Java at Scale, Dallas JUG, October 2013

Title: Java at Scale - What Works and What Doesn't Work Nearly so Well Speaker: Matt Schuetze, Product Manager, Azul Systems Abstract: Java gets used everywhere and for everything due to its efficiency, portability, the productivity it offers developers, and the platform it provides for application frameworks and non-Java languages. But all is not perfect; developers both benefit from and struggle against Java's greatest strength: its memory management. In this session, Matt will describe where Java needs help, the challenges it presents developers who need to provide reliable performance, the reasons those challenges exist, and how developers have traditionally worked around them. He will then discuss where Zing fits in the spectrum of use cases where large memory and predictable performance dominate essential application characteristics.







































































More Related Content
What's hot (20)
Viewers also liked (6)




Similar to Java at Scale, Dallas JUG, October 2013 (20)















![[BGOUG] Java GC - Friend or Foe](https://cdn.slidesharecdn.com/ss_thumbnails/javagcfriendorfoe-101125015602-phpapp01-thumbnail.jpg?width=560&fit=bounds)




More from Azul Systems Inc. (20)




















Recently uploaded (20)




















Java at Scale, Dallas JUG, October 2013
- 1. Java at Scale: Performance & GC Presented to Dallas JUG October 2013 Matt Schuetze Product Manager
- 2. Where is Java Working? • On the server ─ Enterprise applications: business rules ─ Monolithic & distributed computing • On the client ─ Fat client computing ─ Thin client, browser-based • Embedded ─ Android apps © 2013 Azul Systems 2
- 3. What is Java’s Appeal? • Portable ─ Write once, run anywhere (after testing everywhere) • Productive ─ No bad features: no multiple inheritance, operator overloading ─ Do the Right Thing philosophy (vs. C++ Do the Efficient Thing) ─ Memory management reduces opportunities for error • Efficient ─ Interpreter → JIT compilation → Dynamic recompilation • Generic ─ Scala, Clojure, JRuby & more use Java runtime ─ Byte code is the new target architecture (ANDF) • Scalable ─ Small to large platforms © 2013 Azul Systems 3
- 4. Parkinson’s Law Applied to Software • Hardware grows with Moore’s Law ─ Transistor counts double roughly every 18 months ─ Memory size grows around 100x every 10 years • Application sizes grow with hardware ─ ─ ─ ─ ─ 1980: 100 KB data on ¼ – ½ MB server 1990: 10 MB data on 16 – 32 MB server 2000: 1 GB data on 2 – 4 GB server 2010: 100 GB data on 256 GB server (In-memory data size. Bigger data is cached or distributed.) © 2013 Azul Systems 4
- 5. Big Memory Servers are the Standard • Retail prices, major web server store (US $, Jan 2013) • Cheap (< $1/GB/Month), and roughly linear to ~1TB • 10s to 100s of GB/sec of memory bandwidth ─ ─ ─ ─ ─ © 2013 Azul Systems 24 vCore, 24 vCore, 32 vCore, 48 vCore, 64 vCore, 128 GB server 256 GB server 384 GB server 512 GB server 1 TB server $5K $8K $14K $19K $36K 5
- 6. Has Java Kept Up? How Scalable is it? • How big is your Java heap? ˃ .5 GB ˃ 1 GB ˃ 2 GB ˃ 4 GB ˃ 10 GB ˃ 20 GB ˃ 50 GB ˃ 100 GB • Hardly anyone runs over 4 GB © 2013 Azul Systems 6
- 7. Large Heaps are a Rarity • Survey of heap sizes for Plumbr memory leak detector ─ Source: http://plumbr.eu/blog/most-popular-memory-configurations © 2013 Azul Systems 7
- 8. Why So Few Big JVMs on Big Servers? • Java performance gets worse with heap size ehCache: 10 GB cache, 29 GB heap, 48 GB 16 core Ubuntu server ─ Pause frequency varies with application activity ─ Pause duration varies with amount to scan/copy © 2013 Azul Systems 8
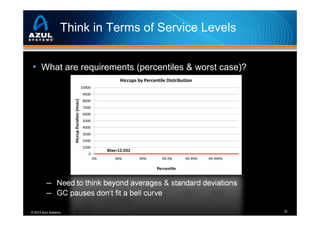
- 9. Think in Terms of Service Levels • What are requirements (percentiles & worst case)? ─ Need to think beyond averages & standard deviations ─ GC pauses don’t fit a bell curve © 2013 Azul Systems 9
- 10. A Classic Look at Application Response • Key assumption: response time is a function of load ─ © 2013 Azul Systems source: IBM CICS server documentation, “understanding response times” 10
- 11. Java Response Has a Different Look • Pauses may track with load, but not in as obvious a way ─ © 2013 Azul Systems source: ZOHO QEngine White Paper: performance testing report analysis 11
- 12. A Few Realities About GC • First the good: ─ GC is very efficient, much better than malloc() ─ Dead objects cost nothing to collect ─ GC will find all the dead objects without help, even cyclic graphs • Now the bad: ─ GC really does stop for ~1 second per GB of live objects ─ You can change when it happens, not if* ─ You can still have memory leaks ─ Hold on to objects so GC can’t release them ─ No pauses in a 20 minute test doesn’t mean they’re gone ─ “You can pay me now, or you can pay me later.” * We’ll talk about that later… © 2013 Azul Systems 12
- 13. How Does a Garbage Collector Work? • Three phases to GC: ─ ─ ─ Identify the live objects ─ Start with stack & statics, flag everything we reach Reclaim resources held by dead objects ─ Anything we didn’t flag in the 1st phase Periodically relocate live objects (defrag) ─ Move objects together, correct references (remap) Free © 2013 Azul Systems 13
- 14. How Does a Garbage Collector Work? • Three phases to GC: ─ ─ ─ Identify the live objects ─ Start with stack & statics, flag everything we reach Reclaim resources held by dead objects ─ Anything we didn’t flag in the 1st phase Periodically relocate live objects (defrag) ─ Move objects together, correct references (remap) • Sample implementations: ─ Mark/sweep/compact for old generation ─ Three separate passes, minimal extra heap ─ Copying collector for new generation ─ Move as we flag, do it all in one pass ─ Requires 2x heap © 2013 Azul Systems 14
- 15. Generational GC Basic assumption: most objects die young • Use copying collector on new objects ─ Scan small % of heap, need small space for copy area ─ Reclaim the most space for the least effort ─ Move objects that live long enough to old generation(s) • Collect old gen as it fills up ─ Much less frequent, likely higher cost, lower benefit • Requires a Remembered Set (e.g. via Card Marking) ─ Track references from outside into new gen ─ Use as roots for new gen collector scan • Don’t absolutely need 2x memory for new gen GC ─ Can overflow into old gen space © 2013 Azul Systems 15
- 16. GC Terminology • Concurrent vs. Parallel ─ A concurrent collector does GC while the application runs ─ A parallel collector uses multiple CPU cores to perform GC ─ A collector may be neither, one, or both • Concurrent vs. Stop-The-World ─ A STW collector pauses the application during part of GC ─ A STW collector is not concurrent; it may be parallel • Incremental ─ An incremental collector does its work in discrete chunks ─ Probably STW, with big gaps between increments © 2013 Azul Systems 16
- 17. GC Terminology 2 • Precise vs. Conservative ─ A conservative collector doesn’t know every object reference or doesn’t know if some values are references or not ─ Can’t relocate objects if it can’t tell a ref from a value ─ A precise collector knows & can process every reference ─ Required to move objects ─ Compiler provides semantic information for the collector ─ Java relies on precise collection • Safepoints ─ Places in execution (point or range) where collector can identify every reference in a thread’s execution stack ─ We bring a thread to a safepoint and keep it there during GC ─ Might mean pausing the thread, might not (e.g. JNI) ─ Safepoints need to be reached frequently ─ Global safepoints apply to all threads (STW) © 2013 Azul Systems 17
- 18. Typical GC Combinations • New generation ─ Usually a copying collector ─ Usually monolithic, stop-the-world • Old generation ─ Usually Mark/Sweep/Compact ─ May be stop-the-world, or concurrent, or mostly concurrent, or incremental stop-the-world, or mostly incremental stop-the-world • Mostly means not always ─ Fall back to monolithic stop-the-world (i.e. big pauses) © 2013 Azul Systems 18
- 19. The Good Little Architect – A Moral Tale A good architect must be able to impose her architectural choices on her projects • Once upon a time, Azul met an app with 18 sec pauses ─ App had 10s of millions of object finalizations every GC cycle ─ Back then, reference processing was a stop-the-world event • Every class in the project had a finalizer ─ All the finalizers did was null every reference field ─ In theory, saves the GC from following pointers ─ Right for C++ reference counting, oh so wrong for Java • Two morals: ─ Know the cost of your actions (learn the underlying system) ─ Just because it doesn’t cost now doesn’t mean it won’t later © 2013 Azul Systems 19
- 20. Oracle HotSpot GC Options • Parallel GC ─ New Gen: monolithic STW copying ─ Old Gen: monolithic STW mark/sweep/compact • Concurrent Mark Sweep (CMS) ─ New Gen: monolithic STW copying ─ Old Gen: mostly concurrent non-compacting ─ Mostly concurrent marking (multipass) ─ Concurrent sweeping ─ No compaction: free list, no object movement ─ Fallback is monolithic STW mark/sweep/compact © 2013 Azul Systems 20
- 21. Oracle HotSpot GC Options 2 • Garbage First (G1GC) ─ New Gen: monolithic STW copying ─ Old Gen: ─ Mostly concurrent marker ─ STW to catch up on mutations, reference processing ─ Track inter-region relationships in remembered sets ─ STW mostly incremental compactor ─ Compact regions that can be done in limited time ─ Delay compaction of popular objects & regions ─ Goal: “avoid, as much as possible, having a full GC” ─ Fallback is monolithic STW mark/sweep/compact ─ Required for compacting popular objects & regions © 2013 Azul Systems 21
- 22. Where Do Pauses Matter? • Interactive apps like ecommerce ─ Add many seconds to a transaction & maybe lose a customer ─ Batch apps care about start-to-finish time, not transactions • Big data apps ─ Travel site wants to keep hotel inventory in memory ─ Search app wants to keep entire index in memory • Efficiency & management ─ More work from fewer JVM instances • Low latency apps ─ Financial apps process data as it arrives ─ Small number of msecs down to < 1 msec ─ Requires low latency OS & significant tuning © 2013 Azul Systems 22
- 23. Characterizing GC Pauses • Frequency relates to activity ─ Object creation rate ─ Object mutation rate • Severity relates to memory size ─ The more we examine & copy, the longer it takes ─ New gen is usually not the problem (yet) • Not how much GC overhead, but where it happens © 2013 Azul Systems 23
- 24. Limits to GC Overhead • Worst case: no empty memory = 100% GC ─ GC runs hard all the time, reclaiming nothing • Best case: infinite empty memory = 0% GC ─ Just keep creating objects, never collecting • In between, GC follows 1/x curve as memory grows CPU 100% 0% Live set © 2013 Azul Systems Heap size 24
- 25. How to Measure Pauses • Identify the magnitude of the problem ─ jHiccup: free software from Azul’s CTO (jhiccup.com) ─ Does minimal work & records time to complete ─ Long delays indicate JVM wasn’t letting apps run ─ Run against your application ─ Results should map well to GC logs ─ Results will not include app inefficiencies ─ Run against idle JVM ─ Identify pauses from OS, VM, power management • Don’t fix problems until you know where they lie © 2013 Azul Systems 25
- 26. What To Do About Pauses • Apply creative language (the Marketing solution) ─ “Guarantee a worst case of X msec, 99% of the time” ─ “Mostly concurrent, mostly incremental” ─ i.e. “Will at times exhibit long monolithic STW pauses” ─ “Fairly consistent” ─ i.e. “Will sometimes show results well outside this range” ─ “Typical pauses in the tens of milliseconds” ─ i.e. “Some pauses are a lot longer than that” © 2013 Azul Systems 26
- 27. What To Do About Pauses • Tune like crazy ─ Adjust GC parameters until behavior’s acceptable ─ A stopgap, not a solution • Keep the heap small ─ Multiple small instances instead of fewer bigger ones ─ Move data out of heap (e.g. external cache) ─ Pool your objects (e.g. threads, DB connections) • Commit ritual murder ─ Big heap, kill & restart instance before old gen GC ─ Yes, people really do this • Change your GC ─ Move from one that rarely stalls to one that never stalls © 2013 Azul Systems 27
- 28. Making JVM Pauseless: The Hard Parts • Robust concurrent marking ─ References keep changing ─ Multipass marking is sensitive to mutation rate ─ Weak, Soft, Final references hard to deal with • Concurrent compaction ─ Moving the objects isn’t the problem ─ It’s fixing all the references to the moved objects ─ How do you handle an app looking at a stale reference? ─ If you can’t, remapping is a monolithic STW operation • New gen collection at scale ─ New gen is generally monolithic STW ─ Pauses are small because heaps are tiny ─ A 100 GB heap means new gen GC has a lot of work © 2013 Azul Systems 28
- 29. Azul’s Zing JVM • High performance production JVM ─ 64-bit Linux on X86 ─ Red Hat, SuSE, Ubuntu, CentOS ─ Maximum heap size: 512 GB ─ Elastic memory to prevent out-of-memory failures ─ Overdraft protection for your JVM • Always-on performance & execution monitoring ─ System level ─ JVM level ─ Application level © 2013 Azul Systems 29
- 30. Azul’s C4 Collector • Concurrent guaranteed-single-pass marker ─ Unaffected by mutation rate ─ Concurrent reference processing (weak, soft, final) • Concurrent compactor ─ Moves objects without pausing your application ─ Remaps references without pausing your application ─ Can relocate entire generation (new/old) in every GC cycle • Concurrent, compacting old generation • Concurrent, compacting new generation • No stop-the-world fallback. Ever. © 2013 Azul Systems 30
- 31. Remember This Slide? • Java performance gets worse with heap size ehCache: 10 GB cache, 29 GB heap, 48 GB 16 core Ubuntu server ─ Pause frequency varies with application activity ─ Pause duration varies with amount to scan/copy © 2013 Azul Systems 31
- 32. Think in Terms of Service Levels • What are requirements (percentiles & worst case)? ─ Need to think beyond averages & standard deviations ─ GC pauses don’t fit a bell curve © 2013 Azul Systems 32
- 33. In-Memory Computing with Lucene • Wikipedia English language index in memory ─ 132 GB data in 240 GB heap ─ © 2013 Azul Systems Ref: blog.MikeMcCandless.com 33
- 34. In-Memory Computing with Lucene • Wikipedia English language index in memory ─ 132 GB data in 240 GB heap ─ © 2013 Azul Systems Ref: blog.MikeMcCandless.com 34
- 35. Always-on Performance Monitoring • System level activity: CPU, memory, network © 2013 Azul Systems 35
- 36. Always-on Performance Monitoring • JVM activity: CPU & memory © 2013 Azul Systems 36
- 37. Real Time Execution Analysis © 2013 Azul Systems 37
- 38. www.azulsystems.com Technical papers Free trials of Zing VM Free licenses to OSS committers
- 39. Parallel GC © 2013 Azul Systems 39
- 40. Concurrent Mark/Sweep © 2013 Azul Systems 40
- 41. G1GC © 2013 Azul Systems 41
- 42. Zing C4 © 2013 Azul Systems 42