Introdution to Dataops and AIOps (or MLOps)
12 likes1,779 views

This presentation introduces the audience to the DataOps and AIOps practices. It deals with organizational & tech aspects, and provide hints to start you data journey.




































![Matrix organization & serendipity
This matrix organization (transversal datasets owned by the Datahub, securely shared to several isolated
usecases) enable to factorize the work (so raise your dataset ROI). Each time a usecase team needs a new
dataset, it should be capitalized by integratin the data catalog owned by the datahub (see the central team’s
value ?)
Serendipity: by having a clear understanding of your data patrimony, you can valorize it of course, but it may
also help to give new ideas! “Since I’ve this data, and this one, so I may be able to [your_new_idea_here]”
“If only HP knew what HP knows, we'd be three times more productive”
- Lew Platt, former CEO of Hewlett-Packard
Dataset #1 Dataset #2 Dataset #3 Dataset #4
Usecase #1
Usecase #2
Usecase #3
Data Catalog](https://image.slidesharecdn.com/webinardataops-200804101136/85/Introdution-to-Dataops-and-AIOps-or-MLOps-39-320.jpg)

![Data engineering vs Data Science
[80%]
of a data project is roughly about
data aquisition/preparation/sharing
(data engineering)
[20%]
of a data project is roughly about
data valorization
(data science, data analytics)
→ Your datascientists generally spend most of their time at doing data engineering empirically
when a clear data engineer position doesn’t exist in your organization!
- It’s not very efficient (as datascientists costs much more than data engineers and are difficult to hire)
- They generally doesn’t like this activity (and may leave your company at the end!)
- Happens regularly: two datascientists using same data for different usecases will probably create 2 identical
ingestion/preparation pipelines for their projects (you miss a factorization effect)](https://image.slidesharecdn.com/webinardataops-200804101136/85/Introdution-to-Dataops-and-AIOps-or-MLOps-41-320.jpg)




































Ad
More Related Content
What's hot (20)
Similar to Introdution to Dataops and AIOps (or MLOps) (20)


















Ad
More from Adrien Blind (20)





![Docker, cornerstone of cloud hybridation ? [Cloud Expo Europe 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/dockercloudhybridationv2-161129152507-thumbnail.jpg?width=560&fit=bounds)














Ad
Recently uploaded (20)




















Introdution to Dataops and AIOps (or MLOps)
- 1. An introduction to DataOps & AIOps (or MLOps) Adrien Blind (@adrienblind) Disclaimer and credits: Parts of this presentation have been built with former team mates out of the context of Saagie: - a broader talk initially co-developed and co-delivered along with Frederic Petit for DevOps D-Day and Snow Camp conferences. Original slides here: https://bit.ly/2Ci3Ilh - a talk discussing Continuous Delivery and DevOps, co-developed and co-delivered along with Laurent Dussault for DevOps Rex conferences. Slides here: https://bit.ly/2CmEIcB
- 5. The point is to Operationalize data projects Proof of Concept Operational product ● Robust, resilient ● Scalable ● Secure ● Updatable ● Shareable
- 6. Value is hard to demonstrate Long time to implement Rarely deployed in production Only 27% of CxO considered their Big Data projects valuable 12 to 18 months to build and deploy AI pilots Only 15% of AI projects have been deployed Sources Gartner’s CIO Survey (2018) The Big Data Payoff: Turning Big Data into Business Value (Cap Gemini and Informatica survey, 2016) BCG, Putting Artificial Intelligence to Work, September 2017 Challenges delivering value from Big Data / AI
- 7. Fragmented & ever-changing landscape: thousand-piece puzzle, always changing Challenges ㅡ Technology
- 8. DIY, time/budget-consuming, multi-skills, high-risk approach Grant access Connect databases / files Integrate data frameworks Deploy test jobs & validate models Define new policies Change algos and integrate new libs Rewrite/build ETL codes to prod Deploy prod jobs Monitor & audit activity Write/Build ML codes Write/Build ETL codes Provision cluster(s) Align processes w/ business reqs Rewrite/build ML codes to prod Challenges ㅡ Process SecurityIT Ops Data Engineer IT Ops Data Scientist Data Engineer Data Scientist IT Ops IT Ops Data ScientistData Engineer Data Steward Business Analyst
- 9. Barriers between organization : silos and different cultures! Challenges ㅡ People & organization Data Analyst Data Steward BUSINESS Data Analyst Data Steward ANALYTICS TEAM Data Engineer Data Scientists IT IT Ops IT Architect & Coders
- 10. But… Nothing new under the sun?
- 11. How DevOps solved it for app landscape? Manual processing Have a look on the complete DevOps introduction here: https://bit.ly/3gE5Hj4
- 12. Back on DevOps: “You build it, you run it” Strong automation Have a look on the complete Devops introduction here: https://bit.ly/3gE5Hj4
- 13. ITOps, DevOps, DataOps AIOPs (or MLOps)… The point is about operationalization of several topics!
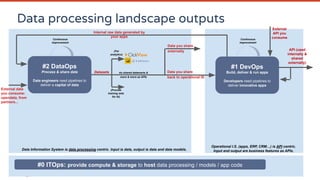
- 14. Information Technology (on premises, cloud, etc.) #0 ITOps: provide compute & storage to host data processing / models / app code Infrastructure landscape: infrastructure driven
- 15. #1 DevOps Build, deliver & run apps Developers need pipelines to deliver innovative apps Continuous improvement #0 ITOps: provide compute & storage to host data processing / models / app code API (used internally & shared externally) External API you consume Operational I.S. (apps, ERP, CRM…) is API centric. Input and output are business features as APIs. Application landscape: API driven Information Technology (on premises, cloud, etc.)
- 16. #1 DevOps Build, deliver & run apps Developers need pipelines to deliver innovative apps #2 DataOps Process & share data Data engineers need pipelines to deliver a capital of data Internal raw data generated by your apps Continuous improvement Continuous improvement Information Technology (on premises, cloud, etc.) #0 ITOps: provide compute & storage to host data processing / models / app code API (used internally & shared externally) External data you consume: opendata, from partners... External API you consume Data Information System is data processing centric. Input is data, output is data and data models. Generally not directly plugged on the operational IS (you copy data and process there) Operational I.S. (apps, ERP, CRM…) is API centric. Input and output are business features as APIs. Data processing landscape: data driven
- 17. #1 DevOps Build, deliver & run apps Developers need pipelines to deliver innovative apps #2 DataOps Process & share data Data engineers need pipelines to deliver a capital of data (For analytics) As shared datamarts & more & more as APIs (Provide training sets for AI) Internal raw data generated by your apps Datasets Continuous improvement Continuous improvement #0 ITOps: provide compute & storage to host data processing / models / app code API (used internally & shared externally) External data you consume: opendata, from partners... Data you share externally Data you share back to operational IS External API you consume Operational I.S. (apps, ERP, CRM…) is API centric. Input and output are business features as APIs.Data Information System is data processing centric. Input is data, output is data and data models. Data processing landscape outputs
- 18. #3 AIOPs Explore & build models Data scientists need pipelines to deliver valuable models #1 DevOps Build, deliver & run apps Developers need pipelines to deliver innovative apps #2 DataOps Process & share data Data engineers need pipelines to deliver a capital of data Continuous improvement (For analytics) Performance drift analysis (to retrain & optimize models) As shared datamarts & more & more as APIs (Provide training sets) Internal raw data generated by your apps Models to be bundled and ran as APIs in the operational IS Datasets Continuous improvement Continuous improvement Information Technology (on premises, cloud, etc.) #0 ITOps: provide compute & storage to host data processing / models / app code API (used internally & shared externally) External data you consume: opendata, from partners... Data you share externally Data you share back to operational IS External API you consume Operational I.S. (apps, ERP, CRM…) is API centric. Input and output are business features as APIs.Data Information System is data processing centric. Input is data, output is data and data models. Data science landscape: model driven
- 19. AIOPs needs DataOps In the data landscape, spotlights are on data analytics, and even more on data science/AI which valorize data in a revolutionary way… because they solve business challenges. … But it requires to have built up a data capital to process first! Said differently, I like to say that… ( of AI ) ( DATA )
- 20. Summary: Pensé par les Devs… Pansé par les Ops! Tech side Non-tech side #0 ITOps ITOps operationalizes the delivery of infrastructure assets. The purpose is to deliver an underlying platform on top of which assets will be hosted (apps/data processing/ML). CloudOps lands here, but is opinionated on the way to achieve this. Fosters collaboration between Infrastructure teams working in project mode to deliver new assets, and those running them (support/run/monitoring, etc.). #1 DevOps DevOps operationalizes the delivery of app code (automates, measure, etc.). The purpose is to deliver innovative services to the business. Fosters collaboration between devs who build apps, and ops responsible to deploying & running these apps. “You build it, you run it!” #2 DataOps DataOps operationalizes the setup of of data (automates data processing). The purpose is to deliver/shape a capital (of data). Fosters collaboration between data engineers who own and shape the data, and ops deploying the underlying data processing jobs. #3 AIOPs AIOPs operationalizes the delivery of models. The purpose is to deliver value. Fosters collaboration between datascientists who explore data to build up models, and ops delivering these as useable asset. Designed by devs, bandaged by the Ops (less fun in english) So, what about BizDevOps, ITSecOps, DevFinOps, etc.? Business, Security, Finance, etc. are transversal interlocutors / topics which are to be addressed anyway, whatever we’re speaking about DevOps, DataOps or AIOPs.
- 21. Focus on DataOps
- 22. Agile & DevOps are not enough for data projects Agile+Devops was good for app-centric projects, where data was isolated. But data-centric projects triggers new additional challenges! ● New players to involve: data scientists, data engineers... These may have a completely different background (mathematicians...) and face the technology differently. → Need common understanding, appropriate ergonomy. (notebooks, GUI…) ● A recurrent technological/language stack used for the various types of jobs to handle: ingestion, dataprep, modeling… → Need for a ready-to-use toolbox ● Coordinate the various jobs applied to the data → Need for job pipelining/orchestration ● Feed the dev process massively using production data (ex. for machine learning) → Strengthen security ● Identify the patrimony (cataloging), share data, control spreading → Need for governance
- 23. One DataOps definition DataOps is a collaborative data management practice focused on improving the communication, integration and automation of data flows between data managers and data consumers across an organization. The goal of DataOps is to deliver value faster by creating predictable delivery and change management of data, data models and related artifacts. DataOps uses technology to automate the design, deployment and management of data delivery with the appropriate levels of governance and metadata to improve the use and value of data in a dynamic environment. Source: Gartner - Innovation Insight for DataOps - Dec. 2018
- 24. DataOps is gaining momentum The number of data and analytics experts in business units will grow at 3X the rate of experts in IT departments, which will force companies to rethink their organizational models and skill sets. 80% of organizations will initiate deliberate competency development in the field of data literacy, acknowledging their extreme deficiency.
- 26. Data engineers need pipelines to deliver data Extract Transform Agregate Share Shared Dataset(s) & data APIs Data processing Consumers That’s where your good old datawarehouse generally stands! If data is the new oil, datalakes are just oil fields (passive, mass raw of structured & unstructured data), Hive/Impala & co. are oil rigs, while the DataOps pipelines are refineries, aimed at processing data… Car engines are the datascience leveraging on this fuel to provide a disruptive way of transportation! #1 the datalake is not the point (while companies focused on it). Data processing is. #2 You don’t process data just for the pleasure. You do it to support activities which, them, bring value to the business. DATALAKE Data storing: datalakes, object storage, data virtualization
- 27. In comparision, Dev needed pipelines to deliver innovative apps Commit Compile & test Package Deploy to Dev & test Code Running app Promote to … & test Promote to PROD
- 28. And Data scientists need pipelines to deliver valuable models
- 29. ShareTransformExtract Inception: DataOps (and AIOps) delivered in a DevOps way CONSUMEAggregate Data processing jobs (for ingesting, transforming data, etc.) are finally just pieces of code. These pieces of code can be delivered themselves using DevOps principles :) Automated through delivery pipelines.
- 30. DataOps Orchestrator Enables the delivery and run of data projects DataLab Teams Data projects governance Software factory Inception: DataOps (& AIOPs) to be achieved... in a DevOps way! Regular landscape for apps (app servers…) UAT PRODPREPRODDEV Feature team x Feature team y Version nVersion n+1Version n+3 Version n+2 Version nVersion n+1Version n+3 Version n+2 Business needs API API
- 31. Building up a dataops platform Concretely, you need a platform performing the following features: - It must enable to deploy data processing jobs, leveraging on languages/stacks and technologies that are commonly used by data engineers (Apache Sqoop, python, java…). Regular ETLs may be part of the story - It must enable to schedule and run pipelines aggregating jobs in logical sequences (acquiring data, preparing it, delivering it in datamarts (databases, indexing clusters…) - It must provide data cataloging & governance features (to have a clear view of the data patrimony), and enable to manage data governance/security (perform access control, etc.) - It must appropriate types of datamarts regarding the data patrimony (structured/non structured, time oriented or not, etc.) - It must have an ergonomy enabling data engineers and dataops persons to be autonomous and productive (avoid using tools not design for them, such as regular “OPs” schedulers, raw use of complex tools such as kubernetes…) Progressively, more event-driven, data streaming projects arrive on the market. They also need appropriate set of underlying technologies (Kafka clusters among them)
- 33. Datahub commitments: build up a data capital Data Dictionnary & catalog Data Extraction / Lineage Expertize animation, marketing, communication Data Exposition Data Processing Data WareHouse / Data Lake Data Viz Data Quality Governance / Security Modelization Transversal commitment: Build up & share a transverse data capital for the company The process is largely geared by DataOps pipelines! This is an extract from a longer presentation: extensive version can be found here https://bit.ly/33tfoNJ
- 34. Datahub commitments: deliver usecases Data Collection Data Exploration & Analysis tools ML Code ML Trainning (Model) Monitoring Data Viz Data Verification Service Presentation Deliver valuable usecases for the business The process is largelly geared by a combination of Devops + Dataops + ML/AIOps pipelines! This is an extract from a longer presentation: extensive version can be found here https://bit.ly/33tfoNJ
- 35. DevOps organizations (remind Spotify?) Squad Squad Squad Chapter devs Tribe Chapter ...
- 36. From DevOps to DataOps & AIOPs Squad Squad Squad Chapter devs Tribe Chapter ... Chapter datascience Chapter data engineer False good idea Sounds logical, prolongating agile/devops paradigms. But it’s too early! You don’t have the maturity & critical mass to do this at the begining!
- 37. From DevOps to DataOps & AIOPs: short term Squad Squad Squad Chapter devs Tribe Chapter ... SquadSquad Chapter datascience Chapter data engineer DataHub Valuableusecasesforthebusiness Transversa lactivities Build a datahub first, which create a clear positionning, creates visibility accross the org. Two objectives: deliver valuable usecases to ignite & show off value of data, while data used for it are the first data to integrate you data catalog
- 38. Data scientists chapters (per tribe & datahub) linked through a guild From DevOps to DataOps & AIOPs: longer term Squad Squad Squad Chapter devs Tribe Chapter ... Squad Data engineers chapters (per tribe & datahub) linked through a guild DataHub People working on business usescases will progressively get back to the regular organization: if you don’t your just creating a new silo, while the devops/agile orgz were intended to remove them (paradox). As it was usefull in a first step, it should progressively spread in the org. You may only keep few squads to work on very innovative tech to address new usescases (ex. deep learning when regular ML will become common). They will also be responsible to foster their expertize through the guild they will animate too. However, you keep people working on transversal data engineering topics) Valuableusecasesforthebusiness Transversa lactivities
- 39. Matrix organization & serendipity This matrix organization (transversal datasets owned by the Datahub, securely shared to several isolated usecases) enable to factorize the work (so raise your dataset ROI). Each time a usecase team needs a new dataset, it should be capitalized by integratin the data catalog owned by the datahub (see the central team’s value ?) Serendipity: by having a clear understanding of your data patrimony, you can valorize it of course, but it may also help to give new ideas! “Since I’ve this data, and this one, so I may be able to [your_new_idea_here]” “If only HP knew what HP knows, we'd be three times more productive” - Lew Platt, former CEO of Hewlett-Packard Dataset #1 Dataset #2 Dataset #3 Dataset #4 Usecase #1 Usecase #2 Usecase #3 Data Catalog
- 41. Data engineering vs Data Science [80%] of a data project is roughly about data aquisition/preparation/sharing (data engineering) [20%] of a data project is roughly about data valorization (data science, data analytics) → Your datascientists generally spend most of their time at doing data engineering empirically when a clear data engineer position doesn’t exist in your organization! - It’s not very efficient (as datascientists costs much more than data engineers and are difficult to hire) - They generally doesn’t like this activity (and may leave your company at the end!) - Happens regularly: two datascientists using same data for different usecases will probably create 2 identical ingestion/preparation pipelines for their projects (you miss a factorization effect)
- 42. Create clear Data Engineer and DataOps positions! Data Engineers are the tech plumber of data Key missions - Create, configure transformation/preparation jobs to ingest and shape the data - Deliver them through appropriate datamarts (DB, indexing clusters, APIs…) - In small / fewly constrained setups, he may handle deployment/run of these process himself in PROD (quite “noOps” pattern), or this is offloaded to a specialized dataops person mutualized among several data engineers Background - More close to a developer / integrator than a datascientist! (but with a sensibilisation on data challenges and technologies : Sqoop, HDFS, Hive, Impala, spark, Object storage, etc.) Data analysts & scientists are experts in valorizing the data Key missions - Develop BI, analytics, models based on the datasets they have. Background - May come from a very non-IT background (former statisticians are commons) Knowledgeable on specific frameworks (tensorflow, etc.) The Data stewart is a functional manager of data Key missions - Manage governance and security Background - Have a functional / business knowledge of data DataOps guy are the local, specialized OPs attached to the data engineers & scientists Key missions - Offload deployment of jobs, pipelines and various assets built up by the data engineer (and datascientists) from dev to prod - Set up CI/CD toolchains and teach data engineers to work “in a devops way” - Instrument/Monitor data flow and data quality, manage the run time - ... Background - Mostly DevOps person, with sensibilization on data challenges, and technologies Transversal, support data functions
- 43. Let’s start with data industrialization!
- 44. How to start? Focus on early usecases delivery to gain trust: datascientists and analysts should be your best friends ● Define clear Data Engineer or even DataOps positions ● Provide them an industrial platform, enabling them to be more autonomous and productive (less round trips with ops) ● Empower pluridisciplinary data project teams and make them achieve some first (simple!) use cases to create confidence and gain more budget if needed ● Set up empirically a basic data catalog made of the dataset gathered and prepared for your usecases Don’t enforce organization changes yet! Foster day to day collaboration on operational topics first. Adopting technologies and automation is at the heart of any tech people (IT dept. at the first row). This is a quite natural process. But changing organization is much more sensitive (address management reorganization, people objectives changes, etc.). This should be done in a latter step, when some early victories have helped to gain trust, and proves your path is the right one.
- 45. How to start? Now, it’s time to shape your datahub ● On the tech side: Automate the whole toolchain (CI/CD); shift to more (complex) use cases (AI…), scale out platform ● Start changing organization / management: set up your datahub with a clear commitment, spend more energy on the dataops part, since enough usecases have been delivered to justify the factorization/transversal effect On a longer term, scuttle your work! ● More seriously, your initial siloted approach enabled to have the critical mass to bootstrap. Now, it’s time to desilot your datalab to spread in the whole IT dept; if you don’t, you just created a sub data driven IT, in the larger IT ecosystem, with few porosity
- 46. BEWARE Data engineering is a hidden (‘cause spotlights are on datascientists) key success factor to accelerate, increase reliability and enhance ROI of your data project. But don’t “do Dataops for Dataops”! Remind : DataOps is there to serve, offload pains of datascientists & analysts, which them transform business needs in solution. Exactly like ITOps is there to provide infrastructure assets to any app / data teams of the IT dept...
- 47. WeWork 92 Av. des Champs-Élysées 75008 Paris - France Seine Innopolis 72, rue de la République 76140 Le Petit-Quevilly - France Thank you! @adrienblind