






![Vector
• c(1, 2, 3, 4)
## [1] 1 2 3 4
• 1:4
## [1] 1 2 3 4
• c("a", "b", "c")
## [1] "a" "b" “c"
• c(T, F, T)
## [1] TRUE FALSE TRUE](https://image.slidesharecdn.com/sparkr-141128041703-conversion-gate01/85/Introduction-to-SparkR-8-320.jpg)
![Matrix
• matrix(c(1, 2, 3, 4), ncol=2)
## [,1] [,2]
## [1,] 1 3
## [2,] 2 4
• matrix(c(1, 2, 3, 4), ncol=2, byrow=T)
## [,1] [,2]
## [1,] 1 2
## [2,] 3 4](https://image.slidesharecdn.com/sparkr-141128041703-conversion-gate01/85/Introduction-to-SparkR-9-320.jpg)
![List
• list(12, “twelve")
## [[1]]
## [1] 12
##
## [[2]]
## [1] "twelve"](https://image.slidesharecdn.com/sparkr-141128041703-conversion-gate01/85/Introduction-to-SparkR-10-320.jpg)







![Word count
lines <- textFile(sc, “/path/to/file")
words <- flatMap(lines,
function(line) {
strsplit(line, " “)[[1]]
})
wordCount <- lapply(words, function(word) { list(word, 1L) })
counts <- reduceByKey(wordCount, "+", 2L)
output <- collect(counts)
for (wordcount in output) {
cat(wordcount[[1]], ": ", wordcount[[2]], “n")
}](https://image.slidesharecdn.com/sparkr-141128041703-conversion-gate01/85/Introduction-to-SparkR-19-320.jpg)
















Introduction to SparkR
- 1. Introduction to R and integration of SparkR and Spark’s MLlib Dang Trung Kien
- 2. About me • Statistics undergraduate • [email protected]
- 3. R
- 4. What is R? • Statistical Programming Language • Open source • > 6000 available packages • widely used in academics and research
- 6. Companies that use R • Facebook • Google • Foursquare • Ford • Bank of America • ANZ • …
- 7. Data types • Vector • Matrix • List • Data frame
- 8. Vector • c(1, 2, 3, 4) ## [1] 1 2 3 4 • 1:4 ## [1] 1 2 3 4 • c("a", "b", "c") ## [1] "a" "b" “c" • c(T, F, T) ## [1] TRUE FALSE TRUE
- 9. Matrix • matrix(c(1, 2, 3, 4), ncol=2) ## [,1] [,2] ## [1,] 1 3 ## [2,] 2 4 • matrix(c(1, 2, 3, 4), ncol=2, byrow=T) ## [,1] [,2] ## [1,] 1 2 ## [2,] 3 4
- 10. List • list(12, “twelve") ## [[1]] ## [1] 12 ## ## [[2]] ## [1] "twelve"
- 11. Data frame name <- c("A", "B", “C") age <- c(30, 17, 42) male <- c(T, F, F) data.frame(name, age, male) ## name age male ## 1 A 30 TRUE ## 2 B 17 FALSE ## 3 C 42 FALSE
- 12. x <- 1:100 y <- 1:100 + runif(100, 0, 20) m <- lm(y~x) plot(y~x) abline(m$coefficients)
- 14. But… • R is single-threaded • Can only process data sets that fit in a single machine
- 15. SparkR
- 16. SparkR • An R package that provides a light-weight front-end to use Apache Spark from R • exposes the RDD API of Spark as distributed lists in R • allows users to interactively run jobs from the R shell on a cluster
- 17. Spark count countByKey countByValue flatMap map (lapply) … broadcast includePackage … Filter reduce reduceByKey distinct union … + R
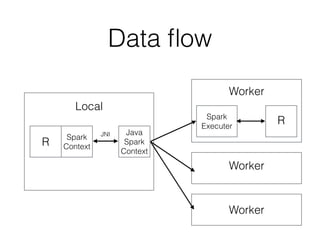
- 18. Data flow Local Worker Worker Worker R Spark Context Java Spark Context Spark R Executer JNI
- 19. Word count lines <- textFile(sc, “/path/to/file") words <- flatMap(lines, function(line) { strsplit(line, " “)[[1]] }) wordCount <- lapply(words, function(word) { list(word, 1L) }) counts <- reduceByKey(wordCount, "+", 2L) output <- collect(counts) for (wordcount in output) { cat(wordcount[[1]], ": ", wordcount[[2]], “n") }
- 20. SparkR and Spark’s MLlib
- 21. Machine Learning • Arthur Samuel (1959): Field of study that gives computers the ability to learn without being explicitly programmed.
- 22. Machine Learning • Supervised Labels, features Mapping of features to labels Estimate a concept (model) that is closest to the true mapping • Unsupervised No labels Clustering of data
- 23. Machine Learning • Supervised Naive Bayes, nearest neighbour, decision tree, linear regression, support vector machine… • Unsupervised K-means, DBSCAN, one-class SVM…
- 24. Supervised
- 25. Supervised • Classification Cat or dog?
- 26. Supervised • Classification Cat or dog? • Regression Age?
- 27. Unsupervised
- 28. Naive Bayes • Supervised machine learning • Classifies texts based on word frequency
- 29. Naive Bayes Π P(class | doc) = P(class) P(word | class) word in doc Π class argmax P(class | doc) = class argmax P(class) P(word | class) word in doc class argmax log(P(class | doc)) argmax log(P(class))+ Σ log(P(word | class)) class word in doc P(c) = number of class c documents in training sets total number of documents in training sets P(w | c) = no. of occurences of word w in documents type c + 1 total no. of words in documents type c + size of vocab
- 30. “a" “b” “c” 1 1 1 0 2 0 2 1 P(1) = P(2) = 1 2 P(a |1) = 1+1 1+1+ 3 = 2 5 P(b |1) = 2 5 P(c |1) = 1 5 P(a | 2) = 1 5 P(b | 2) = 3 5 P(c | 2) = 2 5 P(1| "a b b") = 1 2 × 2 5 × 2 5 × 2 5 = 0.032 P(2 | "a b b") = 1 2 × 1 5 × 3 5 × 3 5 = 0.036
- 31. MLlib • Spark’s scalable machine learning library consisting of common learning algorithms and utilities, including classification, regression, clustering, collaborative filtering, dimensionality reduction, as well as underlying optimization primitives.
- 32. MLlib and SparkR • Currently access to MLlib in SparkR is still in development. Thus use this method to run MLlib in R until MLlib is officially integrated into SparkR.
- 33. MLlib’s Naive Bayes in R R RDD of list(label, features) Java RDD of serialised R objects Scala RDD of LabeledPoint rJava J("org.apache.spark.mllib.classification.NaiveBayes", "train", labeled.point.rdd, lambda)
- 34. Demo
- 35. Thank you for coming!