Introduction to the Hadoop Ecosystem (FrOSCon Edition)
10 likes6,597 views

The document is an introduction to the Hadoop ecosystem presented at an event in Sankt Augustin. It covers topics such as the importance of big data, the Hadoop framework, its architecture, and various components like HDFS, MapReduce, Apache Pig, and Apache Hive. The document also discusses the evolution of Hadoop 2.0 and its resource management capabilities with YARN.













































































Introduction to the Hadoop Ecosystem (FrOSCon Edition)
- 1. Sankt Augustin 24-25.08.2013 Introduction to the Hadoop Ecosystem uweseiler
- 2. Sankt Augustin 24-25.08.2013 About me Big Data Nerd TravelpiratePhotography Enthusiast Hadoop Trainer MongoDB Author
- 3. Sankt Augustin 24-25.08.2013 About us is a bunch of… Big Data Nerds Agile Ninjas Continuous Delivery Gurus Enterprise Java Specialists Performance Geeks Join us!
- 4. Sankt Augustin 24-25.08.2013 Agenda • What is Big Data & Hadoop? • Core Hadoop • The Hadoop Ecosystem • Use Cases • What‘s next? Hadoop 2.0!
- 5. Sankt Augustin 24-25.08.2013 Why Big Data? The volume of datasets is constantly growing…
- 6. Sankt Augustin 24-25.08.2013 Volume 2008 200 PB a day 2009 2,5 PB user data 15 TB a day 2009 6,5 PB User Data 50 TB a day 2011 ~200 PB Data
- 7. Sankt Augustin 24-25.08.2013 Why Big Data? The velocity of data generation is getting faster and faster…
- 9. Sankt Augustin 24-25.08.2013 Why Big Data? The variety of data is increasing…
- 10. Sankt Augustin 24-25.08.2013 Variety Structur ed data Semi- structur ed data Unstruct ured data
- 11. Sankt Augustin 24-25.08.2013 The 3 V’s of Big Data VarietyVolume Velocity
- 12. Sankt Augustin 24-25.08.2013 My favorite definition
- 13. Sankt Augustin 24-25.08.2013 Why Hadoop? TraditionaldataStoresare expensive to scale and by Design difficult to Distribute Scale out is the way to go!
- 14. Sankt Augustin 24-25.08.2013 How to scale data? “Data“ r r “Result“ w w worker workerworker w r
- 15. Sankt Augustin 24-25.08.2013 But… Parallel processing is complicated!
- 16. Sankt Augustin 24-25.08.2013 But… Data storage is not trivial!
- 17. Sankt Augustin 24-25.08.2013 What is Hadoop? Distributed Storage and Computation Framework
- 18. Sankt Augustin 24-25.08.2013 What is Hadoop? «Big Data» != Hadoop
- 19. Sankt Augustin 24-25.08.2013 What is Hadoop? Hadoop != Database
- 20. Sankt Augustin 24-25.08.2013 What is Hadoop?
- 21. Sankt Augustin 24-25.08.2013 What is Hadoop? “Swiss army knife of the 21st century” http://www.guardian.co.uk/technology/2011/mar/25/media-guardian-innovation-awards-apache-hadoop
- 22. Sankt Augustin 24-25.08.2013 The Hadoop App Store HDFS MapRed HCat Pig Hive HBase Ambari Avro Cassandra Chukwa Intel Sync Flume Hana HyperT Impala Mahout Nutch Oozie Scoop Scribe Tez Vertica Whirr ZooKee Horton Cloudera MapR EMC IBM Talend TeraData Pivotal Informat Microsoft. Pentaho Jasper Kognitio Tableau Splunk Platfora Rack Karma Actuate MicStrat
- 23. Sankt Augustin 24-25.08.2013 Functionalityless more Apache Hadoop Hadoop Distributions Big Data Suites • HDFS • MapReduce • Hadoop Ecosystem • Hadoop YARN • Test & Packaging • Installation • Monitoring • Business Support + • Integrated Environment • Visualization • (Near-)Realtime analysis • Modeling • ETL & Connectors + The Hadoop App Store
- 24. Sankt Augustin 24-25.08.2013 The essentials … Core Hadoop
- 25. Sankt Augustin 24-25.08.2013 Data Storage OK, first things first! I want to store all of my <<Big Data>>
- 26. Sankt Augustin 24-25.08.2013 Data Storage
- 27. Sankt Augustin 24-25.08.2013 Hadoop Distributed File System • Distributed file system for redundant storage • Designed to reliably store data on commodity hardware • Built to expect hardware failures
- 28. Sankt Augustin 24-25.08.2013 Hadoop Distributed File System Intended for • large files • batch inserts
- 29. Sankt Augustin 24-25.08.2013 HDFS Architecture NameNode Master Block Map Slave Slave Slave Rack 1 Rack 2 Journal Log DataNode DataNode DataNode File Client Secondary NameNode Helper periodical merges #1 #2 #1 #1 #1
- 30. Sankt Augustin 24-25.08.2013 Data Processing Data stored, check! Now I want to create insights from my data!
- 31. Sankt Augustin 24-25.08.2013 Data Processing
- 32. Sankt Augustin 24-25.08.2013 MapReduce • Programming model for distributed computations at a massive scale • Execution framework for organizing and performing such computations • Data locality is king
- 33. Sankt Augustin 24-25.08.2013 Typical large-data problem • Iterate over a large number of records • Extract something of interest from each • Shuffle and sort intermediate results • Aggregate intermediate results • Generate final output MapReduce
- 34. Sankt Augustin 24-25.08.2013 MapReduce Flow Combine Combine Combine Combine a b 2 c 9 a 3 c 2 b 7 c 8 Partition Partition Partition Partition Shuffle and Sort Map Map Map Map a b 2 c 3 c 6 a 3 c 2 b 7 c 8 a 1 3 b 7 c 2 8 9 Reduce Reduce Reduce a 4 b 9 c 19
- 35. Sankt Augustin 24-25.08.2013 Combined Hadoop Architecture Client NameNode Master Slave TaskTracker Secondary NameNode Helper JobTracker DataNode File Job Block Task Slave TaskTracker DataNode Block Task Slave TaskTracker DataNode Block Task
- 36. Sankt Augustin 24-25.08.2013 Word Count Mapper in Java public class WordCountMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); output.collect(word, one); } } }
- 37. Sankt Augustin 24-25.08.2013 Word Count Reducer in Java public class WordCountReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator values, OutputCollector output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { IntWritable value = (IntWritable) values.next(); sum += value.get(); } output.collect(key, new IntWritable(sum)); } }
- 38. Sankt Augustin 24-25.08.2013 Scripting for Hadoop Java for MapReduce? I dunno, dude… I’m more of a scripting guy…
- 39. Sankt Augustin 24-25.08.2013 Scripting for Hadoop
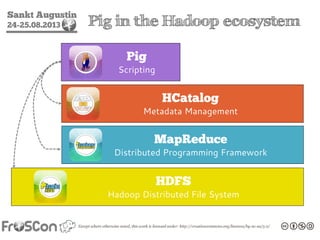
- 40. Sankt Augustin 24-25.08.2013 Apache Pig • High-level data flow language • Made of two components: • Data processing language Pig Latin • Compiler to translate Pig Latin to MapReduce
- 41. Sankt Augustin 24-25.08.2013 Pig in the Hadoop ecosystem HDFS Hadoop Distributed File System MapReduce Distributed Programming Framework HCatalog Metadata Management Pig Scripting
- 42. Sankt Augustin 24-25.08.2013 Pig Latin users = LOAD 'users.txt' USING PigStorage(',') AS (name, age); pages = LOAD 'pages.txt' USING PigStorage(',') AS (user, url); filteredUsers = FILTER users BY age >= 18 and age <=50; joinResult = JOIN filteredUsers BY name, pages by user; grouped = GROUP joinResult BY url; summed = FOREACH grouped GENERATE group, COUNT(joinResult) as clicks; sorted = ORDER summed BY clicks desc; top10 = LIMIT sorted 10; STORE top10 INTO 'top10sites';
- 43. Sankt Augustin 24-25.08.2013 Pig Execution Plan
- 44. Sankt Augustin 24-25.08.2013 Try that with Java…
- 45. Sankt Augustin 24-25.08.2013 SQL for Hadoop OK, Pig seems quite useful… But I’m more of a SQL person…
- 46. Sankt Augustin 24-25.08.2013 SQL for Hadoop
- 47. Sankt Augustin 24-25.08.2013 Apache Hive • Data Warehousing Layer on top of Hadoop • Allows analysis and queries using a SQL-like language
- 48. Sankt Augustin 24-25.08.2013 Hive in the Hadoop ecosystem HDFS Hadoop Distributed File System MapReduce Distributed Programming Framework HCatalog Metadata Management Pig Scripting Hive Query
- 49. Sankt Augustin 24-25.08.2013 Hive Architecture Hive Hive Engine HDFS MapReduce Meta- store Thrift Applications JDBC Applications ODBC Applications Hive Thrift Driver Hive JDBC Driver Hive ODBC Driver Hive Server Hive Shell
- 50. Sankt Augustin 24-25.08.2013 Hive Example CREATE TABLE users(name STRING, age INT); CREATE TABLE pages(user STRING, url STRING); LOAD DATA INPATH '/user/sandbox/users.txt' INTO TABLE 'users'; LOAD DATA INPATH '/user/sandbox/pages.txt' INTO TABLE 'pages'; SELECT pages.url, count(*) AS clicks FROM users JOIN pages ON (users.name = pages.user) WHERE users.age >= 18 AND users.age <= 50 GROUP BY pages.url SORT BY clicks DESC LIMIT 10;
- 51. Sankt Augustin 24-25.08.2013 But there’s still more… More components of the Hadoop Ecosystem
- 52. Sankt Augustin 24-25.08.2013 HDFS Data storage MapReduce Data processing HCatalog Metadata Management Pig Scripting Hive SQL-like queries HBase NoSQLDatabase Mahout Machine Learning ZooKeeper ClusterCoordination Scoop Import & Export of relational data Ambari Clusterinstallation&management Oozie Workflowautomatization Flume Import & Export of data flows
- 53. Sankt Augustin 24-25.08.2013 Bringing it all together… Use Cases
- 54. Sankt Augustin 24-25.08.2013DataSourcesDataSystemsApplications Traditional Sources RDBMS OLTP OLAP … Traditional Systems RDBMS EDW MPP … Business Intelligence Business Applications Custom Applications Operation Manage & Monitor Dev Tools Build & Test Classical enterprise platform
- 55. Sankt Augustin 24-25.08.2013DataSourcesDataSystemsApplications Traditional Sources RDBMS OLTP OLAP … Traditional Systems RDBMS EDW MPP … Business Intelligence Business Applications Custom Applications Operation Manage & Monitor Dev Tools Build & Test New Sources Logs Mails Sensor …Social Media Enterprise Hadoop Plattform Big Data Platform
- 56. Sankt Augustin 24-25.08.2013 DataSourcesDataSystemsApplications Traditional Sources RDBMS OLTP OLAP … Traditional Systems RDBMS EDW MPP … Business Intelligence Business Applications Custom Applications New Sources Logs Mails Sensor …Social Media Enterprise Hadoop Plattform 1 2 3 4 1 2 3 4 Capture all data Process the data Exchange using traditional systems Process & Visualize with traditional applications Pattern #1: Refine data
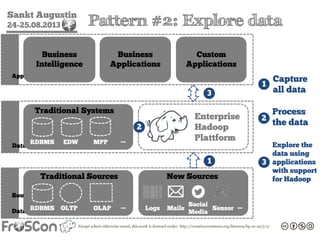
- 57. Sankt Augustin 24-25.08.2013 DataSourcesDataSystemsApplications Traditional Sources RDBMS OLTP OLAP … Traditional Systems RDBMS EDW MPP … Business Intelligence Business Applications Custom Applications New Sources Logs Mails Sensor …Social Media Enterprise Hadoop Plattform 1 2 3 1 2 3 Capture all data Process the data Explore the data using applications with support for Hadoop Pattern #2: Explore data
- 58. Sankt Augustin 24-25.08.2013 DataSourcesDataSystemsApplications Traditional Sources RDBMS OLTP OLAP … Traditional Systems RDBMS EDW MPP … Business Applications Custom Applications New Sources Logs Mails Sensor …Social Media Enterprise Hadoop Plattform 1 3 1 2 3 Capture all data Process the data Directly ingest the data Pattern #3: Enrich data 2
- 59. Sankt Augustin 24-25.08.2013 Bringing it all together… One example…
- 60. Sankt Augustin 24-25.08.2013 Digital Advertising • 6 billion ad deliveries per day • Reports (and bills) for the advertising companies needed • Own C++ solution did not scale • Adding functions was a nightmare
- 61. Sankt Augustin 24-25.08.2013 Campaign Database FFM AMS TCP Interface TCP Interface Custom Flume Source Custom Flume Source Flume HDFS Sink Local files Campaign Data Hadoop Cluster Binary Log Format Synchronisation Pig Hive Temporäre Daten NAS Aggregated data Report Engine Direct Download Job Scheduler Config UI Job Config XML Start AdServer AdServer AdServing Architecture
- 62. Sankt Augustin 24-25.08.2013 What’s next? Hadoop 2.0 aka YARN
- 63. Sankt Augustin 24-25.08.2013 HDFS Hadoop 1.0 Built for web-scale batch apps HDFS HDFS Single App Batch Single App Batch Single App Batch Single App Batch Single App Batch
- 64. Sankt Augustin 24-25.08.2013 MapReduce is good for… • Embarrassingly parallel algorithms • Summing, grouping, filtering, joining • Off-line batch jobs on massive data sets • Analyzing an entire large dataset
- 65. Sankt Augustin 24-25.08.2013 MapReduce is OK for… • Iterative jobs (i.e., graph algorithms) • Each iteration must read/write data to disk • I/O and latency cost of an iteration is high
- 66. Sankt Augustin 24-25.08.2013 MapReduce is not good for… • Jobs that need shared state/coordination • Tasks are shared-nothing • Shared-state requires scalable state store • Low-latency jobs • Jobs on small datasets • Finding individual records
- 67. Sankt Augustin 24-25.08.2013 MapReduce limitations • Scalability – Maximum cluster size ~ 4,500 nodes – Maximum concurrent tasks – 40,000 – Coarse synchronization in JobTracker • Availability – Failure kills all queued and running jobs • Hard partition of resources into map & reduce slots – Low resource utilization • Lacks support for alternate paradigms and services – Iterative applications implemented using MapReduce are 10x slower
- 68. Sankt Augustin 24-25.08.2013 Hadoop 1.0 HDFS Redundant, reliable storage Hadoop 2.0: Next-gen platform MapReduce Cluster resource mgmt + data processing Hadoop 2.0 HDFS 2.0 Redundant, reliable storage MapReduce Data processing Single use system Batch Apps Multi-purpose platform Batch, Interactive, Streaming, … YARN Cluster resource management Others Data processing
- 69. Sankt Augustin 24-25.08.2013 YARN: Taking Hadoop beyond batch Applications run natively in Hadoop HDFS 2.0 Redundant, reliable storage Batch MapReduce Store all data in one place Interact with data in multiple ways YARN Cluster resource management Interactive Tez Online HOYA Streaming Storm, … Graph Giraph In-Memory Spark Other Search, …
- 70. Sankt Augustin 24-25.08.2013 A brief history of YARN • Originally conceived & architected by the team at Yahoo! – Arun Murthy created the original JIRA in 2008 and now is the YARN release manager • The team at Hortonworks has been working on YARN for 4 years: – 90% of code from Hortonworks & Yahoo! • YARN based architecture running at scale at Yahoo! – Deployed on 35,000 nodes for 6+ months • Going GA at the end of 2013?
- 71. Sankt Augustin 24-25.08.2013 YARN concepts • Application – Application is a job submitted to the framework – Example: Map Reduce job • Container – Basic unit of allocation – Fine-grained resource allocation across multiple resources (memory, CPU, disk, network, GPU, …) • container_0 = 2GB, 1CPU • container_1 = 1GB, 6 CPU – Replaces the fixed map/reduce slots
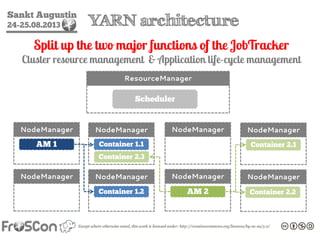
- 72. Sankt Augustin 24-25.08.2013 YARN architecture Split up the two major functions of the JobTracker Cluster resource management & Application life-cycle management ResourceManager NodeManager NodeManager NodeManager NodeManager NodeManager NodeManager NodeManager NodeManager Scheduler AM 1 Container 1.2 Container 1.1 AM 2 Container 2.1 Container 2.2 Container 2.3
- 73. Sankt Augustin 24-25.08.2013 YARN architecture • Resource Manager – Global resource scheduler – Hierarchical queues • Node Manager – Per-machine agent – Manages the life-cycle of container – Container resource monitoring • Application Master – Per-application – Manages application scheduling and task execution – e.g. MapReduce Application Master
- 74. Sankt Augustin 24-25.08.2013 YARN architecture ResourceManager NodeManager NodeManager NodeManager NodeManager NodeManager NodeManager NodeManager NodeManager Scheduler MapReduce 1 map 1.2 map 1.1 MapReduce 2 map 2.1 map 2.2 reduce 2.1 NodeManager NodeManager NodeManager NodeManager reduce 1.1 Tez map 2.3 reduce 2.2 vertex 1 vertex 2 vertex 3 vertex 4 HOYA HBase Master Region server 1 Region server 2 Region server 3 Storm nimbus 1 nimbus 2
- 75. Sankt Augustin 24-25.08.2013 YARN summary 1. Scale 2. New programming models & Services 3. Improved cluster utilization 4. Agility 5. Beyond Java
- 76. Sankt Augustin 24-25.08.2013 Getting started… One more thing…
- 77. Sankt Augustin 24-25.08.2013 User Groups HUG Rhein-Ruhr (Düsseldorf) – https://www.xing.com/net/hugrheinruhr/ HUG Rhein-Main (Frankfurt) – https://www.xing.com/net/hugrheinmain/ – http://www.meetup.com/HUG-Rhein-Main/ Big Data Beers (Berlin) – http://www.meetup.com/Big-Data-Beers/ HUG München – http://www.meetup.com/Hadoop-User-Group-Munich/ HUG Karlsruhe/Stuttgart – http://www.meetup.com/Hadoop-and-Big-Data-User-Group-in-Karlsruhe-Stuttgart/
- 78. Sankt Augustin 24-25.08.2013 Books about Hadoop Hadoop, The Definite Guide; Tom White; 3rd ed.; O’Reilly; 2012. Hadoop in Action; Chuck Lam; Manning; 2011. Programming Pig; Alan Gates; O’Reilly; 2011. Hadoop Operations; Eric Sammer; O’Reilly; 2012.
- 79. Sankt Augustin 24-25.08.2013 Hortonworks Sandbox http://hortonworks.com/products/hortonworsk-sandbox
- 80. Sankt Augustin 24-25.08.2013 Hadoop Training • Programming with Hadoop • 4-day class • 16.09. – 19.09.2013, München • 28.10. – 31.10.2013, Frankfurt • 02.12. – 05.12.2013, Düsseldorf • Administration of Hadoop • 3-day class • 23. – 25.09.2013, München • 04. – 06.11.2013, Frankfurt • 09. – 11.12.2013, Düsseldorf http://www.codecentric.de/portfolio/schulungen-und-workshops