






![Indexing
POST /library/book
{
"title": "Elasticsearch in Action",
"author": [ "Radu Gheorghe",
"Matthew Lee Hinman",
"Roy Russo" ],
"published": "2015-06-30T00:00:00.000Z",
"publisher": {
"name": "Manning",
"country": "USA"
},
"tags": [ "Computer Science", "Development"]
}](https://image.slidesharecdn.com/introduction-to-elasticsearch-online-161119023116/85/Introduction-to-elasticsearch-8-320.jpg)
![Parameter Search
GET /library/book/_search?q=elasticsearch
{
[...]
"hits": {
"hits": [
{
"_index": "library",
"_type": "book",
"_source": {
"title": "Elasticsearch in Action",
[...]](https://image.slidesharecdn.com/introduction-to-elasticsearch-online-161119023116/85/Introduction-to-elasticsearch-9-320.jpg)



















![Terms-Aggregation
"aggregations": {
"common-tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "Development",
"doc_count": 2
},
{
"key": "Computer Science",
"doc_count": 1
}]
[...]](https://image.slidesharecdn.com/introduction-to-elasticsearch-online-161119023116/85/Introduction-to-elasticsearch-34-320.jpg)

















































Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to Introduction to elasticsearch (20)




















Ad
More from Florian Hopf (8)








Recently uploaded (20)




















Introduction to elasticsearch
- 6. Installation # download archive wget https://artifacts.elastic.co/downloads/ elasticsearch/elasticsearch-5.0.0.zip unzip elasticsearch-5.0.0.zip # on windows: elasticsearch.bat elasticsearch-5.0.0/bin/elasticsearch
- 7. Access via HTTP curl -XGET "http://localhost:9200" { "name" : "LI8ZN-t", "cluster_name" : "elasticsearch", "cluster_uuid" : "UvbMAoJ8TieUqugCGw7Xrw", "version" : { "number" : "5.0.0", "build_hash" : "253032b", "build_date" : "2016-10-26T04:37:51.531Z", "build_snapshot" : false, "lucene_version" : "6.2.0" }, "tagline" : "You Know, for Search" }
- 8. Indexing POST /library/book { "title": "Elasticsearch in Action", "author": [ "Radu Gheorghe", "Matthew Lee Hinman", "Roy Russo" ], "published": "2015-06-30T00:00:00.000Z", "publisher": { "name": "Manning", "country": "USA" }, "tags": [ "Computer Science", "Development"] }
- 9. Parameter Search GET /library/book/_search?q=elasticsearch { [...] "hits": { "hits": [ { "_index": "library", "_type": "book", "_source": { "title": "Elasticsearch in Action", [...]
- 10. Search via Query DSL POST /library/book/_search { "query": { "bool": { "must": { "match": { "title": "elasticsearch" } }, "filter": { "term": { "publisher.name": "manning" } } } } }
- 11. Language Specific Search POST /library/book/_search { "query": { "match": { "tags": "development" } } }
- 12. Language Specific Search POST /library/book/_search { "query": { "match": { "tags": "developing" } } }
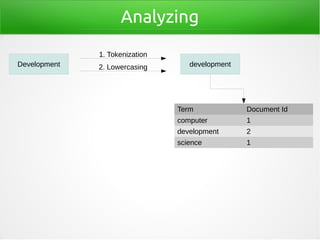
- 13. Analyzing 1. Tokenization Computer Science Development Term Document Id computer 1 development 2 science 1
- 14. Analyzing 1. Tokenization Computer Science Development 2. Lowercasing Term Document Id computer 1 development 2 science 1
- 15. Analyzing 1. Tokenization 2. LowercasingDevelopment development Term Document Id computer 1 development 2 science 1
- 16. Analyzing 1. Tokenization 2. LowercasingDeveloping developing Term Document Id computer 1 development 2 science 1
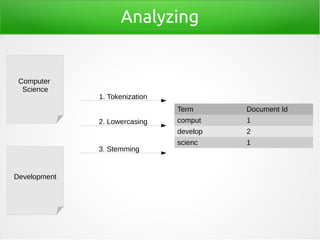
- 17. Analyzing Term Document Id comput 1 develop 2 scienc 1 1. Tokenization Computer Science Development 2. Lowercasing 3. Stemming
- 18. Analyzing 1. Tokenization 2. LowercasingDeveloping develop Term Document Id comput 1 develop 2 scienc 1 3. Stemming
- 19. Mapping PUT /library/book/_mapping { "book": { "properties": { "title": { "type": "text", "analyzer": "english" } } } }
- 20. Full Text Search Features ● Analyzer, preconfigured or custom ● Relevance ● Paging, sorting ● Highlighting, auto completion, ... ● Faceting using Aggregations
- 21. Recap ● Java-based search server ● Communication HTTP and JSON ● Document based storage ● Search using Query DSL ● Inverted index
- 22. Scaling
- 23. Scaling
- 24. Scaling
- 25. Scaling
- 26. Scaling
- 27. Scaling
- 28. Scaling
- 29. Recap ● Nodes form a cluster ● Distribute data using shards ● Replicas for request load, fault tolerance
- 30. Aggregations
- 31. Aggregations ● Information on data ● Faceting ● Search applications and analytics
- 32. Aggregations
- 33. Terms-Aggregation POST /library/book/_search { "size": 0, "aggs": { "common-tags": { "terms": { "field": "tags.keyword" } } } }
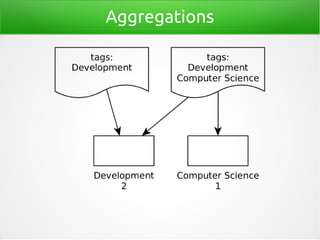
- 34. Terms-Aggregation "aggregations": { "common-tags": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 0, "buckets": [ { "key": "Development", "doc_count": 2 }, { "key": "Computer Science", "doc_count": 1 }] [...]
- 36. Metric-Aggregations ● Calculate one or more values ● Often on numeric fields ● Stats, Percentiles, Min, Max, Sum, Avg, ...
- 37. Stats-Aggregation GET /library/book/_search { "aggs": { "published_stats": { "stats": { "field": "published" } } } }
- 38. Stats-Aggregation "aggregations": { "published_stats": { "count": 5, "min": 1419292800000, "max": 1445990400000, "avg": 1440547200000, "sum": 7202736000000, "min_as_string": "2014-12-23T00:00:00.000Z", "max_as_string": "2015-10-28T00:00:00.000Z", "avg_as_string": "2015-08-26T00:00:00.000Z", "sum_as_string": "2198-03-31T00:00:00.000Z" } }
- 39. Combine Aggregations ● Aggregations can be combined ● Even more detailed view of data ● Tags per publishing date range ● Tags per author ● ...
- 40. Recap ● Aggregations allow new view at data ● Faceting ● Basis for visualization
- 42. Centralized Logging ● Centralize logs of applications ● Centralize logs of machines ● No machine access for developers ● Easy searching ● Real-Time-Analysis ● Visualization
- 46. Logstash-Config input { file { path => "/var/log/apache2/access.log" } } filter { grok { match => { message => "%{COMBINEDAPACHELOG}" } } } output { elasticsearch_http { host => "localhost" } }
- 47. Kibana
- 48. Kibana
- 49. Recap ● Ingestion, enrichment and storage of log events ● Countless inputs in Logstash ● Centralization ● Visualization ● Analysis
- 50. Accessing Elasticsearch ● Lots of clients available ● Access via HTTP ● Sniffing ● Java ● Transport Client, RestClient
- 51. There‘s a lot more! ● Different full text search features ● Lots of aggregations ● Geodata ● Percolator
- 52. More Information
- 53. More Information ● http://elastic.co ● Elasticsearch – The definitive Guide ● https://www.elastic.co/guide/en/elasticsearch/gui de/master/index.html ● Elasticsearch in Action ● https://www.manning.com/books/elasticsearch-in- action ● http://blog.florian-hopf.de