Intro to Data Science Concepts
Download as pptx, pdf3 likes1,912 views

A 1-hour introduction to data science talk given the to the Data Science for Social Good cohort in June 2015 at UW




![6/17/2015 Bill Howe, UW 5
“…the biggest win came from good old SQL on a Vertica data
warehouse and from providing access to data to dozens of
analytics staffers who could follow their own curiosity and
distill and analyze data as they needed.”
Dan Woods
Jan 13 2013, CITO Research
“The decision was made to have Hadoop do the aggregate generations
and anything not real-time, but then have Vertica to answer sort of
‘speed-of-thought’ queries about all the data.”
Josh Hendler, CTO of H & K Strategies
Related: Obama campaign’s data-driven ground game
"In the 21st century, the candidate with [the] best data,
merged with the best messages dictated by that data, wins.”
Andrew Rasiej, Personal Democracy Forum](https://image.slidesharecdn.com/dssgdatasciencejune2015-150617175007-lva1-app6891/85/Intro-to-Data-Science-Concepts-5-320.jpg)

















































![Big Data [sorry] & Data Science: What Does a Data Scientist Do?](https://cdn.slidesharecdn.com/ss_thumbnails/dslatcloudmsevent20130125-130126065651-phpapp01-thumbnail.jpg?width=560&fit=bounds)















More Related Content
What's hot (20)
Viewers also liked (20)


















Similar to Intro to Data Science Concepts (20)




















More from University of Washington (20)




















Recently uploaded (20)




















Intro to Data Science Concepts
- 1. Bill Howe, PhD Introduction to Data Science
- 2. This morning • Context for “Data Science” • Databases and Relational Algebra • NoSQL 6/17/2015 Bill Howe, UW 2
- 4. “The intuition behind this ought to be very simple: Mr. Obama is maintaining leads in the polls in Ohio and other states that are sufficient for him to win 270 electoral votes.” Nate Silver, Oct. 26, 2012 “…the argument we’re making is exceedingly simple. Here it is: Obama’s ahead in Ohio.” Nate Silver, Nov. 2, 2012 “The bar set by the competition was invitingly low. Someone could look like a genius simply by doing some fairly basic research into what really has predictive power in a political campaign.” Nate Silver, Nov. 10, 2012 DailyBeast fivethirtyeight.com fivethirtyeight.comsource: randy stewart Nate Silver
- 5. 6/17/2015 Bill Howe, UW 5 “…the biggest win came from good old SQL on a Vertica data warehouse and from providing access to data to dozens of analytics staffers who could follow their own curiosity and distill and analyze data as they needed.” Dan Woods Jan 13 2013, CITO Research “The decision was made to have Hadoop do the aggregate generations and anything not real-time, but then have Vertica to answer sort of ‘speed-of-thought’ queries about all the data.” Josh Hendler, CTO of H & K Strategies Related: Obama campaign’s data-driven ground game "In the 21st century, the candidate with [the] best data, merged with the best messages dictated by that data, wins.” Andrew Rasiej, Personal Democracy Forum
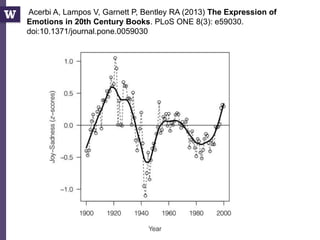
- 8. Acerbi A, Lampos V, Garnett P, Bentley RA (2013) The Expression of Emotions in 20th Century Books. PLoS ONE 8(3): e59030. doi:10.1371/journal.pone.0059030 1) Convert all the digitized books in the 20th century into n-grams (Thanks, Google!) (http://books.google.com/ngrams/) 2) Label each 1-gram (word) with a mood score. (Thanks, WordNet!) 3) Count the occurences of each mood word A 1-gram: “yesterday” A 5-gram: “analysis is often described as”
- 9. Acerbi A, Lampos V, Garnett P, Bentley RA (2013) The Expression of Emotions in 20th Century Books. PLoS ONE 8(3): e59030. doi:10.1371/journal.pone.0059030
- 10. 6/17/2015 Bill Howe, UW 10 Acerbi A, Lampos V, Garnett P, Bentley RA (2013) The Expression of Emotions in 20th Century Books. PLoS ONE 8(3): e59030. doi:10.1371/journal.pone.0059030
- 11. 6/17/2015 Bill Howe, UW 11 … 2. Michel J-P, Shen YK, Aiden AP, Veres A, Gray MK, et al. (2011) Quantitative analysis of culture using millions of digitized books. Science 331: 176–182. doi: 10.1126/science.1199644. Find this article online 3. Lieberman E, Michel J-P, Jackson J, Tang T, Nowak MA (2007) Quantifying the evolutionary dynamics of language. Nature 449: 713– 716. doi: 10.1038/nature06137. Find this article online 4. Pagel M, Atkinson QD, Meade A (2007) Frequency of word-use predicts rates of lexical evolution throughout Indo-European history. Nature 449: 717–720. doi: 10.1038/nature06176. Find this article online … 6. DeWall CN, Pond RS Jr, Campbell WK, Twenge JM (2011) Tuning in to Psychological Change: Linguistic Markers of Psychological Traits and Emotions Over Time in Popular U.S. Song Lyrics. Psychology of Aesthetics, Creativity and the Arts 5: 200–207. doi: 10.1037/a0023195. Find this article online …
- 12. What is Data Science? • Fortune – “Hot New Gig in Tech” • Hal Varian, Google’s Chief Economist, NYT, 2009: – “The next sexy job” – “The ability to take data—to be able to understand it, to process it, to extract value from it, to visualize it, to communicate it—that’s going to be a hugely important skill.” • Mike Driscoll, CEO of metamarkets: – “Data science, as it's practiced, is a blend of Red-Bull-fueled hacking and espresso-inspired statistics.” – “Data science is the civil engineering of data. Its acolytes possess a practical knowledge of tools & materials, coupled with a theoretical understanding of what's possible.” 6/17/2015 Bill Howe, UW 12
- 13. Drew Conway’s Data Science Venn Diagram 6/17/2015 Bill Howe, UW 13
- 14. What do data scientists do? “They need to find nuggets of truth in data and then explain it to the business leaders” Data scientists “tend to be “hard scientists”, particularly physicists, rather than computer science majors. Physicists have a strong mathematical background, computing skills, and come from a discipline in which survival depends on getting the most from the data. They have to think about the big picture, the big problem.” 6/17/2015 Bill Howe, UW 14 -- DJ Patil, Chief Scientist at LinkedIn -- Rchard Snee, EMC
- 15. Mike Driscoll’s three sexy skills of data geeks • Statistics – traditional analysis • Data Munging – parsing, scraping, and formatting data • Visualization – graphs, tools, etc. 6/17/2015 Bill Howe, UW 15
- 16. “Data Science refers to an emerging area of work concerned with the collection, preparation, analysis, visualization, management and preservation of large collections of information.” 6/17/2015 Bill Howe, UW 16 Jeffrey Stanton Syracuse University School of Information Studies An Introduction to Data Science
- 17. Data Science is about Data Products • “Data-driven apps” – Spellchecker – Machine Translator • Interactive visualizations – Google flu application – Global Burden of Disease • Online Databases – Enterprise data warehouse – Sloan Digital Sky Survey 6/17/2015 Bill Howe, UW 17 (Mike Loukides) Data science is about building data products, not just answering questions Data products empower others to use the data. May help communicate your results (e.g., Nate Silver’s maps) May empower others to do their own analysis (e.g., Global Burden of Disease)
- 18. A Typical Data Science Workflow 6/17/2015 Bill Howe, UW 18 1) Preparing to run a model 2) Running the model 3) Interpreting the results Gathering, cleaning, integrating, restructuring, transforming, loading, filtering, deleting, combining, merging, verifying, extracting, shaping, massaging “80% of the work” -- Aaron Kimball “The other 80% of the work”
- 19. 6/17/2015 Bill Howe, UW 19 What are the abstractions of data science? “Data Jujitsu” “Data Wrangling” “Data Munging” Translation: “We have no idea what this is all about”
- 20. 6/17/2015 Bill Howe, UW 20 1850s: matrices and linear algebra (today: engineers and scientists) 1950s: arrays and custom algorithms (today: C/Fortran performance junkies) 1950s: s-expressions and pure functions (today: language purists) 1960s: objects and methods (today: software engineers) 1970s: files and scripts (today: system administrators) 1970s: relations and relational algebra (today: large-scale data engineers) 1980s: data frames and functions (today: statisticians) 2000s: key-value pairs + one of the above (today: NoSQL hipsters) But what are the abstractions of data science?
- 21. DATABASES AND RELATIONAL ALGEBRA 6/17/2015 Bill Howe, UW 21
- 22. 6/17/2015 Bill Howe, eScience Institute 22 Pre-Relational: if your data changed, your application broke. Early RDBMS were buggy and slow (and often reviled), but required only 5% of the application code. “Activities of users at terminals and most application programs should remain unaffected when the internal representation of data is changed and even when some aspects of the external representation are changed.” Key Ideas: Programs that manipulate tabular data exhibit an algebraic structure allowing reasoning and manipulation independently of physical data representation Relational Database History -- Codd 1979
- 23. 6/17/2015 Bill Howe, eScience Institute 23 Key Idea: “Physical Data Independence” physical data independence files and pointers relations SELECT seq FROM ncbi_sequences WHERE seq = ‘GATTACGATATTA’; f = fopen(‘table_file’); fseek(10030440); while (True) { fread(&buf, 1, 8192, f); if (buf == GATTACGATATTA) { . . .
- 24. 6/17/2015 Bill Howe, eScience Institute 24 Key Idea: An Algebra of Tables select project join join Other operators: aggregate, union, difference, cross product
- 25. Equivalent logical expressions 25 σp=knows(R) o=s (σp=holdsAccount(R) o=s σp=accountHomepage(R)) (σp=knows(R) o=s σp=holdsAccount(R)) o=s σp=accountHomepage(R) σp1=knows & p2=holdsAccount & p3=accountHomepage (R x R x R) right associative left associative distributive
- 26. 6/17/2015 Bill Howe, eScience Institute 26 Why do we care? Algebraic Optimization N = ((z*2)+((z*3)+0))/1 Algebraic Laws: 1. (+) identity: x+0 = x 2. (/) identity: x/1 = x 3. (*) distributes: (n*x+n*y) = n*(x+y) 4. (*) commutes: x*y = y*x Apply rules 1, 3, 4, 2: N = (2+3)*z two operations instead of five, no division operator Same idea works with the Relational Algebra!
- 27. So what? RA is now ubiquitous • Galaxy – “bioinformatics workflows” • Pandas and Blaze: High Performance Arrays in Python merge(left, right, on=‘key’) • dplyr in R filter(x), select(x), arrange(x), groupby(x), inner_join(x, y), left_join(x, y) • Hadoop and contemporaries all evolved to support RA-like interfaces: Pig, HIVE, Cascalog, Flume, Spark/Shark, Dremel “…Operate on Genomics Intervals -> Join”
- 28. “NOSQL” SYSTEMS 6/17/2015 Bill Howe, UW 28
- 29. Year System/ Paper Scale to 1000s Primary Index Secondary Indexes Transactions Joins/ Analytics Integrity Constraints Views Language/ Algebra Data model my label 1971 RDBMS O ✔ ✔ ✔ ✔ ✔ ✔ ✔ tables sql-like 2003 memcached ✔ ✔ O O O O O O key-val nosql 2004 MapReduce ✔ O O O ✔ O O O key-val batch 2005 CouchDB ✔ ✔ ✔ record MR O ✔ O document nosql 2006 BigTable/Hbase ✔ ✔ ✔ record compat. w/MR / O O ext. record nosql 2007 MongoDB ✔ ✔ ✔ EC, record O O O O document nosql 2007 Dynamo ✔ ✔ O O O O O O ext. record nosql 2008 Pig ✔ O O O ✔ / O ✔ tables sql-like 2008 HIVE ✔ O O O ✔ ✔ O ✔ tables sql-like 2008 Cassandra ✔ ✔ ✔ EC, record O ✔ ✔ O key-val nosql 2009 Voldemort ✔ ✔ O EC, record O O O O key-val nosql 2009 Riak ✔ ✔ ✔ EC, record MR O key-val nosql 2010 Dremel ✔ O O O / ✔ O ✔ tables sql-like 2011 Megastore ✔ ✔ ✔ entity groups O / O / tables nosql 2011 Tenzing ✔ O O O O ✔ ✔ ✔ tables sql-like 2011 Spark/Shark ✔ O O O ✔ ✔ O ✔ tables sql-like 2012 Spanner ✔ ✔ ✔ ✔ ? ✔ ✔ ✔ tables sql-like 2013 Impala ✔ O O O ✔ ✔ O ✔ tables sql-like NoSQL and related systems, by feature
- 30. 6/17/2015 Bill Howe, UW 30 Year System/ Paper Scale to 1000s Primary Index Secondary Indexes Transactions Joins/ Analytics Integrity Constraints Views Language/ Algebra Data model my label 1971 RDBMS O ✔ ✔ ✔ ✔ ✔ ✔ ✔ tables sql-like 2003 memcached ✔ ✔ O O O O O O key-val nosql 2004 MapReduce ✔ O O O ✔ O O O key-val batch 2005 CouchDB ✔ ✔ ✔ record MR O ✔ O document nosql 2006 BigTable (Hbase) ✔ ✔ ✔ record compat. w/MR / O O ext. record nosql 2007 MongoDB ✔ ✔ ✔ EC, record O O O O document nosql 2007 Dynamo ✔ ✔ O O O O O O ext. record nosql 2008 Pig ✔ O O O ✔ / O ✔ tables sql-like 2008 HIVE ✔ O O O ✔ ✔ O ✔ tables sql-like 2008 Cassandra ✔ ✔ ✔ EC, record O ✔ ✔ O key-val nosql 2009 Voldemort ✔ ✔ O EC, record O O O O key-val nosql 2009 Riak ✔ ✔ ✔ EC, record MR O key-val nosql 2010 Dremel ✔ O O O / ✔ O ✔ tables sql-like 2011 Megastore ✔ ✔ ✔ entity groups O / O / tables nosql 2011 Tenzing ✔ O O O O ✔ ✔ ✔ tables sql-like 2011 Spark/Shark ✔ O O O ✔ ✔ O ✔ tables sql-like 2012 Spanner ✔ ✔ ✔ ✔ ? ✔ ✔ ✔ tables sql-like 2012 Accumulo ✔ ✔ ✔ record compat. w/MR / O O ext. record nosql 2013 Impala ✔ O O O ✔ ✔ O ✔ tables sql-like Scale was the primary motivation!
- 31. 6/17/2015 Bill Howe, UW 31 Rick Cattel’s clustering from “Scalable SQL and NoSQL Data Stores” SIGMOD Record, 2010 extensible record stores document stores key-value stores Year System/ Paper Scale to 1000s Primary Index Secondary Indexes Transactions Joins/ Analytics Integrity Constraints Views Language/ Algebra Data model my label 1971 RDBMS O ✔ ✔ ✔ ✔ ✔ ✔ ✔ tables sql-like 2003 memcached ✔ ✔ O O O O O O key-val nosql 2004 MapReduce ✔ O O O ✔ O O O key-val batch 2005 CouchDB ✔ ✔ ✔ record MR O ✔ O document nosql 2006 BigTable (Hbase) ✔ ✔ ✔ record compat. w/MR / O O ext. record nosql 2007 MongoDB ✔ ✔ ✔ EC, record O O O O document nosql 2007 Dynamo ✔ ✔ O O O O O O key-val nosql 2008 Pig ✔ O O O ✔ / O ✔ tables sql-like 2008 HIVE ✔ O O O ✔ ✔ O ✔ tables sql-like 2008 Cassandra ✔ ✔ ✔ EC, record O ✔ ✔ O key-val nosql 2009 Voldemort ✔ ✔ O EC, record O O O O key-val nosql 2009 Riak ✔ ✔ ✔ EC, record MR O key-val nosql 2010 Dremel ✔ O O O / ✔ O ✔ tables sql-like 2011 Megastore ✔ ✔ ✔ entity groups O / O / tables nosql 2011 Tenzing ✔ O O O O ✔ ✔ ✔ tables sql-like 2011 Spark/Shark ✔ O O O ✔ ✔ O ✔ tables sql-like 2012 Spanner ✔ ✔ ✔ ✔ ? ✔ ✔ ✔ tables sql-like 2012 Accumulo ✔ ✔ ✔ record compat. w/MR / O O ext. record nosql 2013 Impala ✔ O O O ✔ ✔ O ✔ tables sql-like
- 32. 6/17/2015 Bill Howe, UW 32 Year System/ Paper Scale to 1000s Primary Index Secondary Indexes Transactions Joins/ Analytics Integrity Constraints Views Language/ Algebra Data model my label 1971 RDBMS O ✔ ✔ ✔ ✔ ✔ ✔ ✔ tables sql-like 2003 memcached ✔ ✔ O O O O O O key-val nosql 2004 MapReduce ✔ O O O ✔ O O O key-val batch 2005 CouchDB ✔ ✔ ✔ record MR O ✔ O document nosql 2006 BigTable (Hbase) ✔ ✔ ✔ record compat. w/MR / O O ext. record nosql 2007 MongoDB ✔ ✔ ✔ EC, record O O O O document nosql 2007 Dynamo ✔ ✔ O O O O O O ext. record nosql 2008 Pig ✔ O O O ✔ / O ✔ tables sql-like 2008 HIVE ✔ O O O ✔ ✔ O ✔ tables sql-like 2008 Cassandra ✔ ✔ ✔ EC, record O ✔ ✔ O key-val nosql 2009 Voldemort ✔ ✔ O EC, record O O O O key-val nosql 2009 Riak ✔ ✔ ✔ EC, record MR O key-val nosql 2010 Dremel ✔ O O O / ✔ O ✔ tables sql-like 2011 Megastore ✔ ✔ ✔ entity groups O / O / tables nosql 2011 Tenzing ✔ O O O ✔ ✔ ✔ ✔ tables sql-like 2011 Spark/Shark ✔ O O O ✔ ✔ O ✔ tables sql-like 2012 Spanner ✔ ✔ ✔ ✔ ? ✔ ✔ ✔ tables sql-like 2012 Accumulo ✔ ✔ ✔ record compat. w/MR / O O ext. record nosql 2013 Impala ✔ O O O ✔ ✔ O ✔ tables sql-like MapReduce-based Systems
- 33. 6/17/2015 Bill Howe, UW 33 2004 Hadoop 2005 MapReduce 2006 2007 2008 2009 2010 2011 2012 MapReduce-based Systems non-Google open source implementation direct influence / shared features compatible implementation of Pig HIVE Tenzing Impala
- 34. 6/17/2015 Bill Howe, UW 34 Year System/ Paper Scale to 1000s Primary Index Secondary Indexes Transactions Joins/ Analytics Integrity Constraints Views Language/ Algebra Data model my label 1971 RDBMS O ✔ ✔ ✔ ✔ ✔ ✔ ✔ tables sql-like 2003 memcached ✔ ✔ O O O O O O key-val nosql 2004 MapReduce ✔ O O O ✔ O O O key-val batch 2005 CouchDB ✔ ✔ ✔ record MR O ✔ O document nosql 2006 BigTable (Hbase) ✔ ✔ ✔ record compat. w/MR / O O ext. record nosql 2007 MongoDB ✔ ✔ ✔ EC, record O O O O document nosql 2007 Dynamo ✔ ✔ O O O O O O ext. record nosql 2008 Pig ✔ O O O ✔ / O ✔ tables sql-like 2008 HIVE ✔ O O O ✔ ✔ O ✔ tables sql-like 2008 Cassandra ✔ ✔ ✔ EC, record O ✔ ✔ O key-val nosql 2009 Voldemort ✔ ✔ O EC, record O O O O key-val nosql 2009 Riak ✔ ✔ ✔ EC, record MR O key-val nosql 2010 Dremel ✔ O O O / ✔ O ✔ tables sql-like 2011 Megastore ✔ ✔ ✔ entity groups O / O / tables nosql 2011 Tenzing ✔ O O O ✔ ✔ ✔ ✔ tables sql-like 2011 Spark/Shark ✔ O O O ✔ ✔ O ✔ tables sql-like 2012 Spanner ✔ ✔ ✔ ✔ ? ✔ ✔ ✔ tables sql-like 2012 Accumulo ✔ ✔ ✔ record compat. w/MR / O O ext. record nosql 2013 Impala ✔ O O O ✔ ✔ O ✔ tables sql-like
- 35. 6/17/2015 Bill Howe, UW 35 BigTable Cassandra 2004 2005 memcached 2006 2007 2008 2009 Spanner Megastore 2010 2011 2012 NoSQL Systems direct influence / shared features compatible implementation of Dynamo Voldemort Riak Accumulo 2003 CouchDB MongoDB
- 36. 6/17/2015 Bill Howe, UW 36 A lot of these systems give up joins! Year source System/ Paper Scale to 1000s Primary Index Secondary Indexes Transactions Joins/ Analytics Integrity Constraints Views Language/ Algebra Data model my label 1971 many RDBMS O ✔ ✔ ✔ ✔ ✔ ✔ ✔ tables SQL-like 2003 other memcached ✔ ✔ O O O O O O key-val lookup 2004 Google MapReduce ✔ O O O ✔ O O O key-val MR 2005 couchbase CouchDB ✔ ✔ ✔ record MR O ✔ O document filter/MR 2006 Google BigTable (Hbase) ✔ ✔ ✔ record compat. w/MR / O O ext. record filter/MR 2007 10gen MongoDB ✔ ✔ ✔ EC, record O O O O document filter 2007 Amazon Dynamo ✔ ✔ O O O O O O key-val lookup 2007 Amazon SimpleDB ✔ ✔ ✔ O O O O O ext. record filter 2008 Yahoo Pig ✔ O O O ✔ / O ✔ tables RA-like 2008 Facebook HIVE ✔ O O O ✔ ✔ O ✔ tables SQL-like 2008 Facebook Cassandra ✔ ✔ ✔ EC, record O ✔ ✔ O key-val filter 2009 other Voldemort ✔ ✔ O EC, record O O O O key-val lookup 2009 basho Riak ✔ ✔ ✔ EC, record MR O key-val filter 2010 Google Dremel ✔ O O O / ✔ O ✔ tables SQL-like 2011 Google Megastore ✔ ✔ ✔ entity groups O / O / tables filter 2011 Google Tenzing ✔ O O O ✔ ✔ ✔ ✔ tables SQL-like 2011 Berkeley Spark/Shark ✔ O O O ✔ ✔ O ✔ tables SQL-like 2012 Google Spanner ✔ ✔ ✔ ✔ ? ✔ ✔ ✔ tables SQL-like 2012 Accumulo Accumulo ✔ ✔ ✔ record compat. w/MR / O O ext. record filter 2013 Cloudera Impala ✔ O O O ✔ ✔ O ✔ tables SQL-like
- 37. Joins • Ex: Show all comments by “Sue” on any blog post by “Jim” • Method 1: – Lookup all blog posts by Jim – For each post, lookup all comments and filter for “Sue” • Method 2: – Lookup all comments by Sue – For each comment, lookup all posts and filter for “Jim” • Method 3: – Filter comments by Sue, filter posts by Jim, – Sort all comments by blog id, sort all blogs by blog id – Pull one from each list to find matches 6/17/2015 Bill Howe, UW 37
- 38. 6/17/2015 Bill Howe, UW 38 Year System/ Paper Scale to 1000s Primary Index Secondary Indexes Transactions Joins/ Analytics Integrity Constraints Views Language/ Algebra Data model my label 1971 RDBMS O ✔ ✔ ✔ ✔ ✔ ✔ ✔ tables SQL-like 2003 memcached ✔ ✔ O O O O O O key-val lookup 2004 MapReduce ✔ O O O ✔ O O O key-val MR 2005 CouchDB ✔ ✔ ✔ record MR O ✔ O document filter/MR 2006 BigTable (Hbase) ✔ ✔ ✔ record compat. w/MR / O O ext. record filter/MR 2007 MongoDB ✔ ✔ ✔ EC, record O O O O document filter 2007 Dynamo ✔ ✔ O O O O O O key-val lookup 2008 Pig ✔ O O O ✔ / O ✔ tables RA-like 2008 HIVE ✔ O O O ✔ ✔ O ✔ tables SQL-like 2008 Cassandra ✔ ✔ ✔ EC, record O ✔ ✔ O key-val filter 2009 Voldemort ✔ ✔ O EC, record O O O O key-val lookup 2009 Riak ✔ ✔ ✔ EC, record MR O key-val filter 2010 Dremel ✔ O O O / ✔ O ✔ tables SQL-like 2011 Megastore ✔ ✔ ✔ entity groups O / O / tables filter 2011 Tenzing ✔ O O O O ✔ ✔ ✔ tables SQL-like 2011 Spark/Shark ✔ O O O ✔ ✔ O ✔ tables SQL-like 2012 Spanner ✔ ✔ ✔ ✔ ? ✔ ✔ ✔ tables SQL-like 2012 Accumulo ✔ ✔ ✔ record compat. w/MR / O O ext. record filter 2013 Impala ✔ O O O ✔ ✔ O ✔ tables SQL-like
- 39. • Two value propositions – Performance: “I started with MySQL, but had a hard time scaling it out in a distributed environment” – Flexibility: “My data doesn’t conform to a rigid schema” 6/17/2015 Bill Howe, UW 39 NoSQL Criticism Stonebraker CACM (blog 2)
- 40. NoSQL Criticism: flexibility argument • Who are the customers of NoSQL? – Lots of startups • Very few enterprises. Why? most applications are traditional OLTP on structured data; a few other applications around the “edges”, but considered less important 6/17/2015 Bill Howe, UW 40 Stonebraker CACM (blog 2)
- 41. Some Takeaways • Data wrangling is the hard part of data science, not statistics • Relational algebra is the right abstraction for reasoning about data wrangling • Even “NoSQL” systems that explicitly rejected relational concepts eventually brought them back 6/17/2015 Bill Howe, UW 41