























![Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU
Interacting with HDFS
• Interacting with HDFS is primarily performed from the command
line using the script named hdfs. The hdfs script has the
following usage:
• The -option argument is the name of a specific option for the
specified command, and <arg> is one or more arguments that that
are specified for this option.
• For example, show help
25
$ hadoop fs [-option <arg>]
$ hadoop fs -help](https://image.slidesharecdn.com/week112017-170423155723/85/Introduction-to-Hadoop-and-MapReduce-25-320.jpg)

![Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU
Interacting with HDFS
• Creating a directory
• To create the books directory within HDFS, use the -mkdir
command:
• For example, create books directory in home directory
• Use the -ls command to verify that the previous directories were
created:
27
$ hadoop fs -mkdir [directory name]
$ hadoop fs -mkdir books
$ hadoop fs -ls](https://image.slidesharecdn.com/week112017-170423155723/85/Introduction-to-Hadoop-and-MapReduce-27-320.jpg)
![Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU
Interacting with HDFS
• Copy Data onto HDFS
• After a directory has been created for the current user, data can
be uploaded to the user’s HDFS home directory with the -put
command:
• For example, copy book file from local to HDFS
• Use the -ls command to verify that pg20417.txt was moved to
HDFS:
28
$ hadoop fs -put [source file] [destination file]
$ hadoop fs -put pg20417.txt books/pg20417.txt
$ hadoop fs -ls books](https://image.slidesharecdn.com/week112017-170423155723/85/Introduction-to-Hadoop-and-MapReduce-28-320.jpg)

![Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU
Interacting with HDFS
• Retrieve (view) Data from HDFS
• Data can also be copied from HDFS to the local filesystem using
the -get command. The -get command is the opposite of the -put
command:
• For example, This command copies pg20417.txt from HDFS to the
local filesystem.
30
$ hadoop fs -get [source file] [destination file]
$ hadoop fs -get pg20417.txt .](https://image.slidesharecdn.com/week112017-170423155723/85/Introduction-to-Hadoop-and-MapReduce-30-320.jpg)



















































![Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU
MapReduce examples: shared friendship
• The following Python pseudocode demonstrates how to perform
this computation:
85
def map(person, friends):
for friend in friends.split(“,”):
pair = sort([person, friend])
emit(pair,friends)
def reduce(pair, friends):
shared = set(friend[0])
shared = shared.intersection(friends[1])
emit(pair,shared)](https://image.slidesharecdn.com/week112017-170423155723/85/Introduction-to-Hadoop-and-MapReduce-85-320.jpg)





























































Ad
More Related Content
What's hot (20)
Similar to Introduction to Hadoop and MapReduce (20)


















Ad
Recently uploaded (20)




















Ad
Introduction to Hadoop and MapReduce
- 1. BD514: Big Data Management Eakasit Pacharawongsakda, Ph.D. [email protected] 23/04/2017 Week 11: MapReduce and Hadoop Reference: "Data Analytics with Hadoop: An Introduction for Data Scientists", Benjamin Bengfort and Jenny Kim, 2016 "Hadoop with Python", Zachary Radtka and Donald Miner, 2016 "Mining of Massive Datasets",Jure Leskovec, Anand Rajaraman and Jeff Ullman, 2014
- 2. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Books • "Data Analytics with Hadoop: An Introduction for Data Scientists", Benjamin Bengfort and Jenny Kim, 2016 • "Hadoop with Python", Zachary Radtka and Donald Miner, 2016 • "Mining of Massive Datasets",Jure Leskovec, Anand Rajaraman and Jeff Ullman, 2014 • “Big Data Fundamentals: Concepts, Drivers & Techniques”, Thomas Erl, Wajid Khattak and Paul Buhler, 2016 2
- 3. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Outline • Introduction • Hadoop Architecture • Hadoop Distributed File System (HDFS) • MapReduce • Hadoop Streaming • Hadoop with Python 3
- 4. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Introduction • Modern applications, often called “big-data” analysis, require us to manage immense amounts of data quickly. • To deal with applications such as these, a new software stack has evolved. • These programming systems are designed to get their parallelism not from a “supercomputer,” but from “computing clusters” • large collections of commodity hardware, including conventional processors (“compute nodes”) connected by Ethernet cables or inexpensive switches. 4
- 5. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Introduction • In order to perform computation at scale, Hadoop distributes an analytical computation that involves a massive dataset to many machines that each simultaneously operate on their own individual chunk of data. • Distributed system must meet the following requirements: • Fault tolerance • Recoverability • Consistency • Scalability 5
- 6. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Introduction • Distributed system must meet the following requirements: • Fault tolerance • If component fails, it should not result in the failure of the entire system. • The system should gracefully degrade into a lower performing state. • If a failed component recovers, it should be able to rejoin the system. • Recoverability • In the event of failure, no data should be lost. • Consistency • The failure of one job or task should not affect the final result. 6
- 7. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Introduction • Distributed system must meet the following requirements: • Scalability • Increasing resources should result in a proportional increase in capacity. • Hadoop addresses these requirements through several abstract concepts as described in the following list • Data is distributed immediately when added to the cluster and stored on multiple nodes. Nodes prefer to process data that is stored locally in order to minimize traffic across the network. 7
- 8. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Introduction • Hadoop addresses these requirements through several abstract concepts as described in the following list • Data is stored in blocks of a fixed size (usually 128 MB) and each block is duplicated multiple times across the system to provide redundancy and data safety. • A computation is usually referred to as a job: jobs are broken into tasks where each individual node performs the task on a single block of data. • The amount of network traffic between nodes should be minimised transparently by the system. Each task should be independent and nodes should not have to communicate with each other during processing. 8
- 9. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Outline • Introduction • Hadoop Architecture • Hadoop Distributed File System (HDFS) • MapReduce • Hadoop Streaming • Hadoop with Python 9
- 10. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop architecture • Hadoop is composed of two primary components that implement the basic concepts of distributed storage and computation: HDFS and YARN • HDFS (sometimes shortened to DFS) is the Hadoop Distributed File System, responsible for managing data stored on disks across the cluster. • YARN acts as a cluster resource manager, allocating computational assets (processing availability and memory on worker nodes) to applications that wish to perform a distributed computation. 10
- 11. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop architecture 11 Image source: "Data Analytics with Hadoop: An Introduction for Data Scientists", Benjamin Bengfort and Jenny Kim, 2016
- 12. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop architecture • HDFS and YARN work in concert to minimize the amount of network traffic in the cluster primarily by ensuring that data is local to the required computation. • A set of machines that is running HDFS and YARN is known as a cluster, and the individual machines are called nodes. • A cluster can have a single node, or many thousands of nodes, but all clusters scale horizontally, meaning as you add more nodes, the cluster increases in both capacity and performance in a linear fashion. 12
- 13. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop architecture • Each node in the cluster is identified by the type of process that it runs: • Master nodes • These nodes run coordinating services for Hadoop workers and are usually the entry points for user access to the cluster. • Worker nodes • Worker nodes run services that accept tasks from master nodes either to store or retrieve data or to run a particular application. • A distributed computation is run by parallelizing the analysis across worker nodes. 13
- 14. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop architecture • For HDFS, the master and worker services are as follows: • NameNode (Master) • Stores the directory tree of the file system, file metadata, and the location of each file in the cluster. • Clients wanting to access HDFS must first locate the appropriate storage nodes by requesting information from the NameNode. • DataNode (Worker) • Stores and manages HDFS blocks on the local disk. • Reports health and status of individual data stores back to the NameNode 14
- 15. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop architecture • An HDFS cluster with a replication factor of two; the NameNode contains the mapping of files to blocks, and the DataNodes store the blocks and their replicas 15 Image source: "Hadoop with Python", Zachary Radtka and Donald Miner, 2016
- 16. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop architecture • When data is accessed from HDFS • a client application must first make a request to the NameNode to locate the data on disk. • The NameNode will reply with a list of DataNodes that store the data. • the client must then directly request each block of data from the DataNode. 16
- 17. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop architecture • YARN has multiple master services and a worker service as follows: • ResourceManager (Master) • Allocates and monitors available cluster resources (e.g., physical assets like memory and processor cores) • handling scheduling of jobs on the cluster • ApplicationMaster (Master) • Coordinates a particular application being run on the cluster as scheduled by the ResourceManager 17
- 18. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop architecture • YARN has multiple master services and a worker service as follows: • NodeManager (Worker) • Runs and manages processing tasks on an individual node as well as reports the health and status of tasks as they’re running 18
- 19. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop architecture • A small Hadoop cluster with two master nodes and four workers nodes that implements all six primary Hadoop services 19 Image source: "Data Analytics with Hadoop: An Introduction for Data Scientists", Benjamin Bengfort and Jenny Kim, 2016
- 20. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop architecture • Clients that wish to execute a job • must first request resources from the ResourceManager, which assigns an application-specific ApplicationMaster for the duration of the job. • the ApplicationMaster tracks the execution of the job. • the ResourceManager tracks the status of the nodes • each individual NodeManager creates containers and executes tasks within them 20
- 21. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop architecture • Finally, one other type of cluster is important to note: a single node cluster. • In “pseudo-distributed mode” a single machine runs all Hadoop daemons as though it were part of a cluster, but network traffic occurs through the local loopback network interface. • Hadoop developers typically work in a pseudo-distributed environment, usually inside of a virtual machine to which they connect via SSH. • Cloudera, Hortonworks, and other popular distributions of Hadoop provide pre-built virtual machine images that you can download and get started with right away. 21
- 22. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Outline • Introduction • Hadoop Architecture • Hadoop Distributed File System (HDFS) • MapReduce • Hadoop Streaming • Hadoop with Python 22
- 23. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop Distributed File System (HDFS) • HDFS provides redundant storage for big data by storing that data across a cluster of cheap, unreliable computers, thus extending the amount of available storage capacity that a single machine alone might have. • HDFS performs best with modest number of very large files • millions of large files (100 MB or more) rather than billions of smaller files that might occupy the same volume. • It is not a good fit as a data backend for applications that require updates in real-time, interactive data analysis, or record-based transactional support. 23
- 24. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop Distributed File System (HDFS) • HDFS files are split into blocks, usually of either 64MB or 128MB. • Blocks allow very large files to be split across and distributed to many machines at run time. • Additionally, blocks will be replicated across the DataNodes. • by default, the replication is three fold • Therefore, each block exists on three different machines and three different disks, and if even two node fail, the data will not be lost. 24
- 25. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Interacting with HDFS • Interacting with HDFS is primarily performed from the command line using the script named hdfs. The hdfs script has the following usage: • The -option argument is the name of a specific option for the specified command, and <arg> is one or more arguments that that are specified for this option. • For example, show help 25 $ hadoop fs [-option <arg>] $ hadoop fs -help
- 26. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Interacting with HDFS • List directory contents • use -ls command: • Running the -ls command on a new cluster will not return any results. This is because the -ls command, without any arguments, will attempt to display the contents of the user’s home directory on HDFS. • Providing -ls with the forward slash (/) as an argument displays the contents of the root of HDFS: 26 $ hadoop fs -ls $ hadoop fs -ls /
- 27. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Interacting with HDFS • Creating a directory • To create the books directory within HDFS, use the -mkdir command: • For example, create books directory in home directory • Use the -ls command to verify that the previous directories were created: 27 $ hadoop fs -mkdir [directory name] $ hadoop fs -mkdir books $ hadoop fs -ls
- 28. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Interacting with HDFS • Copy Data onto HDFS • After a directory has been created for the current user, data can be uploaded to the user’s HDFS home directory with the -put command: • For example, copy book file from local to HDFS • Use the -ls command to verify that pg20417.txt was moved to HDFS: 28 $ hadoop fs -put [source file] [destination file] $ hadoop fs -put pg20417.txt books/pg20417.txt $ hadoop fs -ls books
- 29. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Interacting with HDFS • Retrieve (view) Data from HDFS • Multiple commands allow data to be retrieved from HDFS. • To simply view the contents of a file, use the -cat command. -cat reads a file on HDFS and displays its contents to stdout. • The following command uses -cat to display the contents of pg20417.txt 29 $ hadoop fs -cat books/pg20417.txt
- 30. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Interacting with HDFS • Retrieve (view) Data from HDFS • Data can also be copied from HDFS to the local filesystem using the -get command. The -get command is the opposite of the -put command: • For example, This command copies pg20417.txt from HDFS to the local filesystem. 30 $ hadoop fs -get [source file] [destination file] $ hadoop fs -get pg20417.txt .
- 31. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Outline • Introduction • Hadoop Architecture • Hadoop Distributed File System (HDFS) • MapReduce • Hadoop Streaming • Hadoop with Python 31
- 32. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce • MapReduce is a programming model that enables large volumes of data to be processed and generated by dividing work into independent tasks and executing the tasks in parallel across a cluster of machines. • At a high level, every MapReduce program transforms a list of input data elements into a list of output data elements twice, once in the map phase and once in the reduce phase. • The MapReduce framework is composed of three major phases: map, shuffle and sort, and reduce. 32 Image source: "Data Analytics with Hadoop: An Introduction for Data Scientists", Benjamin Bengfort and Jenny Kim, 2016
- 33. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce • Map • The first phase of a MapReduce application is the map phase. Within the map phase, a function (called the mapper) processes a series of key-value pairs. • The mapper sequentially processes each key-value pair individually, producing zero or more output key- value pairs • As an example, consider a mapper whose purpose is to transform sentences into words. 33
- 34. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce • Map • The input to this mapper would be strings that contain sentences, and the mapper’s function would be to split the sentences into words and output the words 34 Image source: "Hadoop with Python", Zachary Radtka and Donald Miner, 2016
- 35. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce • Shuffle and Sort • As the mappers begin completing, the intermediate outputs from the map phase are moved to the reducers. This process of moving output from the mappers to the reducers is known as shuffling. • Shuffling is handled by a partition function, known as the partitioner. The partitioner ensures that all of the values for the same key are sent to the same reducer. • The intermediate keys and values for each partition are sorted by the Hadoop framework before being presented to the reducer. 35
- 36. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce • Reduce • Within the reducer phase, an iterator of values is provided to a function known as the reducer. The iterator of values is a nonunique set of values for each unique key from the output of the map phase. • The reducer aggregates the values for each unique key and produces zero or more output key-value pairs • As an example, consider a reducer whose purpose is to sum all of the values for a key. The input to this reducer is an iterator of all of the values for a key, and the reducer sums all of the values. 36
- 37. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce • Reduce • The reducer then outputs a key-value pair that contains the input key and the sum of the input key values 37 Image source: "Hadoop with Python", Zachary Radtka and Donald Miner, 2016
- 38. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce • Data flow of a MapReduce job being executed on a cluster of a few nodes 38 Image source: "Data Analytics with Hadoop: An Introduction for Data Scientists", Benjamin Bengfort and Jenny Kim, 2016
- 39. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples • In order to demonstrate how data flows through a map and reduce computational pipeline, we will present 3 examples • word counting • IoT data • shared friendship 39
- 40. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • The word-counting application takes as input one or more text files and produces a list of word and their frequencies as output. 40 Image source: "Data Analytics with Hadoop: An Introduction for Data Scientists", Benjamin Bengfort and Jenny Kim, 2016
- 41. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Because Hadoop utilizes key/value pairs the input key is a file ID and line number and the input value is a string, while the output key is a word and the output value is an integer. • The following Python pseudocode shows how this algorithm is implemented: 41 # emit is a function that performs hadoop I/O def map(dockey, line): for word in value.split(): emit(word, 1) def reduce(word, values): count = sum(value for value in values) emit(word,count)
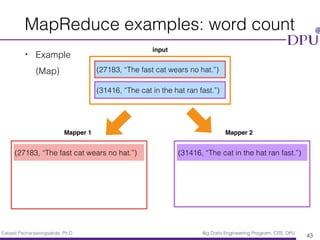
- 42. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU • Example (Map) MapReduce examples: word count 42 (27183, “The fast cat wears no hat.”) (31416, “The cat in the hat ran fast.”) input Mapper 1 Mapper 2
- 43. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU • Example (Map) MapReduce examples: word count 43 (27183, “The fast cat wears no hat.”) (31416, “The cat in the hat ran fast.”) input Mapper 1 Mapper 2 (27183, “The fast cat wears no hat.”) (31416, “The cat in the hat ran fast.”)
- 44. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU • Example (Map) MapReduce examples: word count 44 (“The”,1) (“The”,1) input Mapper 1 Mapper 2 (27183, “The fast cat wears no hat.”) (31416, “The cat in the hat ran fast.”)
- 45. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU • Example (Map) MapReduce examples: word count 45 (27183, “The fast cat wears no hat.”) (31416, “The cat in the hat ran fast.”) (“The”,1) (“The”,1)(“fast”,1) (“cat”,1) input Mapper 1 Mapper 2
- 46. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU • Example (Map) MapReduce examples: word count 46 (27183, “The fast cat wears no hat.”) (31416, “The cat in the hat ran fast.”) (“The”,1) (“The”,1)(“fast”,1) (“cat”,1)(“cat”,1) (“in”,1) input Mapper 1 Mapper 2
- 47. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU • Example (Map) MapReduce examples: word count 47 (27183, “The fast cat wears no hat.”) (31416, “The cat in the hat ran fast.”) (“The”,1) (“The”,1)(“fast”,1) (“cat”,1)(“cat”,1) (“in”,1) (“wears”,1) (“the”,1) input Mapper 1 Mapper 2
- 48. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU • Example (Map) MapReduce examples: word count 48 (27183, “The fast cat wears no hat.”) (31416, “The cat in the hat ran fast.”) (“The”,1) (“The”,1)(“fast”,1) (“cat”,1)(“cat”,1) (“in”,1) (“wears”,1) (“the”,1)(“no”,1) (“hat”,1) input Mapper 1 Mapper 2
- 49. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU • Example (Map) MapReduce examples: word count 49 (27183, “The fast cat wears no hat.”) (31416, “The cat in the hat ran fast.”) (“The”,1) (“The”,1)(“fast”,1) (“cat”,1)(“cat”,1) (“in”,1) (“wears”,1) (“the”,1)(“no”,1) (“hat”,1)(“hat”,1) (“ran”,1) input Mapper 1 Mapper 2
- 50. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU • Example (Map) MapReduce examples: word count 50 (27183, “The fast cat wears no hat.”) (31416, “The cat in the hat ran fast.”) (“The”,1) (“The”,1)(“fast”,1) (“cat”,1)(“cat”,1) (“in”,1) (“wears”,1) (“the”,1)(“no”,1) (“hat”,1)(“hat”,1) (“.”,1) (“ran”,1) (“fast”,1) input Mapper 1 Mapper 2
- 51. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU • Example (Map) MapReduce examples: word count 51 (27183, “The fast cat wears no hat.”) (31416, “The cat in the hat ran fast.”) (“The”,1) (“The”,1)(“fast”,1) (“cat”,1)(“cat”,1) (“in”,1) (“wears”,1) (“the”,1)(“no”,1) (“hat”,1)(“hat”,1) (“.”,1) (“ran”,1) (“fast”,1) (“.”,1) input Mapper 1 Mapper 2
- 52. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU • Example (Shuffle & Sort) MapReduce examples: word count 52 (“The”,1) (“The”,1)(“fast”,1) (“cat”,1)(“cat”,1) (“in”,1) (“wears”,1) (“the”,1)(“no”,1) (“hat”,1)(“hat”,1) (“.”,1) (“ran”,1) (“fast”,1) (“.”,1) (“.”,1) (“.”,1) Mapper 1 Mapper 2 Shuffle & Sort
- 53. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Example (Shuffle & Sort) 53 (“The”,1) (“The”,1)(“fast”,1) (“cat”,1)(“cat”,1) (“in”,1) (“wears”,1) (“the”,1)(“no”,1) (“hat”,1)(“hat”,1) (“.”,1) (“ran”,1) (“fast”,1) (“.”,1) (“.”,1) (“.”,1) (“cat”,1) (“cat”,1) Mapper 1 Mapper 2 Shuffle & Sort
- 54. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Example (Shuffle & Sort) 54 (“The”,1) (“The”,1)(“fast”,1) (“cat”,1)(“cat”,1) (“in”,1) (“wears”,1) (“the”,1)(“no”,1) (“hat”,1)(“hat”,1) (“.”,1) (“ran”,1) (“fast”,1) (“.”,1) (“.”,1) (“.”,1) (“cat”,1) (“cat”,1) (“fast”,1) (“fast”,1) Mapper 1 Mapper 2 Shuffle & Sort
- 55. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Example (Shuffle & Sort) 55 (“The”,1) (“The”,1)(“fast”,1) (“cat”,1)(“cat”,1) (“in”,1) (“wears”,1) (“the”,1)(“no”,1) (“hat”,1)(“hat”,1) (“.”,1) (“ran”,1) (“fast”,1) (“.”,1) (“.”,1) (“.”,1) (“cat”,1) (“cat”,1) (“fast”,1) (“fast”,1) (“hat”,1) (“hat”,1) Mapper 1 Mapper 2 Shuffle & Sort
- 56. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Example (Shuffle & Sort) 56 (“The”,1) (“The”,1)(“fast”,1) (“cat”,1)(“cat”,1) (“in”,1) (“wears”,1) (“the”,1)(“no”,1) (“hat”,1)(“hat”,1) (“.”,1) (“ran”,1) (“fast”,1) (“.”,1) (“.”,1) (“.”,1) (“cat”,1) (“cat”,1) (“fast”,1) (“fast”,1) (“hat”,1) (“hat”,1) (“in”,1) Mapper 1 Mapper 2 Shuffle & Sort
- 57. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Example (Shuffle & Sort) 57 (“The”,1) (“The”,1)(“fast”,1) (“cat”,1)(“cat”,1) (“in”,1) (“wears”,1) (“the”,1)(“no”,1) (“hat”,1)(“hat”,1) (“.”,1) (“ran”,1) (“fast”,1) (“.”,1) (“.”,1) (“.”,1) (“cat”,1) (“cat”,1) (“fast”,1) (“fast”,1) (“hat”,1) (“hat”,1) (“in”,1) (“no”,1) Mapper 1 Mapper 2 Shuffle & Sort
- 58. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Example (Shuffle & Sort) 58 (“The”,1) (“The”,1)(“fast”,1) (“cat”,1)(“cat”,1) (“in”,1) (“wears”,1) (“the”,1)(“no”,1) (“hat”,1)(“hat”,1) (“.”,1) (“ran”,1) (“fast”,1) (“.”,1) (“.”,1) (“.”,1) (“cat”,1) (“cat”,1) (“fast”,1) (“fast”,1) (“hat”,1) (“hat”,1) (“in”,1) (“no”,1) (“ran”,1) Mapper 1 Mapper 2 Shuffle & Sort
- 59. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Example (Shuffle & Sort) 59 (“The”,1) (“The”,1)(“fast”,1) (“cat”,1)(“cat”,1) (“in”,1) (“wears”,1) (“the”,1)(“no”,1) (“hat”,1)(“hat”,1) (“.”,1) (“ran”,1) (“fast”,1) (“.”,1) (“.”,1) (“.”,1) (“cat”,1) (“cat”,1) (“fast”,1) (“fast”,1) (“hat”,1) (“hat”,1) (“in”,1) (“no”,1) (“ran”,1) (“the”,1) Mapper 1 Mapper 2 Shuffle & Sort
- 60. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Example (Shuffle & Sort) 60 (“The”,1) (“The”,1)(“fast”,1) (“cat”,1)(“cat”,1) (“in”,1) (“wears”,1) (“the”,1)(“no”,1) (“hat”,1)(“hat”,1) (“.”,1) (“ran”,1) (“fast”,1) (“.”,1) (“.”,1) (“.”,1) (“cat”,1) (“cat”,1) (“fast”,1) (“fast”,1) (“hat”,1) (“hat”,1) (“in”,1) (“no”,1) (“ran”,1) (“the”,1) (“wears”,1) Mapper 1 Mapper 2 Shuffle & Sort
- 61. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Example (Shuffle & Sort) 61 Mapper 1 (“The”,1) (“The”,1)(“fast”,1) (“cat”,1)(“cat”,1) (“in”,1) (“wears”,1) (“the”,1)(“no”,1) (“hat”,1)(“hat”,1) (“.”,1) (“ran”,1) (“fast”,1) (“.”,1) (“.”,1) (“.”,1) (“cat”,1) (“cat”,1) (“fast”,1) (“fast”,1) (“hat”,1) (“hat”,1) (“in”,1) (“no”,1) (“ran”,1) (“the”,1) (“wears”,1) (“The”,1) (“The”,1) Mapper 2 Shuffle & Sort
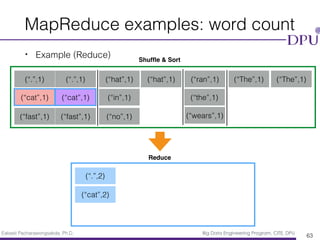
- 62. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Example (Reduce) 62 (“.”,1) (“.”,1) (“cat”,1) (“cat”,1) (“fast”,1) (“fast”,1) (“hat”,1) (“hat”,1) (“in”,1) (“no”,1) (“ran”,1) (“the”,1) (“wears”,1) (“The”,1) (“The”,1) Shuffle & Sort Reduce (“.”,2)
- 63. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Example (Reduce) 63 (“.”,1) (“.”,1) (“cat”,1) (“cat”,1) (“fast”,1) (“fast”,1) (“hat”,1) (“hat”,1) (“in”,1) (“no”,1) (“ran”,1) (“the”,1) (“wears”,1) (“The”,1) (“The”,1) Shuffle & Sort Reduce (“.”,2) (“cat”,2)
- 64. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Example (Reduce) 64 (“.”,1) (“.”,1) (“cat”,1) (“cat”,1) (“fast”,1) (“fast”,1) (“hat”,1) (“hat”,1) (“in”,1) (“no”,1) (“ran”,1) (“the”,1) (“wears”,1) (“The”,1) (“The”,1) Shuffle & Sort Reduce (“.”,2) (“cat”,2) (“fast”,2)
- 65. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Example (Reduce) 65 (“.”,1) (“.”,1) (“cat”,1) (“cat”,1) (“fast”,1) (“fast”,1) (“hat”,1) (“hat”,1) (“in”,1) (“no”,1) (“ran”,1) (“the”,1) (“wears”,1) (“The”,1) (“The”,1) Shuffle & Sort Reduce (“.”,2) (“cat”,2) (“fast”,2) (“hat”,2)
- 66. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Example (Reduce) 66 (“.”,1) (“.”,1) (“cat”,1) (“cat”,1) (“fast”,1) (“fast”,1) (“hat”,1) (“hat”,1) (“in”,1) (“no”,1) (“ran”,1) (“the”,1) (“wears”,1) (“The”,1) (“The”,1) Shuffle & Sort Reduce (“.”,2) (“cat”,2) (“fast”,2) (“hat”,2) (“in”,1)
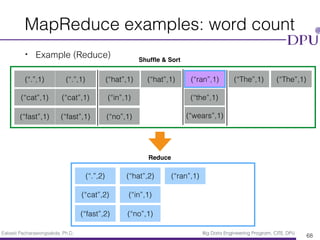
- 67. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Example (Reduce) 67 (“.”,1) (“.”,1) (“cat”,1) (“cat”,1) (“fast”,1) (“fast”,1) (“hat”,1) (“hat”,1) (“in”,1) (“no”,1) (“ran”,1) (“the”,1) (“wears”,1) (“The”,1) (“The”,1) Shuffle & Sort Reduce (“.”,2) (“cat”,2) (“fast”,2) (“hat”,2) (“in”,1) (“no”,1)
- 68. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Example (Reduce) 68 (“.”,1) (“.”,1) (“cat”,1) (“cat”,1) (“fast”,1) (“fast”,1) (“hat”,1) (“hat”,1) (“in”,1) (“no”,1) (“ran”,1) (“the”,1) (“wears”,1) (“The”,1) (“The”,1) Shuffle & Sort Reduce (“.”,2) (“cat”,2) (“fast”,2) (“hat”,2) (“in”,1) (“no”,1) (“ran”,1)
- 69. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Example (Reduce) 69 (“.”,1) (“.”,1) (“cat”,1) (“cat”,1) (“fast”,1) (“fast”,1) (“hat”,1) (“hat”,1) (“in”,1) (“no”,1) (“ran”,1) (“the”,1) (“wears”,1) (“The”,1) (“The”,1) Shuffle & Sort Reduce (“.”,2) (“cat”,2) (“fast”,2) (“hat”,2) (“in”,1) (“no”,1) (“ran”,1) (“the”,1)
- 70. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Example (Reduce) 70 (“.”,1) (“.”,1) (“cat”,1) (“cat”,1) (“fast”,1) (“fast”,1) (“hat”,1) (“hat”,1) (“in”,1) (“no”,1) (“ran”,1) (“the”,1) (“wears”,1) (“The”,1) (“The”,1) Shuffle & Sort Reduce (“.”,2) (“cat”,2) (“fast”,2) (“hat”,2) (“in”,1) (“no”,1) (“ran”,1) (“the”,1) (“wears”,1)
- 71. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: word count • Example (Reduce) 71 (“.”,1) (“.”,1) (“cat”,1) (“cat”,1) (“fast”,1) (“fast”,1) (“hat”,1) (“hat”,1) (“in”,1) (“no”,1) (“ran”,1) (“the”,1) (“wears”,1) (“The”,1) (“The”,1) Shuffle & Sort Reduce (“.”,2) (“cat”,2) (“fast”,2) (“hat”,2) (“in”,1) (“no”,1) (“ran”,1) (“the”,1) (“wears”,1) (“The”,2)
- 72. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples • In order to demonstrate how data flows through a map and reduce computational pipeline, we will present 3 examples • word counting • IoT data • shared friendship 72
- 73. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: IoT • IoT applications create an enormous amount of data that has to be processed. This data is generated by physical sensors who take measurements, like room temperature at 8.00 o’Clock. • Every measurement consists of • a key (the timestamp when the measurement has been taken) and • a value (the actual value measured by the sensor). • for example, (2016-05-01 01:02:03, 1). • The goal of this exercise is to create average daily values of that sensor’s data. 73
- 74. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU • Example(Map) MapReduce examples: IoT 74 input Mapper 1 Mapper 2 Mapper 3 (“2016-05-01 01:02:03”,1) (“2016-05-02 12:09:04”,2) (“2016-05-03 09:21:07”,3) (“2016-05-03 09:21:45”,4) (“2016-05-01 01:02:04”,5) (“2016-05-02 12:09:01”,6) (“2016-05-02 12:09:30”,7) (“2016-05-03 09:21:31”,8) (“2016-05-01 01:02:05”,9)
- 75. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU • Example(Map) MapReduce examples: IoT 75 input Mapper 1 Mapper 2 Mapper 3 (“2016-05-01 01:02:03”,1) (“2016-05-02 12:09:04”,2) (“2016-05-03 09:21:07”,3) (“2016-05-03 09:21:45”,4) (“2016-05-01 01:02:04”,5) (“2016-05-02 12:09:01”,6) (“2016-05-02 12:09:30”,7) (“2016-05-03 09:21:31”,8) (“2016-05-01 01:02:05”,9) (“2016-05-01 01:02:03”,1) (“2016-05-02 12:09:04”,2) (“2016-05-03 09:21:07”,3) (“2016-05-03 09:21:45”,4) (“2016-05-01 01:02:04”,5) (“2016-05-02 12:09:01”,6) (“2016-05-02 12:09:30”,7) (“2016-05-03 09:21:31”,8) (“2016-05-01 01:02:05”,9)
- 76. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU • Example(Map) MapReduce examples: IoT 76 input Mapper 1 Mapper 2 Mapper 3 (“2016-05-01 01:02:03”,1) (“2016-05-02 12:09:04”,2) (“2016-05-03 09:21:07”,3) (“2016-05-03 09:21:45”,4) (“2016-05-01 01:02:04”,5) (“2016-05-02 12:09:01”,6) (“2016-05-02 12:09:30”,7) (“2016-05-03 09:21:31”,8) (“2016-05-01 01:02:05”,9) (“2016-05-01”,1) (“2016-05-02”,2) (“2016-05-03”,3) (“2016-05-03”,4) (“2016-05-01”,5) (“2016-05-02”,6) (“2016-05-02”,7) (“2016-05-03”,8) (“2016-05-01”,9)
- 77. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: IoT • Example(Shuffle & Sort) 77 Mapper 1 Mapper 2 Mapper 3 (“2016-05-01”,1) (“2016-05-02”,2) (“2016-05-03”,3) (“2016-05-03”,4) (“2016-05-01”,5) (“2016-05-02”,6) (“2016-05-02”,7) (“2016-05-03”,8) (“2016-05-01”,9) (“2016-05-01”,1) (“2016-05-01”,5) (“2016-05-01”,9) Shuffle & Sort
- 78. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: IoT • Example(Shuffle & Sort) 78 Mapper 1 Mapper 2 Mapper 3 (“2016-05-01”,1) (“2016-05-02”,2) (“2016-05-03”,3) (“2016-05-03”,4) (“2016-05-01”,5) (“2016-05-02”,6) (“2016-05-02”,7) (“2016-05-03”,8) (“2016-05-01”,9) (“2016-05-01”,1) (“2016-05-01”,5) (“2016-05-01”,9) (“2016-05-02”,2) (“2016-05-02”,6) (“2016-05-02”,7) Shuffle & Sort
- 79. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: IoT • Example(Shuffle & Sort) 79 Mapper 1 Mapper 2 Mapper 3 (“2016-05-01”,1) (“2016-05-02”,2) (“2016-05-03”,3) (“2016-05-03”,4) (“2016-05-01”,5) (“2016-05-02”,6) (“2016-05-02”,7) (“2016-05-03”,8) (“2016-05-01”,9) (“2016-05-01”,1) (“2016-05-01”,5) (“2016-05-01”,9) (“2016-05-02”,2) (“2016-05-02”,6) (“2016-05-02”,7) (“2016-05-03”,3) (“2016-05-03”,4) (“2016-05-03”,8) Shuffle & Sort
- 80. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: IoT • Example(Reduce) 80 (“2016-05-01”,1) (“2016-05-01”,5) (“2016-05-01”,9) (“2016-05-02”,2) (“2016-05-02”,6) (“2016-05-02”,7) (“2016-05-03”,3) (“2016-05-03”,4) (“2016-05-03”,8) Shuffle & Sort (“2016-05-01”,5)value = (1+5+9)/3 Reduce
- 81. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: IoT • Example(Reduce) 81 (“2016-05-01”,1) (“2016-05-01”,5) (“2016-05-01”,9) (“2016-05-02”,2) (“2016-05-02”,6) (“2016-05-02”,7) (“2016-05-03”,3) (“2016-05-03”,4) (“2016-05-03”,8) Shuffle & Sort Reduce (“2016-05-01”,5) value = (2+6+7)/3 (“2016-05-02”,5)
- 82. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: IoT • Example(Reduce) 82 (“2016-05-01”,1) (“2016-05-01”,5) (“2016-05-01”,9) (“2016-05-02”,2) (“2016-05-02”,6) (“2016-05-02”,7) (“2016-05-03”,3) (“2016-05-03”,4) (“2016-05-03”,8) Shuffle & Sort (“2016-05-01”,5) value = (3+4+8)/3 (“2016-05-02”,5) (“2016-05-03”,5) Reduce
- 83. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples • In order to demonstrate how data flows through a map and reduce computational pipeline, we will present 3 examples • word counting • IoT data • shared friendship 83
- 84. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: shared friendship • In the shared friendship task, the goal is to analyze a social network to see which friend relationships users have in common. • Given an input data source where the key is the name of a user and the value is a comma-separated list of friends. 84
- 85. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: shared friendship • The following Python pseudocode demonstrates how to perform this computation: 85 def map(person, friends): for friend in friends.split(“,”): pair = sort([person, friend]) emit(pair,friends) def reduce(pair, friends): shared = set(friend[0]) shared = shared.intersection(friends[1]) emit(pair,shared)
- 86. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: shared friendship • The mapper create an intermediate keycap of all of the possible (friend, friend) tuples that exist from the initial dataset. • This allows us to analyze the dataset on a per-relationship basis as the value is the list of associated friends. • The pair is sorted, which ensures that the input (“Mike”,“Linda”) and (“Linda”,“Mike”) end up being the same key during aggregation in the reducer. 86
- 87. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU • Example(Map) MapReduce examples: shared friendship 87 input (“Allen”,”Betty, Chris, David”) (“Betty”,”Allen, Chris, David, Ellen”) (“Chris”,”Allen, Betty, David,Ellen”) (“David”,”Allen, Betty, Chris, Ellen”) (“Ellen”,”Betty, Chris, David”)
- 88. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU • Example(Map) MapReduce examples: shared friendship 88 input Mapper 1 Mapper 2 (“Allen”,”Betty, Chris, David”) (“Betty”,”Allen, Chris, David, Ellen”) (“Chris”,”Allen, Betty, David,Ellen”) (“David”,”Allen, Betty, Chris, Ellen”) (“Ellen”,”Betty, Chris, David”) (“Allen, Betty”,”Betty, Chris, David”) (“Allen, Chris”,”Betty, Chris, David”) (“Allen, David”,”Betty, Chris, David”) (“Betty, Ellen”,”Betty, Chris, David”) (“Chris, Ellen”,”Betty, Chris, David”) (“David, Ellen”,”Betty, Chris, David”)
- 89. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU • Example(Map) MapReduce examples: shared friendship 89 input Mapper 3 Mapper 4 (“Allen”,”Betty, Chris, David”) (“Betty”,”Allen, Chris, David, Ellen”) (“Chris”,”Allen, Betty, David,Ellen”) (“David”,”Allen, Betty, Chris, Ellen”) (“Ellen”,”Betty, Chris, David”) (“Allen, Betty”,”Allen, Chris, David, Ellen”) (“Betty, Chris”,”Allen, Chris, David, Ellen”) (“Betty, David”,”Allen, Chris, David, Ellen”) (“Betty, Ellen”,”Allen, Chris, David, Ellen”) (“Allen, Chris”,”Allen, Betty, David,Ellen”) (“Betty, Chris”,”Allen, Betty, David,Ellen”) (“Chris, David”,”Allen, Betty, David,Ellen”) (“Chris, Ellen”,”Allen, Betty, David,Ellen”)
- 90. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU • Example(Map) MapReduce examples: shared friendship 90 input Mapper 5 (“Allen”,”Betty, Chris, David”) (“Betty”,”Allen, Chris, David, Ellen”) (“Chris”,”Allen, Betty, David,Ellen”) (“David”,”Allen, Betty, Chris, Ellen”) (“Ellen”,”Betty, Chris, David”) (“Allen, David”,”Allen, Betty, Chris, Ellen”) (“Betty, David”,”Allen, Betty, Chris, Ellen”) (“Chris, David”,”Allen, Betty, Chris, Ellen”) (“David, Ellen”,”Allen, Betty, Chris, Ellen”)
- 91. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: shared friendship • Example (Shuffle & Sort) 91 Shuffle & Sort (“Allen, Betty”,”Betty, Chris, David”)(“Allen, Betty”,”Allen, Chris, David, Ellen”) (“Allen, Chris”,”Allen, Betty, David,Ellen”) (“Allen, Chris”,”Betty, Chris, David”) (“Allen, David”,”Allen, Betty, Chris, Ellen”) (“Allen, David”,”Betty, Chris, David”) (“Betty, Chris”,”Allen, Betty, David,Ellen”) (“Betty, Chris”,”Allen, Chris, David, Ellen”) (“Betty, David”,”Allen, Chris, David, Ellen”)(“Betty, David”,”Allen, Betty, Chris, Ellen”) (“Betty, Ellen”,”Allen, Chris, David, Ellen”) (“Betty, Ellen”,”Betty, Chris, David”) (“Chris, David”,”Allen, Betty, David,Ellen”)(“Chris, David”,”Allen, Betty, Chris, Ellen”) (“Chris, Ellen”,”Betty, Chris, David”)(“Chris, Ellen”,”Allen, Betty, David,Ellen”) (“David, Ellen”,”Allen, Betty, Chris, Ellen”) (“David, Ellen”,”Betty, Chris, David”)
- 92. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: shared friendship • Example (Shuffle & Sort) 92 Shuffle & Sort (“Allen, Betty”,”Betty, Chris, David”)(“Allen, Betty”,”Allen, Chris, David, Ellen”) (“Allen, Chris”,”Allen, Betty, David,Ellen”) (“Allen, Chris”,”Betty, Chris, David”) (“Allen, David”,”Allen, Betty, Chris, Ellen”) (“Allen, David”,”Betty, Chris, David”) (“Betty, Chris”,”Allen, Betty, David, Ellen”) (“Betty, Chris”,”Allen, Chris, David, Ellen”) (“Betty, David”,”Allen, Chris, David, Ellen”)(“Betty, David”,”Allen, Betty, Chris, Ellen”) (“Betty, Ellen”,”Allen, Chris, David, Ellen”) (“Betty, Ellen”,”Betty, Chris, David”) (“Chris, David”,”Allen, Betty, David,Ellen”)(“Chris, David”,”Allen, Betty, Chris, Ellen”) (“Chris, Ellen”,”Betty, Chris, David”)(“Chris, Ellen”,”Allen, Betty, David,Ellen”) (“David, Ellen”,”Allen, Betty, Chris, Ellen”) (“David, Ellen”,”Betty, Chris, David”)
- 93. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU MapReduce examples: shared friendship • Example (Reduce) 93 (“Allen, Betty”, “Chris, David”) (“Allen, Chris”, “Betty, David”) (“Allen, David”, “Betty, Chris”) (“Betty, Chris”, “Allen, David, Ellen”) (“Betty, David”, “Allen, Chris, Ellen”) (“Betty, Ellen”, “Chris, David”) (“Chris, David”, “Allen, Betty, Ellen”) (“Chris, Ellen”, “Betty, David”) (“David, Ellen”, “Betty, Chris”)
- 94. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Outline • Introduction • Hadoop Architecture • Hadoop Distributed File System (HDFS) • MapReduce • Hadoop with Python • Hadoop streaming • Python MapReduce library (mrjob) 94
- 95. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop Streaming • Hadoop streaming is a utility that comes packaged with the Hadoop distribution and allows MapReduce jobs to be created with any executable as the mapper and/or the reducer. • The Hadoop streaming utility enables Python, shell scripts, or any other language to be used as a mapper, reducer, or both. • The mapper and reducer are both executables that • read input, line by line, from the standard input (stdin), • and write output to the standard output (stdout). • The Hadoop streaming utility creates a MapReduce job, submits the job to the cluster, and monitors its progress until it is complete. 95
- 96. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop Streaming • When the mapper is initialized, each map task launches the specified executable as a separate process. • The mapper reads the input file and presents each line to the executable via stdin. After the executable processes each line of input, the mapper collects the output from stdout and converts each line to a key-value pair. • The key consists of the part of the line before the first tab character, and the value consists of the part of the line after the first tab character. 96
- 97. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop Streaming • When the reducer is initialized, each reduce task launches the specified executable as a separate process. • The reducer converts the input key-value pair to lines that are presented to the executable via stdin. • The reducer collects the executables result from stdout and converts each line to a key-value pair. • Similar to the mapper, the executable specifies key-value pairs by separating the key and value by a tab character. 97
- 98. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop Streaming • Data flow in Hadoop Streaming via Python mapper.py and reducer.py scripts 98 Image source: "Data Analytics with Hadoop: An Introduction for Data Scientists", Benjamin Bengfort and Jenny Kim, 2016
- 99. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop Streaming example • The WordCount application can be implemented as two Python programs: mapper.py and reducer.py. • mapper.py is the Python program that implements the logic in the map phase of WordCount. • It reads data from stdin, splits the lines into words, and outputs each word with its intermediate count to stdout. 99
- 100. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop Streaming example • mapper.py 100 #!/usr/bin/env python import sys # input comes from STDIN (standard input) for line in sys.stdin: # remove leading and trailing whitespace line = line.strip() # split the line into words words = line.split() # increase counters for word in words: # write the results to STDOUT (standard output); # what we output here will be the input for the # Reduce step, i.e. the input for reducer.py # # tab-delimited; the trivial word count is 1 print '%st%s' % (word, 1)
- 101. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop Streaming example • reducer.py is the Python program that implements the logic in the reduce phase of WordCount. • It reads the results of mapper.py from stdin, sums the occurrences of each word, and writes the result to stdout. • reducer.py 101 #!/usr/bin/env python from operator import itemgetter import sys current_word = None current_count = 0 word = None
- 102. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop Streaming example • reducer.py (cont’) 102 # input comes from STDIN for line in sys.stdin: # remove leading and trailing whitespace line = line.strip() # parse the input we got from mapper.py word, count = line.split('t', 1) # convert count (currently a string) to int try: count = int(count) except ValueError: # count was not a number, so silently # ignore/discard this line continue
- 103. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop Streaming example • reducer.py (cont’) 103 # this IF-switch only works because Hadoop sorts map output # by key (here: word) before it is passed to the reducer if current_word == word: current_count += count else: if current_word: # write result to STDOUT print '%st%s' % (current_word, current_count) current_count = count current_word = word # do not forget to output the last word if needed! if current_word == word: print '%st%s' % (current_word, current_count)
- 104. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop Streaming example • Before attempting to execute the code, ensure that the mapper.py and reducer.py files have execution permission. • The following command will enable this for both files: • Also ensure that the first line of each file contains the proper path to Python. This line enables mapper.py and reducer.py to execute as standalone executables. • It is highly recommended to test all programs locally before running them across a Hadoop cluster. 104 $ chmod +x mapper.py reducer.py $ echo ‘The fast cat wears no hat’ | ./mapper.py | sort -t 1| ./reducer.py
- 105. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop Streaming example • Download 3 ebooks from Project Gutenberg • The Outline of Science, Vol. 1 (of 4) by J. Arthur Thomson (659 KB) • The Notebooks of Leonardo Da Vinci (1.4 MB) • Ulysses by James Joyce (1.5 MB) • Before we run the actual MapReduce job, we must first copy the files from our local file system to Hadoop’s HDFS. 105 $ hadoop fs -put pg20417.txt books/pg20417.txt $ hadoop fs -put 5000-8.txt books/5000-8.txt $ hadoop fs -put 4300-0.txt books/4300-0.txt $ hadoop fs -ls books
- 106. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop Streaming example • The mapper and reducer programs can be run as a MapReduce application using the Hadoop streaming utility. • The command to run the Python programs mapper.py and reducer.py on a Hadoop cluster is as follows: 106 $ hadoop jar /usr/lib/hadoop-0.20-mapreduce/contrib/streaming/ hadoop-streaming-2.0.0-mr1-cdh*.jar -files mapper.py, reducer.py -mapper mapper.py -reducer reducer.py -input /user/hduser/books/* -output /user/hduser/books/output
- 107. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Hadoop Streaming example • Options for Hadoop streaming 107 Option Description -files A command-separated list of files to be copied to the MapReduce cluster -mapper The command to be run as the mapper -reducer The command to be run as the reducer -input The DFS input path for the Map step -output The DFS output directory for the Reduce step
- 108. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Outline • Introduction • Hadoop Architecture • Hadoop Distributed File System (HDFS) • MapReduce • Hadoop with Python • Hadoop streaming • Python MapReduce library (mrjob) 108
- 109. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Python MapReduce library: mrjob • mrjob is a Python MapReduce library, created by Yelp, that wraps Hadoop streaming, allowing MapReduce applications to be written in a more Pythonic manner. • mrjob enables multistep MapReduce jobs to be written in pure Python. • MapReduce jobs written with mrjob can be tested locally, run on a Hadoop cluster, or run in the cloud using Amazon Elastic MapReduce (EMR). 109
- 110. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU Python MapReduce library: mrjob • Installation • First, install python pip on CDH VM • The installation of mrjob is simple; it can be installed with pip by using the following command: 110 $ yum -y install python-pip $ pip install mrjob
- 111. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU mrjob example • word_count.py • To run the job locally and count the frequency of words within a file named pg20417.txt, use the following command: 111 from mrjob.job import MRJob class MRWordCount(MRJob): def mapper(self, _, line): for word in line.split(): yield(word, 1) def reducer(self, word, counts): yield(word, sum(counts)) if __name__ == '__main__': MRWordCount.run() $ python word_count.py books/pg20419.txt
- 112. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU mrjob example • The MapReduce job is defined as the class, MRWordCount. Within the mrjob library, the class that inherits from MRJob contains the methods that define the steps of the MapReduce job. • The steps within an mrjob application are mapper, combiner, and reducer. The class inheriting MRJob only needs to define one of these steps. • The mapper() method defines the mapper for the MapReduce job. It takes key and value as arguments and yields tuples of (output_key, output_value). • In the WordCount example, the mapper ignored the input key and split the input value to produce words and counts. 112
- 113. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU mrjob example • The combiner is a process that runs after the mapper and before the reducer. • It receives, as input, all of the data emitted by the mapper, and the output of the combiner is sent to the reducer. The combiner yields tuples of (output_key, output_value) as output. • The reducer() method defines the reducer for the MapReduce job. • It takes a key and an iterator of values as arguments and yields tuples of (output_key, output_value). • In example, the reducer sums the value for each key, which represents the frequency of words in the input. 113
- 114. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU mrjob example • The final component of a MapReduce job written with the mrjob library is the two lines at the end of the file: if __name__ == '__main__': MRWordCount.run() • These lines enable the execution of mrjob; without them, the application will not work. • Executing a MapReduce application with mrjob is similar to executing any other Python program. The command line must contain the name of the mrjob application and the input file: 114 $ python mr_job.py input.txt
- 115. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU mrjob example • By default, mrjob runs locally, allowing code to be developed and debugged before being submitted to a Hadoop cluster. • To change how the job is run, specify the -r/--runner option. 115 $ python word_count.py -r hadoop hdfs:books/pg20419.txt
- 116. Eakasit Pacharawongsakda, Ph.D. Big Data Engineering Program, CITE, DPU References • "Data Analytics with Hadoop: An Introduction for Data Scientists", Benjamin Bengfort and Jenny Kim, 2016 • "Hadoop with Python", Zachary Radtka and Donald Miner, 2016 • "Mining of Massive Datasets",Jure Leskovec, Anand Rajaraman and Jeff Ullman, 2014 • “Big Data Fundamentals: Concepts, Drivers & Techniques”, Thomas Erl, Wajid Khattak and Paul Buhler, 2016 • http://www.michael-noll.com/tutorials/writing-an-hadoop-mapreduce-program-in- python/ • http://iotdonequick.com/2016/06/24/mastering-big-data-with-distributed-processing/ • https://www.liquidweb.com/kb/how-to-install-pip-on-centos-7/ 116