Introduction to Spark Streaming
Download as PPT, PDF3 likes3,803 views

It Provide a way to consume continues stream of data. Build on top of Spark Core It supports Java, Scala and Python. API is similar to Spark Core.

















































Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to Introduction to Spark Streaming (20)




















Ad
More from Knoldus Inc. (20)




















Recently uploaded (20)













![Get & Download Wondershare Filmora Crack Latest [2025]](https://cdn.slidesharecdn.com/ss_thumbnails/revolutionizingresidentialwi-fi-250422112639-60fb726f-250429170801-59e1b240-thumbnail.jpg?width=560&fit=bounds)






Introduction to Spark Streaming
- 1. Introduction to Streaming in Apache Spark Based on Apache Spark 1.6.0 Akash Sethi Software Consultant Knoldus Software LLP.
- 2. Agenda What is Streaming Abstraction Provided For Streaming Execution Process Transformation Type of Transformation Action Performance Tuning options
- 3. High Level architecture of Spark Streaming Streaming in Apache Spark Provide way to consume continues stream of data. Build on top of Spark Core It supports Java, Scala and Python. API is similar to Spark Core.
- 4. DStream as a continues series of Data Streaming in Apache Spark Spark Streaming uses a “micro-batch” architecture. New batches are created at regular time intervals. At the beginning of each time interval a new batch is created, and any data that arrives during that interval gets added to that batch. At the end of the time interval the batch is done growing. The size of the time intervals is determined by a parameter called the batch interval.
- 5. Streaming in Apache Spark Spark Streaming provides an abstraction called DStreams, or discretized streams. A DStream is a sequence of data arriving over time. Internally, each DStream is represented as a sequence of RDDs arriving at each time step. Here RDDs are created on the basis of Time. Each input batch forms an RDD, and is processed using Spark jobs to create other RDDs. The processed results can then be pushed out to external systems in batches. We can also specify block size in milliseconds.
- 6. By default, received data is replicated across two nodes, so Spark Streaming can tolerate single worker failures. Using just lineage, however, re computation could take a long time for data that has been built up since the beginning of the program. Thus, Spark Streaming also includes a mechanism called checkpointing that saves state periodically to a reliable file system (e.g., HDFS or S3). Typically, you might set up checkpointing every 5–10 batches of data. When recovering lost data, Spark Streaming needs only to go Streaming in Apache Spark
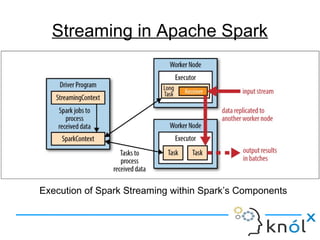
- 7. Execution of Spark Streaming within Spark’s Components Streaming in Apache Spark
- 8. Transformation Transformations apply some operation on current DStream and generate a new DStream. Transformations on DStreams can be grouped into either stateless or stateful: In stateless transformations the processing of each batch does not depend on the data of its previous batches. Stateful transformations, in contrast, use data or intermediate results from previous batches to compute the results of the current batch. They include transformations based on sliding windows and on tracking state across time.
- 10. Transformation on DStream Stateless Transformation
- 11. Stateful Transformations Stateful transformations are operations on DStreams that track data across time; that is, some data from previous batches is used to generate the results for a new batch. The two main types of Stateful Transformation are: Windowed Operations UpdateStateByKey
- 12. Stateful Transformation Windowed Transformations Windowed operations compute results across a longer time period than the StreamingContext’s batch interval, by combining results from multiple batches All windowed operations need two parameters, window duration and sliding duration, both of which must be a multiple of the StreamingContext’s batch interval. The window duration controls how many previous batches of data are considered
- 13. Stateful Transformation If we had a source DStream with a batch interval of 10 seconds and wanted to create a sliding window of the last 30 seconds(or last 3 batches) we would set the windowDuration to 30 seconds. The sliding duration, which defaults to the batch interval, controls how frequently the new DStream computes results. If we had the source DStream with a batch interval of 10 seconds and wanted to compute our window only on every second batch, we would set our sliding interval to 20 seconds.
- 14. Stateful Transformations UpdateStateByKey Transformations it’s useful to maintain state across the batches in a DStream . updateStateByKey() enables this by providing access to a state variable for DStreams of key/value pairs. Given a DStream of (key, event) pairs, it lets you construct a new DStream of (key, state) pairs by taking a function that specifies how to update the state for each key given new events. For example, in a web server log, our events might be visits to the site, where the key is the user ID. Using updateStateByKey(), we could track the last pages each user visited. This list would be our “state” object, and we’d update it as each event arrives.
- 15. Action/Output Operations Output operations specify what needs to be done with the final transformed data in a stream. Output Operations are similar to spark core. - print the output - save to text file - save as Object in File etc. It contains some extra methods like. forEachRdd()
- 16. Performance Considerations Spark Streaming applications have a few specialized tuning options. Batch and Window Sizes The most common question is what minimum batch size Spark Streaming can use. In general, 500 milliseconds has proven to be a good minimum size for many applications. The best approach is to start with a larger batch size (around 10 seconds) and work your way down to a smaller batch size. Level of Parallelism A common way to reduce the processing time of batches is to increase the parallelism.
- 17. Increasing the number of receivers Receivers can sometimes act as a bottleneck if there are too many records for a single machine to read in and distribute. You can add more receivers by creating multiple input DStreams (which creates multiple receivers), and then applying union to merge them into a single stream. Explicitly repartitioning received data If receivers cannot be increased anymore, you can further redistribute the received data by Performance Considerations
- 19. References Learning Spark LIGHTNING-FAST DATA ANALYSIS Holden Karau, Andy Konwinski, Patrick Wendell & Matei Zaharia http://spark.apache.org/streaming/
- 20. Thank You