Introduction to Semantic Web for GIS Practitioners
Download as ppt, pdf9 likes3,647 views

This document provides an introduction to the Semantic Web and RDF (Resource Description Framework). It discusses how the Semantic Web aims to extend the current web by giving data well-defined meaning to enable computers and people to better work together. It introduces RDF as a standard for representing information in the Semantic Web and provides examples of how RDF can be used to represent different types of data, such as relational data and evolving data scenarios.
![Introduction to Semantic Web for GIS Practitioners 3.5.2011, Como Emanuele Della Valle [email_address] http://emanueledellavalle.org](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-1-320.jpg)





![Introduction Do We Really Know What “Understanding” means? [ source http://www.thefarside.com/ ]](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-7-320.jpg)

![Introduction Smart Machines Working examples found on the Web Image Processing retrievr: find by sketching http://labs.systemone.at/retrievr/ Audio Processing midomi: find by singing http://www.midomi.com/ […] Natural Language Processing semantic proxy: http://semanticproxy.opencalais.com/about.html Sensor Data Symbolic Description Image Processing Audio Processing Natural Language Processing […]](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-9-320.jpg)
![Introduction Smart Machines alone cannot bridge the gap … Natural Language Processing (NLP) meets Image Processing (IP) NLP : What does your eye see? IP : I see a sea NLP : You see a “c”? IP : Yes, what else could it be? [Source NLP Related Entertainment http://www.cl.cam.ac.uk/Research/NL/amusement.html] Sensor Data Symbolic Description Image Processing Natural Language Processing sea “ c” Semantic Gap](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-10-320.jpg)

![Introduction What a machine “understands” of the Web What we say to Web agents " For more information visit <a href= “http://www.ex.org”> my company </a> Web site. . .” What they “hear” " blah blah blah blah blah <a href= “http://www.ex.org”> blah blah blah </a> blah blah. . .” Jet this is enought to train them to achive tasks for us [ source http://www.thefarside.com/ ]](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-12-320.jpg)
![Introduction What does Google “understand”? Understanding that [page1] links [page2] page2 is interesting Google is able to rank results! “ The heart of our software is PageRank™, a system for ranking web pages […] (that) relies on the uniquely democratic nature of the web by using its vast link structure as an indicator of an individual page's value .” http://www.google.com/technology/](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-13-320.jpg)

![Introduction The Semantic Web 2/4 “ The Semantic Web is not a separate Web, but an extension of the current one […] ” Web 1.0 The Web Today](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-15-320.jpg)
![Introduction The Semantic Web 3/4 “ The Semantic Web […] , in which information is given well-defined meaning […]” Human understandable but “only” machine-readable Human and machine “ understandable ” ? Web 1.0 Semantic Web](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-16-320.jpg)
![Introduction The Semantic Web 4/4 Semantic Web Fewer Integration - standard - multi-lateral […] better enabling computers and people to work in cooperation. Even More Applications Easier to understand for people More “understandable” for computers Semantic Mash-ups & Search](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-17-320.jpg)





![Introduction Semantic Web “layer cake” Standardized Under Investigation Already Possible [ source http://www.w3.org/2007/03/layerCake.png ]](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-24-320.jpg)








![What if I cannot thing about a good URI? When no go URI exists, you can use blank nodes ( ) The following relational data … … can be translated in RDF, in the BIO vocabulary [1], as follows [1] http://vocab.org/bio/0.1.html RDF in a nutshell Representing data in RDF Q/A 4/4 1974-02-28 http://www.sofia.org/#me http://purl.org/vocab/bio/0.1/Birth http://purl.org/vocab/bio/0.1/Marriage 1995-08-04 http://purl.org/vocab/bio/0.1/event http://purl.org/vocab/bio/0.1/event http://www.w3.org/1999/02/22-rdf-syntax-ns#type http://purl.org/vocab/bio/0.1/date http://purl.org/vocab/bio/0.1/event http://purl.org/vocab/bio/0.1/date Advanced Person Bio Event Date Sofia Birth 1974-02-28 Sofia Marriage 1995-08-04](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-33-320.jpg)






![RDF in a nutshell Serializing RDF in XML W3C standardized an RDF/XML syntax [1] The basic idea is to insert an XML element for each node (sobject and value) and arc (predicate) Es. < rdf:RDF xmlns:rdf= ”http://www.w3.org/1999/02/22-rdf-syntax-ns#” xmlns:ex= ”http://www.example.org/” xmlns:sid= “URN:org:example:staffid:” xmlns:dc= ”http://purl.org/dc/elements/1.1/”> < rdf:Description rdf:about ="http://www.example.org/index.html "> < dc:creator > < rdf:Description rdf:about ="URN:org:example:staffid:85740"/> </ dc:creator > </rdf:Description> </rdf:RDF> [1] RDF/XML Syntax Specification available at http://www.w3.org/TR/rdf-syntax-grammar/ ex:index.html sid:85740 dc:creator property element Root tag](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-41-320.jpg)





























![RDF-S/OWL in a nutshell What is an Ontology? A model of (some aspect of) the world Introduces vocabulary relevant to domain e.g., anatomy Specifies meaning (semantics) of terms Heart is a muscular organ that is part of the circulatory system Formalised using suitable logic ∀ x.[ Heart (x)-> MuscolarOrgan (x)∧ ∃y.[ isPartOf (x,y )∧ CirculatorySystem (y)]] Shared among multiple people organizations](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-72-320.jpg)
![RDF-S/OWL in a nutshell How much explicit shall the specification be ? “ A little semantics, goes a long way” [James Hendler, 2001] Advanced](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-73-320.jpg)

![RDF-S/OWL in a nutshell Specifying classes, sub-classes and instances Creating a class RDFS: Artist rdf:type rdfs:Class . FOL: x Artist(x) Creating a subclass RDFS: Painter rdfs:subClassOf Artist . RDFS: Sculptor rdfs:subClassOf Artist . FOL: x [Painter(x) Sculptor(x) Artist(x)] Creating an instance RDFS: Rodin rdf:type Sculptor . FOL: Sculptor(Rodin) Artist Painter Sculptor Rodin](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-75-320.jpg)
![Creating a property RDFS: creates rdf:type rdf:Property . FOL: x y Creates(x,y) Using a property RDFS: Rodin creates TheKiss . FOL: Creates(Rodin, TheKiss) Creating subproperties RDFS: paints rdfs:subPropertyOf creates . FOL: x y [Paints(x,y) Creates(x,y)] RDFS: sculpts rdfs:subPropertyOf creates . FOL: x y [Sculpts(x,y) Creates(x,y)] RDF-S/OWL in a nutshell Specifying properties and sub-properties - - creates paints](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-76-320.jpg)
![RDF-S/OWL in a nutshell Specifying domain/range constrains Checking which classes and properties can be use together RDFS: creates rdfs:domain Artist . creates rdfs:range Piece . paints rdfs:domain Painter . paints rdfs:range Paint . sculpts rdfs:domain Sculptor . sculpts rdfs:range Sculpt . FOL: x y [Creates(x,y) Artist(x) Piece(y)] x y [Paints(x,y) Painter(x) Paint(y)] x y [Sculpts(x,y) Sculptor(x) Sculpt(y)]](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-77-320.jpg)



![RDF-S/OWL in a nutshell Without Inference A recipient, that only understands XML syntax, receiving <RDF> <Description about="Rodin"> <sculpts resource="TheKiss"/> </Description> </RDF> can answer the following queries What does Rodin sculpt? RDF/Description[@about='Rodin']/sculpts/@resource Who does sculpt TheKiss? RDF/Description[sculpts/@resource='TheKiss']/@about Try out your self at http://www.mizar.dk/ XPath / but it cannot answer Who is Rodin? What is TheKiss? Is there any Sculptor/Scupts? Is there any Artist/Piece?](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-81-320.jpg)







![RDF-S/OWL in a nutshell More expressive power 1/3 RDFS is a light ontological language that allows for defining simple vocabularies. One may want also express Cardinality constrains (max, min, exactly) for properties usage Es. a Polygon has 3 or more edges x [Polygon(x) ≥3y Edge(y) Forms(y,x) ] Property types transitive e.g. hasAncestor is a transitive property: if A hasAncestor B and B hasAncestor C , then A hasAncestor C . x y z [HasAncestor(x,y) HasAncestor(y,z) HasAncestor(x,z) ] inverse e.g. sclupts has isSculptedBy as inverse property: if A sclupts B then B isSculptedBy A x y [Sculpts(x,y) IsSculptedBy(y,x) ] Advanced](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-89-320.jpg)
![RDF-S/OWL in a nutshell More expressive power 2/3 simmetric e.g. isCloseTo is a simmetric property: if A isCloseTo B then B isCloseTo A x y [IsCloseTo(x,y) IsCloseTo(y,x) ] Restrictions of usage for a specific property All values of property must be of a certain kind e.g. a D.O.C. Wine can be only produced by a Certified Wienery x y [DOCWine(x) Produces(x,y) CertifiedWienery(y)] Some values of property must be of a certain kind e.g. a Famous Painter must have painted some Famous Painting x [FamousPainter(x) y FamousPaint(y) IsPaintedBy(y,x)] A class is defined combining other classes (union, intersection, negation, ...) A white wine is a Wine and its color is “white” x [Wine(x) White(x)] Advanced](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-90-320.jpg)
![RDF-S/OWL in a nutshell More expressive power 3/3 Two instances refers to the same real object “ The Boss” and “Bruce Springsteen” are two names for the same person TheBoss = BruceSpringsteen Two classes refers to the same set “ Painters” in english and “Pittori” in italian x [Painter(x) Pittore(x)] Two properties refers to the same binary relationship “ Paints” in english and “Dipinge” in italian x y [Paints(x,y) Dipinge(x,y)] Advanced](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-91-320.jpg)










![Introduction to Semantic Web for GIS Practitioners 3.5.2011, Como Emanuele Della Valle [email_address] http://emanueledellavalle.org](https://image.slidesharecdn.com/semanticweb4gis-110504153905-phpapp02/85/Introduction-to-Semantic-Web-for-GIS-Practitioners-102-320.jpg)






























More Related Content
Viewers also liked (6)
Similar to Introduction to Semantic Web for GIS Practitioners (20)




More from Emanuele Della Valle (20)




















Recently uploaded (20)




















Introduction to Semantic Web for GIS Practitioners
- 1. Introduction to Semantic Web for GIS Practitioners 3.5.2011, Como Emanuele Della Valle [email_address] http://emanueledellavalle.org
- 2. Share, Remix, Reuse — Legally This work is licensed under the Creative Commons Attribution 3.0 Unported License. Your are free: to Share — to copy, distribute and transmit the work to Remix — to adapt the work Under the following conditions Attribution — You must attribute the work by inserting “ © applied-semantic-web.org” at the end of each reused slide a credits slide stating “These slides are partially based on “ An Introduction to the Semantic Web for GIS Practitioners ” by Emanuele Della Valle http://applied-semantic-web.org/slides/2011/05/ SemanticWeb4GIS.ppt To view a copy of this license, visit http://creativecommons.org/licenses/by/3.0/
- 3. Agenda Introduction and Motivation Data Interchange on the Web: RDF Querying the Semantic Web: SPARQL Modelling data and knowledge for the Semantic Web: RDF-S and OWL Conclusions
- 4. Introduction The Web Today Large number of integrations - ad hoc - pair-wise Too much information to browse, need for searching and mashing up automatically Each site is “understandable” for us Computers don’t “understand” much ? Millions of Applications Search & Mash-up Engine 010 0 1 1 0 0 1101 10100 10 0010 01 101 101 01 110 1 10 1 10 0 1 1 0 1 0 1 0 0 1 1 0 1 1 1 10 0 1 101 0 1
- 5. Introduction The Problem: “Semantic Gap” Sensor Data Semantic Gap Symbolic Description
- 6. Introduction “Understanding” Means Bridging the Gap understanding Sensor Data Symbolic Description
- 7. Introduction Do We Really Know What “Understanding” means? [ source http://www.thefarside.com/ ]
- 8. Introduction Two ways for computer to “ understand ” Smart Machine Smart Data
- 9. Introduction Smart Machines Working examples found on the Web Image Processing retrievr: find by sketching http://labs.systemone.at/retrievr/ Audio Processing midomi: find by singing http://www.midomi.com/ […] Natural Language Processing semantic proxy: http://semanticproxy.opencalais.com/about.html Sensor Data Symbolic Description Image Processing Audio Processing Natural Language Processing […]
- 10. Introduction Smart Machines alone cannot bridge the gap … Natural Language Processing (NLP) meets Image Processing (IP) NLP : What does your eye see? IP : I see a sea NLP : You see a “c”? IP : Yes, what else could it be? [Source NLP Related Entertainment http://www.cl.cam.ac.uk/Research/NL/amusement.html] Sensor Data Symbolic Description Image Processing Natural Language Processing sea “ c” Semantic Gap
- 11. Introduction … smart data are need Natural Language Processing (NLP) meets Image Processing (IP) NLP : What does your eye see? IP : I see a wordnet:word-sea NLP : mmm, I see a wordnet:word-c IP : I believe we have different understanding of the world … NLP : So do I Sensor Data Symbolic Description Image Processing Natural Language Processing sea “ c” smart data The Semantic Web offers a set of standards that lowers the barriers to employ smart data at large scale
- 12. Introduction What a machine “understands” of the Web What we say to Web agents " For more information visit <a href= “http://www.ex.org”> my company </a> Web site. . .” What they “hear” " blah blah blah blah blah <a href= “http://www.ex.org”> blah blah blah </a> blah blah. . .” Jet this is enought to train them to achive tasks for us [ source http://www.thefarside.com/ ]
- 13. Introduction What does Google “understand”? Understanding that [page1] links [page2] page2 is interesting Google is able to rank results! “ The heart of our software is PageRank™, a system for ranking web pages […] (that) relies on the uniquely democratic nature of the web by using its vast link structure as an indicator of an individual page's value .” http://www.google.com/technology/
- 14. Introduction The Semantic Web 1/4 “ The Semantic Web is not a separate Web, but an extension of the current one, in which information is given well-defined meaning, better enabling computers and people to work in cooperation.” “ The Semantic Web”, Scientific American Magazine, Maggio 2001 http://www.sciam.com/article.cfm?articleID=00048144-10D2-1C70-84A9809EC588EF21 Key concepts an extension of the current Web in which information is given well-defined meaning better enabling computers and people to work in cooperation. Both for computers and people
- 15. Introduction The Semantic Web 2/4 “ The Semantic Web is not a separate Web, but an extension of the current one […] ” Web 1.0 The Web Today
- 16. Introduction The Semantic Web 3/4 “ The Semantic Web […] , in which information is given well-defined meaning […]” Human understandable but “only” machine-readable Human and machine “ understandable ” ? Web 1.0 Semantic Web
- 17. Introduction The Semantic Web 4/4 Semantic Web Fewer Integration - standard - multi-lateral […] better enabling computers and people to work in cooperation. Even More Applications Easier to understand for people More “understandable” for computers Semantic Mash-ups & Search
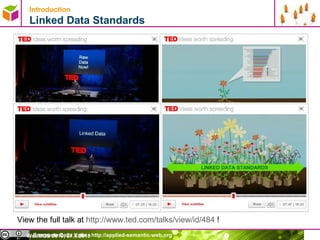
- 18. Introduction Linked Data Standards WebMGS 2010, 27.8.2010 View the full talk at http://www.ted.com/talks/view/id/484 !
- 19. Introduction Linking Open Data Project Goal: extend the Web with data commons by publishing open data sets using Semantic Web techs Visit http://esw.w3.org/topic/SweoIG/TaskForces/CommunityProjects/LinkingOpenData !
- 20. Introduction Example: BIO2RDF Peter Ansell, Model and prototype for querying multiple linked scientific datasets, Future Generation Computer Systems, Volume 27, Issue 3, March 2011, Pages 329-333
- 21. Introduction data.gov and data.gov.uk
- 22. Introduction Example: BBC’s Artist as Linked Data <?xml version="1.0" encoding="utf-8"?> <rdf:RDF xmlns:rdf = "http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:rdfs = "http://www.w3.org/2000/01/rdf-schema#" xmlns:owl = "http://www.w3.org/2002/07/owl#" xmlns:dc = "http://purl.org/dc/elements/1.1/" xmlns:foaf = "http://xmlns.com/foaf/0.1/" xmlns:rel = "http://www.perceive.net/schemas/relationship/" xmlns:mo = "http://purl.org/ontology/mo/" xmlns:rev = "http://purl.org/stuff/rev#" > <rdf:Description rdf:about="/music/artists/a3cb23fc-acd3-4ce0-8f36-1e5aa6a18432.rdf"> <rdfs:label>Description of the artist U2</rdfs:label> <foaf:primaryTopic rdf:resource="/music/artists/a3cb23fc-acd3-4ce0-8f36-1e5aa6a18432#artist"/> </rdf:Description> <mo:MusicGroup rdf:about="/music/artists/a3cb23fc-acd3-4ce0-8f36-1e5aa6a18432#artist"> <foaf:name>U2</foaf:name> <owl:sameAs rdf:resource="http://dbpedia.org/resource/U2" /> <foaf:page rdf:resource="/music/artists/a3cb23fc-acd3-4ce0-8f36-1e5aa6a18432.html" /> <mo:musicbrainz rdf:resource="http://musicbrainz.org/artist/a3cb23fc-acd3-4ce0-8f36-1e5aa6a18432.html" /> <mo:homepage rdf:resource="http://www.u2.com/" /> <mo:fanpage rdf:resource="http://www.atu2.com/" /> <mo:wikipedia rdf:resource="http://en.wikipedia.org/wiki/U2" /> <mo:imdb rdf:resource="http://www.imdb.com/name/nm1277752/" /> <mo:myspace rdf:resource="http://www.myspace.com/u2" /> <mo:member rdf:resource="/music/artists/7f347782-eb14-40c3-98e2-17b6e1bfe56c#artist" /> <mo:member rdf:resource="/music/artists/1f52af22-0207-40ac-9a15-e5052bb670c2#artist" /> HTML: http://www.bbc.co.uk/music/artists/a3cb23fc-acd3-4ce0-8f36-1e5aa6a18432 RDF : http://www.bbc.co.uk/music/artists/a3cb23fc-acd3-4ce0-8f36-1e5aa6a18432.rdf
- 23. Introduction Example: LinkedGeoData LinkedGeoData is an effort to add a spatial dimension to the Semantic Web. uses the information collected by the OpenStreetMap project makes it available as an RDF knowledge base according to the Linked Data principles. interlinks this data with other knowledge bases in the Linking Open Data initiative.
- 24. Introduction Semantic Web “layer cake” Standardized Under Investigation Already Possible [ source http://www.w3.org/2007/03/layerCake.png ]
- 26. RDF in a nutshell Looking for a flexible data model Why Application are always changing (competitive environment) People are always adding more features Graceful evolution is important Optimal: relational model Relational model is remarkably flexible Supports graceful evolution Change => Add another table Existing queries are unaffected Easily accommodates new data Without affecting existing queries Allows data to be easily combined ("joined") in new ways 25+ years of relational database experience - - © 2001-2005 E. Della Valle - CEFRIEL
- 27. RDF in a nutshell Resource Description Framework The adaptation of the relational model to the Web give rise to RDF From T-tuples to Triples Any relational data can be represented as triples Row Key --> Subject Column --> Property Value --> Value
- 28. RDF in a nutshell Representing relational data in RDF (almost) E.g., geographical data Represented in RDF (almost) IT.2 Italy 1.298.972 Milano Milan Mailand Country Population Is a City Legend resource literal Name City Country Population IT.2 Italy 1.298.972 City Name IT.2 Milano IT.2 Milan IT.2 Mailand
- 29. RDF in a nutshell Representing relational data in RDF (almost) Two important problems Once out of the database internal ID (e.g., IT.2) becomes useless Once out of the database internal names of schema element (e.g., City) becomes useless as well RDF solves it by using URI Internal ID should be replaced by URI Internal schema names should be replaced by URI Values do (always) not need to be URI-fied http://sws.geonames.org/3173435/ http://www.geonames.org/countries/#IT 1.298.972 Milano Milan Mailand http://www.geonames.org/ontology#inCountry http://www.geonames.org/ontology#population http://www.w3.org/2000/01/rdf-schema#label http://www.geonames.org/ontology#P http://www.w3.org/1999/02/22-rdf-syntax-ns#type Legend resource literal
- 30. Which URI should we use? Popular ones! Data merge will take place automatically! RDF in a nutshell Representing data in RDF Q/A 1/4 http://sws.geonames.org/3173435/ http://www.geonames.org/countries/#IT http://www.geonames.org/ontology#inCountry + http://sws.geonames.org/3173435/ 20100 http://dbpedia.org/resource/Postalcode http://sws.geonames.org/3173435/ http://www.geonames.org/countries/#IT http://www.geonames.org/ontology#inCountry = 20100 http://dbpedia.org/resource/Postalcode
- 31. Where do I find popular URIs? A difficult question with no clear answer The best place to keep an eye on is the Linking Open Data Project http://esw.w3.org/topic/SweoIG/TaskForces/CommunityProjects/LinkingOpenData and in particular the following pages of the Wiki Data Sets http://esw.w3.org/topic/TaskForces/CommunityProjects/LinkingOpenData/DataSets Semantic Web Search Engines http://esw.w3.org/topic/TaskForces/CommunityProjects/LinkingOpenData/SemanticWebSearchEngines Common Vocabularies http://esw.w3.org/topic/TaskForces/CommunityProjects/LinkingOpenData/CommonVocabularies RDF in a nutshell Representing data in RDF Q/A 2/4
- 32. What is a value? When shall we URI-fy a value? Literals cannot be used to merge different data set E.g., having chosen to represent postal codes as a string, merging different data sets using postal codes is impossible 20100 may refer to lots of different thing on the Web e.g., try http://images.google.com/images?q=20100 URI-fy any value that can be eventually used to merge different dataset and leave the other values as literals RDF in a nutshell Representing data in RDF Q/A 3/4 20100 http://dbpedia.org/resource/Postalcode 20100 http://dbpedia.org/resource/Postalcode + = ?
- 33. What if I cannot thing about a good URI? When no go URI exists, you can use blank nodes ( ) The following relational data … … can be translated in RDF, in the BIO vocabulary [1], as follows [1] http://vocab.org/bio/0.1.html RDF in a nutshell Representing data in RDF Q/A 4/4 1974-02-28 http://www.sofia.org/#me http://purl.org/vocab/bio/0.1/Birth http://purl.org/vocab/bio/0.1/Marriage 1995-08-04 http://purl.org/vocab/bio/0.1/event http://purl.org/vocab/bio/0.1/event http://www.w3.org/1999/02/22-rdf-syntax-ns#type http://purl.org/vocab/bio/0.1/date http://purl.org/vocab/bio/0.1/event http://purl.org/vocab/bio/0.1/date Advanced Person Bio Event Date Sofia Birth 1974-02-28 Sofia Marriage 1995-08-04
- 34. RDF in a nutshell Other data structure in RDF Trees can be represented in RDF Anything can be represented in RDF
- 35. RDF in a nutshell XML vs. RDF w.r.t. Evolving Data Scenario: Describe printer capabilities V1 has several features XML RDF
- 36. RDF in a nutshell XML vs. RDF w.r.t. Evolving Data V1.1 adds two features What effect on existing client software? Regenerate stubs? Recompile? Did any queries break? (Depends how they're written. Best programmers?) XML RDF
- 37. RDF in a nutshell XML vs. RDF w.r.t. Evolving Data V1.2 adds three more features What effect on existing client software? XML RDF
- 38. RDF in a nutshell XML vs. RDF w.r.t. Evolving Data V2 adds colors What effect on existing client software? XML RDF
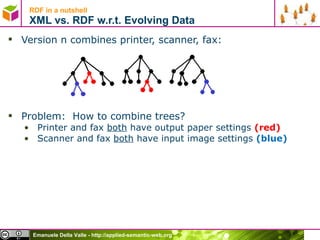
- 39. RDF in a nutshell XML vs. RDF w.r.t. Evolving Data Version n combines printer, scanner, fax: Problem: How to combine trees? Printer and fax both have output paper settings (red) Scanner and fax both have input image settings (blue)
- 40. RDF in a nutshell XML vs. RDF w.r.t. Evolving Data Flexibility is important Products are always changing (competitive environment) People are always adding more features Graceful evolution is important Relational data is remarkably flexible XML syntax is important Lots of application, which use XML, are already available Lots of tools for XML are already available Trees alows for simple parsing without loading the entire model (i.e., XML parsing using SAX)
- 41. RDF in a nutshell Serializing RDF in XML W3C standardized an RDF/XML syntax [1] The basic idea is to insert an XML element for each node (sobject and value) and arc (predicate) Es. < rdf:RDF xmlns:rdf= ”http://www.w3.org/1999/02/22-rdf-syntax-ns#” xmlns:ex= ”http://www.example.org/” xmlns:sid= “URN:org:example:staffid:” xmlns:dc= ”http://purl.org/dc/elements/1.1/”> < rdf:Description rdf:about ="http://www.example.org/index.html "> < dc:creator > < rdf:Description rdf:about ="URN:org:example:staffid:85740"/> </ dc:creator > </rdf:Description> </rdf:RDF> [1] RDF/XML Syntax Specification available at http://www.w3.org/TR/rdf-syntax-grammar/ ex:index.html sid:85740 dc:creator property element Root tag
- 42. RDF in a nutshell Serializing RDF in XML A compact XML serialization of is <ex:pagina_web rdf:about="http://www.example.org/index.html"> <dc:creator> <ex:impiegato rdf:about="sid:55740" foaf:email="mailto:[email protected]"/> <dc:creator> </ex:pagina_web> Advanced
- 43. RDF in a nutshell Merging XML files 1/2 Suppose you have to merge the two following XML Merging the XML trees is difficult, but being RDF … <Park rdf:about="Yosemite"> <conteins> <Camp rdf:about="North-Pines"/> </conteins> <crossedBy> <Path rdf:about="S11"/> </crossedBy> </Park> <Camp rdf:about="North-Pines" locatedIn=" Yosemite "> <accessibleBy> <Path rdf:about="S11"/> </accessibleBy> </Camp> Yosemite North-Pines Park rdf : type rdf : type conteins Camp S11 rdf : type Path crossedBy Yosemite North-Pines rdf : type Camp S11 rdf : type Path accessibleBy locatedIn Advanced
- 44. RDF in a nutshell Merging XML files 2/2 It’s (just) a matter to merge the two RDF graphs NOTE: It works out nicely because both RDF/XML documents refer to the same resources and use the same vocabularies. U Yosemite North-Pines Park rdf : type rdf : type conteins Camp S11 Path accessibleBy crossedBy locatedIn rdf : type Advanced
- 45. RDF in a nutshell Serializing RDF in Turtle - namespaces RDF allows for serializations alternative to XML Turtle serialization is often used for teaching Semantic Web Technologies because triples are more evident Example @prefix sr: <http://www.streamreasoning.org/sr4ld2011/onto#> . @prefix skos: <http://www.w3.org/2004/02/skos/core#> . @prefix dbp: <http://dbpedia.org/resource/Category:> . sr:LaScala a sr:NamedPlace ; skos:subject dbp: Opera_houses_in_Italy . sr:GalleriaVittorioEmanueleII a sr:NamedPlace ; skos:subject dbp:Pedestrian_streets_in_Italy, dbp:Buildings_and_structures_in_Milan . sr:Duomo a sr:NamedPlace ; skos:subject dbp:ChurchesInMilan.
- 46. RDF in a nutshell Serializing RDF in Turtle - namespaces RDF allows for serializations alternative to XML Turtle serialization is often used for teaching Semantic Web Technologies because triples are more evident URI terms can be abbreviated using namespaces @prefix sr: <http://www.streamreasoning.org/sr4ld2011/onto#> . sr:LaScala rdf:type sr:NamedPlace . <http://www.w3.org/1999/ 02/22-rdf-syntax-ns#type> = ' a ' sr:LaScala a sr:NamedPlace .
- 47. RDF in a nutshell Serializing RDF in Turtle - Convience Syntax Abbreviating repeated subjects: sr:LaScala a sr:NamedPlace . sr:LaScala skos:subject dbp:Opera_houses_in_Italy . ... is the same as ... sr:LaScala a sr:NamedPlace ; skos:subject dbp:Opera_houses_in_Italy . Abbreviating repeated subject/predicate pairs: sr:GalleriaVittorioEmanueleII skos:subject dbp:Pedestrian_streets_in_Italy . sr:GalleriaVittorioEmanueleII skos:subject dbp:Buildings_and_structures_in_Milan. ... is the same as ... sr:GalleriaVittorioEmanueleII skos:subject dbp:Pedestrian_streets_in_Italy, dbp:Buildings_and_structures_in_Milan .
- 48. RDF in a nutshell RDF Resources RDF at the W3C - primer and specifications http://www.w3.org/RDF/ Semantic Web tools - community maintained list; includes triple store, programming environments, tool sets, and more http://esw.w3.org/topic/SemanticWebTools 302 Semantic Web Videos and Podcasts - includes a section specifically on RDF videos http://www.semanticfocus.com/blog/entry/title/302-semantic-web-videos-and-podcasts/
- 49. Query: SPARQL
- 50. SPARQL in a nutshell What is SPARQL? SPARQL is the query language of the Semantic Web stays for S PARQL P rotocol a nd R DF Q uery L anguage A Query Language ...: find named place : PREFIX sr: <http://www.streamreasoning.org/sr4ld2011/onto#> SELECT ?poi WHERE { ?poi a sr:NamedPlace . } ... and a Protocol. http://lod.openlinksw.com/sparql?&query=PREFIX+sr%3A+%3Chttps%3A%2F%2Fptop.only.wip.la%3A443%2Fhttp%2Fwww.streamreasoning.org%2Fsr4ld2011%2Fonto%2F%3E%0D%0ASELECT+%3Fpoi+WHERE+{+%3Fpoi+a+sr%3ANamedPlace+.+}
- 51. SPARQL in a nutshell Why SPARQL? SPARQL let us Pull values from structured and semi-structured data represented in RDF Explore RDF data by querying unknown relationships Perform complex joins of disparate RDF repositories in a single query Transform RDF data from one vocabulary to another Develop higher-level cross-platform application
- 52. SPARQL in a nutshell Anatomy of a SPARQL query
- 53. SPARQL in a nutshell Anatomy of a SPARQL SELECT query
- 54. SPARQL in a nutshell Triple Pattern Syntax Turtle-like: URIs, QNames, literals, convenience syntax. Adds variables to get basic graph patterns ?var Variable names are a subset of NCNames (no "-" or ".") E.g., simple ?poi a sr:NamedPlace . a bit more complex ?poi a geo:NamedPlace . ?poi skos:subject ?category . Adds OPTIONAL to cope with semi-structured nature of RDF FILTER to select solution according to some criteria UNION operator to get complex patterns
- 55. SPARQL in a nutshell Writing a Simple Query Data @prefix sr:<http://www.streamreasoning.org/sr4ld2011/onto#> . sr:LaScala a sr:NamedPlace . sr:GalleriaVittorioEmanueleII a sr:NamedPlace . sr:Duomo a sr:NamedPlace . Query PREFIX sr: <http://www.streamreasoning.org/sr4ld2011/onto#> SELECT ?poi WHERE { ?poi a sr:NamedPlace . } Results a = rdf:type ?poi http://www.streamreasoning.org/sr4ld2011/data#GalleriaVittorioEmanueleII http://www.streamreasoning.org/sr4ld2011/data#LaScala http://www.streamreasoning.org/sr4ld2011/data#Duomo
- 56. SPARQL in a nutshell Matching Matches the graph means find a set of bindings such that the substitution of variables for values creates a triple that is in the set of triples making up the graph. Solution 1: variable poi has value sr:GalleriaVittorioEmanueleII Triple sr: GalleriaVittorioEmanueleII a sr:NamedPlace . is in the graph. Solution 2: variable poi has value sr: LaScala Triple sr: LaScala a sr:NamedPlace . is in the graph. Solution 3: variable poi has value sr: Duomo Triple sr: Duomo a sr:NamedPlace . is in the graph. No order of solutions in this query.
- 57. SPARQL in a nutshell Writing a bit more complex query Query PREFIX skos: <http://www.w3.org/2004/02/skos/core#> PREFIX sr: <http://www.streamreasoning.org/sr4ld2011/onto#> SELECT ?poi ?category WHERE { ?poi a geo:NamedPlace ; skos:subject ?category . } Results ?poi ?category http://www.streamreasoning.org/sr4ld2011/data#GalleriaVittorioEmanueleII http://dbpedia.org/resource/Category:Pedestrian_streets_in_Italy http://www.streamreasoning.org/sr4ld2011/data#GalleriaVittorioEmanueleII http://dbpedia.org/resource/Category:Buildings_and_structures_in_Milan http://www.streamreasoning.org/sr4ld2011/data#LaScala http://dbpedia.org/resource/Category:Opera_houses_in_Italy http://www.streamreasoning.org/sr4ld2011/data#Duomo http://dbpedia.org/class/yago/ChurchesInMilan … …
- 58. SPARQL in a nutshell Basic Graph Patterns A Basic Graph Patter is a set of triple patterns, all of which must be matched . In this case m atches the graph means find a set of bindings such that the substitution of variables for values creates a subgraph that is in the set of triples making up the graph.
- 59. SPARQL in a nutshell Matching RDF literals – text Query PREFIX sr: <http://www.streamreasoning.org/sr4ld2011/onto#> SELECT ?poi WHERE { ?poi sr:name "Duomo". } Results Alert! It may return 0 results if the literal have a language tag E.g., if data contains only the triple sr: Duomo sr:name "Duomo"@it . To obtain results also add the language tag to the triple pattern E.g, ?poi sr:name "Duomo"@it. ?poi http://www.streamreasoning.org/sr4ld2011/data#Duomo
- 60. SPARQL in a nutshell Matching RDF literals – numerical values As in the case of language tags, if the literals are typed (i.e., "3.14"^^xsd:float ), they do not match if they are not given explicitly. Query PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> PREFIX geo: < http://www.w3.org/2003/01/geo/wgs84_pos# > PREFIX sr: <http://www.streamreasoning.org/sr4ld2011/onto#> SELECT ?poi WHERE { ?poi a sr:NamedPlace ; geo:lat "45.46416854858398" ^^xsd:float ; geo:long "9.191389083862305" ^^xsd:float . } Results ?poi http://www.streamreasoning.org/sr4ld2011/data#Duomo
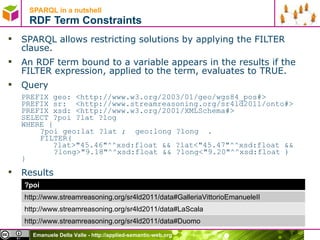
- 61. SPARQL in a nutshell RDF Term Constraints SPARQL allows restricting solutions by applying the FILTER clause. An RDF term bound to a variable appears in the results if the FILTER expression, applied to the term, evaluates to TRUE. Query PREFIX geo: <http://www.w3.org/2003/01/geo/wgs84_pos#> PREFIX sr: <http://www.streamreasoning.org/sr4ld2011/onto#> PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> SELECT ?poi ?lat ?log WHERE { ?poi geo:lat ?lat ; geo:long ?long . FILTER( ?lat>"45.46"^^xsd:float && ?lat<"45.47"^^xsd:float && ?long>"9.18"^^xsd:float && ?long<"9.20"^^xsd:float ) } Results ?poi http://www.streamreasoning.org/sr4ld2011/data#GalleriaVittorioEmanueleII http://www.streamreasoning.org/sr4ld2011/data#LaScala http://www.streamreasoning.org/sr4ld2011/data#Duomo
- 62. SPARQL in a nutshell RDF Term Constraints – regex SPARQL FILTERs allows also restricting values of strings using the regex() Query PREFIX sr: <http://www.streamreasoning.org/sr4ld2011/onto#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> SELECT ?poi ?c WHERE { ?poi rdfs:comment ?c . FILTER(regex(?c, "glass-vaulted arcades", "i" ))} Results ?poi ?c http://www.streamreasoning.org/sr4ld2011/data#GalleriaVittorioEmanueleII The Galleria Vittorio Emanuele II is a covered double arcade formed of two glass-vaulted arcades at right angles intersecting in an octagon, prominently sited on the northern side of the Piazza del Duomo in Milan, and connects to the Piazza della Scala.
- 63. SPARQL in a nutshell Value Tests Notation for value comparison: <, >, =, <=, >= and != Test functions Check if a variable is bound: BOUND Check the type of resource bound: isIRI, isBLANK, isLITERAL Accessing accessories: LANG, DATATYPE Logic operators: || and && Comparing strings: REGEX, langMatches Constructor functions: bool, dbl, flt, dec, int, dT, str, IRI Extensible Value Testing E.g., FILTER ( aGeo:distance(?axLoc, ?ayLoc, ?bxLoc, ?byLoc) < 10 ) . (see http://www.w3.org/TR/rdf-sparql-query/#extensionFunctions )
- 64. SPARQL in a nutshell Value Tests - Extensible Value Testing 1/2 Find all schools within a 5km radius around a specific location, and for each school find coffeeshops that are closer than 1km. PREFIX lgdo: <http://linkedgeodata.org/ontology/> SELECT ?schoolname ?schoolgeo ?coffeeshopname ?coffeeshopgeo WHERE { ?school a lgdo:School . ?school geo:geometry ?schoolgeo . ?school rdfs:label ?schoolname . ?coffeeshop a lgdo:CoffeeShop . ?coffeeshop geo:geometry ?coffeeshopgeo . ?coffeeshop rdfs:label ?coffeeshopname . FILTER( bif:st_intersects( ?schoolgeo,bif:st_point(4.892222,52.373056), 5) && bif:st_intersects(?coffeeshopgeo, ?schoolgeo, 1) ) . } Click here for query results on a Virtuoso endpoint used by LinkedGeoData project.
- 65. SPARQL in a nutshell Value Tests - Extensible Value Testing 2/2 Signature st_intersects(g1, g2, prec) Parameters g1 – The first geometry. g2 – The second geometry. prec – A tolerance for the matching in units of linear distance appropriate to the srid. Default is 0. Description Returns intersects between two geometries. If prec is supplied, this is a tolerance for the matching in units of linear distance appropriate to the srid. Both geometries should have the same srid. st_intersects is true if there is at least one point in common.
- 66. SPARQL in a nutshell More Sophisticated Graph Patterns RDF is "semi structured" and has no integrity constrains SPARQL addresses this issue with Group patterns match if all subpatterns match and all constraints are satisfied In SPARQL syntax, groups are { … } OPTIONAL graph patterns accommodate the need to add information to a result but without the query failing just because some information is missing. In SPARQL syntax, OPTIONAL { … } UNION graph patterns allows to match alternatives In SPARQL syntax, { … } UNION { … }
- 67. SPARQL in a nutshell Result Forms Besides selecting tables of values, SPARQL allows three other types of queries: ASK - returns a boolean answering, does the query have any results? CONSTRUCT - uses variable bindings to return new RDF triples DESCRIBE - returns server-determined RDF about the queried resources SELECT and ASK results can be returned as XML or JSON. CONSTRUCT and DESCRIBE results can be returned via any RDF serialization (e.g. RDF/XML or Turtle).
- 68. SPARQL in a nutshell SPARQL Resources SPARQL Frequently Asked Questions http://thefigtrees.net/lee/sw/sparql-faq SPARQL implementations - community maintained list of open-source and commercial SPARQL engines http://esw.w3.org/topic/SparqlImplementations Public SPARQL endpoints - community maintained list http://esw.w3.org/topic/SparqlEndpoints SPARQL extensions - collection of SPARQL extensions implemented in various SPARQL engines http://esw.w3.org/topic/SPARQL/Extensions
- 69. Ontology: RDF-S and OWL
- 70. RDF-S/OWL in a nutshell Ontology definition Philosophy (400BC): Systematic explanation of Existence Neches (91): Ontology defines basic terms and relations comprising the vocabulary of a topic area as well as the rules for combining terms and relations to define extensions to the vocabulary Gruber (93): Explicit specification of a conceptualization Borst (97): Formal specification of a shared conceptualization Studer(98) Formal, explicit specification of a shared conceptualization
- 71. RDF-S/OWL in a nutshell What does it mean? Formal, explicit specification of a shared conceptualization Machine readable Several people agrees that such conceptual model is adequate to describe such aspects of the reality A conceptual model of some aspects of the reality It makes domain assumption explicit
- 72. RDF-S/OWL in a nutshell What is an Ontology? A model of (some aspect of) the world Introduces vocabulary relevant to domain e.g., anatomy Specifies meaning (semantics) of terms Heart is a muscular organ that is part of the circulatory system Formalised using suitable logic ∀ x.[ Heart (x)-> MuscolarOrgan (x)∧ ∃y.[ isPartOf (x,y )∧ CirculatorySystem (y)]] Shared among multiple people organizations
- 73. RDF-S/OWL in a nutshell How much explicit shall the specification be ? “ A little semantics, goes a long way” [James Hendler, 2001] Advanced
- 74. RDF-S/OWL in a nutshell A simple ontology Artist Piece Painter Paint paints Sculptor Sculpt sculpts creates
- 75. RDF-S/OWL in a nutshell Specifying classes, sub-classes and instances Creating a class RDFS: Artist rdf:type rdfs:Class . FOL: x Artist(x) Creating a subclass RDFS: Painter rdfs:subClassOf Artist . RDFS: Sculptor rdfs:subClassOf Artist . FOL: x [Painter(x) Sculptor(x) Artist(x)] Creating an instance RDFS: Rodin rdf:type Sculptor . FOL: Sculptor(Rodin) Artist Painter Sculptor Rodin
- 76. Creating a property RDFS: creates rdf:type rdf:Property . FOL: x y Creates(x,y) Using a property RDFS: Rodin creates TheKiss . FOL: Creates(Rodin, TheKiss) Creating subproperties RDFS: paints rdfs:subPropertyOf creates . FOL: x y [Paints(x,y) Creates(x,y)] RDFS: sculpts rdfs:subPropertyOf creates . FOL: x y [Sculpts(x,y) Creates(x,y)] RDF-S/OWL in a nutshell Specifying properties and sub-properties - - creates paints
- 77. RDF-S/OWL in a nutshell Specifying domain/range constrains Checking which classes and properties can be use together RDFS: creates rdfs:domain Artist . creates rdfs:range Piece . paints rdfs:domain Painter . paints rdfs:range Paint . sculpts rdfs:domain Sculptor . sculpts rdfs:range Sculpt . FOL: x y [Creates(x,y) Artist(x) Piece(y)] x y [Paints(x,y) Painter(x) Paint(y)] x y [Sculpts(x,y) Sculptor(x) Sculpt(y)]
- 78. RDF-S/OWL in a nutshell The ontology we specified Artist Piece Painter Paint paints Sculptor Sculpt sculpts creates
- 79. RDF-S/OWL in a nutshell RDF semantics (a part of it) if then x rdfs:subClassOf y . a rdf:type y . a rdf:type x . x rdfs:subClassOf y . x rdfs:subClassOf z . y rdfs:subClassOf z . x a y . x b y . a rdfs:subPropertyOf b . a rdfs:subPropertyOf b . a rdfs:subPropertyOf c . b rdfs:subPropertyOf c . x a y . x rdf:type z . a rdfs:domain z . x a u . u rdf:type z . a rdfs:range z . Read out more in RDF Semantics http://www.w3.org/TR/rdf-mt/
- 80. RDF-S/OWL in a nutshell RDF semantics at work Shared the ontology ... @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . @prefix ex: <http://www.ex.org/schema#> . ex:Sculptor rdfs:subClassOf ex:Artist . ex:Painter rdfs:subClassOf ex:Artist . ex:Sculpt rdfs:subClassOf ex:Piece. ex:Painting rdfs:subClassOf ex:Piece . ex:creates rdfs:domain ex:Artist . ex:creates rdfs:range ex:Piece. ex:sculpts rdfs:subPropertyOf ex:creates . ex:sculpts rdfs:domain ex:Sculptor . ex:sculpts rdfs:range ex:Sculpt . ... when transmitting the following triple … ex:Rodin ex:sculpts ex:TheKiss .
- 81. RDF-S/OWL in a nutshell Without Inference A recipient, that only understands XML syntax, receiving <RDF> <Description about="Rodin"> <sculpts resource="TheKiss"/> </Description> </RDF> can answer the following queries What does Rodin sculpt? RDF/Description[@about='Rodin']/sculpts/@resource Who does sculpt TheKiss? RDF/Description[sculpts/@resource='TheKiss']/@about Try out your self at http://www.mizar.dk/ XPath / but it cannot answer Who is Rodin? What is TheKiss? Is there any Sculptor/Scupts? Is there any Artist/Piece?
- 82. RDF-S/OWL in a nutshell Knowing the ontology and RDF semantics … A recipient, that knows the ontology and “understands” RDF semantics , Receiving Rodin sculpts TheKiss . Rodin TheKiss Artist Piece Painter Paint paints Sculptor Sculpt sculpts creates
- 83. RDF-S/OWL in a nutshell … a reasoner can answer 1/2 the previous queries What does Rodin sculpt? PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX ex: <http://www.ex.org/schema#> SELECT ?x WHERE { ex:Rodin ex:sculpts ?x } ?x = ex:TheKiss Who does sculpt TheKiss? WHERE { ex:Rodin ex:sculpts ?x } ?x = ex:Rodin and it can also answer Who is Rodin? WHERE { ex:Rodin a ?x } ?x = ex:Artist, ex:Sculptor, rdfs: Resource What is TheKiss? WHERE { ex:TheKiss a ?x } ?x = ex:Sclupt, ex:Piece, rdfs: Resource
- 84. RDF-S/OWL in a nutshell … a reasoner can answer 2/2 Is there any Sculptor? WHERE { ?x a ex:Sculptor} ?x = ex:Rodin Is the any Artist? WHERE { ?x a ex:Artist } ?x = ex:Rodin Is there any Sculpt? WHERE { ?x a ex:Sculpt } ?x = ex:TheKiss Is there any Piece? WHERE { ?x a ex:Piece } ?x = ex:TheKiss Is there any Paint? WHERE { ?x a ex:Paint } 0 results Is there any Painter? WHERE { ?x a ex:Painter } 0 results
- 85. RDF-S/OWL in a nutshell Reasoning and Query Answering SPARQL alone cannot answer queries that require reasoning but a reasoner can be exposed as a SPARQL service. Or a query can be rewritten in order to incorporate the ontology data SPARQL service Reasoner data SPARQL service Inferred data ontology data SPARQL service ontology Rewritten query Advanced
- 86. Given ontology O and query Q, use O to rewrite Q as Q’ so that, for any set of ground facts A contained in multiple databases: answer(Q, O ,A) = answer(Q’, ,A) The answer of the query Q using the ontology O for any set of ground facts A is equal to answer of a query Q’ without considering the ontology O Use (Global As View) mapping M to map Q’ to multiple SQL queries to the various databases RDF-S/OWL in a nutshell Reasoning and Information Integration Rewrite O Q Q ’ Map SQL M answer Advanced
- 87. RDF-S/OWL in a nutshell Query Rewriting Technique (basics) Example: Ontology Doctors treats patients Consultants are doctors Query Give me those that treats some patient For OWL2 QL, the rewriting results in a union of conjunctive queries Advanced
- 88. RDF-S/OWL in a nutshell Query Rewriting Technique (basics) Relationship between ontology and databases defined by mappings , e.g.: Note: the mapping can be partial, i.e., Consultant is non mapped Using the mapping the query resulting from the mapping can be translated in SQL Advanced
- 89. RDF-S/OWL in a nutshell More expressive power 1/3 RDFS is a light ontological language that allows for defining simple vocabularies. One may want also express Cardinality constrains (max, min, exactly) for properties usage Es. a Polygon has 3 or more edges x [Polygon(x) ≥3y Edge(y) Forms(y,x) ] Property types transitive e.g. hasAncestor is a transitive property: if A hasAncestor B and B hasAncestor C , then A hasAncestor C . x y z [HasAncestor(x,y) HasAncestor(y,z) HasAncestor(x,z) ] inverse e.g. sclupts has isSculptedBy as inverse property: if A sclupts B then B isSculptedBy A x y [Sculpts(x,y) IsSculptedBy(y,x) ] Advanced
- 90. RDF-S/OWL in a nutshell More expressive power 2/3 simmetric e.g. isCloseTo is a simmetric property: if A isCloseTo B then B isCloseTo A x y [IsCloseTo(x,y) IsCloseTo(y,x) ] Restrictions of usage for a specific property All values of property must be of a certain kind e.g. a D.O.C. Wine can be only produced by a Certified Wienery x y [DOCWine(x) Produces(x,y) CertifiedWienery(y)] Some values of property must be of a certain kind e.g. a Famous Painter must have painted some Famous Painting x [FamousPainter(x) y FamousPaint(y) IsPaintedBy(y,x)] A class is defined combining other classes (union, intersection, negation, ...) A white wine is a Wine and its color is “white” x [Wine(x) White(x)] Advanced
- 91. RDF-S/OWL in a nutshell More expressive power 3/3 Two instances refers to the same real object “ The Boss” and “Bruce Springsteen” are two names for the same person TheBoss = BruceSpringsteen Two classes refers to the same set “ Painters” in english and “Pittori” in italian x [Painter(x) Pittore(x)] Two properties refers to the same binary relationship “ Paints” in english and “Dipinge” in italian x y [Paints(x,y) Dipinge(x,y)] Advanced
- 92. RDF-S/OWL in a nutshell Expressivity vs. Tractability The more an ontological language is expressive the less is tractable the Web Ontology Language (OWL) comes with several profiles that offers different trade-offs between expressivity and tractability. Advanced
- 93. RDF-S/OWL in a nutshell OWL 1 and OWL 2 profiles OWL 1 defines only one fragment (OWL Lite) And it isn’t very tractable! OWL 2 defines several different fragments with Useful computational properties E.g., reasoning complexity in range LOGSPACE to PTIME Useful implementation possibilities E.g., Smaller fragments implementable using RDBs OWL 2 profiles OWL 2 EL, OWL 2 QL, OWL 2 RL
- 94. RDF-S/OWL in a nutshell OWL 2 EL Useful for applications employing ontologies that contain very large number of properties and/or classes Captures expressive power used by many large-scaleontologies E.g.; SNOMED CT, NCI thesaurus Features Included: existential restrictions, intersection, subClass,equivalentClass, disjointness, range and domain, object property inclusion possibly involving property chains, and data property inclusion, transitive properties, keys … Missing: include value restrictions, Cardinality restrictions (min, max and exact), disjunction and negation Maximal language for which reasoning (including query answering) known to be worst-case polynomial
- 95. RDF-S/OWL in a nutshell OWL 2 QL Useful for applications that use very large volumes of data, and where query answering is the most important task Captures expressive power of simple ontologies like thesauri, classifications, and (most of) expressive power of ER/UML schemas E.g., CIM10, Thesaurus of Nephrology, ... Features Included: limited form of existential restrictions, subClass, equivalentClass, disjointness, range & domain, symmetric properties, … Missing: existential quantification to a class, self restriction, nominals, universal quantification to a class, disjunction etc. Can be implemented on top of standard relational DBMS Maximal language for which reasoning (including query answering) is known to be worst case logspace (same as DB)
- 96. RDF-S/OWL in a nutshell OWL 2 RL Useful for applications that require scalable reasoning without sacrifying too much expressive power, and where query answering is the most important task Support most OWL features but with restrictions placed on the syntax of OWL 2 standard semantics only apply when they are used in a restricted way Can be implemented on top of rule extended DBMS E.g., Oracle’s OWL Prime implemented using forward chaining rules in Oracle 11g Related to DLP and pD* Allows for scalable ( polynomial) reasoning using rule-based technologies
- 97. RDF-S/OWL in a nutshell RDF -S/OWL Resources OWL Frequently Asked Questions http://www.w3.org/2003/08/owlfaq.html RDF-S/OWL implementations - community maintained list of open-source and commercial SPARQL engines http://esw.w3.org/topic/SemanticWebTools#head-d07454b4f0d51f5e9d878822d911d0bfea9dcdfd RDF-S Specification http://www.w3.org/TR/rdf-schema/ OWL Working Group Wiki http://www.w3.org/2007/OWL/wiki
- 98. Conclusions 1/2 Achievements Extending the Web with a data commons 27 billion triples 395 million links Vibrant, global RTD community Industrial uptake begins e.g., BBC, NYT, Eli Lilly Government sponsorship mainly in USA and UK, but something moves in EU as well
- 99. Conclusions 2/2 Challenges Coherence relatively few and expansive to maintain links Quality Partly low quality data and inconsistencies Performance Still substantial penalties compared to relational Data consumption Large-scale processing, schema mapping and data fusions still in its infancy Usability Missing direct end-user tools and network effect
- 100. Credits Introduction and RDF slides are inspired by “Fundamentals of the Semantic Web” by David Booth http://www.w3.org/2002/Talks/0813-semweb-dbooth/ SPARQL slides are partially based on WWW 2005 SPARQL Tutorial http://www.w3.org/2004/Talks/17Dec-sparql/ OWL 2 slides are partially based on “ OWL 2 Update” by Christine Golbreich http://esw.w3.org/topic/HCLSIG/F2F/2008-10_F2F?action=AttachFile&do=get&target=HCLSF2F2008-OWL2-CG.pdf “ Scalable Ontology-Based Information Systems ” by Ian Horrocks presented at EDBT/ICDT 2010 Joint Conference, Lausanne, Switzerland, March 26th, 2010. http://www.comlab.ox.ac.uk/people/ian.horrocks/Seminars/download/EDBT-2010.pdf Conclusions are based on “Towards the Linked Data Web” by Sören Auer http://www.slideshare.net/lod2project/towards-the-linked-data-web-sren-auer-2612011-brussels-belgium
- 101. Advertisement ;-)
- 102. Introduction to Semantic Web for GIS Practitioners 3.5.2011, Como Emanuele Della Valle [email_address] http://emanueledellavalle.org
Editor's Notes
- #27: 05/04/11 © 2005 - Della Valle - CEFRIEL
- #44: 05/04/11 © 2005 - Della Valle - CEFRIEL
- #45: 05/04/11 © 2005 - Della Valle - CEFRIEL
- #55: PREFIX skos: <http://www.w3.org/2004/02/skos/core#> PREFIX dbpedia: <http://dbpedia.org/resource/> PREFIX dbpedia-owl: <http://dbpedia.org/ontology/> PREFIX category: <http://dbpedia.org/resource/Category:> select ?s ?p where { ?s a dbpedia-owl:Drug ; skos:subject category:Anxiolytics ; ?p dbpedia:Kidney . } http://dbpedia.org/isparql/view/?query=PREFIX%20skos%3A%20%3Chttps%3A%2F%2Fptop.only.wip.la%3A443%2Fhttp%2Fwww.w3.org%2F2004%2F02%2Fskos%2Fcore%23%3E%0APREFIX%20dbpedia%3A%20%3Chttps%3A%2F%2Fptop.only.wip.la%3A443%2Fhttp%2Fdbpedia.org%2Fresource%2F%3E%20%0APREFIX%20dbpedia-owl%3A%20%3Chttps%3A%2F%2Fptop.only.wip.la%3A443%2Fhttp%2Fdbpedia.org%2Fontology%2F%3E%20%0APREFIX%20category%3A%20%3Chttps%3A%2F%2Fptop.only.wip.la%3A443%2Fhttp%2Fdbpedia.org%2Fresource%2FCategory%3A%3E%20%0A%0Aselect%20%3Fs%20%3Fp%20%0Awhere%20%7B%20%3Fs%20a%20dbpedia-owl%3ADrug%20%3B%0A%20%20%20%20%20%20%20%20skos%3Asubject%20category%3AAnxiolytics%20%3B%0A%20%20%20%20%20%20%20%20%3Fp%20dbpedia%3AKidney%20.%20%7D%0A%20&endpoint=/sparql&maxrows=50&default-graph-uri=http://dbpedia.org
- #58: PREFIX skos: <http://www.w3.org/2004/02/skos/core#> PREFIX dbpedia-owl: <http://dbpedia.org/ontology/> SELECT ?drug ?category WHERE { ?drug a dbpedia-owl:Drug ; skos:subject ?category . }
- #60: PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX dbpedia-owl: <http://dbpedia.org/ontology/> SELECT ?drug WHERE { ?drug a dbpedia-owl:Drug ; rdfs:label &quot;Budesonide&quot; . }
- #61: PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> PREFIX dbpprop: <http://dbpedia.org/property/> PREFIX dbpedia-owl: <http://dbpedia.org/ontology/> SELECT ?drug WHERE { ?drug a dbpedia-owl:Drug ; dbpprop:chemspiderid &quot;4777&quot; ^^xsd:integer . }
- #62: PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> PREFIX dbpprop: <http://dbpedia.org/property/> PREFIX dbpedia-owl: <http://dbpedia.org/ontology/> SELECT ?drug ?mp WHERE { ?drug a dbpedia-owl:Drug ; dbpprop:meltingPoint ?mp . FILTER ( ?mp < 30 ) }
- #63: PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX dbpedia-owl: <http://dbpedia.org/ontology/> SELECT ?drug ?c WHERE { ?drug a dbpedia-owl:Drug ; rdfs:comment ?c . FILTER( regex(?c, &quot;Asthma&quot;, &quot;i&quot;)) }
- #82: <RDF> <Description about=&quot;Rodin&quot;> <sculpts resource=&quot;TheKiss&quot;/> </Description> <Description about=&quot;Painting&quot;> <subClassOf resource=&quot;Piece&quot;/> </Description> <Description about=&quot;sculpts&quot;> <range resource=&quot;Sculpt&quot;/> <domain resource=&quot;Sculptor&quot;/> <subPropertyOf resource=&quot;creates&quot;/> </Description> <Description about=&quot;Sculpt&quot;> <subClassOf resource=&quot;Piece&quot;/> </Description> <Description about=&quot;creates&quot;> <range resource=&quot;Piece&quot;/> <domain resource=&quot;Artist&quot;/> </Description> <Description about=&quot;Sculptor&quot;> <subClassOf resource=&quot;Artist&quot;/> </Description> <Description about=&quot;Painter&quot;> <subClassOf resource=&quot;Artist&quot;/> </Description> </RDF> RDF/Description[@about='Rodin']/sculpts/@resource RDF/Description[sculpts/@resource='TheKiss']/@about