Introduction to deep learning using python
2 likes213 views

A brief introduction to machine learning and a short example on how to use Python and TensorFlow to build a neural network.















![MNIST training data
>>> import matplotlib.pyplot as plt
>>> plt.imshow(train_images[0])
>>> plt.gray()
>>> plt.show()
>>> train_labels
array([5, 0, 4, ..., 5, 6, 8], dtype=uint8)](https://image.slidesharecdn.com/introductiontodeeplearningusingpython-180516210151/85/Introduction-to-deep-learning-using-python-19-320.jpg)
![MNIST testing data
>>> test_images.shape
(10000, 28, 28)
>>> test_labels
array([7, 2, 1, ..., 4, 5, 6], dtype=uint8)
Testing input: 10,000 images (28 pixels * 28 pixels)
Testing labels: 10,000
Training
60,000 images
60,000 labels
Testing
10,000 images
10,000 labels](https://image.slidesharecdn.com/introductiontodeeplearningusingpython-180516210151/85/Introduction-to-deep-learning-using-python-20-320.jpg)
![Data Reshaping (Input X)
# Train images
>>> train_images = train_images.reshape((60000, 28 * 28))
>>> train_images = train_images.astype('float32') / 255
# Test images
>>> test_images = test_images.reshape((10000, 28 * 28))
>>> test_images = test_images.astype('float32') / 255
1. 28 * 28 image (int values 0 -
255)
2. 28 * 28 = 784-element vector:
[row 0, row 1, …, row 27]
3. 784-element vectors with float
values in range 0 to 1](https://image.slidesharecdn.com/introductiontodeeplearningusingpython-180516210151/85/Introduction-to-deep-learning-using-python-21-320.jpg)
![Data Reshaping (Labels Y)
>>> from keras.utils import to_categorical
# Train labels
>>> train_labels = to_categorical(train_labels)
# Test labels
>>> test_labels = to_categorical(test_labels)
1. train_labels = [5 0 4 ... 5 6 8]
2. train_labels =
[[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
…
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]]](https://image.slidesharecdn.com/introductiontodeeplearningusingpython-180516210151/85/Introduction-to-deep-learning-using-python-22-320.jpg)

![Network compilation
>>> network.compile(optimizer='rmsprop',
... loss='categorical_crossentropy',
... metrics=['accuracy'])](https://image.slidesharecdn.com/introductiontodeeplearningusingpython-180516210151/85/Introduction-to-deep-learning-using-python-26-320.jpg)

![Let’s train!
>>> network.fit(train_images, train_labels, epochs=5, batch_size=128)
Epoch 1/5
60000/60000 [==============================] - 2s 33us/step - loss: 0.2179 - acc: 0.9329
Epoch 2/5
60000/60000 [==============================] - 2s 31us/step - loss: 0.0805 - acc: 0.9750
Epoch 3/5
60000/60000 [==============================] - 2s 32us/step - loss: 0.0531 - acc: 0.9841
Epoch 4/5
60000/60000 [==============================] - 2s 31us/step - loss: 0.0385 - acc: 0.9883
Epoch 5/5
60000/60000 [==============================] - 2s 31us/step - loss: 0.0290 - acc: 0.9908
Train
Accuracy: 99.08%](https://image.slidesharecdn.com/introductiontodeeplearningusingpython-180516210151/85/Introduction-to-deep-learning-using-python-28-320.jpg)
![Test Accuracy
>>> test_loss, test_acc = network.evaluate(test_images, test_labels)
10000/10000 [==============================] - 0s 47us/step
>>> print('Test accuracy: %s' % test_acc)
Test accuracy: 0.9799
Test Accuracy: 97.99%](https://image.slidesharecdn.com/introductiontodeeplearningusingpython-180516210151/85/Introduction-to-deep-learning-using-python-29-320.jpg)


























![Dimension reduction techniques[Feature Selection]](https://cdn.slidesharecdn.com/ss_thumbnails/dimensionreductiontechnibyaakankshajain-210625102243-thumbnail.jpg?width=560&fit=bounds)






Ad
More Related Content
What's hot (13)
Similar to Introduction to deep learning using python (20)











Ad
Recently uploaded (20)




















Ad
Introduction to deep learning using python
- 1. Introduction to Deep Learning using Python Lino Coria [email protected] @linocoria
- 2. About Wiivv Wiivv is a technology company transforming footwear and apparel for every human body. Wiivv Insoles and Sandals are created uniquely for you, based on measurements taken from the award-winning Wiivv app.
- 3. Testing our sandals - Boston Marathon 2018
- 4. What is Deep Learning?
- 5. AI, Machine Learning, Deep Learning Artificial Intelligence Machine Learning Deep Learning
- 6. Artificial Intelligence - Deep Learning
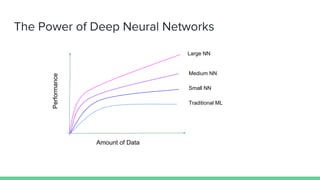
- 8. The Power of Deep Neural Networks Amount of Data Performance Traditional ML Small NN Medium NN Large NN
- 9. Why is Deep Learning in Vogue? ● Hardware ○ GPUs ○ NVIDIA leading the way ● Tons of Data ○ ImageNet dataset: 1.4 million annotated images ● Better Algorithms ● Democratic ○ If you know Python, you can do deep learning ○ Many tutorials, pre-trained models
- 10. Deep Learning and Python
- 11. Open-Source Resources for Deep Learning Keras
- 12. A good way to start Keras
- 13. How to get Data
- 14. Example: MNIST Dataset A classic Machine Learning problem Input X (Images) Labels Y: 5 0 4 (Answers)
- 15. Training Data + Testing Data Input X (Images) Labels Y Training Data Input X (Images) Labels Y Testing Data
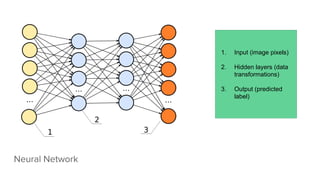
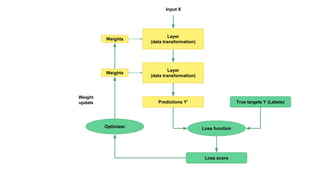
- 16. Neural Network 1. Input (image pixels) 2. Hidden layers (data transformations) 3. Output (predicted label)
- 17. Weights Layer (data transformation) Input X Weights Layer (data transformation) Predictions Y’ True targets Y (Labels) Loss function Loss score Optimizer Weight update
- 18. Load MNIST Data >>> import keras >>> from keras.datasets import mnist >>> (train_images, train_labels), (test_images, test_labels) = mnist.load_data() >>> train_images.shape (60000, 28, 28) >>> len(train_labels) 60000 Training input: 60,000 images (28 pixels * 28 pixels) Training labels: 60,000
- 19. MNIST training data >>> import matplotlib.pyplot as plt >>> plt.imshow(train_images[0]) >>> plt.gray() >>> plt.show() >>> train_labels array([5, 0, 4, ..., 5, 6, 8], dtype=uint8)
- 20. MNIST testing data >>> test_images.shape (10000, 28, 28) >>> test_labels array([7, 2, 1, ..., 4, 5, 6], dtype=uint8) Testing input: 10,000 images (28 pixels * 28 pixels) Testing labels: 10,000 Training 60,000 images 60,000 labels Testing 10,000 images 10,000 labels
- 21. Data Reshaping (Input X) # Train images >>> train_images = train_images.reshape((60000, 28 * 28)) >>> train_images = train_images.astype('float32') / 255 # Test images >>> test_images = test_images.reshape((10000, 28 * 28)) >>> test_images = test_images.astype('float32') / 255 1. 28 * 28 image (int values 0 - 255) 2. 28 * 28 = 784-element vector: [row 0, row 1, …, row 27] 3. 784-element vectors with float values in range 0 to 1
- 22. Data Reshaping (Labels Y) >>> from keras.utils import to_categorical # Train labels >>> train_labels = to_categorical(train_labels) # Test labels >>> test_labels = to_categorical(test_labels) 1. train_labels = [5 0 4 ... 5 6 8] 2. train_labels = [[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.] [1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 1. 0. 0. 0. 0. 0.] … [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 1. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]]
- 23. Building our Network >>> from keras import models >>> from keras import layers >>> network = models.Sequential() >>> network.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,))) >>> network.add(layers.Dense(512, activation='relu')) >>> network.add(layers.Dense(10, activation='softmax'))
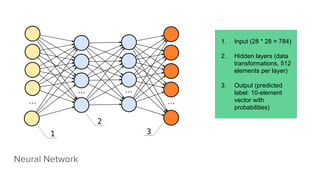
- 24. Neural Network 1. Input (28 * 28 = 784) 2. Hidden layers (data transformations, 512 elements per layer) 3. Output (predicted label: 10-element vector with probabilities)
- 25. Weights Layer (data transformation) Input X Weights Layer (data transformation) Predictions Y’ True targets Y (Labels) Loss function Loss score Optimizer Weight update
- 26. Network compilation >>> network.compile(optimizer='rmsprop', ... loss='categorical_crossentropy', ... metrics=['accuracy'])
- 27. Weights Layer (data transformation) Input X Weights Layer (data transformation) Predictions Y’ True targets Y (Labels) Loss function Loss score Optimizer Weight update
- 28. Let’s train! >>> network.fit(train_images, train_labels, epochs=5, batch_size=128) Epoch 1/5 60000/60000 [==============================] - 2s 33us/step - loss: 0.2179 - acc: 0.9329 Epoch 2/5 60000/60000 [==============================] - 2s 31us/step - loss: 0.0805 - acc: 0.9750 Epoch 3/5 60000/60000 [==============================] - 2s 32us/step - loss: 0.0531 - acc: 0.9841 Epoch 4/5 60000/60000 [==============================] - 2s 31us/step - loss: 0.0385 - acc: 0.9883 Epoch 5/5 60000/60000 [==============================] - 2s 31us/step - loss: 0.0290 - acc: 0.9908 Train Accuracy: 99.08%
- 29. Test Accuracy >>> test_loss, test_acc = network.evaluate(test_images, test_labels) 10000/10000 [==============================] - 0s 47us/step >>> print('Test accuracy: %s' % test_acc) Test accuracy: 0.9799 Test Accuracy: 97.99%
- 30. Resources Online Udacity, Coursera PyImageSearch Book Deep Learning with Python by Francois Chollet