Introduction to Kafka Cruise Control
Download as PPTX, PDF31 likes27,587 views

An introduction to Kafka cruise control which performs dynamic workload balancing for Kafka clusters.
























![Distributed Data Systems 26©2016 LinkedIn Corporation. All Rights Reserved.
REST API
./rebalance_cluster [balance_percentage]
./add_brokers <broker-info>
./decommission_brokers <broker-info>
./assignment_history [option]
./restore_assignment [option]
./cancel_all
./list_assignment [option]](https://image.slidesharecdn.com/35pe810r0or3khtslbje-signature-6ce679e537137b84f1dc277d23a356ff88d2b85bc01a14d311b2e4e3b4ec6955-poli-161104081506/85/Introduction-to-Kafka-Cruise-Control-26-320.jpg)



















































Ad
More Related Content
What's hot (20)
Similar to Introduction to Kafka Cruise Control (20)









![OOW16 - Getting Optimal Performance from Oracle E-Business Suite [CON6711]](https://cdn.slidesharecdn.com/ss_thumbnails/con6711-gettingoptimalperformancefromoraclee-businesssuite-160930182552-thumbnail.jpg?width=560&fit=bounds)








Ad
Recently uploaded (20)




















Ad
Introduction to Kafka Cruise Control
- 1. Distributed Data Systems 1©2016 LinkedIn Corporation. All Rights Reserved. Introduction to Kafka Cruise Control Jiangjie (Becket) Qin Efe Gencer
- 2. Distributed Data Systems 2©2016 LinkedIn Corporation. All Rights Reserved. Agenda ▪ The operation challenges for Kafka ▪ What is Kafka Cruise Control? ▪ Complexity of dynamic workload balancing ▪ Goals for workload balancing ▪ System design and architecture ▪ Q&A
- 3. Distributed Data Systems 3©2016 LinkedIn Corporation. All Rights Reserved. Agenda ▪ The operation challenges for Kafka ▪ What is Kafka Cruise Control? ▪ Complexity of dynamic workload balancing ▪ Goals for workload balancing ▪ System design and architecture ▪ Q&A
- 4. Distributed Data Systems 4©2016 LinkedIn Corporation. All Rights Reserved. The operation challenges for Kafka ▪ The scale of Kafka’s deployment @ LinkedIn – ~1,800 brokers – ~80,000 Topics – > 1.3 Trillion messages / day
- 5. Distributed Data Systems 5©2016 LinkedIn Corporation. All Rights Reserved. The operation challenges for Kafka ▪ Almost everyday – Broker dies – new topics creation – Partition reassignment to balance the workload ▪ Huge operation load
- 6. Distributed Data Systems 6©2016 LinkedIn Corporation. All Rights Reserved. Agenda ▪ The operation challenges for Kafka ▪ What is Kafka Cruise Control? ▪ Complexity of dynamic workload balancing ▪ Goals for workload balancing ▪ System design and architecture ▪ Q&A
- 7. Distributed Data Systems 7©2016 LinkedIn Corporation. All Rights Reserved. What is Kafka Cruise Control ▪ Dynamic workload balancing for resources – CPU – Disk Utilization – Network Inbound – Network Outbound ▪A predecessor (kafka-assigner) with only disk balancing –https://github.com/linkedin/kafka-tools
- 8. Distributed Data Systems 8©2016 LinkedIn Corporation. All Rights Reserved. What is Kafka Cruise Control ▪ Failure detection and self-healing – Reassign the replicas on the dead brokers – Reduce the window of under replication ▪ Add / decommission a broker
- 9. Distributed Data Systems 9©2016 LinkedIn Corporation. All Rights Reserved. Agenda ▪ The operation challenges for Kafka ▪ What is Kafka Cruise Control? ▪ Complexity of dynamic workload balancing ▪ Goals for workload balancing ▪ System design and architecture ▪ Q&A
- 10. Distributed Data Systems 10©2016 LinkedIn Corporation. All Rights Reserved. Complexity of Dynamic Workload Balancing ▪ Consider a Kafka cluster with – 2000 Topics – 16,000 partitions – 32,000 replicas (assume RF=2)
- 11. Distributed Data Systems 11©2016 LinkedIn Corporation. All Rights Reserved. Complexity of Dynamic Workload Balancing ▪ Each replica has various workload profile – CPU (Leader > Follower) – Disk utilization (Leader = Follower) – Network Inbound (Leader = Follower) – Network Outbound (Follower = 0) Leader Follower Decompression Re-compression (Optional) Append ConsumerProducer
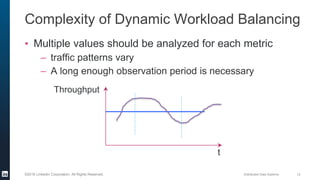
- 12. Distributed Data Systems 12©2016 LinkedIn Corporation. All Rights Reserved. Complexity of Dynamic Workload Balancing ▪ Multiple values should be analyzed for each metric – traffic patterns vary – A long enough observation period is necessary t Throughput
- 13. Distributed Data Systems 13©2016 LinkedIn Corporation. All Rights Reserved. ▪ Some more things to consider – Even distribution of all partitions among the brokers – Rack awareness – The load of each broker after one of the brokers failed Complexity of Dynamic Workload Balancing
- 14. Distributed Data Systems 14©2016 LinkedIn Corporation. All Rights Reserved. Complexity of Dynamic Workload Balancing ▪ Partition reassignment is tricky – Should not affect the normal traffic (KIP-73) – May need to be interrupted ▪ e.g. A failed broker recovered
- 15. Distributed Data Systems 15©2016 LinkedIn Corporation. All Rights Reserved. ▪ Large number of replicas ▪ Workload on multiple resources ▪ Additional restrictions ▪ Two ways to balance – Leadership movement (cheap) – Replica movement (expensive) Complexity of Dynamic Workload Balancing
- 16. Distributed Data Systems 16©2016 LinkedIn Corporation. All Rights Reserved. Agenda ▪ The operation challenges for Kafka ▪ What is Kafka Cruise Control? ▪ Complexity of dynamic workload balancing ▪ Goals for workload balancing ▪ System design and architecture ▪ Q&A
- 17. Distributed Data Systems 17©2016 LinkedIn Corporation. All Rights Reserved. Goals of workload balancing 1. Rack Awareness Goal (Hard Goal) – The replicas of the same partition has to be in different racks Rack0 p0r0 p1r1 Rack1 p0r1 p2r0 Rack2 p1r0 p2r1
- 18. Distributed Data Systems 18©2016 LinkedIn Corporation. All Rights Reserved. Goals of workload balancing 2. Resource Utilization Threshold Goal (Hard Goal) – The utilization of each resource on a broker has to be below a defined threshold
- 19. Distributed Data Systems 19©2016 LinkedIn Corporation. All Rights Reserved. Goals of workload balancing 3. Resource Utilization During Failure Goal (Soft Goal) – Utilization of each resource on a broker cannot exceed the broker’s capacity when there are broker failures.
- 20. Distributed Data Systems 20©2016 LinkedIn Corporation. All Rights Reserved. Goals of workload balancing 4. Resource Utilization Balance Goal (Soft Goal) – The utilization of each resource of a broker should not differ for more than X% of the average utilization.
- 21. Distributed Data Systems 21©2016 LinkedIn Corporation. All Rights Reserved. Goals of workload balancing 5. Topic Partition Distribution Goal (Soft Goal) – The partitions of each topic should be distributed among the brokers as evenly as possible Rack0 Rack1 Broker0 Broker1 Broker2 T0_P0_R1 T0_P1_R0 T0_P0_R0 Rack2 Broker3 T0_P1_R1
- 22. Distributed Data Systems 22©2016 LinkedIn Corporation. All Rights Reserved. Goals of workload balancing 6. Global Partition Distribution Goal (Soft Goal) – Partitions of all the topics in the Kafka cluster should be distributed among the brokers as evenly as possible Rack0 Rack1 Broker0 Broker1 Broker2 T0_P0_R1 T0_P1_R0 T0_P0_R0 Rack2 Broker3 T0_P1_R1 T1_P0_R0 T1_P1_R1 T1_P0_R1 T1_P1_R0
- 23. Distributed Data Systems 23©2016 LinkedIn Corporation. All Rights Reserved. Goals of workload balancing ▪ Each goal has a priority – Represented by a unique integer – Determines the satisfying order
- 24. Distributed Data Systems 24©2016 LinkedIn Corporation. All Rights Reserved. Agenda ▪ The operation challenges for Kafka ▪ What is Kafka Cruise Control? ▪ Complexity of dynamic workload balancing ▪ Goals for workload balancing ▪ System design and architecture ▪ Q&A
- 25. Distributed Data Systems 25©2016 LinkedIn Corporation. All Rights Reserved. Kafka Cruise Control Architecture of Kafka Cruise Control Workload Monitor Executor Kafka Cluster Failure Detector User Analyzer Metric Sampler REST API Goal0 Goal1 …
- 26. Distributed Data Systems 26©2016 LinkedIn Corporation. All Rights Reserved. REST API ./rebalance_cluster [balance_percentage] ./add_brokers <broker-info> ./decommission_brokers <broker-info> ./assignment_history [option] ./restore_assignment [option] ./cancel_all ./list_assignment [option]
- 27. Distributed Data Systems 27©2016 LinkedIn Corporation. All Rights Reserved. Many Interesting Challenges ▪ Trustworthy Workload Modeling (Workload Monitor) ▪ Fast Optimization Resolution (Analyzer) ▪ False Alarm in Failure (Failure Detector) ▪ Controlled Balancing Execution (Executor) ▪ And so on…
- 28. Distributed Data Systems 28©2016 LinkedIn Corporation. All Rights Reserved. Trustworthy Workload Modeling ▪ Garbage in, garbage out ▪ A good workload model is critical – Robust workload sampling ▪ Workload sampling may fail intermittently – Only take action when we are confident
- 29. Distributed Data Systems 29©2016 LinkedIn Corporation. All Rights Reserved. Robust Workload Sampling ▪ Replica workload model (Workload Sample) – CPU Utilization: Derived from total CPU usage ▪(Partition_Bytes_In / Total_Bytes_In) * CPU_UTIL – Disk Utilization: Partition size (latest size) – Network Inbound: Kafka metrics – Network Outbound: Kafka metrics ▪ Followers’ loads are derived from leaders’ loads
- 30. Distributed Data Systems 30©2016 LinkedIn Corporation. All Rights Reserved. Robust Workload Sampling ▪ Workload Monitor – Periodically sample the Kafka cluster ▪ E.g. Every 5 min. ▪ Many metrics if the cluster is big –Multiple customizable metric samplers ▪Parallel metric sampling – Each Workload Sample is for one partition
- 31. Distributed Data Systems 31©2016 LinkedIn Corporation. All Rights Reserved. ▪ Workload Snapshot – Represents the average workload in a defined window – Keep most recent N snapshots for each partition – Multiple workload samples in each workload snapshot – Insufficient samples leads to invalid Workload Snapshots ▪ E.g. 4 samples per snapshot window, at least 3 samples required Only take confident action Snapshot 0 Snapshot 1 Snapshot 2 S0 S1 S2 S3 S0 S1 S2 S3 S0 S1 S2 S3
- 32. Distributed Data Systems 32©2016 LinkedIn Corporation. All Rights Reserved. Only take confident action ▪ Never take action when we are not confident – Exclude a partition without enough valid snapshots – Exclude a topic if one of its partitions is excluded – Stop the analysis if too many topics are excluded ▪ E.g. < 98% topics are included
- 33. Distributed Data Systems 33©2016 LinkedIn Corporation. All Rights Reserved. Many Interesting Challenges ▪ Trustworthy Workload Modeling (Workload Monitor) ▪ Fast Optimization Resolution (Analyzer) ▪ False Alarm in Failure (Failure Detector) ▪ Controlled Balancing Execution (Executor) ▪ And so on…
- 34. Distributed Data Systems 34©2016 LinkedIn Corporation. All Rights Reserved. Fast Optimization Resolution ▪ A reminder: dynamic workload balancing is not easy – Tens of thousands of replicas – Multiple resources (CPU, DISK, Network) – 6 Goals ▪ We need to get a solution quickly – Otherwise the workload model may be outdated
- 35. Distributed Data Systems 35©2016 LinkedIn Corporation. All Rights Reserved. An attempt of using Microsoft Z3 ▪ Microsoft z3 – An open source theorem prover (optimizer) ▪ https://github.com/Z3Prover/z3 – Optimization by minimize a set of cost functions ▪ In our case it is a bunch of first order formula.
- 36. Distributed Data Systems 36©2016 LinkedIn Corporation. All Rights Reserved. An attempt of using Microsoft Z3 ▪ Microsoft z3 – An open source theorem prover (optimizer) ▪ https://github.com/Z3Prover/z3 – Optimization by minimize a set of cost functions ▪ In our case it is a bunch of first order formula. ▪ It takes a couple of weeks to get a solution assuming everything goes perfectly well
- 37. Distributed Data Systems 37©2016 LinkedIn Corporation. All Rights Reserved. Heuristic Analyzer ▪ Simple procedure Move a partition to other brokers Get an unchecked broker Y Y Have unchecked broker? Can move a partition to other brokers? Y N N Done Failed N Start All goals met? Hard goal? Y N N
- 38. Distributed Data Systems 38©2016 LinkedIn Corporation. All Rights Reserved. Heuristic Analyzer ▪ From weeks to lower seconds – Not globally optimal solution – But good enough ▪ Pluggable goals – Each goal implements an interface – Easy to add new goals
- 39. Distributed Data Systems 39©2016 LinkedIn Corporation. All Rights Reserved. Many Interesting Challenges ▪ Trustworthy Workload Modeling (Workload Monitor) ▪ Fast Optimization Resolution (Analyzer) ▪ False Alarm in Failure (Failure Detector) ▪ Controlled Balancing Execution (Executor) ▪ And so on…
- 40. Distributed Data Systems 40©2016 LinkedIn Corporation. All Rights Reserved. Avoid false alarm in failure detection ▪ Broker may appear to be failed in a few cases – Rolling bounce – Machine reboot – Hard kill testing ▪ Heal a cluster is expensive – Data movement
- 41. Distributed Data Systems 41©2016 LinkedIn Corporation. All Rights Reserved. Avoid false alarm in failure detection ▪ Trade off between detection time and false alarm – A grace period for a broker to come back ▪ E.g. 30 min. – Asking for human intervention ▪ E.g. a broker will be back with a reboot.
- 42. Distributed Data Systems 42©2016 LinkedIn Corporation. All Rights Reserved. Many Interesting Challenges ▪ Trustworthy Workload Modeling ▪ Fast Optimization Resolution ▪ False Alarm in Failure ▪ Controlled Balancing Execution ▪ And so on…
- 43. Distributed Data Systems 43©2016 LinkedIn Corporation. All Rights Reserved. Controlled Balancing Execution ▪ Leader movement is cheap ▪ Partition reassignment is expensive – A long lasting job – Data movements – Difficult to interrupt ▪ When and how to interrupt
- 44. Distributed Data Systems 44©2016 LinkedIn Corporation. All Rights Reserved. Controlled Balancing Execution ▪ KIP-73 – replication quotas to throttle the replication traffic during partition reassignment – Avoid impact on normal traffic ▪ Executor in Kafka Cruise Control – Batched replica reassignment – Allow easy and safe interruption between batches
- 45. Distributed Data Systems 45©2016 LinkedIn Corporation. All Rights Reserved. Future Works ▪ Integration with cloud infrastructure – E.g. RAIN, Kubernetes ▪ GUI for Cruise Control ▪ Time machine for partition assignments – Allows restoring a previous partition assignment ▪ Optimize performance and reduce overheads
- 46. Distributed Data Systems 46©2016 LinkedIn Corporation. All Rights Reserved. Acknowledgements Aditya Auradkar Dong Lin Joel Koshy Kartik Paramasivam Kafka team@LinkedIn
- 47. Distributed Data Systems 47©2016 LinkedIn Corporation. All Rights Reserved. Q&A