Java 的開放原碼全文搜尋技術 - Lucene
Download as ppt, pdf10 likes6,514 views

簡介 Java-based 的全文搜尋引擎 Lucene 的概念及基本實作
![Java 的開放原碼全文搜尋技術 - Lucene 作者: 王建興 /Chien-Hsing Wang [email_address]](https://image.slidesharecdn.com/qing-lucene-j22004fin-120208013141-phpapp01/85/Java-Lucene-1-320.jpg)












































![詞之修飾子 (2/2) 相近搜尋 搜尋的字組之間的距離不超過指定的範圍 "jakarta apache"~10 範圍搜尋 基於字串順序 mod_date:[20020101 TO 20030101] title:{Aida TO Carmen}](https://image.slidesharecdn.com/qing-lucene-j22004fin-120208013141-phpapp01/85/Java-Lucene-48-320.jpg)










![In-Memory Indexing RAMDirectory ramDir = new RAMDirectory(); IndexWriter ramWriter = new IndexWriter(ramDir, analyzer, true); … … IndexWriter fsWriter = new IndexWriter(indexDir, analyzer, true); fsWriter.addIndexes(new Directory[] { ramDir }); ramWriter.close(); fsWriter.close();](https://image.slidesharecdn.com/qing-lucene-j22004fin-120208013141-phpapp01/85/Java-Lucene-59-320.jpg)

![Resources (1/2) Project http://jakarta.apache.org/lucene/docs/index.html [email_address] [email_address] Index Format http://jakarta.apache.org/lucene/docs/fileformats.html Introduction http://today.java.net/pub/a/today/2003/07/30/LuceneIntro.html](https://image.slidesharecdn.com/qing-lucene-j22004fin-120208013141-phpapp01/85/Java-Lucene-61-320.jpg)
































More Related Content
What's hot (19)
Viewers also liked (6)



Similar to Java 的開放原碼全文搜尋技術 - Lucene (20)






![Lucene 3[1] 0 原理与代码分析](https://cdn.slidesharecdn.com/ss_thumbnails/lucene31-0-100225194736-phpapp02-thumbnail.jpg?width=560&fit=bounds)













More from 建興 王 (7)







Recently uploaded (7)






![[GDG Build with AI] 善用現代 AI 科技:打造專屬行銷工具箱 @ GDG Changhua 彰化](https://cdn.slidesharecdn.com/ss_thumbnails/ai-250526054018-7cb05c2e-thumbnail.jpg?width=560&fit=bounds)
Java 的開放原碼全文搜尋技術 - Lucene
- 1. Java 的開放原碼全文搜尋技術 - Lucene 作者: 王建興 /Chien-Hsing Wang [email_address]
- 2. 個人簡介 清大資工博士候選人 研究興趣 Distributed Network Management System Mobile Code System Peer-to-Peer System 開發興趣 J2EE-based System Qing “ ching”
- 3. 概要 全文搜尋引擎簡介 Lucene 簡介與程式設計 Lucene 應用實例-圖檔管理 相關資源
- 5. 為何需要全文搜尋引擎? 你今天 Google 了嗎? Google 大神無所不在,日日焚香禱祝,便可受其庇祐 企業的文件中心 文件資料電子化程度高,數量又龐大 個人的數位資料管理
- 6. 全文搜尋引擎技術 給定一小段字詞,搜尋含有該字詞的文件 作法一: String Matching Algorithm 所有的文件內容都需保留 搜尋速度在規模提升後會衰退的很快 作法二: Index-based Method
- 7. 全文搜尋流程 文件 查詢結果 索引 排名 查詢 輸入查詢條件 預先的處理
- 8. 全文搜尋的查詢 自然語言 ” 我要找出教 Java 程式設計的文章” 布林運算表示 “ Java” and “ 程式設計”
- 9. 全文搜尋中預先的處理動作 依文件格式解出文件中的文字部份 例如: Word, PDF, HTML, etc… 斷字斷詞 東西大不同 建索引
- 10. 文件的結構化表示 王森是個好人 文件 1 王建興 , 也是個好人 文件 2 2 好人 ... ... 2 王建興 2 王建 1 好人 1 森是個 ... ... 1 王森是個 1 王森是 1 王森 文件號 詞
- 11. 索引表示- Vector Space 2 5 1 0 0 4 1 1 0 1 0 3 1 0 0 3 10 2 4 2 0 0 3 1 詞 5 詞 4 詞 3 詞 2 詞 1 文件號
- 12. 索引表示- Inverted Index (1/3) 2 1 1 4 詞 5 5 1 0 2 詞 4 1 0 0 0 詞 3 0 1 3 0 詞 2 0 0 10 3 詞 1 文件 4 文件 3 文件 2 文件 1 詞
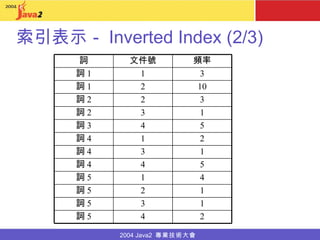
- 13. 索引表示- Inverted Index (2/3) 4 1 詞 5 1 2 詞 5 1 3 詞 5 5 4 詞 4 1 3 詞 4 1 3 詞 2 10 2 詞 1 2 4 詞 5 2 1 詞 4 5 4 詞 3 3 2 詞 2 3 1 詞 1 頻率 文件號 詞
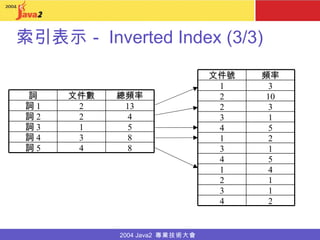
- 14. 索引表示- Inverted Index (3/3) 8 3 詞 4 8 4 詞 5 5 1 詞 3 4 2 詞 2 13 2 詞 1 總頻率 文件數 詞 4 1 1 2 1 3 5 4 1 3 1 3 10 2 2 4 2 1 5 4 3 2 3 1 頻率 文件號
- 15. 索引式方法 VS. Like RDMS 的 like , DB 的索引是起不了作用的 僅用 GREP 式的搜尋 like 不具斷詞的比對效果 Like def% 有可能找出 definition 與 definite like 不能提供比對結果的好壞指標 不具衡量相似性的能力
- 16. Lucene 簡介與程式設計 Lucene 簡介 Lucene 程式設計
- 17. Lucene 是… Lucene 是個高效能的全文搜尋引擎 100% Pure Java 跨平台! 目前是 Jakarta Project 的一部份 Open Source Free
- 18. Lucene 的作者與歷史 作者 : Doug Cutting V-Twin 搜尋引擎的首席開發者 Excite 的資深系統架構師 歷史沿革 www.lucene.com sourceforge.net/projects/lucene jakarta.apache.org/lucene
- 20. Powered by Lucene – Jute
- 21. Powered by Lucene – 博客中國
- 22. Powered by Lucene – 焦點網狂搜
- 23. Lucene 的主要特色 提供高效能的索引機制 提供布林運算查詢 提供查詢結果的排名( ranking )與評分 跨平台 開放易用的 API 極易擴充,客製
- 24. Lucene 做為全文搜尋引擎的優點 (1/2) 支援遞增式的索引 毋需每次重建索引,即使只增加一點資料 不侷限在特定型態的資料來源 例如 HTML 可自行剖析不同的資料來源,轉化成可供 Lucene 處理的文件類別 文件的多欄索引控制 可將文件劃分為多個欄位 每個欄位都可進行不同的索引控制,例如斷詞與否
- 25. Lucene 做為全文搜尋引擎的優點 (2/2) 提供通用的文件分析能力 可自訂文件分析的方式 標準支援 CJK 與阿拉伯語言等非拉丁語系的語言 提供通用的查詢分析能力 可自訂查詢的語法
- 26. Lucene 的安裝與建置 自 Lucene 官方網站取得 Binaries :直接可用 Source Code :需自行編譯 毋需額外的其他 Third Party 程式庫 將 library 檔置於 CLASSPATH 中 lucene-{version}.jar 就是這麼簡單!
- 27. Lucene 的基本架構 Index Query String Query Searcher IndexWriter .addDocument() Document Document Document QueryParser .parse() Document Field1(name, value) Field2(name, value) … . Keyword1(name, value) … .
- 28. Lucene 中的文件( Document ) 每份文件皆被對應至一文件號( document number ) 文件是由一組欄位所構成 每個欄位皆為 name:value 例如: document.add(Field. Text (“title”, “ 我想當個好人” )); document.add(Field. Keyword (“author”, “ 王森” )); document.add(Field. Text (“content”, “ 從前我還是個好人的時候…” ));
- 29. Lucene 中的欄位( Field ) 1/2 具三種可能的特質 Stored :整個欄位值存入,不做索引,只供日後之需 Indexed :欄位值會被索引以利搜尋之用 Tokenized : Tokenized 的欄位也必須是 Indexed ,這代表此欄位的內容會先經過斷詞的程序
- 30. Lucene 中的欄位( Field ) 2/2 對應至 Field 類別的不同方法 各有不同的應用時機 省空間不用 Stored 欄位 有些欄位毋需斷詞,例如作者
- 31. Field 應用實例 文件中心中的文件有下述欄位 檔案位置 ( Stored ) 作者 ( Indexed ) 文件時間 ( Stored ) 文件標題 (Tokenized, Stored ) 文件內容 ( Tokenized )
- 32. Field 類別的不同方法 N Y Y N Y 儲存 文件內容 Y Y Field.UnStored(String name, String value) 檔案位置 檔案時間 N N Field.UnIndexed(String name, String value) 作者 Y N Field.Keyword(String name, String value) 文件內容 Y Y Field.Text(String name, Reader value) 文件標題 Y Y Field.Text(String name, String value) 例 索引 斷詞 方法
- 33. Field 不存在的性質組合 N N Y 儲存 索引等於儲存 斷詞必索引 斷詞必索引 不存在的原因 Y N N Y N Y 索引 斷詞
- 34. Lucene 中的分析器( Analyzer ) 用於斷詞 查詢文字條件 文件內容 深深影響索引與搜尋的品質 有多種預設類型 WhileSpaceAnalyzer SimpleAnalyzer StopAnalyzer StandardAnalyzer 可自訂自己的分析器
- 35. Tokenizer 和 Filter 的作用 Tokenizer 被 Analyzer 用來把一連串的文字斷成” token” This is a book -> “ This ” “is” “a” “book” Filter 對 tokenized 後的 token 進行加工 “ This ” “is” “a” “book” -> “ this ” “book” Analyzer 可能用到一個以上的 Tokenizer 但不一定會用到 Filter
- 36. 各分析器的差異 (1/2) WhileSpaceAnalyzer WhilespaceTokenizer SimpleAnalyzer LetterTokenizer LowerCaseFilter StopAnalyzer LetterTokenizer LowerCaseFilter+StopFilter
- 37. 各分析器的差異 (2/2) StandardAnalyzer StandardTokenizer StandrdFilter+LowerCaseFilter+StopFilter
- 38. Lucene 程式設計 加入文件 文字解析 建立索引 搜尋文件 搜尋 實例說明
- 39. 加入文件 文字解析 針對不同格式取出其文字部份 建立索引 利用 StandardAnalyzer 來分析文件內容 利用 Document 與 Field 來輸入文件 利用 IndexWriter 來寫入索引
- 40. 加入文件 - 文字解析 WordExtractor extractor = new WordExtractor(); FileInputStream fis = new FileInputStream(f); text = extractor. extractText (fis); fis.close(); 使用 org.textmining.text.extraction.WordExtractor
- 41. 加入文件 - 建立索引 IndexWriter writer = new IndexWriter(indexPath, new StandardAnalyzer (), true); Document doc = new Document(); doc. add ( Field.UnIndexed ("path", file.getCanonicalPath())); doc.add( Field.Text ("text", text)); writer. addDocument (doc); writer.close();
- 42. 搜尋文件 對索引進行搜尋 利用 StandardAnalyzer 來分析查詢條件 利用 QueryParser 來建立 Query 物件 利用 IndexSearcher 來對索引進行搜尋 利用 Hits 來取得搜尋結果
- 43. 搜尋文件 - 搜尋 Searcher searcher = new IndexSearcher (indexPath); Query query = QueryParser.parse (queryString, "text", new StandardAnalyzer ()); Hits hits = searcher. search (query);
- 44. 搜尋文件 - 取得搜尋結果 for(int i=0; i<hits.length(); i++) { System.out.println("File:“ +hits.doc(i).get("path")); System.out.println("\tScore:“ +hits.score(i)); }
- 45. Lucene 中的查詢語法 查詢是由詞和運算子所組成 所謂的詞( term )即為單一個字詞 “ Hello” 所謂的詞組( phrase )則是由雙引號所括住的多個字詞 “ Hello World” 多詞可經由運算子相連接形成複雜的查詢
- 46. 欄位查詢 “ text” 欄位是預設的欄位 title:"The Right Way" AND text:go title:"Do it right" AND right title:Do it right
- 47. 詞之修飾子 (1/2) 萬元字元 ? 與 * te?t test* 模糊查詢 基於 Levenshtein Distance 或 Edit Distance 演算法 將 ~ 置於單一字詞之末 roam~ 可能找出 foam 和 roams
- 48. 詞之修飾子 (2/2) 相近搜尋 搜尋的字組之間的距離不超過指定的範圍 "jakarta apache"~10 範圍搜尋 基於字串順序 mod_date:[20020101 TO 20030101] title:{Aida TO Carmen}
- 49. 布林運算子 (1/2) OR "jakarta apache" jakarta "jakarta apache" OR jakarta AND "jakarta apache" AND "jakarta lucene“ + ,也稱為 required 運算子 必須要存在 +jakarta apache
- 50. 布林運算子 (2/2) NOT "jakarta apache" NOT "jakarta lucene" NOT “jakarta apache” <- 不 work - ,也稱 prohibit 運算子 不能存在 "jakarta apache" -"jakarta lucene"
- 51. Lucene 與中文 中文有不同於拉丁語系的斷詞特殊性 自動斷詞 詞庫斷詞 Lucene 目前標準已支援中文
- 52. Lucene 的客製能力 查詢語法 查詢物件的建立 斷詞,詞的過濾 相似性 (Ranking)
- 53. 進階議題 如何處理索引內容的變動 刪除已索引的文件 縮小索引檔的大小 進階的查詢動作 調整參數以提昇索引效能 於記憶體中進行索引,達到加速的目的
- 54. 索引的變動 重新索引 太耗時,不經濟 先刪後增 刪去變動前的文件 新增變動後的文件
- 55. 刪除文件的方式 利用 IndexReader 的 delete() delete(int) 已知文件號 delete(Term) 例如已知檔案路徑
- 56. 索引最佳化 利用 IndexWriter 的 optimize() 方法 可壓縮索引資料庫,並提供查詢速度 在大量批次索引後可為之 毋需每次遞增索引後進行
- 57. 取得 Query 物件的方式 Direct Query Parsing 利用 QueryParser 將查詢字串轉為 Query 物件 Indirect Query Parsing 將使用者的輸入(受限的)轉為查詢字串,再透過 Direct Query Parsing 取得 Query 物件 Query Construction 自己建構 Query 物件 最麻煩但最有彈性
- 58. 提高 Lucene 的索引效能 Indexing Speed Factors IndexWriter.mergeFactor 多少文件索引完後會從 memory 被寫會 disk 也關係到多個 segment 中的文件數量達到多少時,會被合併成一個 segment 例如: mergeFactor 為 10 10 個文件被寫成一個 segement 當出現第 10 個 size 為 10 的 segment 時,會被合併成一個 size 為 100 的 segment IndexWriter.maxMergeDocs 單一 segment 中的文件最大量 預設為 Integer.MAX_VALUE
- 59. In-Memory Indexing RAMDirectory ramDir = new RAMDirectory(); IndexWriter ramWriter = new IndexWriter(ramDir, analyzer, true); … … IndexWriter fsWriter = new IndexWriter(indexDir, analyzer, true); fsWriter.addIndexes(new Directory[] { ramDir }); ramWriter.close(); fsWriter.close();
- 60. WebLucene :網站站內搜尋 中國車東 (chedong) 先生所開發 可為 Web Site 提供站內的全文搜尋機制 當然是 Apache Software License http://sourceforge.net/projects/weblucene
- 61. Resources (1/2) Project http://jakarta.apache.org/lucene/docs/index.html [email_address] [email_address] Index Format http://jakarta.apache.org/lucene/docs/fileformats.html Introduction http://today.java.net/pub/a/today/2003/07/30/LuceneIntro.html
- 62. Resources (2/2) Advanced Text Indexing with Lucene http://www.onjava.com/pub/a/onjava/2003/03/05/lucene.html