Intro to Pinot (2016-01-04)
22 likes27,911 views

Pinot is a distributed near-realtime OLAP datastore used at LinkedIn for analytics queries. It ingests data from Kafka in real-time and Hadoop in batch. It stores data columnarly and supports hybrid querying across real-time and batch data. Pinot is fault tolerant with no single point of failure and automatically expires old data according to user-defined retention periods for different data sources.



































































Ad
More Related Content
What's hot (20)
Similar to Intro to Pinot (2016-01-04) (20)


















Ad
Recently uploaded (20)




















Ad
Intro to Pinot (2016-01-04)
- 1. an introduction to pinot Jean-François Im <jfi[email protected]> 2016-01-04 Tue
- 2. outline Introduction When to use Pinot? An overview of the Pinot architecture Managing Data in Pinot Data storage Realtime data in Pinot Retention Conclusion 2/38
- 3. introduction
- 4. what is pinot? ∙ Distributed near-realtime OLAP datastore ∙ Used at LinkedIn for various user-facing (“Who viewed my profile,” publisher analytics, etc.), client-facing (ad campaign creation and tracking) and internal analytics (XLNT, EasyBI, Raptor, etc.) 4/38
- 5. what is pinot ∙ Offers a SQL query interface on top of a custom-written data store ∙ Offers near-realtime ingestion of events from Kafka (a few seconds latency at most) ∙ Supports pushing data from Hadoop ∙ Can combine data from Hadoop and Kafka at runtime ∙ Scales horizontally and linearly if data size or query rate increases ∙ Fault tolerant (any component can fail without causing availability issues, no single point of failure) ∙ Automatic data expiration 5/38
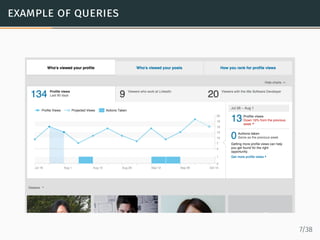
- 6. example of queries SELECT weeksSinceEpochSunday, distinctCount(viewerId) FROM mirrorProfileViewEvents WHERE vieweeId = ... AND (viewerPrivacySetting = ’F’ OR ... OR viewerPrivacySetting = ’’) AND daysSinceEpoch >= 16624 AND daysSinceEpoch <= 16714 GROUP BY weeksSinceEpochSunday TOP 20 LIMIT 0 6/38
- 8. how does “who viewed my profile” work? 8/38
- 9. usage of pinot at linkedin ∙ Over 50 use cases at LinkedIn ∙ Several thousands of queries per second across multiple data centers ∙ Operates 24x7, exposes metrics for production monitoring ∙ The internal de facto solution for scalable data querying 9/38
- 10. when to use pinot?
- 11. design limitations ∙ Pinot is designed for analytical workloads (OLAP), not transactional ones (OLTP) ∙ Data in Pinot is immutable (eg. no UPDATE statement), though it can be overwritten in bulk ∙ Realtime data is append-only (can only load new rows) ∙ There is no support for JOINs or subselects ∙ There are no UDFs for aggregation (work in progress) 11/38
- 12. when to use pinot? ∙ When you have an analytics problem (How many of “x” happened?) ∙ When you have many queries per day and require low query latency (otherwise use Hadoop for one-time ad hoc queries) ∙ When you can’t pre-aggregate data to be stored in some other storage system (otherwise use Voldemort or an OLAP cubing solution) 12/38
- 13. an overview of the pinot architecture
- 14. controller, broker and server ∙ There are three components in Pinot: Controller, broker and server ∙ Controller: Handles cluster-wide coordination using Apache Helix and Apache Zookeeper ∙ Broker: Handles query fan out and query routing to servers ∙ Server: Responds to query requests originating from the brokers 14/38
- 15. controller, broker and server 15/38
- 16. controller, broker and server ∙ All of these components are redundant, so there is no single point of failure by design ∙ Uses Zookeeper as a coordination mechanism 16/38
- 17. managing data in pinot
- 18. getting data into pinot ∙ Let’s first look at the offline case. We have data in Hadoop that we would like to get into Pinot. 18/38
- 19. getting data into pinot ∙ Data in pinot is packaged into segments, which contain a set of rows ∙ These are then uploaded into Pinot 19/38
- 20. getting data into pinot ∙ A segment is a pre-built index over this set of rows ∙ Data in Pinot is stored in columnar format (we’ll get to this later) ∙ Each input Avro file maps to one Pinot segment 20/38
- 21. getting data into pinot ∙ Each segment file that is generated contains both the minimum and maximum timestamp contained in the data ∙ Each segment file also has a sequential number appended to the end ∙ mirrorProfileViewEvents_2015-10-04_2015-10-04_0 ∙ mirrorProfileViewEvents_2015-10-04_2015-10-04_1 ∙ mirrorProfileViewEvents_2015-10-04_2015-10-04_2 21/38
- 22. getting data into pinot ∙ Data uploaded into Pinot is stored on a segment basis ∙ Uploading a segment with the same name overwrites the data that currently exists in that segment ∙ This is the only way to update data in Pinot 22/38
- 23. data storage
- 24. data orientation: rows and columns ∙ Most OLTP databases store data in a row-oriented format ∙ Pinot stores its data in a column-oriented format ∙ If you have heard the terms array of structures (AoS) and structure of arrays (SoA), this is the same idea 24/38
- 25. data orientation: rows and columns 25/38
- 26. benefits of column-orientation ∙ Queries only read the data they need (columns not used in a query are not read) ∙ Individual row lookups are slower, aggregations are faster ∙ Compression can be a lot more effective, as related data is packed together 26/38
- 27. a couple of tricks ∙ Pinot uses a couple of techniques to reduce data size ∙ Dictionary encoding allows us to deduplicate repetitive data in a single column (eg. country, state, gender) ∙ Bit packing allows us to pack multiple values in the same byte/word/dword 27/38
- 28. realtime data in pinot
- 29. tables: offline and realtime ∙ Pinot has two kinds of tables: offline and realtime ∙ An offline table stores data that has been pushed from Hadoop, while a realtime sources its data from Kafka ∙ These two tables are disjoint and can contain the same data 29/38
- 30. data ingestion ∙ Realtime data ingestion is done through Kafka ∙ In the open source release, there is a JSON decoder and an Avro decoder for messages ∙ This architecture allows plugging in new data ingestion sources (eg. other message queuing systems), though at this time there are no other sources implemented 30/38
- 31. hybrid querying ∙ Since realtime and offline tables are disjoint, how are they queried? ∙ If an offline and realtime table have the same name, when a broker receives a query, it rewrites it to two queries, one for the offline and one for the realtime table 31/38
- 32. hybrid querying ∙ Data is partitioned according to a time column, with a preference given to offline data 32/38
- 33. data ∙ Since there are two data sources for the same data, if there is an issue with one (eg. Kafka/Samza issue or Hadoop cluster issue), the other one is used to answer queries ∙ This means that you don’t get called in the middle of the night for data-related issues and there’s a large time window for fixing issues 33/38
- 34. retention
- 35. retention ∙ Tables in Pinot can have a customizable retention period ∙ Segments will be expunged automatically when their last timestamp is past the retention period ∙ This is done by a process called the retention manager 35/38
- 36. retention ∙ Offline and realtime tables have different retention periods. For example, “who viewed my profile?” has a realtime retention of seven days and an offline retention period of 90 days. ∙ This means that even if the Hadoop job doesn’t run for a couple of days, data from the realtime flow will answer the query 36/38
- 37. conclusion
- 38. conclusion ∙ Pinot is a realtime distributed analytical data store that can handle interactive analytical queries running on large amounts of data ∙ It’s used for various internal and external use-cases at LinkedIn ∙ It’s open source! (github.com/linkedin/pinot) ∙ Ping me if you want to deploy it, I’ll help you out 38/38