Introduction to Stream Processing

Independent of the source of data, the integration of event streams into an Enterprise Architecture gets more and more important in the world of sensors, social media streams and Internet of Things. Events have to be accepted quickly and reliably, they have to be distributed and analyzed, often with many consumers or systems interested in all or part of the events. Storing such huge event streams into HDFS or a NoSQL datastore is feasible and not such a challenge anymore. But if you want to be able to react fast, with minimal latency, you can not afford to first store the data and doing the analysis/analytics later. You have to be able to include part of your analytics right after you consume the data streams. Products for doing event processing, such as Oracle Event Processing or Esper, are available for quite a long time and used to be called Complex Event Processing (CEP). In the past few years, another family of products appeared, mostly out of the Big Data Technology space, called Stream Processing or Streaming Analytics. These are mostly open source products/frameworks such as Apache Storm, Spark Streaming, Flink, Kafka Streams as well as supporting infrastructures such as Apache Kafka. In this talk I will present the theoretical foundations for Stream Processing, discuss the core properties a Stream Processing platform should provide and highlight what differences you might find between the more traditional CEP and the more modern Stream Processing solutions.























![Fault Tolerance: Delivery Guarantees
Introduction to Stream Processing
• At most once (fire-and-forget) - means the message is sent, but the sender
doesn’t care if it’s received or lost. Imposes no additional overhead to ensure
message delivery, such as requiring acknowledgments from consumers. Hence, it
is the easiest and most performant behavior to support.
• At least once - means that retransmission of a message will occur until an
acknowledgment is received. Since a delayed acknowledgment from the receiver
could be in flight when the sender retransmits the message, the message may be
received one or more times.
• Exactly once - ensures that a message is received once and only once, and is
never lost and never repeated. The system must implement whatever
mechanisms are required to ensure that a message is received and processed
just once
[ 0 | 1 ]
[ 1+ ]
[ 1 ]](https://image.slidesharecdn.com/introduction-to-stream-processing-v1-180925065707/85/Introduction-to-Stream-Processing-24-320.jpg)











































More Related Content
What's hot (20)
Similar to Introduction to Stream Processing (20)


















More from Guido Schmutz (20)




















Recently uploaded (20)

















![Pixologic ZBrush Crack Plus Activation Key [Latest 2025] New Version](https://cdn.slidesharecdn.com/ss_thumbnails/fashionevolution2-250322112409-f76abaa7-250428124909-b51264ff-250504160528-fc2bb1c5-thumbnail.jpg?width=560&fit=bounds)


Introduction to Stream Processing
- 1. BASEL BERN BRUGG DÜSSELDORF FRANKFURT A.M. FREIBURG I.BR. GENF HAMBURG KOPENHAGEN LAUSANNE MÜNCHEN STUTTGART WIEN ZÜRICH Introduction to Stream Processing Guido Schmutz DOAG Big Data 2018 – 20.9.2018 @gschmutz guidoschmutz.wordpress.com
- 2. Guido Schmutz Working at Trivadis for more than 21 years Oracle ACE Director for Fusion Middleware and SOA Consultant, Trainer Software Architect for Java, Oracle, SOA and Big Data / Fast Data Head of Trivadis Architecture Board Technology Manager @ Trivadis More than 30 years of software development experience Contact: [email protected] Blog: http://guidoschmutz.wordpress.com Slideshare: http://www.slideshare.net/gschmutz Twitter: gschmutz Introduction to Stream Processing
- 3. Agenda Introduction to Stream Processing 1. Motivation for Stream Processing? 2. Capabilities for Stream Processing 3. Implementing Stream Processing Solutions 4. Summary
- 4. Motivation for Stream Processing? Introduction to Stream Processing
- 5. Why not using Traditional BI Infrastructures? Enterprise Data Warehouse ETL / Stored Procedures Bulk Source DB Extract File DB Architekturen von Big Data Anwendungen BI Tools Search / Explore Enterprise Apps Logic { } API high latency
- 6. Bulk Source Hadoop Clusterd Hadoop Cluster Big Data Platform BI Tools Enterprise Data Warehouse SQL Search / Explore Parallel Processing Storage Storage RawRefined Results high latency Enterprise Apps Logic { } API File Import / SQL Import DB Extract File DB Big Data solves Volume and Variety – not Velocity Introduction to Stream Processing
- 7. Bulk Source Hadoop Clusterd Hadoop Cluster Big Data Platform BI Tools Enterprise Data Warehouse SQL Search / Explore Parallel Processing Storage Storage RawRefined Results high latency Enterprise Apps Logic { } API File Import / SQL Import DB Extract File DB Event Source Location Telemetry IoT Data Mobile Apps Social Big Data solves Volume and Variety – not Velocity Introduction to Stream Processing Event Stream
- 8. Bulk Source Hadoop Clusterd Hadoop Cluster Big Data Platform BI Tools Enterprise Data Warehouse SQL Search / Explore • Machine Learning • Graph Algorithms • Natural Language Processing Parallel Processing Storage Storage RawRefined Results high latency Enterprise Apps Logic { } API File Import / SQL Import DB Extract File DB Event Stream Event Source Location IoT Data Mobile Apps Social Big Data solves Volume and Variety – not Velocity Introduction to Stream Processing Event Hub Event Hub Event Hub Telemetry
- 9. Data Value Chain Milliseconds • Place Trace • Serve ad • Enrich Stream • Approve Trans Hundredths of Seconds • Calculate Risk • Leaderboard • Aggregate • Count Second(s) • Retrieve Click Stream • Show orders Minutes • Backtest algo • BI • Daily Reports Hours • Algo discovery • Log analysis • Fraud pattern match Architekturen von Big Data Anwendungen
- 10. "Data at Rest" vs. "Data in Motion" Data at Rest Data in Motion Store Act Analyze StoreAct Analyze 1110 1010 1010 110 1110 1010 1010 110 Introduction to Stream Processing
- 11. Typical Stream Processing Use Cases • Notifications and Alerting - a notification or alert should be triggered if some sort of event or series of events occurs. • Real-Time Reporting – run real-time dashboards that employees/customers can look at • Incremental ETL – still ETL, but not in Batch but in streaming, continuous mode • Update data to serve in real-time – compute data that get served interactively by other applications • Real-Time decision making – analyzing new inputs and responding to them automatically using business logic, i.e. Fraud Detection • Online Machine Learning – train a model on a combination of historical and streaming data and use it for real-time decision making Introduction to Stream Processing
- 12. When to Stream / When not? Introduction to Stream Processing Constant low Milliseconds & under Low milliseconds to seconds, delay in case of failures 10s of seconds of more, Re-run in case of failures Real-Time Near-Real-Time Batch Source: adapted from Cloudera
- 13. "No free lunch" Introduction to Stream Processing Constant low Milliseconds & under Low milliseconds to seconds, delay in case of failures 10s of seconds of more, Re-run in case of failures Real-Time Near-Real-Time Batch "Difficult" architectures, lower latency "Easier architectures", higher latency
- 14. Event Hub Event Hub Hadoop Clusterd Hadoop Cluster Stream Analytics Platform Stream Processing Architecture solves Velocity BI Tools Enterprise Data Warehouse Event Hub Search / Explore Enterprise Apps Search Results Stream Analytics Reference / Models Dashboard Logic { } API Event Stream Event Stream Event Stream Bulk Source Event Source Location DB Extract File DB IoT Data Mobile Apps Social Introduction to Stream Processing Low(est) latency, no history Telemetry
- 15. Hadoop Clusterd Hadoop Cluster Stream Analytics Platform Big Data for all historical data analysis BI Tools Enterprise Data Warehouse Search / Explore Enterprise Apps Search Results Stream Analytics Reference / Models Dashboard Logic { } API Event Stream Event Stream Hadoop Clusterd Hadoop Cluster Big Data Platform Parallel Processing Storage Storage RawRefined Results Data FlowEvent Hub Event Stream Bulk Source Event Source Location DB Extract File DB IoT Data Mobile Apps Social File Import / SQL Import Introduction to Stream Processing Telemetry
- 16. Data Store Integrate existing systems through CDC Data Event Hub Integration Consuming Systems StateLogic CDC CDC Connector Traditional Silo-based System LogicUser Interface Capture changes directly on database Change Data Capture (CDC) => think like a global database trigger Transform existing systems to event producer Event Stream Event Stream Introduction to Stream Processing
- 17. Hadoop Clusterd Hadoop Cluster Stream Analytics Platform Integrate existing systems with lower latency through CDC BI Tools Enterprise Data Warehouse Search / Explore Enterprise Apps Search Results Stream Analytics Reference / Models Dashboard Logic { } API Hadoop Clusterd Hadoop Cluster Big Data Platform Parallel Processing Storage Storage RawRefined Results File Import / SQL Import Event Stream Event Stream Data FlowEvent Hub Event Stream Bulk Source Event Source Location DB Extract File DB IoT Data Mobile Apps Social Introduction to Stream Processing Telemetry
- 18. New systems participate in event-oriented fashion Hadoop Clusterd Hadoop Cluster Big Data Platform Parallel Processing Storage Storage RawRefined Results Microservice Platform Microservice State { } API Stream Analytics Platform Stream Processor State { } API Event Stream SQL Search BI Tools Enterprise Data Warehouse Search / Explore Service Enterprise Apps Logic { } API File Import / SQL Import Event Stream Data FlowEvent Hub Event Stream Bulk Source Event Source Location DB Extract File DB IoT Data Mobile Apps Social Event Stream Event Stream Introduction to Stream Processing Telemetry
- 19. Edge computing allows processing close to data sources Hadoop Clusterd Hadoop Cluster Big Data Platform Parallel Processing Storage Storage RawRefined Results Microservice Platfrom Microservice State { } API Stream Analytics Platform Stream Processor State { } API SQL Search BI Tools Enterprise Data Warehouse Search / Explore Service Enterprise Apps Logic { } API Bulk Source Event Source Location DB Extract File DB IoT Data Mobile Apps Social Edge Node Rules Event Hub Storage File Import / SQL Import Event Hub Event Stream Event Stream Event Stream Introduction to Stream Processing Telemetry
- 20. Hadoop Clusterd Hadoop Cluster Big Data Unified Architecture for Modern Data Analytics Solutions SQL Search BI Tools Enterprise Data Warehouse Search / Explore File Import / SQL Import Event Hub Parallel Processing Storage Storage RawRefined Results Microservice State { } API Stream Processor State { } API Event Stream Event Stream Service Stream Analytics Microservices Enterprise Apps Logic { } API Edge Node Rules Event Hub Storage Bulk Source Event Source Location DB Extract File DB IoT Data Mobile Apps Social Event Stream Telemetry
- 21. Two Types of Stream Processing (from Gartner) Introduction to Stream Processing Stream Data Integration • primarily focuses on the ingestion and processing of data sources targeting real- time extract-transform-load (ETL) and data integration use cases • filter and enrich the data • optionally calculate time-windowed aggregations before storing the results in a database or file system Stream Analytics • targets analytics use cases • calculating aggregates and detecting patterns to generate higher-level, more relevant summary information (complex events) • Complex events may signify threats or opportunities that require a response from the business through real-time dashboards, alerts or decision automation
- 22. Introduction to Stream Processing Important Capabilities for Stream Processing
- 23. Streaming Model: Event-at-a-time vs. Micro Batch Introduction to Stream Processing Event-at-a-time Processing • Events processed as they arrive • low-latency • fault tolerance expensive Micro-Batch Processing • Splits incoming stream in small batches • Fault tolerance easier • Better throughput
- 24. Fault Tolerance: Delivery Guarantees Introduction to Stream Processing • At most once (fire-and-forget) - means the message is sent, but the sender doesn’t care if it’s received or lost. Imposes no additional overhead to ensure message delivery, such as requiring acknowledgments from consumers. Hence, it is the easiest and most performant behavior to support. • At least once - means that retransmission of a message will occur until an acknowledgment is received. Since a delayed acknowledgment from the receiver could be in flight when the sender retransmits the message, the message may be received one or more times. • Exactly once - ensures that a message is received once and only once, and is never lost and never repeated. The system must implement whatever mechanisms are required to ensure that a message is received and processed just once [ 0 | 1 ] [ 1+ ] [ 1 ]
- 25. API Introduction to Stream Processing Compositional / Programmatic • Highly customizable operator based on basic building blocks • Manual topology definition and optimization Declarative • High-Level, fluent API • Higher order function as operators (filter, mapWithState …) • Logical plan optimization SQL • Query language allowing to use stream in FROM clause • Extensions supporting windowing, pattern matching, spatial, …. Operators • SELECT * FROM <stream> WHERE f1 = 10
- 26. Windowing Introduction to Stream Processing Computations over events done using windows of data Due to size and never-ending nature of it, it’s not feasible to keep entire stream of data in memory A window of data represents a certain amount of data where we can perform computations on Windows give the power to keep a working memory and look back at recent data efficiently Time Stream of Data Window of Data
- 27. Sliding Window (aka Hopping Window) - uses eviction and trigger policies that are based on time: window length and sliding interval length Fixed Window (aka Tumbling Window) - eviction policy always based on the window being full and trigger policy based on either the count of items in the window or time Session Window – composed of sequences of temporarily related events terminated by a gap of inactivity greater than some timeout Windowing Introduction to Stream Processing Time TimeTime
- 28. Joining Introduction to Stream Processing Challenges of joining streams 1. Data streams need to be aligned as they come because they have different timestamps 2. since streams are never-ending, the joins must be limited; otherwise join will never end 3. join needs to produce results continuously as there is no end to the data Stream to Static (Table) Join Stream to Stream Join (one window join) Stream to Stream Join (two window join) Stream- to-Static Join Stream- to-Stream Join Stream- to-Stream Join Time Time Time
- 29. Pattern Detection Introduction to Stream Processing • Streaming Data often contains interesting patterns that only emerge as new streaming data arrives, e.g. • Absence Pattern: event A not followed by event B within time window • Sequence Pattern: event A followed by event B followed by event C • Increasing Pattern: up trend of a value of a certain attribute • Decreasing Pattern: down trend of a value of a certain attribute • … • Pattern operators allow developers to define complex relationships between streaming events
- 30. State Management Introduction to Stream Processing Necessary if stream processing use case is dependent on previously seen data or external data Windowing, Joining and Pattern Detection use State Management behind the scenes State Management services can be made available for custom state handling logic State needs to be managed as close to the stream processor as possible Options for State Management How does it handle failures? If a machine crashes and the/some state is lost? In-Memory Replicated, Distributed Store Local, Embedded Store Operational Complexity and Features Low high
- 31. Queryable State (aka. Interactive Queries) Introduction to Stream Processing Exposes the state managed by the Stream Analytics solution to the outside world Allows an application to query the managed state, i.e. to visualize it For some scenarios, Queryable State can eliminate the need for an external database to keep results Stream Processing Cluster Reference Data Stream Analytics { } Query API State Stream Processor Search / Explore Online & Mobile Apps Model Dashboard
- 32. Event Time vs. Ingestion Time vs. Processing Time Introduction to Stream Processing Event time • the time at which events actually occurred Ingestion time / Processing Time • the time at which events are ingested / observed in the system Not all use cases care about event times but many do Examples • characterizing user behavior over time • most billing applications • anomaly detection
- 33. Capabilities: Stream Data Integration vs. Stream Analytics Introduction to Stream Processing Stream Data Integration Stream Analytics Support for Various Data Sources Yes (yes) Streaming ETL (Transformation, Routing, Validation) yes (yes) Format Translation yes (yes) Micro-Batching yes (yes) Auto Scaling yes Backpressure Support yes - Processing Time vs. Event Time - yes Stream-to-Static Joins (Lookup/Enrichment) yes yes Stream-to-Stream Joins - yes Windowing - yes State Management - yes Queryable State (aka Interactive Queries) - yes Streaming SQL (yes) yes Event Pattern Matching / Detection - Yes
- 34. Implementing Stream Processing Solutions Introduction to Stream Processing
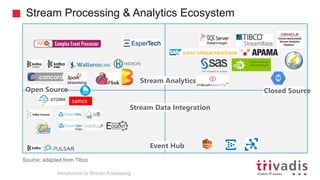
- 35. Stream Processing & Analytics Ecosystem Stream Analytics Event Hub Open Source Closed Source Stream Data Integration Source: adapted from Tibco Edge Introduction to Stream Processing
- 36. Summary Introduction to Stream Processing
- 37. Summary Introduction to Stream Processing Stream Processing is the solution for low-latency Event Hub, Stream Data Integration and Stream Analytics are the main building blocks in your architecture Kafka is currently the de-facto standard for Event Hub Various options exists for Stream Data Integration and Stream Analytics SQL becomes a valid option for implementing Stream Analytics Still room for improvements (SQL, Event Pattern Detection, Streaming Machine Learning)
- 38. Introduction to Stream Processing Technology on its own won't help you. You need to know how to use it properly.