Introduction to Apache Flink at Vienna Meet Up
Download as PPTX, PDF1 like372 views

The document provides an introduction to Apache Flink, emphasizing its capabilities as a native streaming data flow engine. It contrasts streaming and batch processing, highlighting the evolution of technologies and the growing demand for real-time data processing in business. Flink's architecture supports various workloads, including streaming topologies, batch pipelines, and machine learning, making it a versatile solution for modern data processing needs.









![10
Optimized Execution
case class Path (from: Long, to:
Long)
val tc = edges.iterate(10) {
paths: DataSet[Path] =>
val next = paths
.join(edges)
.where("to")
.equalTo("from") {
(path, edge) =>
Path(path.from, edge.to)
}
.union(paths)
.distinct()
next
}
Optimizer
Type extraction
stack
Task
scheduling
Dataflow
metadata
Pre-flight (Client)
Master
Worker
Data Source
orders.tbl
Filter
Map DataSource
lineitem.tbl
Join
Hybrid Hash
buildHT probe
hash-part [0] hash-part [0]
GroupRed
sort
forward
Program
Dataflow Graph
Independent of
batch or
streaming job
deploy
operators
track
intermediate
results](https://image.slidesharecdn.com/introductiontoflink-meetupvienna-151022122019-lva1-app6891/85/Introduction-to-Apache-Flink-at-Vienna-Meet-Up-10-320.jpg)







![19
Expressive APIs
19
case class Word (word: String, frequency: Int)
val lines: DataStream[String] = env.fromSocketStream(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.window(Time.of(5,SECONDS)).every(Time.of(1,SECONDS))
.groupBy("word").sum("frequency")
.print()
val lines: DataSet[String] = env.readTextFile(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.groupBy("word").sum("frequency")
.print()
DataSet API (batch):
DataStream API (streaming):](https://image.slidesharecdn.com/introductiontoflink-meetupvienna-151022122019-lva1-app6891/85/Introduction-to-Apache-Flink-at-Vienna-Meet-Up-19-320.jpg)


Introduction to Apache Flink at Vienna Meet Up
- 1. Introduction to Apache Flink A native Streaming Data Flow Engine Stefan Papp 21.10.2015 – The day of Marty McFlys Arrival
- 2. 2 #Streaming Streaming is the biggest thing since Hadoop
- 3. 3 Streaming Process data immediately at event time. Consequences • Data is processed immediately • The act of processing data is more repetitive Batch Processing Process collected data at scheduled time or when a sufficient amount of data has been accumulated. Consequences • More transactions processed at one time in a single process • Higher processing time #Stream vs Batch Batch Processing vs. Streaming
- 4. 4 Past • Insufficent technologies for streaming, focus on batch • Some technologies were not real streaming, but only microbatches • Either batch or streaming, but no engine that can do both Now • Technologies have matured • Streaming is highly demanded in business Streaming – The challenges in the past #Stream
- 6. 6 #Streaming The Focus moves from Storage to Processing
- 7. 7 Technology Stack Storage Layer General Purpose Processing Engine SQL Engine Abstraction Engine ML Graph Streaming
- 8. 8 Technology Stack with Technologies Hadoop, S3,... Flink, Spark Hive, SparkSQL Cascading, Pig FlinkML, MLLib Gelly, GraphX Flink, Spark Streaming
- 9. 9 Old Style Batch Processing: MapReduce Step Step Step Step Step Client for (int i = 0; i < maxIterations; i++) { // Execute MapReduce job }
- 10. 10 Optimized Execution case class Path (from: Long, to: Long) val tc = edges.iterate(10) { paths: DataSet[Path] => val next = paths .join(edges) .where("to") .equalTo("from") { (path, edge) => Path(path.from, edge.to) } .union(paths) .distinct() next } Optimizer Type extraction stack Task scheduling Dataflow metadata Pre-flight (Client) Master Worker Data Source orders.tbl Filter Map DataSource lineitem.tbl Join Hybrid Hash buildHT probe hash-part [0] hash-part [0] GroupRed sort forward Program Dataflow Graph Independent of batch or streaming job deploy operators track intermediate results
- 11. 11 Old Style Streaming (Micro Batches) stream discretizer Job Job Job Job while (true) { // get next few records // issue batch job }
- 12. 12 Streaming Topology #Streaming Data Source 1 Data Source 2 Sprout Sprout Bolt BoltBolt Bolt Target Topology
- 13. 13 #Streaming Apache Flink is a Native Streaming GPPE
- 14. 14 The Flink Ecosystem in a Nutshell 14 Gelly Table ML SAMOA DataSet (Java/Scala/Python) DataStream (Java/Scala) HadoopM/R Local Remote Yarn Tez Embedded Dataflow Dataflow(WiP) MRQL Table Cascading(WiP) Streaming dataflow runtime
- 15. 15 Native workload support #workload Flink Streaming topologies Long batch pipelines Machine Learning at scale Graph Analysis
- 16. 16 1. Execute everything as streams 2. Allow some iterative (cyclic) dataflows 3. Allow some mutable state 4. Operate on managed memory Flink Engine – Core Features
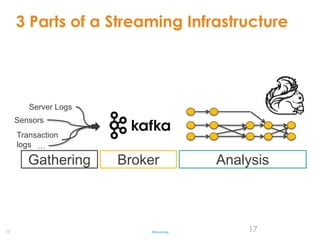
- 17. 17 3 Parts of a Streaming Infrastructure #Streaming 17 Gathering Broker Analysis Sensors Transaction logs … Server Logs
- 18. 18 • Batch programs are a special kind of streaming program Batch on Streaming Infinite Streams Finite Streams Stream Windows Global View Pipelined Data Exchange Pipelined or Blocking Exchange Streaming Programs Batch Programs
- 19. 19 Expressive APIs 19 case class Word (word: String, frequency: Int) val lines: DataStream[String] = env.fromSocketStream(...) lines.flatMap {line => line.split(" ") .map(word => Word(word,1))} .window(Time.of(5,SECONDS)).every(Time.of(1,SECONDS)) .groupBy("word").sum("frequency") .print() val lines: DataSet[String] = env.readTextFile(...) lines.flatMap {line => line.split(" ") .map(word => Word(word,1))} .groupBy("word").sum("frequency") .print() DataSet API (batch): DataStream API (streaming):
- 20. 20 Table API 20 val customers = env.readCsvFile(…).as('id, 'mktSegment) .filter("mktSegment = AUTOMOBILE") val orders = env.readCsvFile(…) .filter( o => dateFormat.parse(o.orderDate).before(date) ) .as("orderId, custId, orderDate, shipPrio") val items = orders .join(customers).where("custId = id") .join(lineitems).where("orderId = id") .select("orderId, orderDate, shipPrio, extdPrice * (Literal(1.0f) – discount) as revenue") val result = items .groupBy("orderId, orderDate, shipPrio") .select('orderId, revenue.sum, orderDate, shipPrio")
- 21. 21 Data Source – Processing – Data Sink © 2014 Teradata
Editor's Notes
- #11: toy program: native transitive closure type extraction: types that go in and out of each operator