Intro to big data analytics using microsoft machine learning server with spark

Alex Zeltov - Intro to Big Data Analytics using Microsoft Machine Learning Server with Spark By combining enterprise-scale R analytics software with the power of Apache Hadoop and Apache Spark, Microsoft R Server for HDP or HDInsight gives you the scale and performance you need. Multi-threaded math libraries and transparent parallelization in R Server handle up to 1000x more data and up to 50x faster speeds than open-source R, which helps you to train more accurate models for better predictions. R Server works with the open-source R language, so all of your R scripts run without changes. Microsoft Machine Learning Server is your flexible enterprise platform for analyzing data at scale, building intelligent apps, and discovering valuable insights across your business with full support for Python and R. Machine Learning Server meets the needs of all constituents of the process – from data engineers and data scientists to line-of-business programmers and IT professionals. It offers a choice of languages and features algorithmic innovation that brings the best of open source and proprietary worlds together. R support is built on a legacy of Microsoft R Server 9.x and Revolution R Enterprise products. Significant machine learning and AI capabilities enhancements have been made in every release. In 9.2.1, Machine Learning Server adds support for the full data science lifecycle of your Python-based analytics. This meetup will NOT be a data science intro or R intro to programming. It is about working with data and big data on MLS . - How to Scale R - Work with R and Hadoop + Spark -Demo of MLS on HDP/HDInsight server with RStudio - How to operationalize deploying models using MLS Webservice operationalization features on MLS Server or on the cloud Azure ML (PaaS) offering. Speaker Bio: Alex Zeltov is Big Data Solutions Architect / Software Engineer / Programmer Analyst / Data Scientist with over 19 years of industry experience in Information Technology and most recently in Big Data and Predictive Analytics. He currently works as Global black belt Technical Specialist in Microsoft where he concentrates on Big Data and Advanced Analytics use cases. Previously to joining Microsoft he worked as a Sr. Solutions Engineer at Hortonworks where he specialized in HDP and HDF platforms.















































![SQL Server
2017 setup
Install Machine
Learning Services
(In-Database)
Consent to install
Microsoft R
Open/Python
Optional: Install R
packages
on SQL Server
2017 machine
Database
configuration
Enable R
language extension
in database
Configure path
for RRO runtime
in database
Grant EXECUTE
EXTERNAL SCRIPT
permission to users
CREATE EXTERNAL EXTENSION [R]
USING SYSTEM LAUNCHER
WITH (RUNTIME_PATH =
'c:revolutionbin‘)
GRANT EXECUTE SCRIPT ON
EXTERNAL EXTENSION::R TO
DataScientistsRole;
/* User-defined role / users */](https://image.slidesharecdn.com/introtobigdataanalyticsusingmicrosoftmachinelearningserverwithspark2-180427152029/85/Intro-to-big-data-analytics-using-microsoft-machine-learning-server-with-spark-63-320.jpg)













































More Related Content
What's hot (20)
Similar to Intro to big data analytics using microsoft machine learning server with spark (20)


















Recently uploaded (20)




















Intro to big data analytics using microsoft machine learning server with spark
- 2. Disclaimer: This is NOT an R , Python , Hadoop or Spark Overview
- 3. • From its inception, R was designed to use only a single thread (processor) at a time. Even today, R works that way unless linked with multi-threaded BLAS/LAPACK libraries. • Microsoft R Open : automatically use all available cores and processors to significantly reduce computation times — without the need to change a line of your R code.
- 4. broad range of scalable and distributed R & Python functions
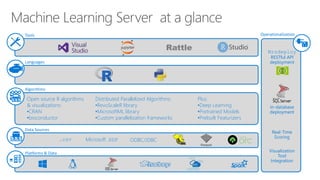
- 5. Platforms & Data Tools Languages Algorithms Data Sources Rattle Mrsdeploy RESTful API deployment Real-Time Scoring Visualization Tool Integration .csv Microsoft .XDF In-database deployment Operationalization Distributed Parallelized Algorithms: •RevoScaleR library •MicrosoftML library •Custom parallelization frameworks Open source R algorithms & visualizations: •CRAN •bioconductor Plus: •Deep Learning •Pretrained Models •Prebuilt Featurizers ODBC/JDBC
- 6. • Small data many models • Hybrid • Large scale machine learning • Batch training and scoring • Model deployment for LOB applications
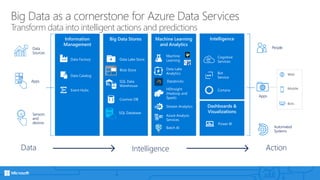
- 8. Machine Learning and Analytics Big Data StoresInformation Management Big Data as a cornerstone for Azure Data Services Transform data into intelligent actions and predictions Action People Automated Systems Apps Web Mobile Bots Event Hubs Data Catalog Data Factory HDInsight (Hadoop and Spark) Stream Analytics Intelligence Data Lake Analytics Machine Learning SQL Data Warehouse Data Lake Store Data Sources Apps Sensors and devices Data Cosmos DB Intelligence Dashboards & Visualizations Cortana Bot Service Cognitive Services Power BI Azure Analysis Services SQL Database Batch AI Blob Store Databricks
- 9. • • • Support: • Inadequacy of Community Support • Application Governance: • Commonly prohibited in production systems without commercial vendor
- 11. • Support for 1.6, 2.0, 2.1 and 2.2 • Support for all three distributions of Hadoop on all three flavors of Linux • Inherits high-performance big-data processing characteristics from Spark • Easily integrate with different data sources e.g. HIVE, Parquet , Orc, XDF, csv, etc… • E2E framework for running parallel workloads • Interoperability with Sparklyr and H2O • Best in-class operationalization • Guaranteed backward compatibility
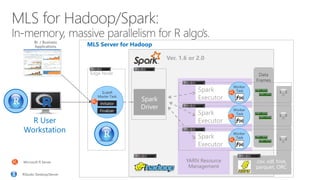
- 12. R User Workstation MLS Server for Hadoop Data Frames YARN Resource Management Spark Executor Worker Task Spark Executor Worker Task Spark Executor Worker Task .csv, xdf, hive, parquet, ORC ScaleR Master Task Finalizer Initiator Edge Node Spark Driver Ver. 1.6 or 2.0 RStudio Desktop/Server Microsoft R Server
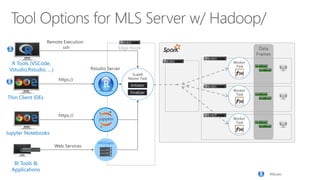
- 13. Data Frames Worker Task Worker Task Worker Task ScaleR Master Task Finalizer Initiator Remote Execution: ssh Web Services MRSDeplo y R Tools (VSCode, Vstudio,Rstudio, …) BI Tools & Applications Jupyter Notebooks Thin Client IDEs https:// https:// Edge Node RStudio Rstudio Server
- 14. Built-in remote execute functions in R Client/R Server Tools to reconcile local and remote Execute .R script or interactive R commands Return results to local Generate working snapshots for resume and reuse IDE agnostic MLS Server configured to (Support Window Server, Linux Server, Hadoop ) Remote Execute R Scripts Execute R Scripts Snapshot remote env. Logout remote server Login remote server Generate Diff report Reconcile Environment
- 15. DEMO : Interacting with MLS Server Rstudio Desktop (Remote Context), Rstudio Server
- 16. ### SETUP HADOOP ENVIRONMENT VARIABLES ### myHadoopCluster <- RxSpark() ### HADOOP COMPUTE CONTEXT ### rxSetComputeContext(myHadoopCluster) ### CREATE HDFS, DIRECTORY AND FILE OBJECTS ### hdfsFS <- RxHdfsFileSystem() ### ANALYTICAL PROCESSING ### ### Statistical Summary of the data rxSummary(~ArrDelay+DayOfWeek, data= AirlineDataSet, reportProgress=1) ### CrossTab the data rxCrossTabs(ArrDelay ~ DayOfWeek, data= AirlineDataSet, means=T) ### Linear Model and plot hdfsXdfArrLateLinMod <- rxLinMod(ArrDelay ~ DayOfWeek + 0 , data = AirlineDataSet) plot(hdfsXdfArrLateLinMod$coefficients) ### LOCAL COMPUTE CONTEXT ### rxSetComputeContext("local") ### CREATE, REFERENCE FILE OBJECTS ### AirlineDataSet <- RxTextData(file.path(dataRead,"AirlineDemoSmall.csv") ) Local Parallel processing – Linux or Windows In – Hadoop (Spark / MR) or SqlServer ScaleR models can be deployed from a server or edge node to run in Hadoop without any functional R model re-coding for map-reduce Functional model R script – does not need to change to run in Hadoop Compute context R script – sets where the model will run
- 17. • Defines where the processing happens • Current set compute context determines processing location • Write Once Deploy Anywhere (WODA) by changing compute context
- 20. “admintable”
- 21. rxSetComputeContext(RxSpark(…)) mydata<-RxTextData("/data/admin.csv", fileSystem = RxHdfsFileSystem()) mylogIt <- rxLogit(admin~ gre + gpa + rank, data = mydata) Using a Spark compute context Keep other code unchanged
- 22. Rx…..Data
- 24. • Scale via parallel & distributed computation • Scales via in-cluster & in-database execution • Escapes R’s memory limitations • Speed analysis by reducing data movement • Stop security risks with in-database & in- Hadoop • Deploys R to multiple platforms f(x) Task Task Task
- 25. RevoScaleR Algorithms & Functions Task Task Task Finalizer Initiator Data Larger than RAM Internal Flow: 1. Algorithm begins initiator process 2. Initiator distributes work to nodes 3. Finalizer collects results 4. Finalizer iterates or continues 5. Finalizer evaluates final model 6. Returns single model to calling script … load a large dataset Model_obj <- rxLinMod(…) … run a RevoScaleR algorithm Typical Characteristics One call, one answer Arbitrarily large data sets Arbitrarily large worker task set Mathematically the same as single-threaded Platform independent Most are written in C++ for speed
- 26. Remote RevoScaleR Algorithm Internal Flow: 1. Algorithm on local checks compute context 2. If set remote, packages and ships request 3. Local script blocks (by default) awaiting response 4. Remote unpacks and executes in parallel 5. Remote returns results to local interface 6. Local interface returns results to script … set compute context to Spark rxSetComputeContext(RxSpark(…)) Model_obj <- rxLinMod(…) … run a RevoScaleR algorithm Big data Remote Execution: Executes RevoScaleR algos on remote data & CPUs “rxSetComputeContext” redirects to remote Algorithms in RevoScaleR library redirect as set Results are returned to script as though local Local RevoScaleR Algorithm Algorithm Interface Remote Local Task Task Task Finalizer Initiator SQL Server, Hadoop, Hadoop MapReduce, HDInsight RevoScaleR Remote Execution
- 29. RevoScaleR Spark + Sparklyr + H20 * Interoperability with Sparklyr and H2O * Best in-class operationalization * Guaranteed backward compatibility DEMO : Data manipulation using sparklyr, Interoperability between sparklyr and RevoScaleR
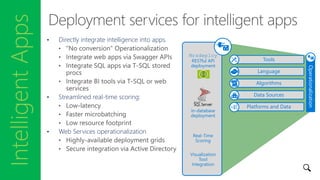
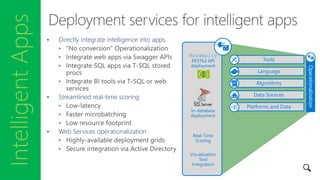
- 30. IntelligentApps • Directly integrate intelligence into apps. • Streamlined real-time scoring: • Web Services operationalization Platforms and Data Tools Language Algorithms Data Sources Operationalization Mrsdeploy RESTful API deployment Real-Time Scoring Visualization Tool Integration In-database deployment
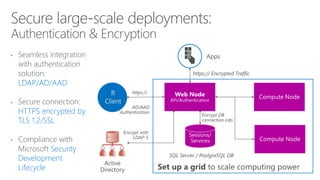
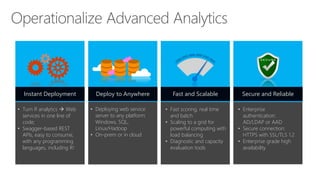
- 32. • Seamless integration with authentication solution: LDAP/AD/AAD • Secure connection: HTTPS encrypted by TLS 1.2/SSL • Compliance with Microsoft Security Development Lifecycle R Client
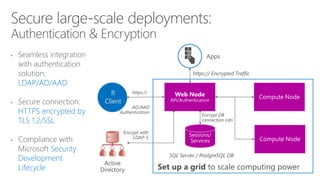
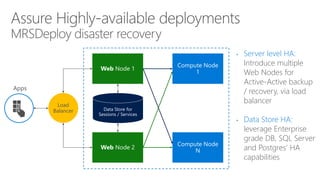
- 33. Load Balancer • Server level HA: Introduce multiple Web Nodes for Active-Active backup / recovery, via load balancer • Data Store HA: leverage Enterprise grade DB, SQL Server and Postgres’ HA capabilities
- 34. • Easily create web services from R scripts & models Build the model first Deploy as a web service instantly
- 35. # Run the following code in R swagger <- api$swagger() cat(swagger, file = "swagger.json", append = FALSE) Generate Swagger Docs for Web Services Popular Swagger Tools: AutoRest or Code Generator AutoRest.exe -CodeGenerator CSharp -Modeler Swagger - Input swagger.json - Namespace Mynamespace Run Swagger tools to generate code Write a few code to consume the service Data Scientist DeveloperDeveloper
- 38. THANK YOU!
- 39. Choice • Open Source: Microsoft R Open: • Microsoft innovations: Microsoft R Extensions: Distributed Parallelized Algorithms: •RevoScaleR library •MicrosoftML library •Custom parallelization frameworks Open source R algorithms & visualizations: •CRAN •bioconductor Plus: •Deep Learning •Pretrained Models •Prebuilt Featurizers Platforms and Data Tools Language Algorithms Data Sources Operationalization
- 40. Variable Selection Stepwise Regression Simulation Simulation (e.g. Monte Carlo) Parallel Random Number Generation Cluster Analysis K-Means Classification Decision Trees Decision Forests Gradient Boosted Decision Trees Naïve Bayes Custom Parallel rxDataStep rxExec rxExecBy – Many-Models PEMA-R API Custom Algorithms Data Step Data import – Delimited, Fixed, SAS, SPSS, ODBC Variable creation & transformation Recode variables Factor variables Missing value handling Sort, Merge, Split Aggregate by category (means, sums) Descriptive Statistics Min / Max, Mean, Median (approx.) Quantiles (approx.) Standard Deviation Variance Correlation Covariance Sum of Squares (cross product matrix for set variables) Pairwise Cross tabs Risk Ratio & Odds Ratio Cross-Tabulation of Data (standard tables & long form) Marginal Summaries of Cross Tabulations Statistical Tests Chi Square Test Kendall Rank Correlation Fisher’s Exact Test Student’s t-Test Sampling Subsample (observations & variables) Random Sampling Predictive Models Sum of Squares (cross product matrix for set variables) Quantiles (approx.) Generalized Linear Models (GLM) exponential family distributions: binomial, Gaussian, inverse Gaussian, Poisson, Tweedie. Standard link functions: cauchit, identity, log, logit, probit. User defined distributions & link functions. Covariance & Correlation Matrices Logistic Regression Linear regression Predictions/scoring for models Residuals for all models
- 41. Learner Strength Learning tasks supported Sample Applications Deep Neural Network Supports custom, multi-layer network topology with filtered, convolutional, and pooling bundles Binary classification Multi-class classification Regression Bing Ads Click Prediction ($50M per year revenue gain); Image Classification Logistic regression L1, L2 regularization Binary classification Multi-class classification. Classifying user feedback One-class SVM Easy to train learner for anomaly detection Anomaly Detection Fraud detection Fast Tree Boosted decision tree. Similar to XGBoost. Supports upto 1B features! Binary classification Regression One of the most popular and best performing learners inside Microsoft. Fast Forest state-of-the-art tree ensembles (Random Forest) Binary classification Regression Churn Prediction Fast Linear (SDCA) Speed, scalability and supports L1,L2 regularization Binary classification, Regression Outlook used for email spam filtering Transform Strength Description Applications Text Battle tested, large language support, performant (Bing, Office) Performs natural language processing of free text into numerical representation. Support ticket classification, Sentiment analysis Categorical / Categorical hash Ease of use; 1 line of code to set Converts categories into numerical data. Ad Click Prediction Feature Selection Ease of use Selects a subset of features to speed up training time. Sentiment analysis, Ad Click Prediction
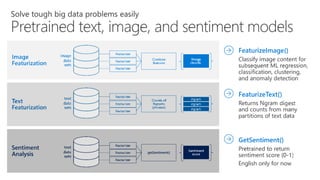
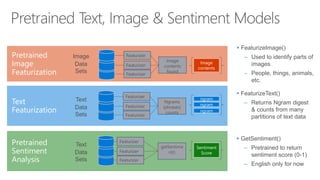
- 42. Pretrained Image Featurization FeaturizeImage() – Used to identify parts of images – People, things, animals, etc. FeaturizeText() – Returns Ngram digest & counts from many partitions of text data Text Featurization Featurizer Featurizer Ngrams (phrases) counts Text Data Sets Featurizer ngram ngram ngram Image Data Sets Image contents Featurizer Featurizer Image contents found Featurizer GetSentiment() – Pretrained to return sentiment score (0-1) – English only for now Pretrained Sentiment Analysis Featurizer Featurizer getSentime nt() Text Data Sets Featurizer Sentiment Score
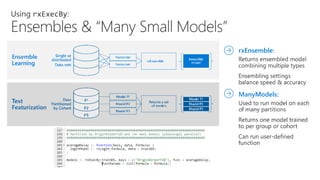
- 43. DistributedModeling • “Many Models” on Partitioned Data • Parallelized ensemble modeling • New rxExecBy framework: • Superior to Spark gapply: Platforms and Data Tools Language Algorithms Data Sources Operationalization
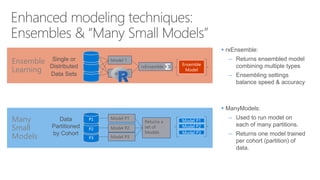
- 44. rxEnsemble: – Returns ensembled model combining multiple types – Ensembling settings balance speed & accuracy Many Small Models Ensemble Learning Model 1 Model 2 rxEnsemble Single or Distributed Data Sets ManyModels: – Used to run model on each of many partitions. – Returns one model trained per cohort (partition) of data. P3 Model P1 P2 P1 Model P2 Returns a set of Models Data Partitioned by Cohort Model P3 Model P1 Model P2 Model P3 Ensemble Model
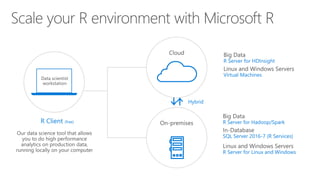
- 45. Scale • RevoScaleR • Microsoft Machine Learning Library • Create custom parallel algorithms and functions: Distributed Parallelized Algorithms: •RevoScaleR library •MicrosoftML library •Custom parallelization frameworks Open source R algorithms & visualizations: •CRAN •bioconductor Plus: •Deep Learning •Pretrained Models •Prebuilt Featurizers Platforms and Data Tools Language Algorithms Data Sources Operationalization
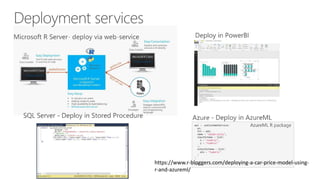
- 47. SQLServer • Fast modeling platform with operationalization in one. • Minimum data movement speeds & secures • Direct T-SQL Integration • Real-Time Scoring Support • SQL Server security & administration • Rapid deployment of R models as stored procedures. • Python support. Platforms and Data Tools Language Algorithms Data Sources Operationalization Distributed Parallelized Algorithms: •RevoScaleR library •MicrosoftML library •Custom parallelization frameworks Open source R algorithms & visualizations: •CRAN •bioconductor Plus: •Deep Learning •Pretrained Models •Prebuilt Featurizers .csv Microsoft .XDF ODBC/JDBC
- 49. (SQL Server 2017) • Python support • Microsoft Machine Learning package included • Process multiple related models in parallel with the rxExecBy function • Create a shared script library with R script package management • Native scoring with T-SQL PREDICT • In-place upgrade of R components
- 50. Spark • Distribute RevoScaleR algorithms using Spark • Spark 1.6 or 2.0 Compatible • Load Spark Dataframes from: • Interop with SparkETL, SparkSQL • Support for HDInsight, Hortonworks, Cloudera & MapR Hadoop Platforms and Data Tools Language Algorithms Data Sources Operationalization Distributed Parallelized Algorithms: •RevoScaleR library •MicrosoftML library •Custom parallelization frameworks Open source R algorithms & visualizations: •CRAN •bioconductor Plus: •Deep Learning •Pretrained Models •Prebuilt Featurizers .csv Microsoft .XDF ODBC/JDBC
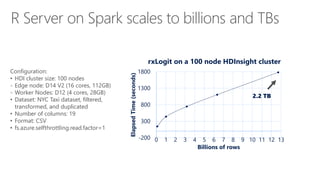
- 51. Configuration: • HDI cluster size: 100 nodes - Edge node: D14 V2 (16 cores, 112GB) - Worker Nodes: D12 (4 cores, 28GB) • Dataset: NYC Taxi dataset, filtered, transformed, and duplicated • Number of columns: 19 • Format: CSV • fs.azure.selfthrottling.read.factor=1 -200 300 800 1300 1800 0 1 2 3 4 5 6 7 8 9 10 11 12 13 ElapsedTime(seconds) Billions of rows rxLogit on a 100 node HDInsight cluster 2.2 TB
- 53. IntelligentApps • Directly integrate intelligence into apps. • Streamlined real-time scoring: • Web Services operationalization Platforms and Data Tools Language Algorithms Data Sources Operationalization Mrsdeploy RESTful API deployment Real-Time Scoring Visualization Tool Integration In-database deployment
- 54. Built-in remote execute functions in R Client/R Server Tools to reconcile local and remote Execute .R script or interactive R commands Return results to local Generate working snapshots for resume and reuse IDE agnostic R Server configured to (Support Window Server, Linux Server, Hadoop ) Remote Execute R Scripts Execute R Scripts Snapshot remote env. Logout remote server Login remote server Generate Diff report Reconcile Environment
- 55. Agility • Visual Studio • Support for open source R Studio GUI • Support for JupyterR • Microsoft contributing to Rattle Rattle Platforms and Data Tools Language Algorithms Data Sources Operationalization
- 58. recognized leader broadest R capabilities performance and scale architectural flexibility Rapid deployment Harnesses the hybrid cloud Scales R for big data workloads Blends best of open source and Microsoft technologies platform choice
- 61. In-Database analytics with SQL Server In SQL Server 2016, Microsoft launched two server platforms for integrating the popular open source R language with business applications: • SQL Server R Services (In-Database), for integration with SQL Server • Machine Learning Server, for enterprise-level R deployments on Windows and Linux servers In SQL Server 2017, the name has been changed to reflect support for the popular Python language: • SQL Server Machine Learning Services (In-Database) supports both R and Python for in- database analytics • Microsoft Machine Learning Server supports R and Python deployments on Windows servers—expansion to other supported platforms is planned for late 2017
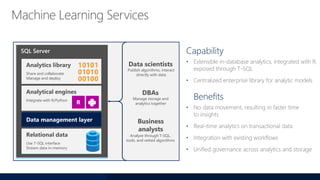
- 62. Capability • Extensible in-database analytics, integrated with R, exposed through T-SQL • Centralized enterprise library for analytic models Benefits SQL Server Analytical engines Integrate with R/Python Data management layer Relational data Use T-SQL interface Stream data in-memory Analytics library Share and collaborate Manage and deploy R Data scientists Business analysts Publish algorithms, interact directly with data Analyze through T-SQL, tools, and vetted algorithms DBAs Manage storage and analytics together Machine Learning Services
- 63. SQL Server 2017 setup Install Machine Learning Services (In-Database) Consent to install Microsoft R Open/Python Optional: Install R packages on SQL Server 2017 machine Database configuration Enable R language extension in database Configure path for RRO runtime in database Grant EXECUTE EXTERNAL SCRIPT permission to users CREATE EXTERNAL EXTENSION [R] USING SYSTEM LAUNCHER WITH (RUNTIME_PATH = 'c:revolutionbin‘) GRANT EXECUTE SCRIPT ON EXTERNAL EXTENSION::R TO DataScientistsRole; /* User-defined role / users */
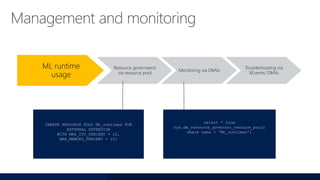
- 64. ML runtime usage Resource governance via resource pool Monitoring via DMVs Troubleshooting via XEvents/ DMVs CREATE RESOURCE POOL ML_runtimes FOR EXTERNAL EXTENSION WITH MAX_CPU_PERCENT = 20, MAX_MEMORY_PERCENT = 10; select * from sys.dm_resource_governor_resouce_pools where name = ‘ML_runtimes';
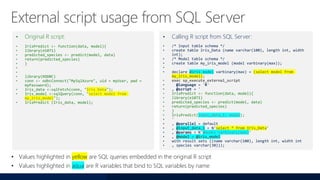
- 65. • Original R script: • IrisPredict <- function(data, model){ • library(e1071) • predicted_species <- predict(model, data) • return(predicted_species) • } • • • library(RODBC) • conn <- odbcConnect("MySqlAzure", uid = myUser, pwd = myPassword); • Iris_data <-sqlFetch(conn, "Iris_Data"); • Iris_model <-sqlQuery(conn, "select model from my_iris_model"); • IrisPredict (Iris_data, model); • Calling R script from SQL Server: • /* Input table schema */ • create table Iris_Data (name varchar(100), length int, width int); • /* Model table schema */ • create table my_iris_model (model varbinary(max)); • • declare @iris_model varbinary(max) = (select model from my_iris_model); • exec sp_execute_external_script • @language = 'R' • , @script = ' • IrisPredict <- function(data, model){ • library(e1071) • predicted_species <- predict(model, data) • return(predicted_species) • } • IrisPredict(input_data_1, model); • ' • , @parallel = default • , @input_data_1 = N'select * from Iris_Data' • , @params = N'@model varbinary(max)' • , @model = @iris_model • with result sets ((name varchar(100), length int, width int • , species varchar(30))); • Values highlighted in yellow are SQL queries embedded in the original R script • Values highlighted in aqua are R variables that bind to SQL variables by name
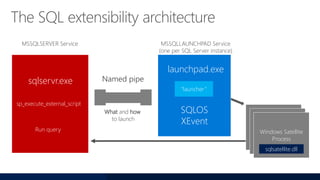
- 66. launchpad.exe sp_execute_external_script sqlservr.exe Named pipe SQLOS XEvent MSSQLSERVER Service MSSQLLAUNCHPAD Service (one per SQL Server instance) What and how to launch “launcher” Bxlserver.exe sqlsatellite.dll Bxlserver.exe sqlsatellite.dll Windows Satellite Process sqlsatellite.dll Run query
- 67. • More efficient than standalone clients • Data does not all have to fit in memory • Reduced data transmission over the network • Most R Open (and Python R) functions are single threaded • We can stream data in parallel and batches from SQL Server to/from script • Use the power of SQL Server and ML to develop, train, and operationalize • SQL Server compute context (remote compute context) • T-SQL queries • Memory-optimized tables • Columnstore indexes • Data compression • Parallel query execution • Stored procedures
- 68. Reduced surface area and isolation “external scripts enabled” is required Script execution outside of SQL Server process space Script execution requires explicit permission sp_execute_external_script requires EXECUTE ANY EXTERNAL SCRIPT for non-admins SQL Server login/user required and db/table access Satellite processes have limited privileges Satellite processes run under low privileged, local user accounts in the SQLRUserGroup Each execution is isolated — different users with different accounts Windows firewall rules block outbound traffic
- 69. MicrosoftML is a package for Machine Learning Server, Microsoft R Client, and SQL Server Machine Learning Services that adds state-of-the-art data transforms, machine learning algorithms, and pretrained models to Microsoft R functionality. • Data transforms helps you to compose, in a pipeline, a custom set of transforms that are applied to your data before training or testing. The primary purpose of these transforms is to allow you to featurize your data. • Machine learning algorithms enable you to tackle common machine learning tasks such as classification, regression and anomaly detection. You run these high-performance functions locally on Windows or Linux machines or on Azure HDInsight (Hadoop/Spark) clusters. • Pretrained models for sentiment analysis and image featurization can also be installed and deployed with the MicrosoftML package.
- 70. Identify Server Set Source Set Context Use
- 71. • Run R or Python inside SQL Server 2017 with ML Services • Existing SQL 2016 clients can R using SQL R Services SQL Server 2017 Run R engine from within the Query Processor
- 72. SQL Server 2016/17 Run R From within the Query Processor Move BIG Work to the Data T-SQL Apps T-SQL Script
- 73. T-SQL Stored ProcedureSQL Server 2016/17 Enable smart non-R apps BI & Reporting; Web apps T-SQL Script R Engine R script
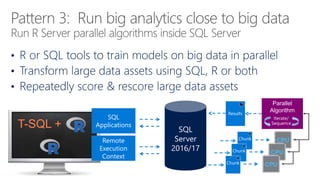
- 74. Large Data Sets in Chunks Remote Execution Context Results Parallel Worker Tasks Parallel Algorithm Iterate/ Sequence SQL ApplicationsT-SQL + SQL Server 2016/17
- 75. Events T-SQL Production Apps Models SQL Server 2017 Real time scoring engine Stored Proc’s and Triggers Events
- 77. Use familiar T-SQL stored procedures to invoke R scripts from your application
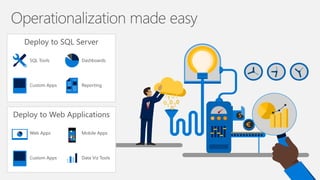
- 78. • Turn R analytics Web services in one line of code; • Swagger-based REST APIs, easy to consume, with any programming languages, including R! • Deploying web service server to any platform: Windows, SQL, Linux/Hadoop • On-prem or in cloud • Fast scoring, real time and batch • Scaling to a grid for powerful computing with load balancing • Diagnostic and capacity evaluation tools • Enterprise authentication: AD/LDAP or AAD • Secure connection: HTTPS with SSL/TLS 1.2 • Enterprise grade high availability Instant Deployment Deploy to Anywhere Fast and Scalable Secure and Reliable
- 79. Data Scientist Developer Easy Integration Easy Deployment Easy Setup In-cloud or on-prem Adding nodes to scale High availability & load balancing Remote execution server Machine Learning Server configured for operationalizing R analytics Microsoft R Client (mrsdeploy package) Easy Consumption publishServiceMicrosoft R Client (mrsdeploy package) Data Scientist
- 80. • Seamless integration with authentication solution: LDAP/AD/AAD • Secure connection: HTTPS encrypted by TLS 1.2/SSL • Compliance with Microsoft Security Development Lifecycle R Client
- 81. Load Balancer • Server level HA: Introduce multiple Web Nodes for Active-Active backup / recovery, via load balancer • Data Store HA: leverage Enterprise grade DB, SQL Server and Postgres’ HA capabilities
- 82. • Easily create web services from R scripts & models Build the model first Deploy as a web service instantly
- 83. Function Description publishService Publish a predictive function as a Web Service deleteService Delete a Web Service getService Get a Web Service ListServices List the different published web services serviceOption Retrieve, set, and list the different service options updateService Updates a Web Service
- 84. # Run the following code in R swagger <- api$swagger() cat(swagger, file = "swagger.json", append = FALSE) Generate Swagger Docs for Web Services Popular Swagger Tools: AutoRest or Code Generator AutoRest.exe -CodeGenerator CSharp -Modeler Swagger - Input swagger.json - Namespace Mynamespace Run Swagger tools to generate code Write a few code to consume the service Data Scientist DeveloperDeveloper
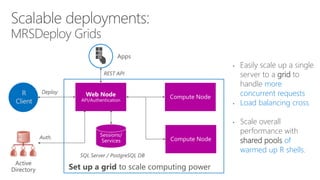
- 86. • Easily scale up a single server to a grid to handle more concurrent requests • Load balancing cross compute nodes • Scale overall performance with shared pools of warmed up R shells. R Client
- 87. Snapshot Functions createSnapshot Create a snapshot of the remote session (workspace and working directory) loadSnapshot Load a snapshot from the server into the remote session (workspace and working directory) listSnapshots Get a list of snapshots for the current user downloadSnapshot Download a snapshot from the server deleteSnapshot Delete a snapshot from the server Remote Objects Management listRemoteFiles Get a list of files in the working directory of the remote session deleteRemoteFile Delete a file from the working directory of the remote R session getRemoteFile Copy a file from the working directory of the remote R session putLocalFile Copy a file from the local machine to the working directory of the remote R session getRemoteObject Get an object from the remote R session putLocalObject Put an object from the local R session and load it into the remote R session getRemoteWorkspace Take all objects from the remote R session and load them into the local R session putLocalWorkspace Take all objects from the local R session and load them into the remote R session Remote Connection remoteLogin Remote login to the R Server with AD or admin credentials remoteLoginAAD Remote login to R Server server using Azure AD remoteLogout Logout of the remote session on the DeployR Server. Remote Execution remoteExecute Remote execution of either R code or an R script remoteScript Wrapper function for remote script execution diffLocalRemote Generate a 'diff' report between local and remote pause Pause remote connection and back to local resume Return the user to the 'REMOTE >' command prompt