calgary CA 17 87 2011-01-01T00:06:41Z Ke$ha en Calgary CA 43 99 2011-01-02T00:08:35Z Selena Gomes en Calgary CA 12 53 timestamp page language city country count sum_added sum_deleted min_added max_added …. 2011-01-01T00:00:00Z Justin Bieber en SF USA 3 57 172 10 32 2011-01-01T00:00:00Z Ke$ha en Calgary CA 2 60 186 17 43 2011-01-02T00:00:00Z Selena Gomes en Calgary CA 1 12 53 12 12 Rollup by hour
- 21. © Hortonworks Inc. 2011 – 2016. All Rights Reserved21 Dictionary Encoding Create and store Ids for each value e.g. page column Values - Justin Bieber, Ke$ha, Selena Gomes Encoding - Justin Bieber : 0, Ke$ha: 1, Selena Gomes: 2 Column Data - [0 0 0 1 1 2] city column - [0 0 0 1 1 1] timestamp page language city country … added deleted 2011-01-01T00:01:35Z Justin Bieber en SF USA 10 65 2011-01-01T00:03:63Z Justin Bieber en SF USA 15 62 2011-01-01T00:04:51Z Justin Bieber en SF USA 32 45 2011-01-01T00:05:35Z Ke$ha en Calgary CA 17 87 2011-01-01T00:06:41Z Ke$ha en Calgary CA 43 99 2011-01-02T00:08:35Z Selena Gomes en Calgary CA 12 53
- 22. © Hortonworks Inc. 2011 – 2016. All Rights Reserved22 Bitmap Indices Store Bitmap Indices for each value Justin Bieber -> [0, 1, 2] -> [1 1 1 0 0 0] Ke$ha -> [3, 4] -> [0 0 0 1 1 0] Selena Gomes -> [5] -> [0 0 0 0 0 1] Queries Justin Bieber or Ke$ha -> [1 1 1 0 0 0] OR [0 0 0 1 1 0] -> [1 1 1 1 1 0] language = en and country = CA -> [1 1 1 1 1 1] AND [0 0 0 1 1 1] -> [0 0 0 1 1 1] Indexes compressed with Concise or Roaring encoding timestamp page language city country … added deleted 2011-01-01T00:01:35Z Justin Bieber en SF USA 10 65 2011-01-01T00:03:63Z Justin Bieber en SF USA 15 62 2011-01-01T00:04:51Z Justin Bieber en SF USA 32 45 2011-01-01T00:01:35Z Ke$ha en Calgary CA 17 87 2011-01-01T00:01:35Z Ke$ha en Calgary CA 43 99 2011-01-01T00:01:35Z Selena Gomes en Calgary CA 12 53
- 23. © Hortonworks Inc. 2011 – 2016. All Rights Reserved23 Approximate Sketch Columns timestamp page userid language city country … added deleted 2011-01-01T00:01:35Z Justin Bieber user1111111 en SF USA 10 65 2011-01-01T00:03:63Z Justin Bieber user1111111 en SF USA 15 62 2011-01-01T00:04:51Z Justin Bieber user2222222 en SF USA 32 45 2011-01-01T00:05:35Z Ke$ha user3333333 en Calgary CA 17 87 2011-01-01T00:06:41Z Ke$ha user4444444 en Calgary CA 43 99 2011-01-02T00:08:35Z Selena Gomes user1111111 en Calgary CA 12 53 timestamp page language city country count sum_added sum_delete d min_added Userid_sket ch …. 2011-01-01T00:00:00Z Justin Bieber en SF USA 3 57 172 10 {sketch} 2011-01-01T00:00:00Z Ke$ha en Calgary CA 2 60 186 17 {sketch} 2011-01-02T00:00:00Z Selena Gomes en Calgary CA 1 12 53 12 {sketch} Rollup by hour
- 24. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Approximate Algorithms Store Sketch objects, instead of raw column values Better rollup for high cardinality columns e.g userid Reduced storage size Use Cases Fast approximate distinct counts Approximate histograms Funnel/retention analysis Limitation Not possible to do exact counts filter on individual row values
- 25. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Realtime Nodes Historical Nodes 25 Druid Architecture Batch Data Event Historical Nodes Broker Nodes Realtime Index Tasks Streaming Data Historical Nodes Handoff
- 26. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Performance and Scalability : Fast Facts Most Events per Day 300 Billion Events / Day (Metamarkets) Most Computed Metrics 1 Billion Metrics / Min (Jolata) Largest Cluster 200 Nodes (Metamarkets) Largest Hourly Ingestion 2TB per Hour (Netflix)
- 27. © Hortonworks Inc. 2011 – 2016. All Rights Reserved27 Companies Using Druid
- 28. © Hortonworks Inc. 2011 – 2016. All Rights Reserved28 Visualization Layer
- 29. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Visualization Layer : Requirements Rich dashboarding capabilities Work with multiple datasoucres Security/Access control Allow for extension Add custom visualizations Data Store Visualization Layer User Dashboards
- 30. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Superset Python backend Flask app builder Authentication Pandas for rich analytics SqlAlchemy for SQL toolkit Javascript frontend React, NVD3 Deep integration with Druid
- 31. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Superset Rich Dashboarding Capabilities: Treemaps
- 32. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Superset Rich Dashboarding Capabilities: Sunburst
- 33. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Superset UI Provides Powerful Visualizations Rich library of dashboard visualizations: Basic: • Bar Charts • Pie Charts • Line Charts Advanced: • Sankey Diagrams • Treemaps • Sunburst • Heatmaps And More!
- 34. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Wikipedia Real-Time Dashboard Kafka Connect IP-to- Geolocation Processor wikipedia-raw topic wikipedia-raw topic wikipedia-enriched topic wikipedia-enriched topic
- 35. © Hortonworks Inc. 2011 – 2016. All Rights Reserved Project Websites Kafka - http://kafka.apache.org Druid - http://druid.io Superset - http://superset.incubator.apache.org
- 36. © Hortonworks Inc. 2011 – 2016. All Rights Reserved36 Thank you ! Questions ? Twitter - @NishantBangarwa Email - [email protected] Linkedin - https://www.linkedin.com/in/nishant-bangarwa Off The Record (OTR) session Experiences and challenges in working with Druid at 03:25 PM - 04:10 PM on 28 July, 2017 in Room 1 MLR Convention Centre, Whitefield